背景
在seq2seq中,一般是有一个encoder 一个decoder ,一般是rnn/cnn 但是rnn 计算缓慢,所以提出了纯用注意力机制来实现编码解码。
模型结构
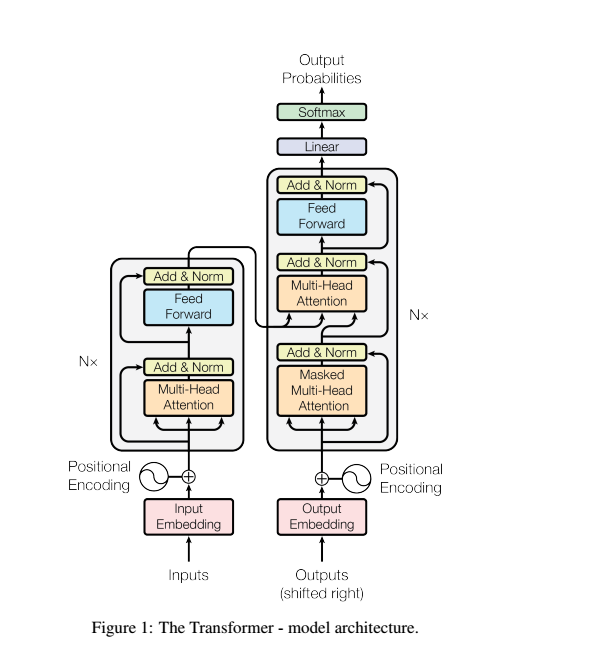
大部分神经序列转导模型都有一个编码器-解码器结构。
这里,编码器映射一个用符号表示的输入序列
(
x
1
,…,x
n
)
到一个连续的表示
z
= (
z
1
,…,z
n
)。
根据
z,解码器生成符号的一个输出序列
(
y
1
,…,y
m
)
,
一次一个元素。
当生成下一个时,消耗先前生成的符号作为附加输入。
Encoder and Decoder Stack
Encoder
6个完全相同的层组成,每层包含2个sub层,分别是
multi-head self-attention mechanism 、
position wise fully connected feed-forward network.
用residual connection 连接2个sub层,再加入normalization.所以最后每层的输出是
每个子层的输出是
LayerNorm
(
x
+
Sublayer
(
x
)),其中
Sublayer
(
x
)
是由子层本身实现的函数。
为了方便这些残差连接,模型中的所有子层以及嵌入层产生的输出维度都为
dmodel
= 512。
decoder
解码器同样由
N
= 6 个完全相同的层堆叠而成。
除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该层对编码器堆栈的输出执行multi-head attention。
与编码器类似,我们在每个子层再采用残差连接,然后进行层标准化。
我们还修改解码器堆栈中的self-attention子层,以防止位置关注到后面的位置。
这种掩码结合将输出嵌入偏移一个位置,确保对位置的预测
i
只能依赖小于
i 的已知输出。
Attention
Attention函数可以描述为将query和一组key-value对映射到输出,其中query、key、value和输出都是向量。
输出为value的加权和,其中分配给每个value的权重通过query与相应key的兼容函数来计算。
query 与key 的match 度得到权重,权重加在val 上 ,val加权和是输出。
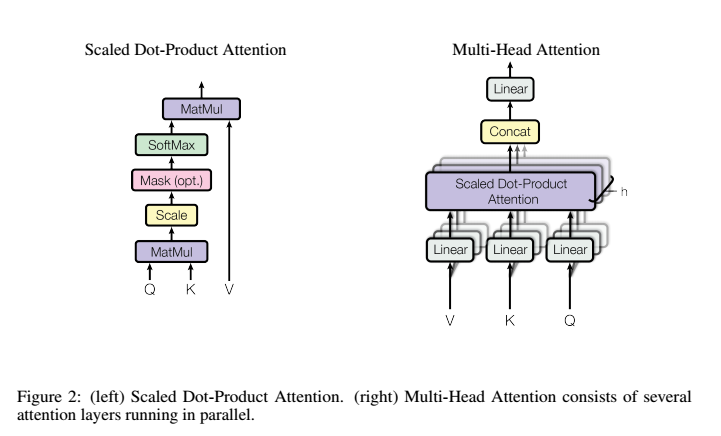
3.2.1
Scaled Dot-Product Attention
输入由query、
d
k
维的key和
d
v
维的value组成。
我们计算query和所有key的点积、用
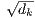
相除,然后应用一个softmax函数以获得值的权重。
在实践中,我们同时计算一组query的attention函数,并将它们组合成一个矩阵
Q。
key和value也一起打包成矩阵
K
和
V
。
我们计算输出矩阵为:
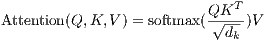 |
(1) |
两个最常用的attention函数是加法attention和点积(乘法)attention。
除了缩放因子
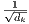
之外,点积attention与我们的算法相同。
加法attention使用具有单个隐藏层的前馈网络计算兼容性函数。
虽然两者在理论上的复杂性相似,但在实践中点积attention的速度更快、更节省空间,因为它可以使用高度优化的矩阵乘法代码来实现。
当
d
k
的值比较小的时候,这两个机制的性能相差相近,当
d
k
比较大时,加法attention比不带缩放的点积attention性能好。
我们怀疑,对于很大的
d
k
值,点积大幅度增长,将softmax函数推向具有极小梯度的区域
4
。
为了抵消这种影响,我们缩小点积
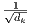
倍。
3.2.2
Multi-Head Attention
我们发现将query、key和value分别用不同的、学到的线性映射
h次到
d
k
、
d
k
和
d
v
维效果更好,而不是用
d model维的query、key和value执行单个attention函数。
基于每个映射版本的query、key和value,我们并行执行attention函数,产生
d
v
维输出值。
将它们连接并再次映射,产生最终值,如图所示
2
。
Multi-head attention允许模型的不同表示子空间联合关注不同位置的信息。
