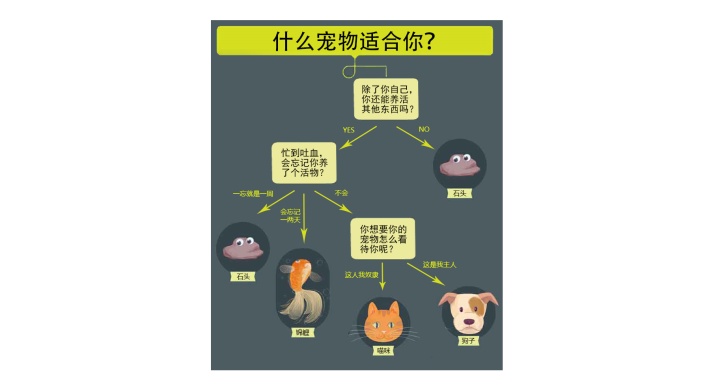
一天,小迪与小西想养一只宠物。
小西:小迪小迪,好想养一只宠物呀,但是不知道养那种宠物比较合适。
小迪:好呀,养只宠物会给我们的生活带来很多乐趣呢。不过养什么宠物可要考虑好,这可不能马虎。我们需要考虑一些比较重要的问题。
小西:我也考虑了好多呀,可是还是很难去选择。我想养可爱的小兔兔,可是兔兔吃得很挑剔,又想养狗狗,可是狗狗每天都需要遛它,怕自己没有时间呀。
小迪:其实我们可以绘制一个决策树,决策树是机器学习中做判断的常用模型。原理也非常简单。
小西:决策树是什么,怎么能帮助我们作出决策呢?
小迪:别着急,听我,慢慢道来~
一、概述
决策树(Decision Tree)是有监督学习中的一种算法,并且是一种基本的分类与回归的方法。也就是说,决策树有两种:分类树和回归树。这里我们主要讨论分类树。
决策树算法的本质就是树形结构,只需要有一些设计好的问题,就可以对数据进行分类了。在这里,我们需要了解三个概念:

我们可以把决策树看作是一个if-then规则的集合。将决策树转换成if-then规则的过程是这样的:
- 由决策树的根节点到叶节点的每一条路径构建一条规则
- 路径上中间节点的特征对应着规则的条件,也叶节点的类标签对应着规则的结论
决策树的路径或者其对应的if-then规则集合有一个重要的性质:互斥并且完备。也就是说,每一个实例都被
有且仅有一条
路径或者规则所覆盖。这里的覆盖是指实例的特征与路径上的特征一致,或实例满足规则的条件。
二、决策树的构建准备工作
使用决策树做分类的每一个步骤都很重要,首先要收集足够多的数据,如果数据收集不到位,将会导致没有足够的特征去构建错误率低的决策树。数据特征充足,但是不知道用哪些特征好,也会导致最终无法构建出分类效果好的决策树。
决策树构建过程可以概括为3个步骤:特征选择、决策树的生成和决策树的剪枝。
1.特征选择
特征选择就是决定用哪个特征来划分特征空间,其目的在于选取对训练数据具有分类能力的特征。这样可以提高决策树学习的效率。如果利用一个特征进行分类的结果与随机分类的结果没有很大的差别,则称这个特征是没有分类能力的,经验上扔掉这些特征对决策树学习的精度影响不会很大。
那如何来选择最优的特征来划分呢?一般而言,随着划分过程不断进行,我们希望决策树的分支节点所包含的样本尽可能属于同一类别,也就是节点的
纯度
(purity)越来越高。
下面三个图表示的是纯度越来越低的过程,最后一个表示的是三幅图中纯度最低的状态。
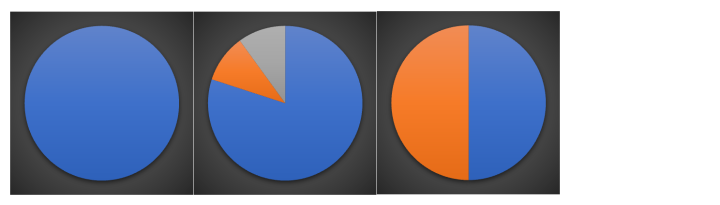
在实际使用中,我们衡量的常常是不纯度。度量不纯度的指标有很多种,比如:熵、增益率、基尼值数。
这里我们使用的是熵,也叫作
香农熵
,这个名字来源于信息论之父 克劳德·香农。
1.1 香农熵及计算函数
熵定义为信息的期望值。在信息论与概率统计中,熵是表示随机变量不确定性的度量。

