这篇文章将以豆瓣网为例子,讲解下如何使用requests.session()方法来保持登录会话,同时引入“抓包”的概念,为下一章动态网页讲解打下基础
本次目标网站:
豆瓣网
第一步:打开网站
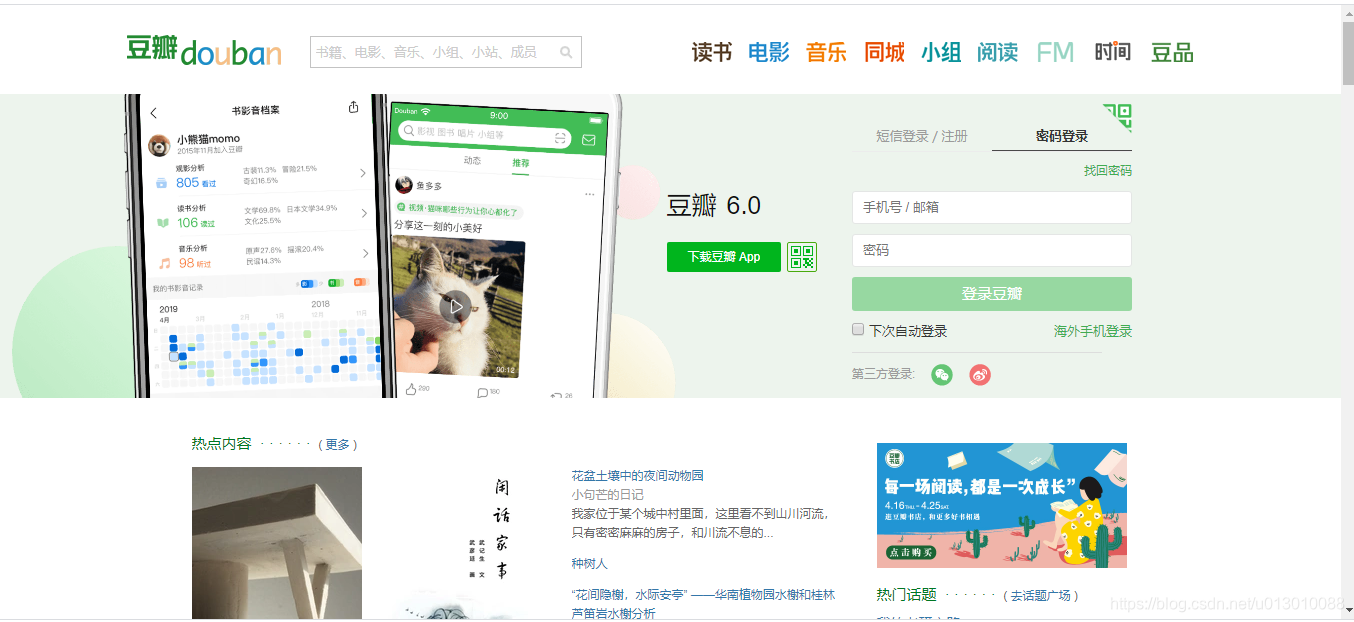
第二步:抓包
在该网页,我们将账号密码输入后点击登录按钮,该网页会将我们输入的账号密码以表单的方式提交给后台,现在我们需要做的就是拿到这个后台地址,然后模拟其需要的参数并访问该地址,以达到直接请求后台登录的目的
首先、键盘按下F12出现以下界面并点击剪头处Network
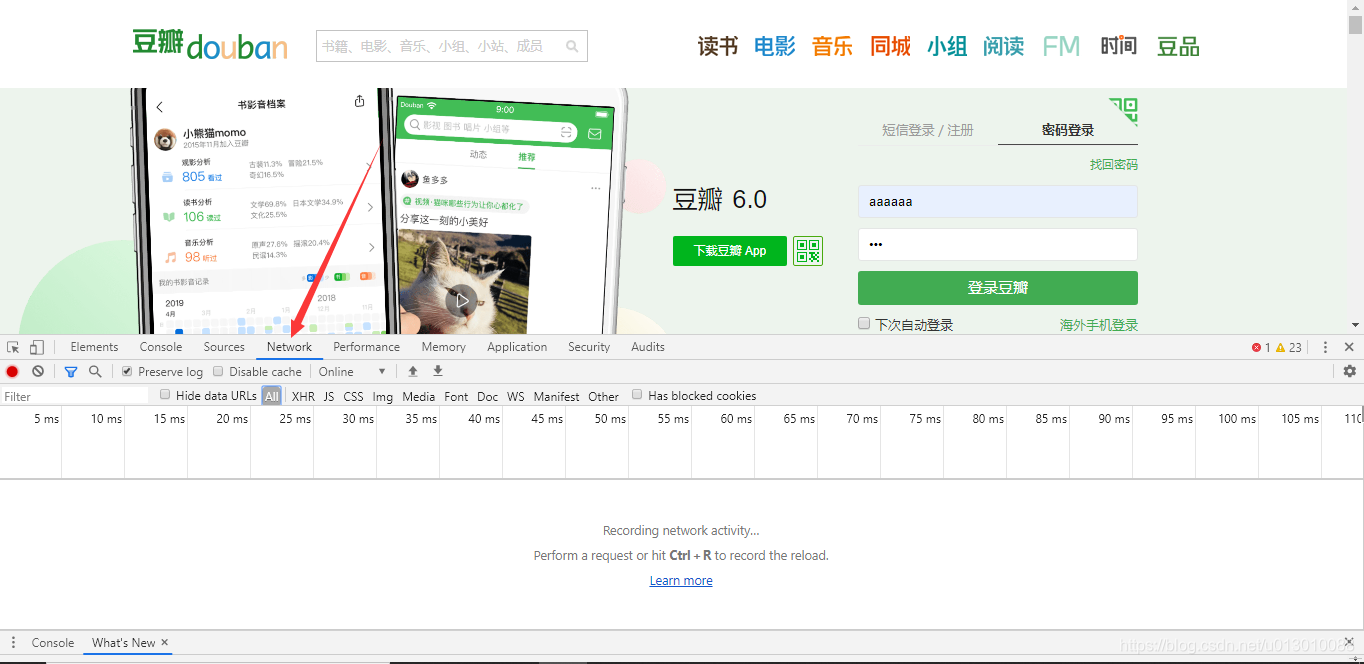
我们先随便输入账号密码点击登录试试看(在此处Network一直保持在下方不要关闭的状态)
而后、按图片所示顺序点击
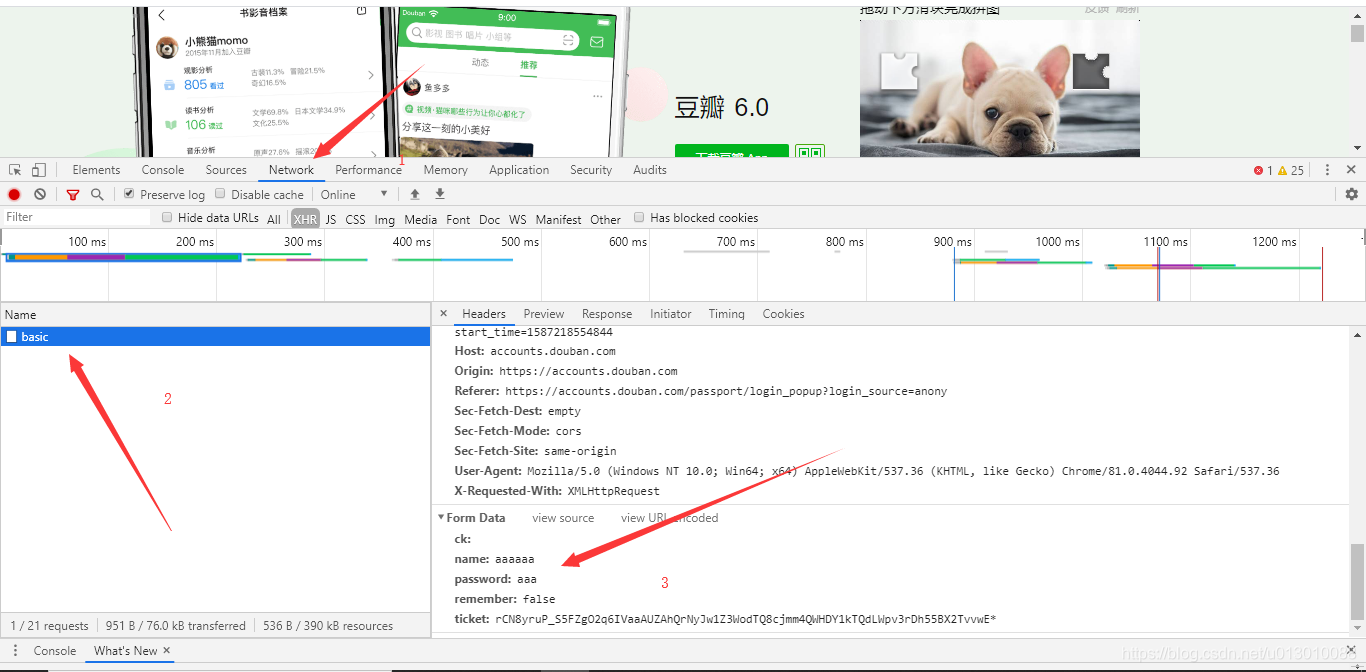
我们可以轻松的发现这是我们刚刚随机输入的账号密码包含在此处的参数中,往上翻,我们便可以拿到账号密码所提交给的后台地址,并且大家注意 下图中的Requests Method方法为POST
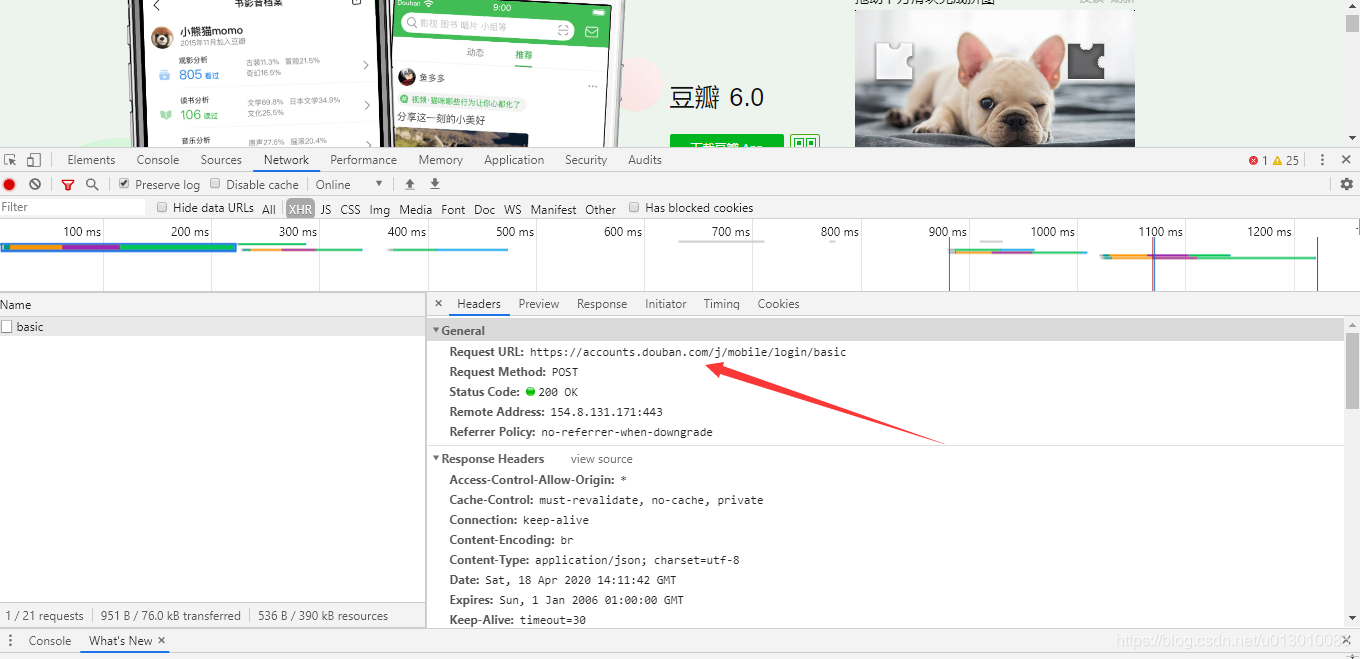
第三步:
