问题描述:
strict=False 但还是size mismatch for []: copying a param with shape [] from checkpoint,the shape in cur []
接着
(6条消息) Deformable DETR环境配置和应用_Alaso_soso的博客-CSDN博客_deformable detr
上面的链接进行继续写,发现很多人同样也遇到了,我遇到的这个问题,找到了解决方案,记录一下,或许也可以解决在训练自己的模型的时候出现的size问题不匹配的问题.
背景:
前期只是用官方给的完整的deformable detr 模型进行预测的,因此没有出现size不匹配的问题,后面报了一大堆类似一下的错误,网上的有的人用pop解决了问题,然而我却不ok,这次使用的预训练模型是r50_deformable_detr_single_scale-checkpoint.pth:
size mismatch for transformer.level_embed: copying a param with shape torch.Size([1, 256]) from checkpoint torch.Size([64, 256])
解决方案:
首先定位到detect.py文件:detect.py参考链接,修改model_path,以为可以直接运行,结果gg了:
model_path = './r50_deformable_detr_single_scale-checkpoint.pth'
Deformable-DETR部署和体验 – 简书 (jianshu.com)
在定位到load_model方法:
def load_model(model_path, args):
model, _, _ = build_model(args)
model.cuda()
model.eval()
ckpt=state_dict = torch.load(model_path) # <-----------修改加载模型的路径
msg=model.load_state_dict(state_dict["model"],strict=False)
model.to(device)
print("load model sucess")
return model在定位到 model, _, _ = build_model(args),这一句创建模型代码上:
def build_model(args):
return build(args)在定位到build(args)这里
def build(args):
# 类别个数
# num_class = 20
# num_classes = 20 if args.dataset_file != 'coco' else (num_class + 1)
num_classes = 20 if args.dataset_file != 'coco' else 91
if args.dataset_file == "coco_panoptic":
num_classes = 250
device = torch.device(args.device)
backbone = build_backbone(args)
transformer = build_deforamble_transformer(args)
model = DeformableDETR(
backbone,
transformer,
num_classes=num_classes,
num_queries=args.num_queries,
num_feature_levels=args.num_feature_levels,
aux_loss=args.aux_loss,
with_box_refine=args.with_box_refine,
two_stage=args.two_stage,
)
if args.masks:
model = DETRsegm(model, freeze_detr=(args.frozen_weights is not None))
matcher = build_matcher(args)
weight_dict = {'loss_ce': args.cls_loss_coef, 'loss_bbox': args.bbox_loss_coef}
weight_dict['loss_giou'] = args.giou_loss_coef
if args.masks:
weight_dict["loss_mask"] = args.mask_loss_coef
weight_dict["loss_dice"] = args.dice_loss_coef
# TODO this is a hack
if args.aux_loss:
aux_weight_dict = {}
for i in range(args.dec_layers - 1):
aux_weight_dict.update({k + f'_{i}': v for k, v in weight_dict.items()})
aux_weight_dict.update({k + f'_enc': v for k, v in weight_dict.items()})
weight_dict.update(aux_weight_dict)
losses = ['labels', 'boxes', 'cardinality']
if args.masks:
losses += ["masks"]
# num_classes, matcher, weight_dict, losses, focal_alpha=0.25
criterion = SetCriterion(num_classes, matcher, weight_dict, losses, focal_alpha=args.focal_alpha)
criterion.to(device)
postprocessors = {'bbox': PostProcess()}
if args.masks:
postprocessors['segm'] = PostProcessSegm()
if args.dataset_file == "coco_panoptic":
is_thing_map = {i: i <= 90 for i in range(201)}
postprocessors["panoptic"] = PostProcessPanoptic(is_thing_map, threshold=0.85)
return model, criterion, postprocessors
根据自己的类别修改num_classes,args是参数配置,此时就定位到configs文件夹下对应的.sh文件了。
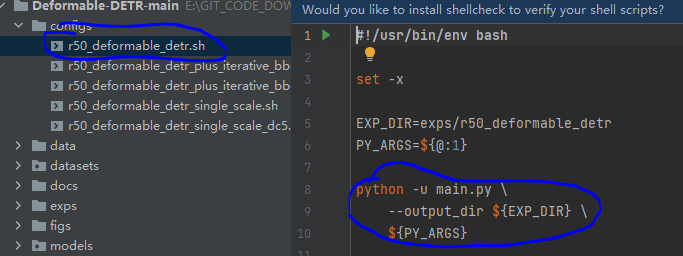
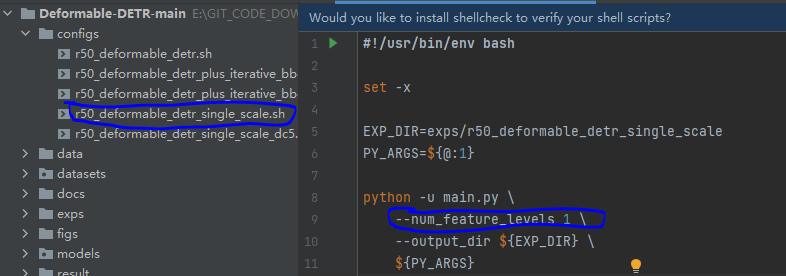
注意到这两个配置文件的区别在于
–num_feature_levels 1
,问题就出在这里,需要在运行detect.py文件的时候添加上这个配置参数。
python detect.py --num_feature_levels 1这里就结束了,可以正常运行,进行图片视频的预测了。
![]()
感谢某人的帮助捏。*★,°*:.☆( ̄▽ ̄)/$:*.°★* 。