在新生代的复制算法中将除新生代的Eden区域以外的内存空间一分为二,分别称为S0区和S2区
S0和s1将可用内存按容量分成大小相等的两块,每次只使用其中一块,当这块内存使用完了,就将还存活的对象复制到另一块内存上去,然后把使用过的内存空间一次清理掉。这样使得每次都是对其中一块内存进行回收,内存分配时不用考虑内存碎片等复杂情况,只需要移动堆顶指针,按顺序分配内存即可,实现简单,运行高效。
复制算法的缺点显而易见,可使用的内存降为原来一半。
一个简单的例子
下图为一个堆,左边的是新生代,右边的是老年代
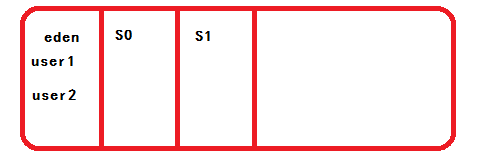
此时从eden区存在两个对象user1和user2,经过GC的观察,发现这两个对象都经常使用,因此将这两个对象转出
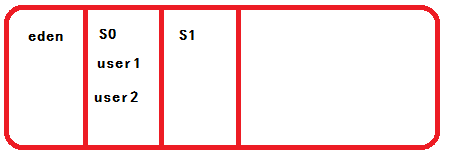
User1和use2进入到S0区,第一次数据转入是随机的,第一次转入可能转到S0区,也可能转到S1区
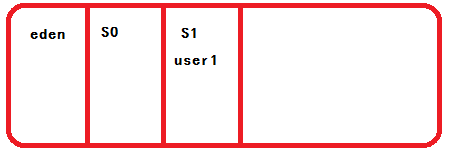
又经过GC的考察,发现user1经常被使用,所以将user1复制到S1区,同时清空S0区
同一时刻,S0和S1区只能有一个区存在数据,另一个区一定是空的
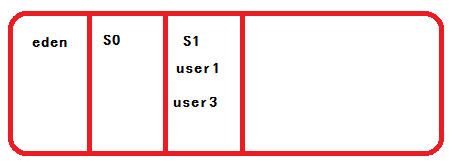
此时又添加了一个新的对象user3,user3一定会存到S1中
经过GC的考验,user1经常被使用,所以将user复制到S0区,同时清空S1区,数据会在S0和S1之间不断循环,
当某一个数据经过了18次GC筛选仍然存活,就将其转到老年代
版权声明:本文为qq_41012446原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。