我们先直接访问豆瓣网看看返回的网页源代码
import requests
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}#此处需要加入请求头,大家可以试一试不加会有什么不同的效果,请求头的作用主要是模拟浏览器访问
def get_html(url):
response = requests.get(url,headers=headers)#访问url,并添加请求头
return response.text
get_html('https://www.douban.com')
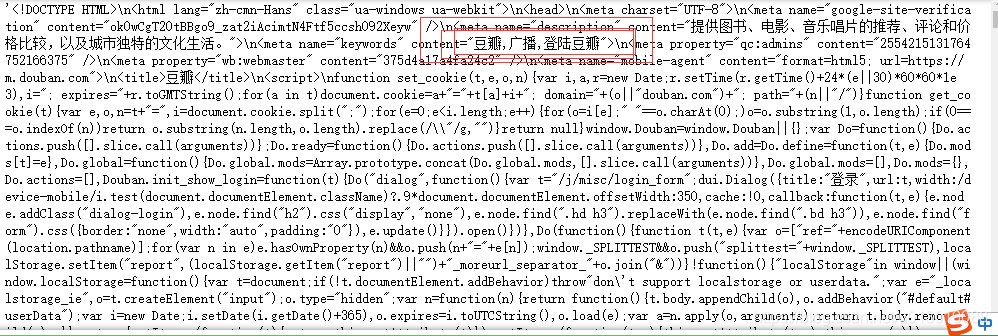
会发现图中框选处很明显是没有登录豆瓣网返回来的网址
第四步:
利用之前抓包获取到的登录的后台地址进行模拟登陆,并返回session保持会话
import requests
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
}#此处需要加入请求头,大家可以试一试不加会有什么不同的效果,请求头的作用主要是模拟浏览器访问
username = ''#输入自己的账号
password = ''#输入自己的密码
def login(url):
session = requests.session()#将session实例化
params={ #构造访问后台所需要的参数
'ck':'' ,
'name':username,#账号
'password': password,#密码
'remember': 'false',
'ticket': ''
}
session.post(url,data = params,headers = headers)#利用post方法向该地址发送请求,并将参数跟请求头一并加上
return session#返回得到的session
def get_html(url):
session = login('https://accounts.douban.com/j/mobile/login/basic') #获得login方法返回的session
response = session.get(url,headers=headers)#访问url,并添加请求头
return response.text
get_html('https://www.douban.com')#传入豆瓣网网址
登陆成功
版权声明:本文为u013010088原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。