一、k8s容器资源限制
Kubernetes采用request和limit两种限制类型来对资源进行分配。
- request(资源需求):即运行Pod的节点必须满足运行Pod的最基本需求才能运行Pod。
- limit(资源限额):即运行Pod期间,可能内存使用量会增加,那最多能使用多少内存,这就是资源限额
资源类型:
- CPU 的单位是核心数,内存的单位是字节。
- 一个容器申请0.5个CPU,就相当于申请1个CPU的一半,你也可以加个后缀m 表示千分之一的概念。比如说100m的CPU,100豪的CPU和0.1个CPU都是一样的。
内存单位:
- K、M、G、T、P、E #以1000为换算标准
- Ki、Mi、Gi、Ti、Pi、Ei #以1024为换算标准
内存限制示例:
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
spec:
containers:
- name: memory-demo
image: reg.harbor.com/library/stress
args:
- --vm
- "1"
- --vm-bytes
- 200M
resources:
requests:
memory: 50Mi
limits:
memory: 100Mikubectl create -f memory.yaml
kubectl get pod

如果容器超过其内存限制,则会被终止。如果可重新启动,则与所有其他类型的运行时故障一样,kubelet 将重新启动它。
如果一个容器超过其内存请求,那么当节点内存不足时,它的 Pod 可能被逐出。
CPU限制示例:
apiVersion: v1
kind: Pod
metadata:
name: cpu-demo
spec:
containers:
- name: cpu-demo
image: reg.harbor.com/library/stress
resources:
limits:
cpu: "10"
requests:
cpu: "5"
args:
- -c
- "2"kubectl create -f cpu.yaml
kubectl get pod
kubectl describe pod cpu-demo


调度失败是因为申请的CPU资源超出集群节点所能提供的资源但CPU使用率过高,不会被杀死
为namespace设置资源限制:
apiVersion: v1
kind: LimitRange
metadata:
name: limitrange-memory
spec:
limits:
- default:
cpu: 0.5
memory: 512Mi
defaultRequest:
cpu: 0.1
memory: 256Mi
max:
cpu: 1
memory: 1Gi
min:
cpu: 0.1
memory: 100Mi
type: Containerkubectl create -f limit.yaml
kubectl describe limitranges #LimitRange 在 namespace 中施加的最小和最大内存限制只有在创建和更新 Pod 时才会被应用。改变 LimitRange 不会对之前创建的 Pod 造成影响。

为namespace设置资源配额:
apiVersion: v1
kind: ResourceQuota
metadata:
name: mem-cpu-demo
spec:
hard:
requests.cpu: "1"
requests.memory: 1Gi
limits.cpu: "2"
limits.memory: 2Gi

创建的ResourceQuota对象将在default名字空间中添加以下限制:
- 每个容器必须设置内存请求(memory request),内存限额(memory limit),cpu请求(cpu request)和cpu限额(cpu limit)。
- 所有容器的内存请求总额不得超过1 GiB。
- 所有容器的内存限额总额不得超过2 GiB。
- 所有容器的CPU请求总额不得超过1 CPU。
- 所有容器的CPU限额总额不得超过2 CPU。
为 Namespace 配置Pod配额:
apiVersion: v1
kind: ResourceQuota
metadata:
name: pod-demo
spec:
hard:
pods: "2"设置Pod配额以限制可以在namespace中运行的Pod数量。

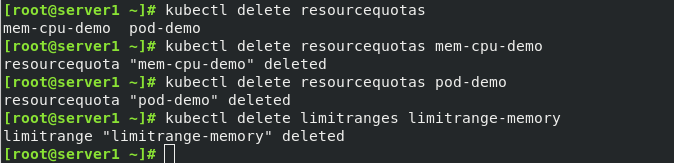
最后删除刚才的配置
二、kubernetes资源监控
1. Metrics-Server部署
Metrics-Server是集群核心监控数据的聚合器,用来替换之前的heapster
容器相关的 Metrics 主要来自于 kubelet 内置的 cAdvisor 服务,有了Metrics-Server之后,用户就可以通过标准的 Kubernetes API 来访问到这些监控数据。
- Metrics API 只可以查询当前的度量数据,并不保存历史数据。
- Metrics API URI 为 /apis/metrics.k8s.io/,在 k8s.io/metrics 维护。
- 必须部署 metrics-server 才能使用该 API,metrics-server 通过调用 Kubelet SummaryAPI 获取数据
示例:
- http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes
- http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/nodes/<node-name>
- http://127.0.0.1:8001/apis/metrics.k8s.io/v1beta1/namespace/<namespace-name>/pods/<pod-name>
Metrics Server 并不是 kube-apiserver 的一部分,而是通过 Aggregator 这种插件机制,在独立部署的情况下同 kube-apiserver 一起统一对外服务的。
kube-aggregator 其实就是一个根据 URL 选择具体的 API 后端的代理服务器。

