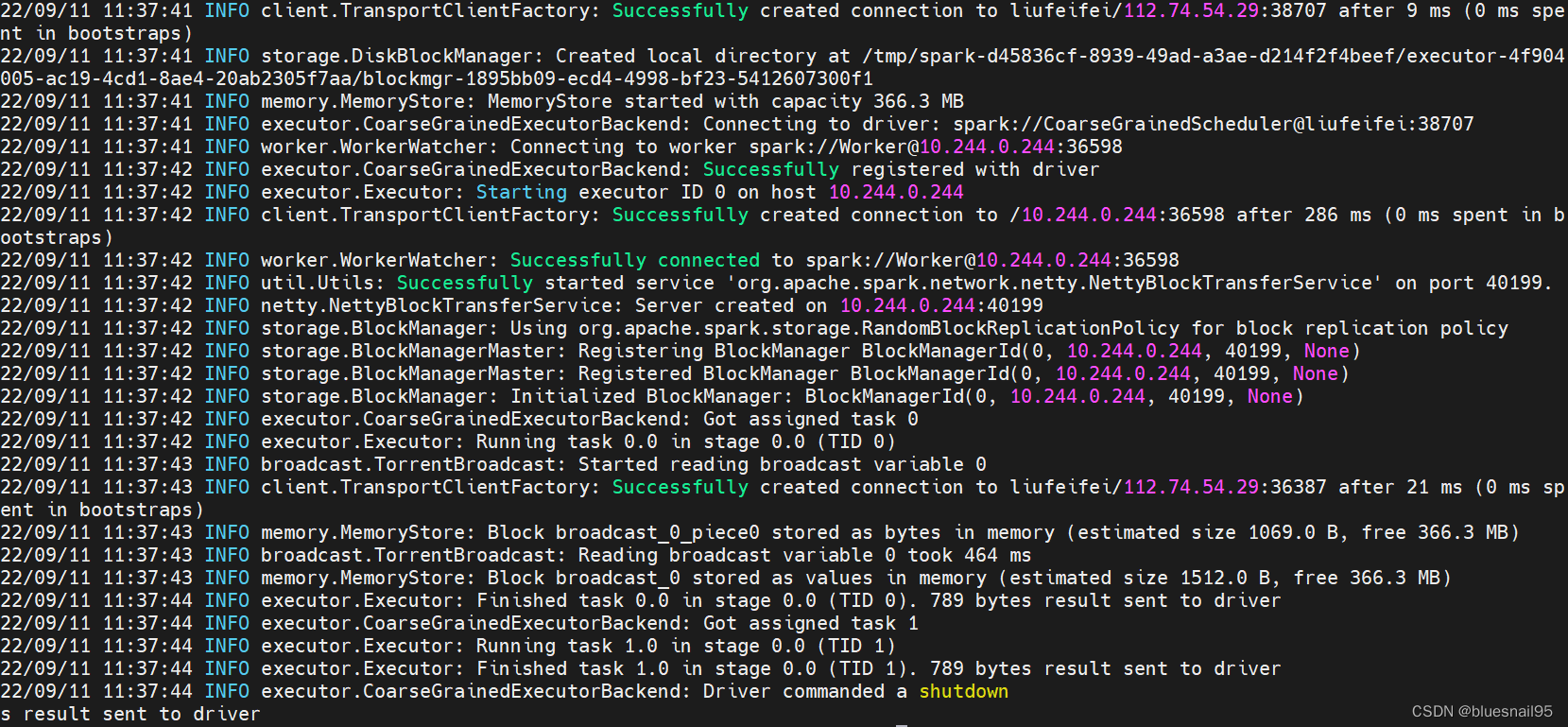
我搭建的Spark集群的版本是2.4.4。
在网上找的maven依赖,链接忘记保存了。。。。
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<hadoop.version>2.6.0-cdh5.14.2</hadoop.version>
<hive.version>1.1.0-cdh5.14.2</hive.version>
<hbase.version>1.2.0-cdh5.14.2</hbase.version>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.4</spark.version>
</properties>
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<!--scala-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<!-- spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- spark-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.4</version>
</dependency>
<!-- spark-graphx -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-graphx_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- hadoop -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- log4j -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
