1.NameServer 集群化部署,保证高可用
第一步要让NameServer 集群化部署,达到高可用,建议部署3台机器,这样能充分保证NameServer 作为路由中的的可用性
哪怕一台或者两台挂掉,因为每个NameServer 上有完整的集群路由信息,所以另外的服务也可以正常运行,
2.基于Dledger的Broker主从架构部署
其次就是考虑broker 集群如何部署,因为RocketMQ 4.5 之前的版本不能实现Master-Slave 部署,所以当Master 挂掉
没法自动将Slave 升级为Master ,所以选用4.5之后的版本,实现Dledger的主备自动切换的功能来进行生产架构的部署
而且Dledge 部署要求一个Master 至少部署两个slave ,这样的三个组成一个Group,一旦Master 宕机,可以从另外的连个slave
选举一个当Master
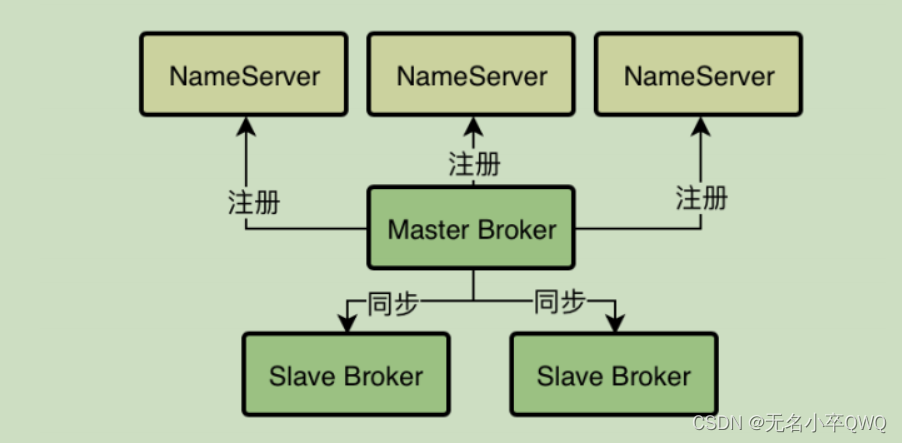
无论master 还是slave 都会把自己注册到NameServer 去,然后Master Broker还会把数据同步给连个Slave Broker
实际上是Slave 自己去Master 拉取
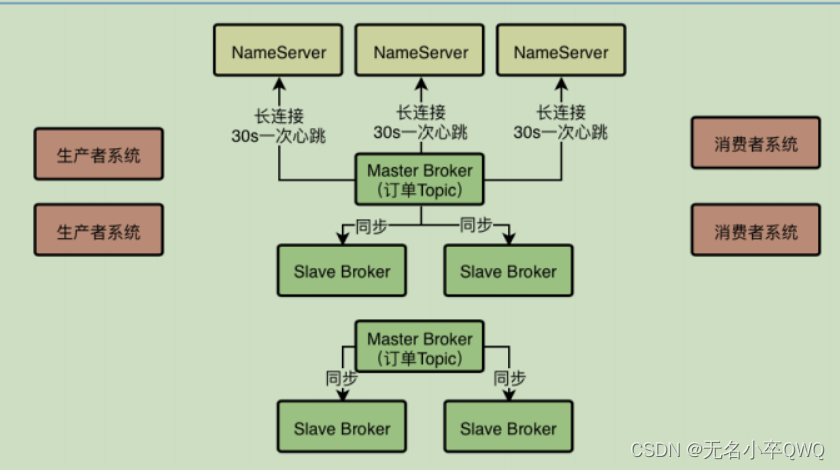
3.Broker是如何跟NameServer进行通信的?
接下来就是探究Broker 怎样跟NameServer 通信的,Broker 其实在启动的时候会去跟NameServer 建立一个TCP
长连接然后通过长连接发送心跳请求过去

所以各个NameServer就是通过跟Broker建立好的长连接不断收到心跳包,然后定时检查Broker有没有120s都没发送心跳包,来判定
集群里各个Broker到底挂掉了没有
4. 使用MQ的系统都要多机器集群部署
下一步我们一定会有很多的系统使用RocketMQ,有些系统是作为生产者往MQ发送消息,有些系统是作为消费者从MQ获取消息,
当然还有的系统是既作为生产者,又作为消费者,所以我们要考虑这些系统的部署。
对于这些系统的部署本身不应该在MQ的考虑范围内,但是我们还是应该给出一个建议,就是无论
作为生产者还是消费者的系统,都应该多机器集群化部署,保证他自己本身作为生产者或者消费者的高可用性。

