redis集群原理
redis是单线程,但是一般的作为缓存使用的话,redis足够了,因为它的读写速度太快了。
官方的一个简单测试:
测试完成了
50个并发
执行
100000个请求
。
设置和获取的值是一个256字节字符串。
结果:
读的速度是110000次/s,写的速度是81000次/s
在这么快的读写速度下,对于一般程序来说足够用了,但是对于访问量特别大的网站来说,还是稍有不足。那么,如何提升redis的性能呢?看标题就知道了,搭建集群。
3.0版本之前
3.0版本之前的redis是不支持集群的,我们的徐子睿老师说,那个时候,我们的redis如果想要集群的话,就需要一个中间件,然后这个中间件负责将我们需要存入redis中的数据的key通过一套算法计算得出一个值。然后根据这个值找到对应的redis节点,将这些数据存在这个redis的节点中。
在取值的时候,同样先将key进行计算,得到对应的值,然后就去找对应的redis节点,从对应的节点中取出对应的值。
这样做有很多不好的地方,比如说我们的这些计算都需要在系统中去进行,所以会增加系统的负担。还有就是这种集群模式下,某个节点挂掉,其他的节点无法知道。而且也不容易对每个节点进行负载均衡。
3.0版本及以后
先来一张redis集群的架构图:
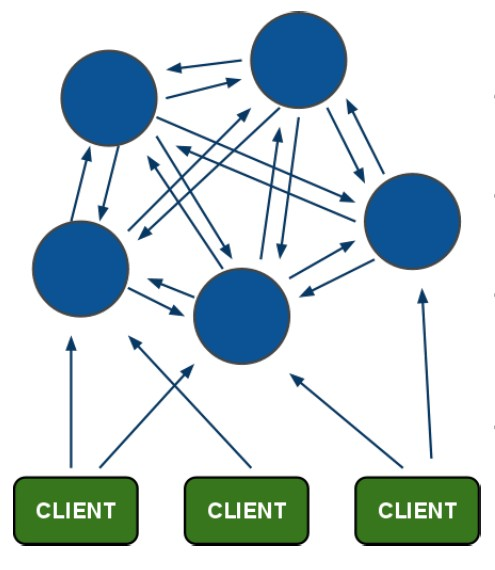
在这个图中,每一个蓝色的圈都代表着一个redis的服务器节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。对其进行存取和其他操作。
那么redis是怎么做到的呢?首先,在redis的每一个节点上,都有这么两个东西,一个是插槽(slot)可以理解为是一个可以存储两个数值的一个变量这个变量的取值范围是:0-16383。还有一个就是cluster我个人把这个cluster理解为是一个集群管理的插件。当我们的存取的key到达的时候,redis会根据crc16的算法得出一个结果,然后把结果对
16384 求余数,这样每个
key 都会对应一个编号在
0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。

还有就是因为如果集群的话,是有好多个redis一起工作的,那么,就需要这个集群不是那么容易挂掉,所以呢,理论上就应该给集群中的每个节点至少一个备用的redis服务。这个备用的redis称为从节点(slave)。那么这个集群是如何判断是否有某个节点挂掉了呢?
首先要说的是,每一个节点都存有这个集群所有主节点以及从节点的信息。
它们之间通过互相的ping-pong判断是否节点可以连接上。如果有一半以上的节点去ping一个节点的时候没有回应,集群就认为这个节点宕机了,然后去连接它的备用节点。如果某个节点和所有从节点全部挂掉,我们集群就进入faill状态。还有就是如果有一半以上的主节点宕机,那么我们集群同样进入发力了状态。这就是我们的redis的投票机制,具体原理如下图所示:
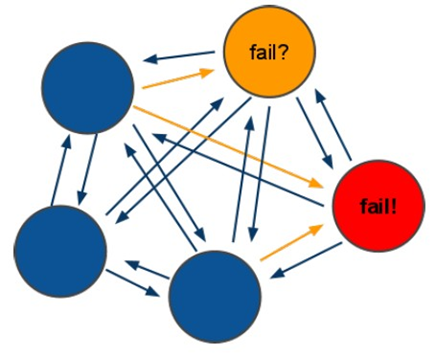
(1)投票过程是集群中所有
master参与
,如果半数以上
master节点与
master节点通信超时
(cluster-node-timeout),认为当前
master节点挂掉
.