Metrics-server属于Core metrics(核心指标),提供API metrics.k8s.io,仅提供Node和Pod的CPU和内存使用情况。而其他Custom Metrics(自定义指标)由Prometheus等组件来完成。
资源下载:
https://github.com/kubernetes-incubator/metrics-server
Metrics-server部署:
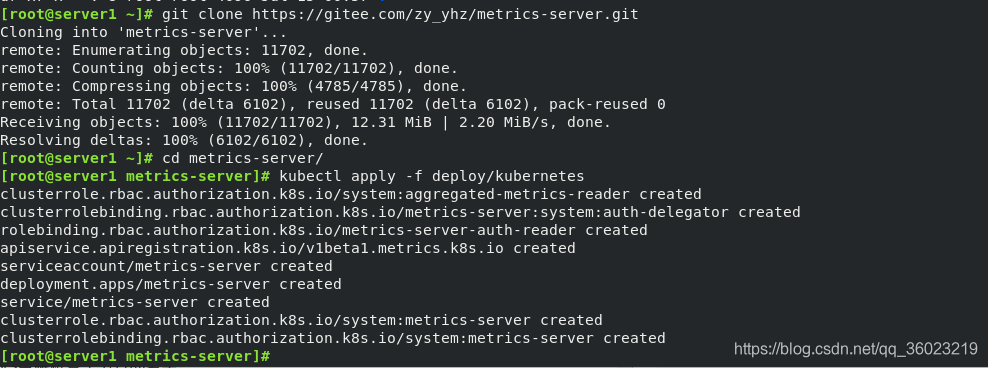
git clone https://github.com/kubernetes-incubator/metrics-server
##因为太慢,我用了码云加速 git clone https://gitee.com/zy_yhz/metrics-server.git
cd metrics-server
kubectl apply -f deploy/kubernetes
这时候查看pod发现出现问题
kubectl -n kube-system describe pods metrics-server-75d4fff9f-vv7gn

因为网络原因,拉取镜像失败
解决:从阿里云手动拉取,重新tag
docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.6
docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.6 k8s.gcr.io/metrics-server-amd64:v0.3.6
docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/metrics-server-amd64:v0.3.6

因为刚才是部署在server2的,我是在server1拉取的,在这里打包发送给server2(可以直接server2拉取)
docker save -o metrics-server-amd64.tar k8s.gcr.io/metrics-server-amd64
scp metrics-server-amd64.tar root@server2:/mnt

server2节点load
docker load < /mnt/metrics-server-amd64.tar

kubectl -n kube-system get deployment ##查看pod

部署后查看Metrics-server的Pod日志:
错误1:
dial tcp: lookup server2 on 10.96.0.10:53: no such host
这是因为没有内网的DNS服务器,所以metrics-server无法解析节点名字。可以直接修改coredns的configmap,将各个节点的主机名加入到hosts中,这样所有Pod都可以从CoreDNS中解析各个节点的名字。
解决:
kubectl edit configmap coredns -n kube-system

![]()
报错2:
x509: certificate signed by unknown authority
Metric Server 支持一个参数 –kubelet-insecure-tls,可以跳过这一检查,然而官方也明确说了,这种方式不推荐生产使用。
解决:
启用TLS Bootstrap 证书签发
vim /var/lib/kubelet/config.yaml...
serverTLSBootstrap: true ##该设置打开systemctl restart kubelet
kubectl get csr
kubectl certificate approve csr-n9pvr

报错3:
Error from server (ServiceUnavailable): the server is currently unable to handle the request (get nodes.metrics.k8s.io)
如果metrics-server正常启动,没有错误,一般为网络问题。修改metrics-server的Pod 网络模式:
hostNetwork: true