5.MQ的核心数据模型:Topic到底是什么?
下一步,生产者消费者都会往MQ 生产消息,消费消息
MQ中的数据模型是什么?你投递出去的消息在逻辑上到底是放到哪里去的?是队列吗?还是别的什么呢?
Topic :这个就是MQ中的核心数据模型,Topic就是一类数据集合的意思,不同类型的数据放到不同的Topic
举个例子,现在你的订单系统需要往MQ里发送订单消息,那么此时你就应该建一个Topic,他的名字可以叫做:topic_order_info,也
就是一个包含了订单信息的数据集合
6.Topic作为一个数据集合是怎么在Broker集群里存储的?
我们建立的Topic 怎样存储在Broker 中的呢?
比如我们有一个订单Topic,可能订单系统每天都会往里面投递几百万条数据,然后这些数据在MQ集群上还得保
留好多天,那么最终可能会有几千万的数据量,这还只是一个Topic
如果这么大的数据用一台机器来存储,那么可能会放不下这么大的数据,所以要采用分布式存储。
在创建Topic的时候指定让他里面的数据分散存储在多台Broker机器上,比如一个Topic里有1000万条数据,此时有2台
Broker,那么就可以让每台Broker上都放500万条数据
每个broker 在往NameServer 上报心跳包的时候都会告诉NameServer 哪些Topic 的哪些数据在自己这里
7.生产者系统是如何将消息发送给Broker的?
首先我们之前说过,得先有一个Topic,然后在发送消息的时候你得指定你要发送到哪个Topic里面去。你知道你要发送的Topic,
那么就可以跟NameServer建立一个TCP长连接,然后定时从他那里拉取到最新的路由信息,包括集群里有哪些Broker,集群里有
哪些Topic,每个Topic都存储在哪些Broker上
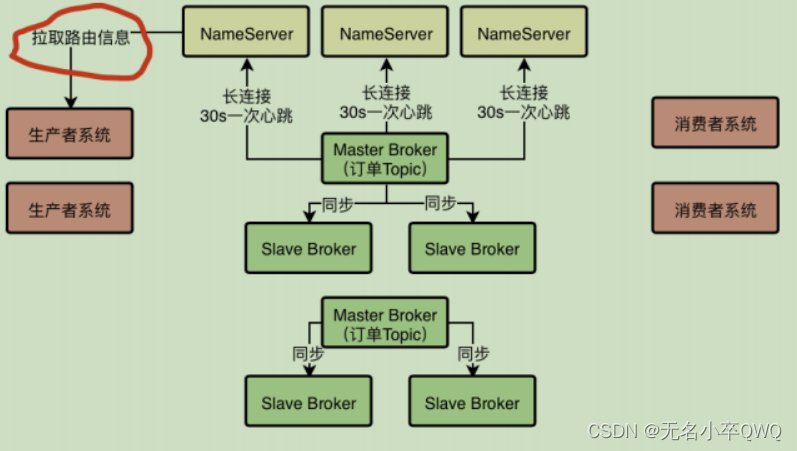
然后生产者系统自然就可以通过路由信息找到自己要投递消息的Topic分布在哪几台Broker上,此时可以根据负载均衡算法,从里面选
择一台Broke机器出来,比如round robine轮询算法,或者是hash算法,都可以。
选择一台Broker之后,就可以跟那个Broker也建立一个TCP长连接,然后通过长连接向Broker发送消息即可
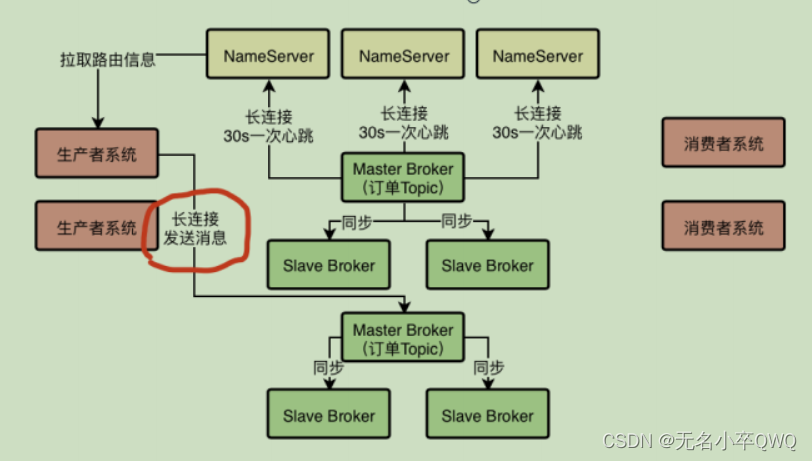
唯一要注意的一点,就是生产者一定是投递消息到Master Broker的,然后Master Broker会同步数据给他的Slave Brokers,实现
一份数据多份副本,保证Master故障的时候数据不丢失,而且可以自动把Slave切换为Master提供服务
8.消费者是如何从Broker上拉取消息的?
消费者系统其实跟生产者系统原理是类似的,他们也会跟NameServer建立长连接,然后拉取路由信息,接着找到自己要获取消息的
Topic在哪几台Broker上,就可以跟Broker建立长连接,从里面拉取消息了

这里唯一要注意的一点是,消费者系统可能会从Master Broker拉取消息,也可能从Slave Broker拉取消息,都有可能,一切都看具体
情况
9. 整体架构:高可用、高并发、海量消息、可伸缩
整个这套生产架构是实现完全高可用的,因为NameServer随便一台机器挂了都不怕,他是集群化部署的,
每台机器都有完整的路由信息;
Broker随便挂了一台机器也不怕,挂了Slave对集群没太大影响,挂了Master也会基于Dledger技术实现自动Slave切换为Master;
生产者系统和消费者系统随便挂了一台都不怕,因为他们都是集群化部署的,其他机器会接管工作。
而且这个架构可以抗下高并发,因为假设订单系统对订单Topic要发起每秒10万QPS的写入,那么只要订单Topic分散在比如5台Broker
上,实际上每个Broker会承载2万QPS写入,也就是说高并发场景下的10万QPS可以分散到多台Broker上抗下来。
然后集群足以存储海量消息,因为所有数据都是分布式存储的,每个Topic的数据都是存储在多台Broker机器上的,用集群里多台
Master Broker就足以存储海量的消息。
所以,用多个Master Broker部署的方式,加上Topic分散在多台Broker上的机制,可以抗下高并发访问以及海量消息的分布式存储。
然后每个Master Broker有两个Slave Broker结合Dledger技术可以实现故障时的自动Slave-Master切换,实现高可用性。
最后,这套架构还具备伸缩性,就是说如果要抗更高的并发,存储跟多的数据,完全可以在集群里加入更多的Broker机器,这样就可以
线性扩展集群了