(2):什么时候整个集群不可用
(cluster_state:fail)?
a:如果集群任意
master挂掉
,且当前
master没有
slave.集群进入
fail状态
,也可以理解成集群的
slot映射
[0-16383]不完整时进入
fail状态
. ps : redis-3.0.0.rc1加入
cluster-require-full-coverage参数
,默认关闭
,打开集群兼容部分失败
.
b:如果集群超过半数以上
master挂掉,无论是否有
slave,集群进入
fail状态
.
Redis之集群配置
为了保证可以进行投票,需要至少3个主节点。每个主节点都需要至少一个从节点,所以需要至少3个从节点所以一共需要6台redis服务器,为了模拟6个redis节点,我们可以使用6个redis实例作为节点。6个redis实例的端口号,7001~7006.
首先在我们的linux中安装一个redis,如果不会的同学,可以去看我之前的博客《
redis安装-单机版
》然后:
1. 把bin目录里面的rdb,和aof文件删除,准备干净的redis
[root@localhost bin]#
rm -rf appendonly.aof
[root@localhost bin]#
rm -f dump.rdb
完事效果如下:
退出到上级目录,将bin复制6份
把bin复制6份
[root@localhost bin]#
cd ..
如果没有redis-cluster文件夹的话需要创建一个
[root@localhost redis]#
mkdir redis-cluster
[root@localhost redis]#
cp -r bin redis-cluster/redis1
[root@localhost redis]#
cp -r bin redis-cluster/redis2
[root@localhost redis]#
cp -r bin redis-cluster/redis3
[root@localhost redis]#
cp -r bin redis-cluster/redis4
[root@localhost redis]#
cp -r bin redis-cluster/redis5
[root@localhost redis]#
cp -r bin redis-cluster/redis6
这个时候,我们进入redis-cluster目录下看到的结果是这样的:
现在,为了让这6个redis节点运行的时候不起节点的冲突,我们需要修改它们的节点端口号。将端口号一次修改为7001~7006
首先打开第一个节点的redis.conf 配置文件:[root@itcast-01 redis-cluster]#
vim redis1/redis.conf
将端口号修改为7001(将这的6379改为7001)

剩下的代码用同样的方法修改即可。
分别启动6个redis节点的服务,或者是写一个脚本,然后给脚本附上执行权限,然后用脚本启动也可以。
准备集群安装环境
redis集群的管理工具使用的是ruby脚本语言,安装集群需要ruby环境。
安装ruby环境[root@itcast-01 redis-cluster]#
yum install ruby
安装Ruby的打包系统
[root@itcast-01 redis-cluster]# yum install rubygems
下载一个redis-3.0.0.gem的文件,然后将文件上传,再执行命令安转。
[root@itcast-01 ~]#
gem install redis-3.0.0.gem
安装集群
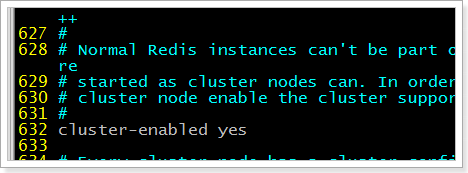
修改这6个实例的redis.conf配置文件,开启redis-cluster
[root@localhost redis-cluster]#
vim redis1/redis.conf
然后再次重启实例
集群管理工具在redis解压文件夹的src的文件夹中,使用redis-cluster的集群管理工具启动集群

先进入集群管理工具所在的路径:[root@localhost redis-cluster]#
cd /root/redis-3.0.0/src/
再启动命令:[root@localhost src]#
./redis-trib.rb create –replicas 1 192.168.37.161:7001 192.168.37.161:7002 192.168.37.161:7003 192.168.37.161:7004 192.168.37.161:7005 192.168.37.161:7006
此时的启动信息如下:

>>> Creating cluster
Connecting to node 192.168.37.131:7001: OK
Connecting to node 192.168.37.131:7002: OK
Connecting to node 192.168.37.131:7003: OK
Connecting to node 192.168.37.131:7004: OK
Connecting to node 192.168.37.131:7005: OK
Connecting to node 192.168.37.131:7006: OK
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.37.131:7001
192.168.37.131:7002
192.168.37.131:7003
Adding replica 192.168.37.131:7004 to 192.168.37.131:7001
Adding replica 192.168.37.131:7005 to 192.168.37.131:7002
Adding replica 192.168.37.131:7006 to 192.168.37.131:7003
M: 955567f988830cdf4328854f815719ea28082ca8 192.168.37.131:7001
slots:0-5460 (5461 slots) master
M: 4f3eeced04b930aa48193699301745a05a70697a 192.168.37.131:7002
slots:5461-10922 (5462 slots) master
M: 871a684dbbc0f43dcc16107710d7bd2f4e6de76a 192.168.37.131:7003
slots:10923-16383 (5461 slots) master
