为什么要引入Cache
cache,高速缓冲存储器,是一种以RAM为材料制成的高速存储器。引入的原因主要有:
- I/O设备向主存的访问级别高于CPU,在I/O访存期间,CPU将处于空闲状态。
- 主存速度的提高始终跟不上CPU的发展,主存与CPU的速度明显不匹配
局部性原理
程序访问的局部性原理包括时间局部和空间局部性。前者是指最近未来要用到的信息很可能是正在使用的信息,这是因为程序存在循环。后者是指指令和数据在内存中都是连续存放的并且有些指令和数据往往会被多次调用(如子程序,循环程序和一些常数)。因此只要将CPU近期要用到的程序和数据前从主存送到Cache,这样大多数情况下,CPU都能直接从Cache中取得指令和数据。
Cache的工作原理
Cache是一种容量小而速度快的高度缓冲器,由快速的SRAM组成,直接做在CPU内,速度几乎与CPU一样快,任何时刻都有一些主存块处于缓存之中,因此,CPU欲访问主存的时候,有两种可能:
- 所需要的字已经在缓存中,于是CPU直接访问Cache,(通常一次传送一个字,主存不参与)
- 所需要的字不在缓存中,那么此时需要将字所在的主存块整块一次调入Cache中,(即主存-Cache之间以块为单位进行传送 )。主存块调入缓存的过程,称为建立对应关系。
我们将第一种情况称为
CPU访问Cache命中
,简称Cache命中。第二种情况为不命中。由于缓存块数目远小于主存数,因此每个缓存快要设立一个标识,用来表明当前存放的是哪一个主存块。
Cache的容量与长度是影响Cache效率的重要因素,通常用命中率来衡量Cache的效率 。
在一个程序执行期间,设总的命中次数为Nc,访问主存的次数为Nm,那么命中率可以这样表示:
H
=
N
c
/
(
N
c
+
N
m
)
H=N_c /(N_c+N_m)
H
=
N
c
/
(
N
c
+
N
m
)
设Tc为命中时Cache的访问时间,那么Tm为未命中时的主存访问时间,那么平均访问时间为:
T
a
=
H
t
c
+
(
1
−
H
)
t
m
T_a=Ht_c +(1-H)t_m
T
a
=
H
t
c
+
(
1
−
H
)
t
m
其中H为命中率,1 – H是未命中率。
显然,越好的Cache,其Ta值越接近Tc(即H接近于1)。
Cache与主存之间的映射
在Cache中,地址映射是指把主存地址空间映射到Cache地址空间,在将主存块复制到Cache中的时候遵循一定的映射规则,标志位为1时候,表示其Cache映射的主存块数据有效。(注意与地址变换的区别,地址变换是指CPU在访存的时候,将主存地址按照映射规则换算成Cache地址的过程 )。
地址映射有三种方式:直接映射,全相联映射,组相联映射、
-
直接映射
这种方式主存块只能装入Cache的唯一位置,若该位置已有内容,则产生块冲突,原来在Cache中的块将无条件被替换出去,直接映射的关系可以定义为:
j=
i
%
2
c
j = i \% 2^c
j
=
i
%
2
c
其中,j为Cache的块号或者行号。i为主存块号,2^c为Cache的总块数,%为模运算,因此
主存
的
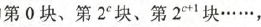
只能映射到第0行,依次类推,其地址结构为:

CPU的访存过程
:首先根据地址中间的Cache字块地址,直接找到对应的Cache块号,若块号的有效位为1,则表示命中,否则为不命中此时从主存中读取该地址所在的主存块号,并将其内容送到对应的Cache块并将有效位置1,同时将内容送到CPU。
缺点
:这种方式映射不够灵活
-
全相联映射
这种方式可以把主存数据块装入Cache的任意一块, 方式可以从已占满的Cache存储块中,替换出任一旧块,显然这种方式灵活,命中率也高,缩短了块冲突,与直接相联映射相比,其主存字块位数增加,使得Cache标记位增多地址变换速度慢。通常使用“按内容寻址的”相联存储器。其地址结构为:

-
组相联映射
将Cache空间分成大小相同的组,主存的一个数据块可以装到组内的任一个位置,即组间采取直接映射,组内采取全相联映射。
如果把Cache分成Q组,每组有R块,那么有:
i=
j
%
q
i= j \% q
i
=
j
%
q
其中i为缓存的组号,j为主存块号主存地址分为三个字段:

当组内2块的时候,称为2路组相联映射。
下一篇将介绍一下Cache相关的算法跟计算。