如果只有一个attention head,它的平均值会削弱这个信息。

在这项工作中,我们采用
h
= 8 个并行attention层或head。
对每个head,我们使用
d
k
=
d
v
=
dmodel
∕ h
= 64。
由于每个head的大小减小,总的计算成本与具有全部维度的单个head attention相似。
其中,映射为参数矩阵
W
i
Q
∈
ℝ
dmodel
×
d
k
,
W
i
K
∈
ℝ
dmodel
×
d
k
,
W
i
V
∈
ℝ
dmodel
×
d
v
及
W
O
∈
ℝ
hd
v
×
dmodel
。
3.2.3 Applications of Attention in our Model
Transformer使用以3种方式使用multi-head attention:
-
在“编码器—解码器attention”层,query来自前一个解码器层,key和value来自编码器的输出。
这允许解码器中的每个位置能关注到输入序列中的所有位置。
这模仿序列到序列模型中典型的编码器—解码器的attention机制,例如[
38
,
2
,
9
]。
-
编码器包含self-attention层。
在self-attention层中,所有的key、value和query来自同一个地方,在这里是编码器中前一层的输出。
编码器中的每个位置都可以关注编码器上一层的所有位置。
-
类似地,解码器中的self-attention层允许解码器中的每个位置都关注解码器中直到并包括该位置的所有位置。
我们需要防止解码器中的向左信息流来保持自回归属性。
通过屏蔽softmax的输入中所有不合法连接的值(设置为
-∞),我们在缩放版的点积attention中实现。
见图
2
.
3.3 Position-wise Feed-Forward Networks
除了attention子层之外,我们的编码器和解码器中的每个层都包含一个完全连接的前馈网络,
该前馈网络单独且相同地应用于每个位置
。
它由两个线性变换组成,之间有一个ReLU激活。
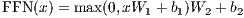 |
(2) |
尽管线性变换在不同位置上是相同的,但它们层与层之间使用不同的参数。
它的另一种描述方式是两个内核大小为1的卷积。
输入和输出的维度为
dmodel
= 512,内部层的维度为
d
ff
= 2048。
3.4 Embeddings and Softmax
与其他序列转导模型类似,我们使用学习到的嵌入将输入词符和输出词符转换为维度为
dmodel的向量。
我们还使用普通的线性变换和softmax函数将解码器输出转换为预测的下一个词符的概率。
在我们的模型中,两个嵌入层之间和pre-softmax线性变换共享相同的权重矩阵,类似于[
30
]。
在嵌入层中,我们将这些权重乘以
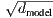
。
3.5 Positional Encoding
由于我们的模型不包含循环和卷积,为了让模型利用序列的顺序,我们必须注入序列中关于词符相对或者绝对位置的一些信息。
为此,我们将“位置编码”添加到编码器和解码器堆栈底部的输入嵌入中。
位置编码和嵌入的维度
dmodel相同,所以它们俩可以相加。
有多种位置编码可以选择,例如通过学习得到的位置编码和固定的位置编码[
9
]。
在这项工作中,我们使用不同频率的正弦和余弦函数:
|
PE ( pos, 2 i ) = sin ( pos ∕ 10000 2 i ∕ dmodel ) |
||
|
PE ( pos, 2 i +1) = cos ( pos ∕ 10000 2 i ∕ dmodel ) |
其中
pos 是位置,
i 是维度。
也就是说,位置编码的每个维度对应于一个正弦曲线。
这些波长形成一个几何级数,从
2
π 到
10000
⋅
2
π。
我们选择这个函数是因为我们假设它允许模型很容易学习对相对位置的关注,因为对任意确定的偏移
k,
PE
pos
+
k
可以表示为
PE
pos
的线性函数。
我们还使用学习到的位置嵌入
9
进行了试验,发现这两个版本产生几乎相同的结果(参见表
3
行(E))。
我们选择了正弦曲线,因为它可以允许模型推断比训练期间遇到的更长的序列。
每个位置对应一个向量,不可训练的。
对于每个句子,位置向量是相同的。
参考:
https://www.yiyibooks.cn/yiyibooks/Attention_Is_All_You_Need/index.html
https://www.jianshu.com/p/3f2d4bc126e6
转载于:https://www.cnblogs.com/zle1992/p/9752742.html