错误4:
v1beta1.metrics.k8s.io kube-system/metrics-server False (FailedDiscoveryCheck) 9s
修改deployment重新部署
1 ---
2 apiVersion: v1
3 kind: ServiceAccount
4 metadata:
5 name: metrics-server
6 namespace: kube-system
7 ---
8 apiVersion: apps/v1
9 kind: Deployment
10 metadata:
11 name: metrics-server
12 namespace: kube-system
13 labels:
14 k8s-app: metrics-server
15 spec:
16 selector:
17 matchLabels:
18 k8s-app: metrics-server
19 template:
20 metadata:
21 name: metrics-server
22 labels:
23 k8s-app: metrics-server
24 spec:
25 serviceAccountName: metrics-server
26 volumes:
27 - name: tmp-dir
28 emptyDir: {}
29 hostNetwork: true
30 containers:
31 - name: metrics-server
32 image: reg.harbor.com/library/metrics-server-amd64
33 imagePullPolicy: IfNotPresent
34 args:
35 - /metrics-server
36 - --kubelet-preferred-address-types=InternalIP
37 - --kubelet-insecure-tls ##为了方便测试我这里直跳过安全tls,推荐配置相关证书
38 - --cert-dir=/tmp
39 - --secure-port=4443
40 ports:
41 - name: main-port
42 containerPort: 4443
43 protocol: TCP
44 securityContext:
45 readOnlyRootFilesystem: true
46 runAsNonRoot: true
47 runAsUser: 1000
48 volumeMounts:
49 - name: tmp-dir
50 mountPath: /tmp
51 nodeSelector:
52 kubernetes.io/os: linux
53 kubernetes.io/arch: "amd64"
部署成功后
kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes/server1"

kubectl top node


2. Dashboard部署
Dashboard可以给用户提供一个可视化的 Web 界面来查看当前集群的各种信息。用户可以用 Kubernetes Dashboard 部署容器化的应用、监控应用的状态、执行故障排查任务以及管理 Kubernetes 各种资源。
网址:
https://github.com/kubernetes/dashboard
下载部署文件:
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0-rc5/aio/deploy/recommended.yaml
kubectl -n kubernetes-dashboard get svc #修改为NodePort方式,以便外部访问。登陆dashboard需要认证,需要获取dashboard pod的token:
kubectl describe secrets kubernetes-dashboard-token-g2g6g -n kubernetes-dashboard

默认dashboard对集群没有操作权限,需要授权:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard-admin
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboardDashboard如果无法展示metrics-server的数据指标,可以通过以下两种方式解决:
- 修改dashboard-metrics-scraper 的Pod网络模式: hostNetwork: true
- 通过node或pod的亲和性设置,让dashboard-metrics-scraper和metrics-server的Pod处于同一个node节点。
三、HPA
官网:
https://kubernetes.io/zh/docs/tasks/run-application/horizontal-pod-autoscale- walkthrough/
运行deployment 服务:
kubectl run hpa-example --image=hpa-example --requests=cpu=200m --expose --port=80
kubectl get deployments.apps
kubectl autoscale deployment hpa-example --cpu-percent=50 --min=1 --max=10
kubectl get hpa
kubectl get svc hpa-example
kubectl run test -it --rm --image=busybox --restart=Never
kubectl get hpaHPA伸缩过程:
- 收集HPA控制下所有Pod最近的cpu使用情况(CPU utilization)
- 对比在扩容条件里记录的cpu限额(CPUUtilization)
- 调整实例数(必须要满足不超过
- 每隔30s做一次自动扩容的判断
CPU utilization的计算方法是用cpu usage(最近一分钟的平均值,通过metrics可以直接获取到)除以cpu request(这里cpu request就是我们在创建容器时制定的cpu使用核心数)得到一个平均值,这个平均值可以理解为:平均每个Pod CPU核心的使用占比
HPA进行伸缩算法:
- 计算公式:TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target)
- ceil()表示取大于或等于某数的最近一个整数
- 每次扩容后冷却3分钟才能再次进行扩容,而缩容则要等5分钟后。
-
当前Pod Cpu使用率与目标使用率接近时,不会触发扩容或缩容:
触发条件:avg(CurrentPodsConsumption) / Target >1.1 或 <0.9
HPAv2
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: hpa-example
spec:
maxReplicas: 10
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: hpa-example
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 60
type: Utilization
- type: Resource
resource:
name: memory
target:
averageValue: 50Mi
type: AverageValue