对一篇英文文章进行词频统计重点在于内容去噪和归一化,可用split()进行分词。本文以《飘》为例,统计词频最高的前十位。
1.读取文件,通过lower()、replace()函数将所有单词统一为小写,并用空格替换特殊字符。
def gettext():
txt = open("piao.txt","r",errors='ignore').read()
txt = txt.lower()
for ch in '!"#$&()*+,-./:;<=>?@[\\]^_{|}·~‘’':
txt = txt.replace(ch,"")
return txt
2.对处理后的文本进行词频统计存入字典。
txt = gettext()
words = txt.split()
counts = {}
for word in words:
counts[word] = counts.get(word,0) + 1
3.统计结果存为列表类型,按词频由高到低进行排序,输出前十位。
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(10):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
输入:

输出:
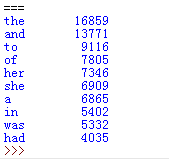
版权声明:本文为aieraisiji原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。