熟悉pandas的人应该都会发现,通过groupby聚合出来的结果,通常含有“层级索引”。通俗地说,即按照索引的优先级顺序,把索引按相同层级地合并同类项(个人的理解与语言表达可能不太恰当,见谅),最后的结果,如果输出到Excel中,即可发现,同一级索引中,相同的内容会被合并到一起(可以简单理解成“合并单元格”)。但是,有时候我们并不需要这些层级索引,因为我们之后有可能还会涉及到二次计算,或者需要以DataFrame的形式来展示数据。
今天闲来无事,于是上网搜索了一下相关的文章,想学点新知识。无意中发现除了用 .reser_index() 外,还有其它的方法。于是试验了一下,就写下这篇文章。
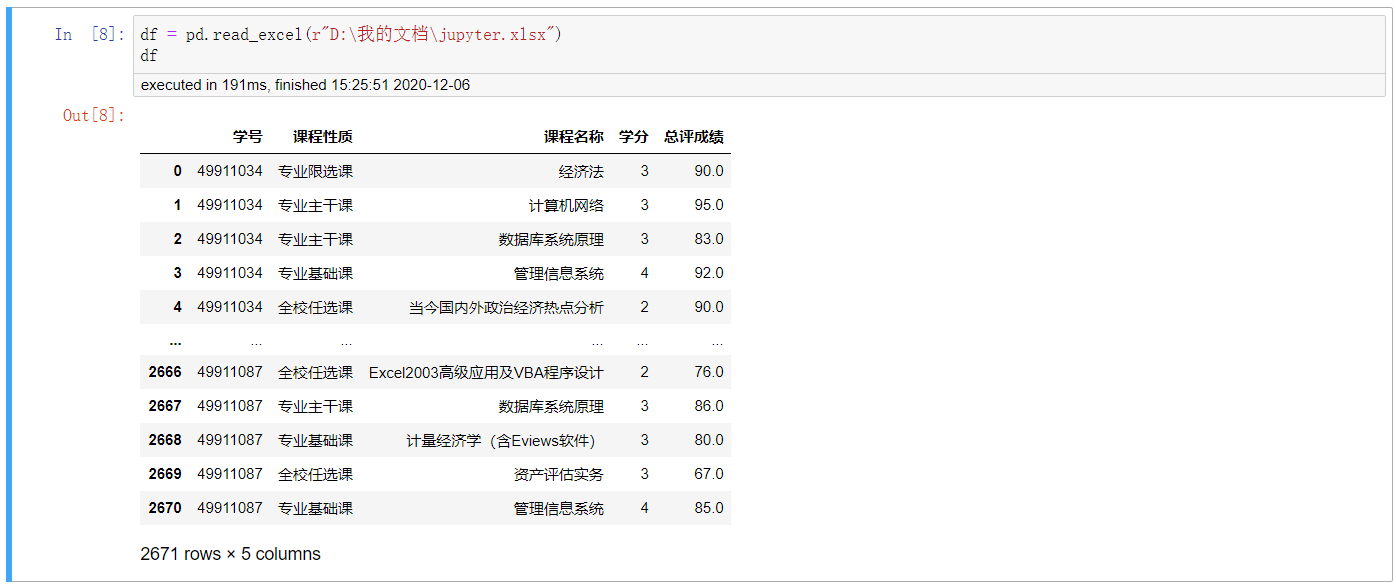
1. 先加载数据
df = pd.read_excel(r”D:\我的文档\jupyter.xlsx”)
df
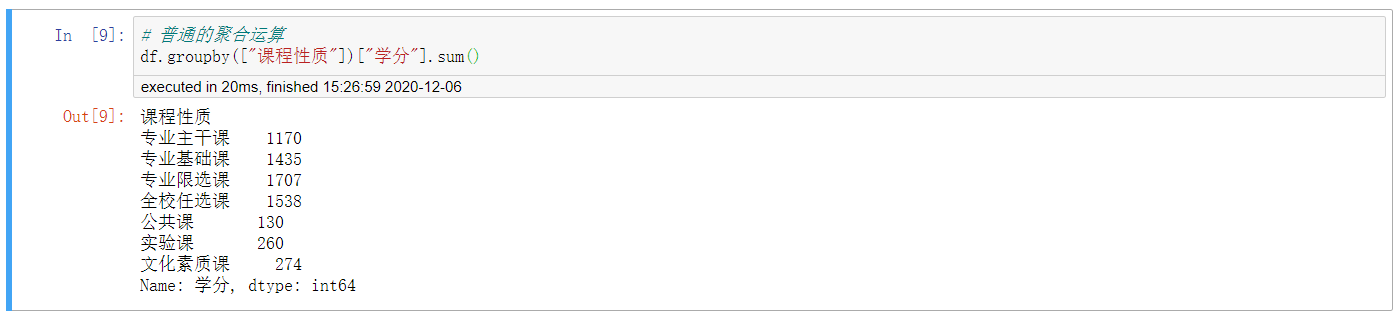
2. 常规的聚合运算
# 普通的聚合运算
df.groupby([“课程性质”])[“学分”].sum()
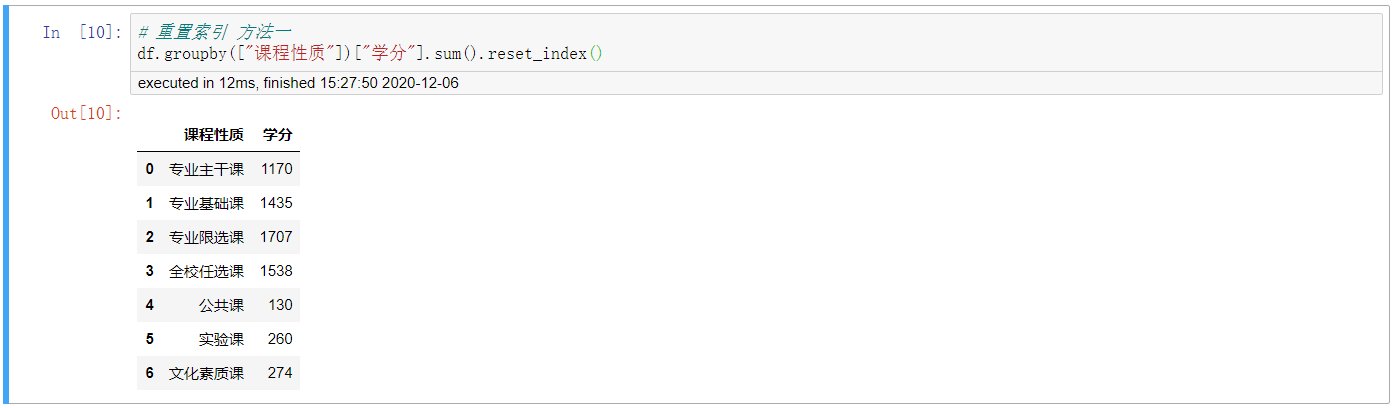
3. 重置索引 方法一
# 重置索引 方法一
df.groupby([“课程性质”])[“学分”].sum().reset_index()
