一、背景介绍
在临床医学中,医生的一项重要任务就是判断就诊者是否患病,以便采取适当的进一步行动。临床检测结果常被用于指导临床决策,因此对临床诊断实验的质量评价由于重要。常用的描述检测质量的统计指标有:灵敏度、特异度、预测值、正确率和似然比等。
二、数据集
下面将以pROC包的数据集aSAH为例进行下面讲述:
1. 查看pROC下数据集
install.packages('pROC')
library(pROC)
data(aSAH)
str(aSAH)
2. 结果展示
# 未引入pROC前是无法查看到aSAH数据集
> data(aSAH)
Warning message:
In data(aSAH) : 没有‘aSAH’这个数据集
> library(pROC)
Type 'citation("pROC")' for a citation.
载入程辑包:‘pROC’
The following objects are masked from ‘package:stats’:
cov, smooth, var
Warning message:
程辑包‘pROC’是用R版本4.0.5 来建造的
> data(aSAH)
> str(aSAH)
'data.frame': 113 obs. of 7 variables:
$ gos6 : Ord.factor w/ 5 levels "1"<"2"<"3"<"4"<..: 5 5 5 5 1 1 4 1 5 4 ...
$ outcome: Factor w/ 2 levels "Good","Poor": 1 1 1 1 2 2 1 2 1 1 ...
$ gender : Factor w/ 2 levels "Male","Female": 2 2 2 2 2 1 1 1 2 2 ...
$ age : int 42 37 42 27 42 48 57 41 49 75 ...
$ wfns : Ord.factor w/ 5 levels "1"<"2"<"3"<"4"<..: 1 1 1 1 3 2 5 4 1 2 ...
$ s100b : num 0.13 0.14 0.1 0.04 0.13 0.1 0.47 0.16 0.18 0.1 ...
$ ndka : num 3.01 8.54 8.09 10.42 17.4 ...
> head(aSAH)
gos6 outcome gender age wfns s100b ndka
29 5 Good Female 42 1 0.13 3.01
30 5 Good Female 37 1 0.14 8.54
31 5 Good Female 42 1 0.10 8.09
32 5 Good Female 27 1 0.04 10.42
33 1 Poor Female 42 3 0.13 17.40
34 1 Poor Male 48 2 0.10 12.75
三、统计指标解析
| 检查结果 | 有病 | 无病 | 合计 |
|---|---|---|---|
| 阳性 | a(真阳性) | b(假阳性) | a+b |
| 阴性 | c(假阴性) | d(真阴性) | c+d |
| 合计 | a+c | b+d | a+b+c+d |
1. 灵敏度和特异度
- 灵敏度:是指患者检测结果为阳性的百分率,也叫真阳性率(Sensitivity)。
灵敏度 = a/(a+c)*100%
- 特异度:是指未患病的人检测结果为阴性的百分率,也叫真阴性率(Specificity)。
特异度 = d/(b+d)*100%
2. 正确率
正确率(accuracy):又称总符合率,表示检测结果与金标准的符合程度。
正确率=(a+d)/(a+b+c+d)*100%
正确率反应一项诊断实验或者参数正确区分患者与非患者的能力,但是很大程度依赖人群的发病率(患病率如果为3%,即使全部诊断为阴性,也有97%的正确率)。
3. 约登指数
约登指数(Youden index):反映诊断实验真实性的综合指标。