S: baca3ce2223dfcd9c636a7193b12998b1dbb2431 192.168.37.131:7004
replicates 955567f988830cdf4328854f815719ea28082ca8
S: 0b599863ddf2e03b0326c75b874a1af8ae430d2e 192.168.37.131:7005
replicates 4f3eeced04b930aa48193699301745a05a70697a
S: 92f712d954c62f2743e2e572f6582a6ef9a163e0 192.168.37.131:7006
replicates 871a684dbbc0f43dcc16107710d7bd2f4e6de76a
Can I set the above configuration? (type 'yes' to accept):
>>> Creating cluster
Connecting to node 192.168.37.131:7001: OK
Connecting to node 192.168.37.131:7002: OK
Connecting to node 192.168.37.131:7003: OK
Connecting to node 192.168.37.131:7004: OK
Connecting to node 192.168.37.131:7005: OK
Connecting to node 192.168.37.131:7006: OK
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.37.131:7001
192.168.37.131:7002
192.168.37.131:7003
Adding replica 192.168.37.131:7004 to 192.168.37.131:7001
Adding replica 192.168.37.131:7005 to 192.168.37.131:7002
Adding replica 192.168.37.131:7006 to 192.168.37.131:7003
M: 955567f988830cdf4328854f815719ea28082ca8 192.168.37.131:7001
slots:0-5460 (5461 slots) master
M: 4f3eeced04b930aa48193699301745a05a70697a 192.168.37.131:7002
slots:5461-10922 (5462 slots) master
M: 871a684dbbc0f43dcc16107710d7bd2f4e6de76a 192.168.37.131:7003
slots:10923-16383 (5461 slots) master
S: baca3ce2223dfcd9c636a7193b12998b1dbb2431 192.168.37.131:7004
replicates 955567f988830cdf4328854f815719ea28082ca8
S: 0b599863ddf2e03b0326c75b874a1af8ae430d2e 192.168.37.131:7005
replicates 4f3eeced04b930aa48193699301745a05a70697a
S: 92f712d954c62f2743e2e572f6582a6ef9a163e0 192.168.37.131:7006
replicates 871a684dbbc0f43dcc16107710d7bd2f4e6de76a
Can I set the above configuration? (type 'yes' to accept):
输入yes,然后回车,又是一大堆的提示信息:
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join..
>>> Performing Cluster Check (using node 192.168.37.131:7001)
M: 955567f988830cdf4328854f815719ea28082ca8 192.168.37.131:7001
slots:0-5460 (5461 slots) master
M: 4f3eeced04b930aa48193699301745a05a70697a 192.168.37.131:7002
slots:5461-10922 (5462 slots) master
M: 871a684dbbc0f43dcc16107710d7bd2f4e6de76a 192.168.37.131:7003
slots:10923-16383 (5461 slots) master
M: baca3ce2223dfcd9c636a7193b12998b1dbb2431 192.168.37.131:7004
slots: (0 slots) master
replicates 955567f988830cdf4328854f815719ea28082ca8
M: 0b599863ddf2e03b0326c75b874a1af8ae430d2e 192.168.37.131:7005
slots: (0 slots) master
replicates 4f3eeced04b930aa48193699301745a05a70697a
M: 92f712d954c62f2743e2e572f6582a6ef9a163e0 192.168.37.131:7006
slots: (0 slots) master
replicates 871a684dbbc0f43dcc16107710d7bd2f4e6de76a
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
这时,我们的集群就算是安装成功了。
测试
使用redis命令行客户端连接
[root@localhost bin]#
./redis-cli -h 192.168.37.131 -p 7006
-c
192.168.37.131:7006> set hello money
-> Redirected to slot [866] located at 192.168.37.131:7001
OK
一定要加-c参数,节点之间就可以互相跳转
这就表示我们的集群搭建成功了,而且,自动将访问7001端口的那个请求跳转到7006.并且保存成功。