文本特征提取–TFIDF与Word2Vec
1.TF-IDF
1.1 定义
TF-IDF是Term Frequency – Inverse Document Frequency的缩写,即“词频-逆文本频率”。它由两部分组成,TF和IDF。TF-IDF:是一种加权技术。采用一种统计方法,根据字词在文本中出现的次数和在整个语料中出现的文档频率来计算一个字词在整个语料中的重要程度。
1.2 计算过程:
公式如下:
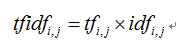
t
f
i
d
f
i
,
j
tfidf_{i,j}
t
f
i
d
f
i
,
j
表示词频
t
f
i
,
j
tf_{i,j}
t
f
i
,
j
和倒文本词频
i
d
f
i
,
j
idf_{i,j}
i
d
f
i
,
j
的乘积。TF-IDF值越大,表示该特征词对这个文本的重要性越大。
1.2.1 TF(Term Frequency):
TF(Term Frequency): 表示某个关键词在整篇文章中出现的频率。计算公式如下:
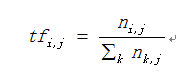
其中,分子为特征词 t 在文本 dj 中出现的次数,分母则是文本dj中所有特征词的个数。计算的结果即为某个特征词的词频。
1.2.2 IDF(InversDocument Frequency):
IDF(InversDocument Frequency):表示计算倒文本频率。文本频率是指某个关键词在整个语料所有文章中出现的次数。倒文本频率是文本频率的倒数,主要用于降低所有文档中一些常见却对文档影响不大的词语的作用。IDF反应了一个词在所有文本中出现的频率,如果一个词在很多的文本中出现,那么它的IDF值应该低,而反过来如果一个词在比较少的文本中出现,那么它的IDF值应该高。
计算公式,如下:
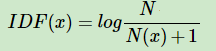
其中N代表语料库中文本的总数(样本数),而N(x)代表语料库中有多少文本包含词x。 为防止该词语在语料库中不存在,即分母为0,使用 N(x)+1 作为分母
也有人在 在分母和取对数后加1,这都是为了使IDF平滑(类似于加载分母上的eplcsion)
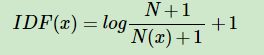
1.3 基于scikit-learn的实现:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(ngram_range=(1, 2), min_df=3, max_df=0.9, sublinear_tf=True)
vectorizer.fit(df_train['word_seg'])
x_train = vectorizer.transform(df_train['word_seg'])
x_test = vectorizer.transform(df_test['word_seg'])
1.4 优缺点
能过滤掉一些常见的却无关紧要的词语,同时保留影响整个文本的重要词语。但丢失了文本上下文之间的联系
1.5 主要应用:
关键词提取,找相似文章,文章自动摘要,作为分类或聚类的输入。
1.6 TF-IDF的实现方法:
这篇文章主要介绍了计算TF-IDF的不同方法实现,主要有三种方法:
用sklearn库来计算tfidf值
用gensim库来计算tfidf值
用python手动实现tfidf的计算
代码实现链接:
(
https://colab.research.google.com/drive/1HZRYL_XF0KqT4Pz_S7yycGTfNkSU1SNA#scrollTo=EwimwMWgdG-z
)`
1.6.1 用sklearn库来计算tfidf值
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
valid_words=["this three stooges flick is at a tie with ......"]
tfidf_vec = TfidfVectorizer(stop_words={ 'english'})
tfidf_matrix = tfidf_vec.fit_transform(valid_words)
print(tfidf_matrix)
直接输出,得到的是一个generator,一般要用tfidf_matrix.toarray()将其转为array

# 得到语料库所有不重复的词
print(tfidf_vec.get_feature_names())
# 得到每个单词对应的id值
print(tfidf_vec.vocabulary_)
# 得到每个句子所对应的向量
# 向量里数字的顺序是按照词语的id顺序来的
print(tfidf_matrix.toarray())

TF-IDF的参数
-
token_pattern: 这个参数使用正则表达式来分词,其默认参数为r”(?u)\b\w\w+\b”,其中的两个\w决定了其匹配长度至少为2的单词,所以这边减到1个。对这个参数进行更多修改,可以满足其他要求.
-
max_df/min_df: [0.0, 1.0]内浮点数或正整数, 默认值=1.0
当设置为浮点数时,过滤出现在超过max_df/低于min_df比例的句子中的词语;正整数时,则是超过max_df句句子。这样就可以帮助我们过滤掉出现太多的无意义词语, -
stop_words: list类型
直接过滤指定的停用词。 -
vocabulary: dict类型
只使用特定的词汇,是指定对应关系。这一参数的使用有时能帮助我们专注于一些词语,比如我对本诗中表达感情的一些特定词语(甚至标点符号)感兴趣,就可以设定这一参数,只考虑他们.
2.Word2Vec
2.1 概念
word2vec主要分为CBOW(Continuous Bag of Words)和Skip-Gram两种模式。CBOW是从原始语句推测目标字词;而Skip-Gram正好相反,是从目标字词推测出原始语句。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
参考链接
https://www.jianshu.com/p/dfcc19bba2d5
https://www.cnblogs.com/pinard/p/6693230.html
https://blog.csdn.net/ukakasu/article/details/83022034
https://blog.csdn.net/a1240663993/article/details/88259978
https://www.jianshu.com/p/f3b92124cd2b
https://blog.csdn.net/blmoistawinde/article/details/80816179