约登指数 = 灵敏度+特异度-1
约登指数的值范围在-1和1之间,其值越大表明诊断实验的真实性越好,当值为负数时,该诊断实验无任何临床应用价值。
4. 似然比
似然比(likelihood ratio):是患者与非患者中出现某种检验结果的概率之比,反映了得到该测定结果的诊断价值。
-
阳性似然比
阳性似然比(positive likelihood ratio):是真阳性与假阳性之比。
阳性似然比 = 灵敏度/(1-特异度)=(a/(a+c))/(b/(b+d))
-
阴性似然比
阴性似然比(negative likelihood ratio):是假阴性率与真阴性率之比。
阴性似然比 = (1-灵敏度)/特异度=(c/(a+c))/(b/(b+d))
如果似然比等于1说明在患者和非患者中得到该检验结果是相同的,无诊断价值。似然比离1越远表明该检验结果诊断的准确性越高。同时其不受患病率影响,同时结合了灵敏度和特异度信息,比预测值更能反应指标的正确性。
四、单个ROC曲线分析
1. 画ROC曲线
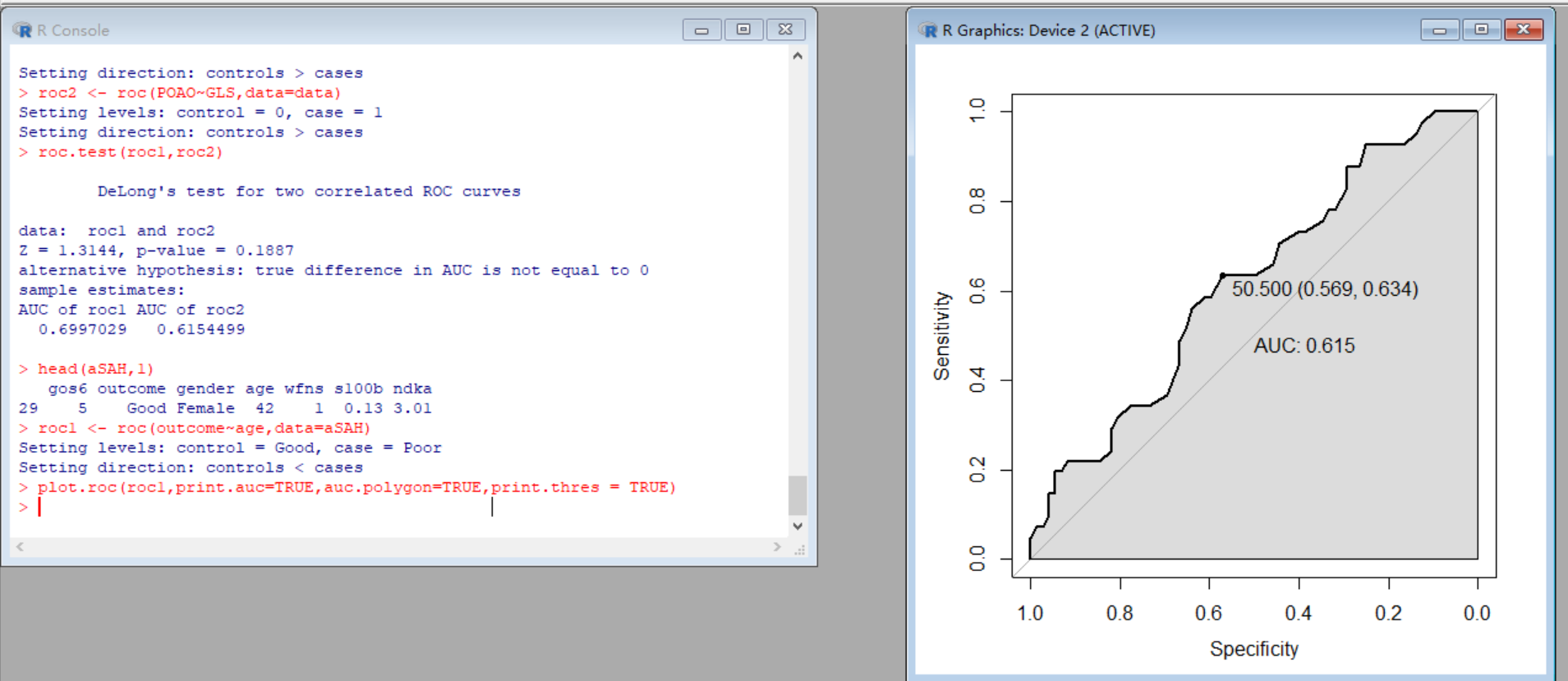
> head(aSAH,1)
gos6 outcome gender age wfns s100b ndka
29 5 Good Female 42 1 0.13 3.01
> roc1 <- roc(outcome~age,data=aSAH)
Setting levels: control = Good, case = Poor
Setting direction: controls < cases
> plot.roc(roc1,print.auc=TRUE,auc.polygon=TRUE,print.thres = TRUE)
>
2. 计算95%可信区间
> library(dplyr)
载入程辑包:‘dplyr’
The following objects are masked from ‘package:stats’:
filter, lag
The following objects are masked from ‘package:base’:
intersect, setdiff, setequal, union
> ci.auc(roc1)
95% CI: 0.5082-0.7219 (DeLong)
3. 计算p值
由于outcome是字符串,不能直接参与p值的计算,这里我们需要添加一个新的参数result(如果outcome是Good的在result中对应是0,如果不是则为1)
> library(verification)
> aSAH$result[aSAH$outcome == "Good"] <- 0
> aSAH$result[aSAH$outcome == "Poor"] <- 1
> aSAH$result
[1] 0 0 0 0 1 1 0 1 0 0 1 0 1 1 0 0 1 0 1 1 1 0 1 0 0 0 0 0 0 0 0 0 1 0 0 1
[37] 1 0 1 1 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 0 0 0 1 0 1 0 0 1 1 1 0 1 1 0 1 1
[73] 1 1 0 0 0 1 1 0 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 0 0
[109] 0 1 0 0 0
> roc.area(aSAH$result,roc1$predictor)
$A
[1] 0.6150068
$n.total
[1] 113
$n.events
[1] 41
$n.noevents
[1] 72
$p.value
[1] 0.02143495
版权声明:本文为weixin_43935907原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。