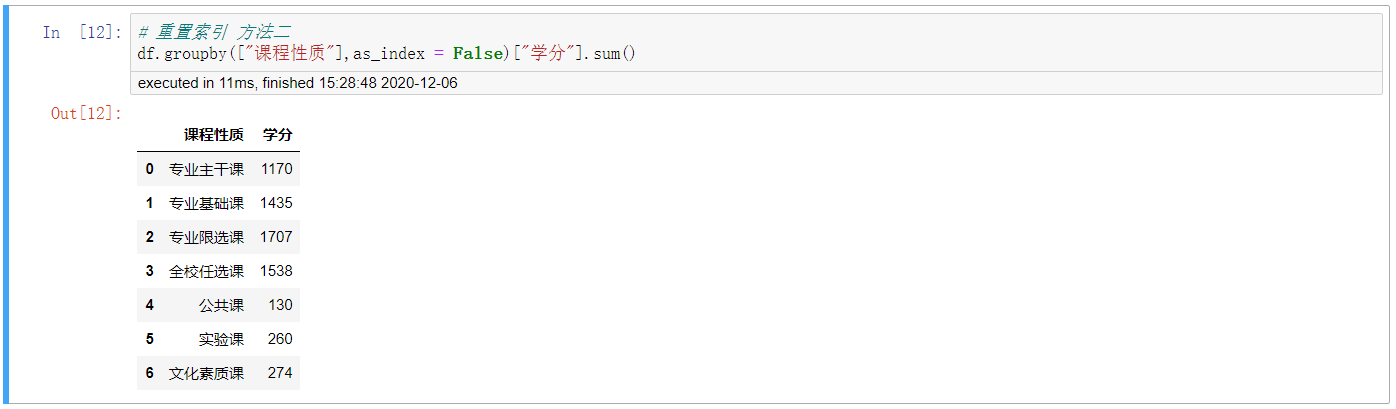
4. 重置索引 方法二
# 重置索引 方法二
df.groupby([“课程性质”],as_index = False)[“学分”].sum()
如果看不清楚,请在看下面:
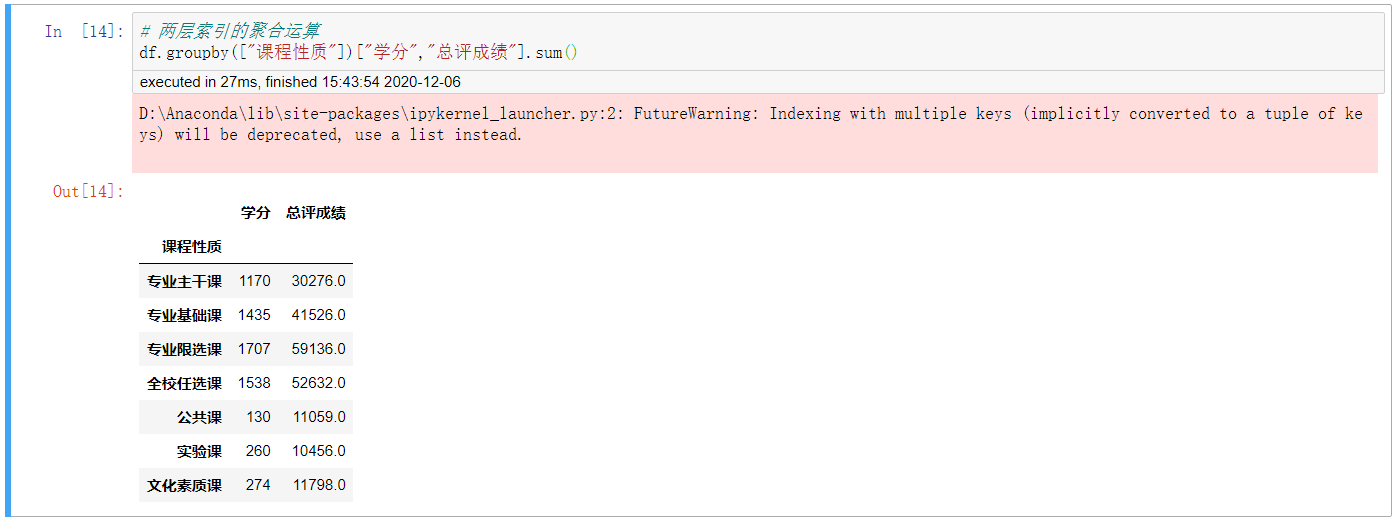
5. 带两组变元(下面的两层索引纯属笔误,但懒得改了)的聚合运算
# 两层索引的聚合运算
df.groupby([“课程性质”])[“学分”,”总评成绩”].sum()
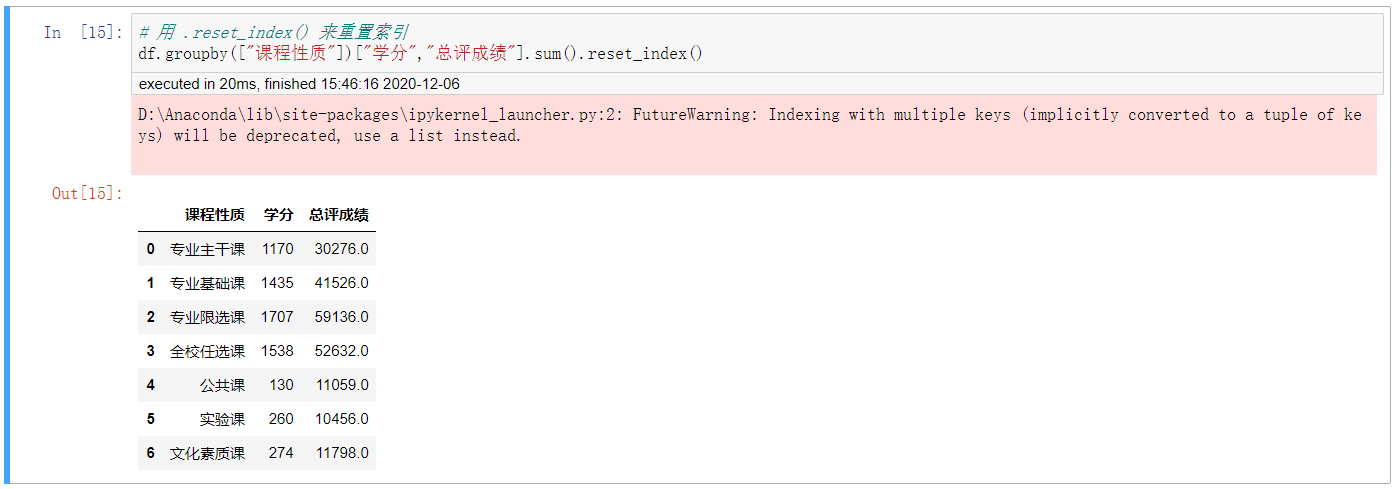