香农熵的python代码如下:
"""
我们以海洋生物数据为例,构建数据集,并计算其香农熵
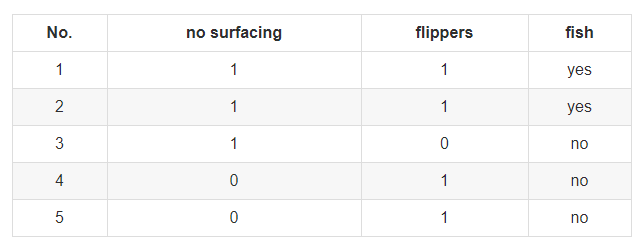
表1 海洋生物数据
#创建数据集
熵越高,信息的不纯度就越高。也就是混合的数据就越多。
1.2 信息增益
信息增益
(Information Gain)的计算公式其实就是父节点的信息熵与其下所有子节点总信息熵之差。但这里要注意的是,此时计算子节点的总信息熵不能简单求和,而要求在求和汇总之前进行修正。

a用同样的方法,把第1列的信息增益也算出来,结果为0.17
2. 数据集最佳切分函数
划分数据集的最大准则是选择
最大信息增益
,也就是信息下降最快的方向。
"""
通过上面手动计算,可以得出:
第0列的信息增益为0.42,第1列的信息增益为0.17,0.42>0.17,所以应该选择第0列进行切分数据集。
接下来,我们来验证我们构造的数据集最佳切分函数返回的结果与手动计算的结果是否一致。
bestSplit
3. 按照给定列切分数据集
通过最佳切分函数返回最佳切分列的索引,可以根据这个索引,构建一个按照给定列切分数据集的函数
"""
验证函数,以axis=0,value=1为例
mySplit
三、递归构建决策树
目前我们已经学习了从数据集构造决策树算法所需要的子功能模块,其工作原理如下:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分之后,数据集被向下传递到树的分支的下一个结点。在这个结点上,我们可以再次划分数据。因此我们可以采用递归的原则处理数据集。
决策树生成算法递归地产生决策树,直到不能继续下去未为止。这样产生的树往往对训练数据的分类很准确,但对未知的测试数据的分类却没有那么准确,即出现过拟合现象。过拟合的原因在于学习时过多地考虑如何提高对训练数据的正确分类,从而构建出过于复杂的决策树。解决这个问题的办法是考虑决策树的复杂度,对已生成的决策树进行简化,也就是常说的剪枝处理。剪枝处理的具体讲解我会放在回归树里面。
1. ID3算法
构建决策树的算法有很多,比如ID3、C4.5和CART,这里我们选择ID3算法。
ID3算法的核心是在决策树各个节点上对应信息增益准则选择特征,递归地构建决策树。具体方法是:从根节点开始,对节点计算所有可能的特征的信息增益,选择信息增益最大的特征作为节点的特征,由该特征的不同取值建立子节点;再对子节点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止。最后得到一个决策树。
递归结束的条件是:程序遍历完所有的特征列,或者每个分支下的所有实例都具有相同的分类。如果所有实例具有相同分类,则得到一个叶节点。任何到达叶节点的数据必然属于叶节点的分类,即叶节点里面必须是标签。
2. 编写代码构建决策树
"""
查看函数运行结果
myTree
四、决策树的存储
构造决策树是很耗时的任务,即使处理很小的数据集,也要花费几秒的时间,如果数据集很大,将会耗费很多计算时间。因此为了节省时间,建好树之后立马将其保存,后续使用直接调用即可。
这里使用的是numpy里面的save()函数,它可以直接把字典形式的数据保存为.npy文件,调用的时候直接使用load()函数即可。
#树的存储
五、使用决策树执行分类
"""
测试函数
train
使用SKlearn中graphviz包实现决策树的绘制
#导入相应的包
这样最终的树模型就画出来啦。