6. 用 .reset_index() 来重置索引
# 用 .reset_index() 来重置索引
df.groupby([“课程性质”])[“学分”,”总评成绩”].sum().reset_index()
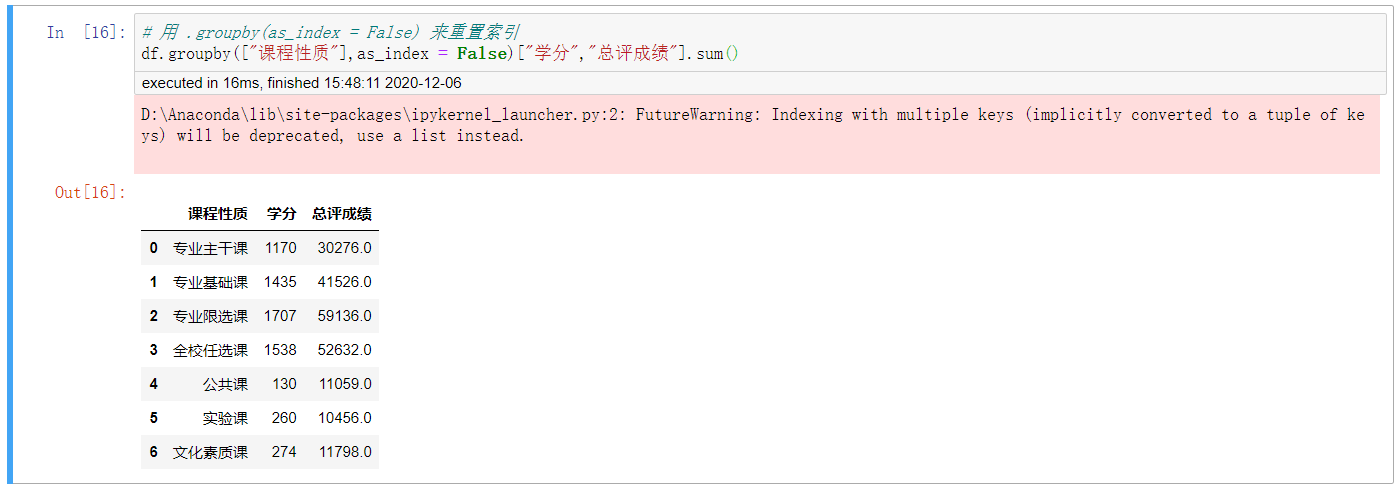
7. 用 .groupby(as_index = False)来重置索引
# 用 .groupby(as_index = False) 来重置索引
df.groupby([“课程性质”],as_index = False)[“学分”,”总评成绩”].sum()
小结:可见,在Python中的解题实现方法,有可能不只一种的。