<!-- kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.2</version>
</dependency>
<!-- mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.31</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.0.1.RELEASE</version>
<configuration>
<mainClass>gdut.spark.SparkInit</mainClass>
</configuration>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
Java客户端连接示例:
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.SparkConf;
import java.util.Arrays;
import java.util.List;
public class SparkInit {
public static void main(String[] args) {
try {
SparkConf conf = new SparkConf().setAppName("liufeifei").setMaster("spark://x.x.x.x:30010");
conf.set("spark.executor.cores","1");
conf.set("spark.executor.memory", "1024m");
JavaSparkContext sc = new JavaSparkContext(conf);
List<Integer> data = Arrays.asList(1, 2, 3, 4, 5);
JavaRDD<Integer> distData = sc.parallelize(data);
System.out.println("result is " + distData.count());
} catch (Exception e) {
e.printStackTrace();
}
}
}
遇到问题:
(1)spark集群中,worker节点提示:Failed to send RPC
master pod的spark-shell执行collect方法,日志输出如下:
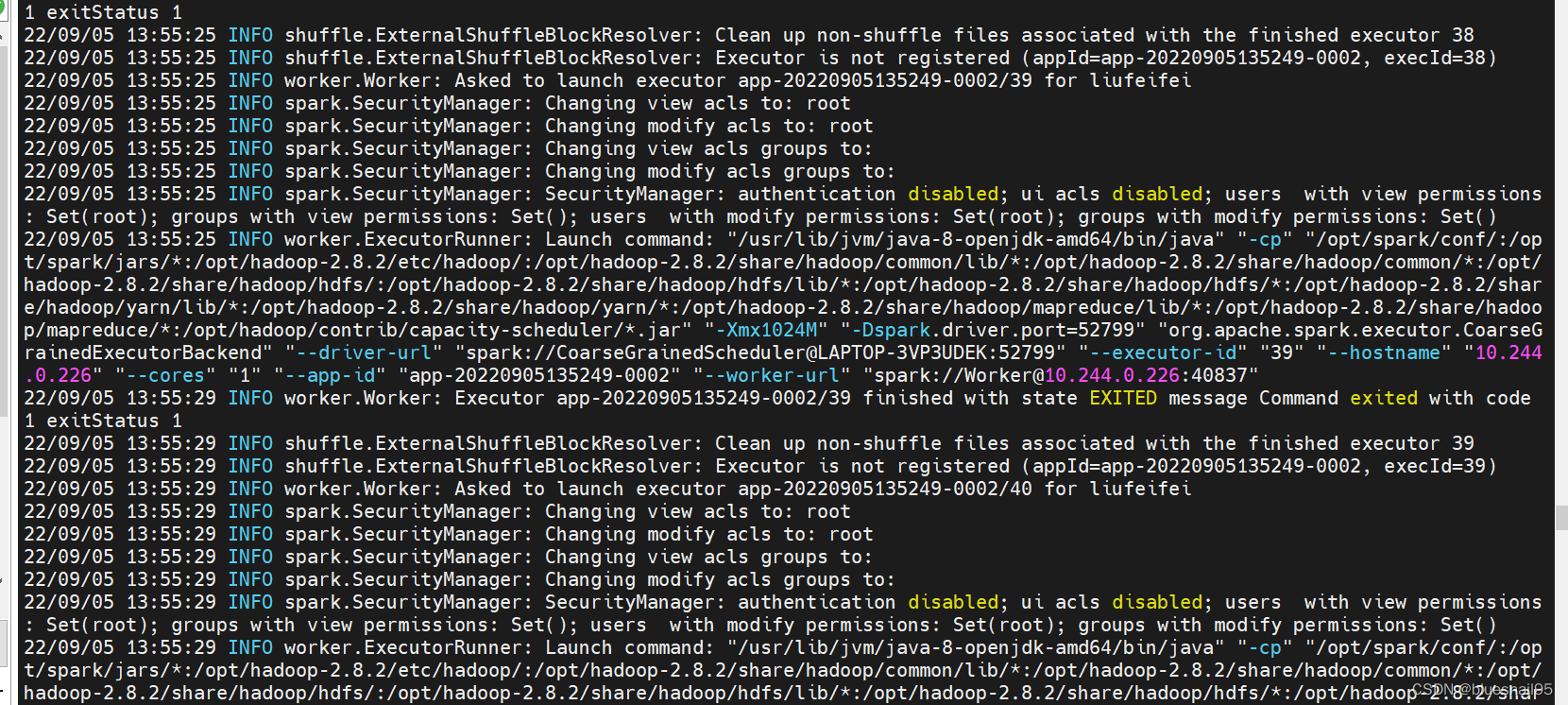
worker pod输出如下:
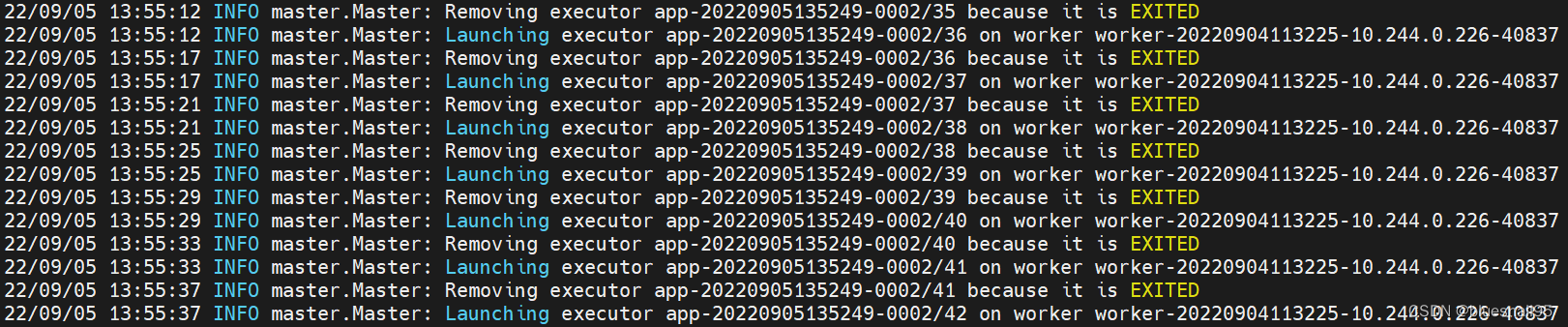
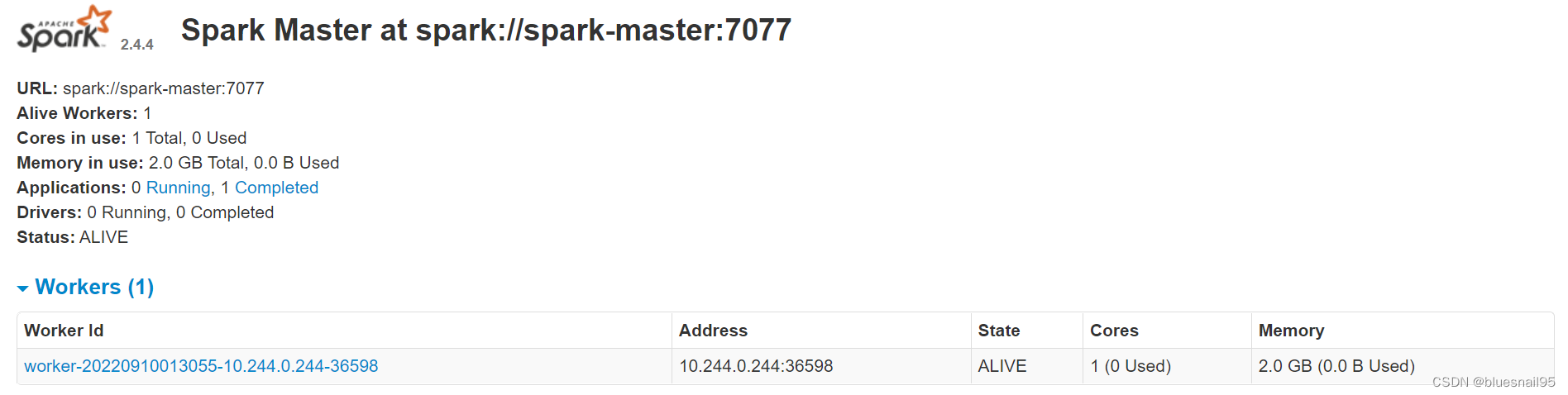
worker节点无法创建Executor,在worker节点的安装目录下有个work目录,有每次创建Executor的日志。查看是worker节点与master节点无法通信。但是worker节点有向master注册,在master的UI界面有显示注册的worker节点。在网上不经意看到有人说可能是istio影响了,然后想起自己之前部署过istio。查看spark部署的命名空间确实是开启istio注入。
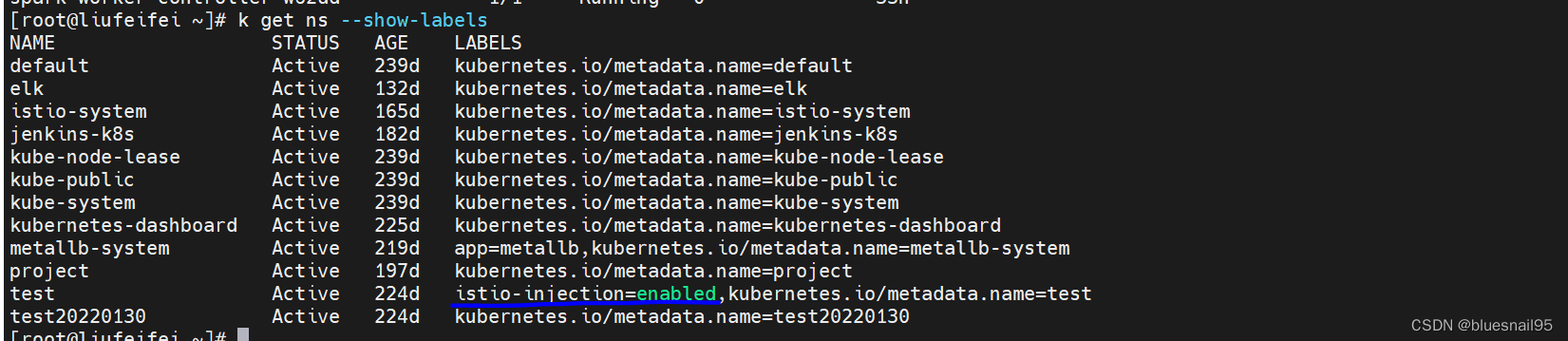
换个没有istio注入的命名空间创建spark集群。在master节点的spark-shell可以执行collect方法,可以调度到worker节点的Executor。
(2)Caused by: java.net.UnknownHostException: XXX
无论在本地还是在虚拟机执行上面的客户端连接,都会提示UnknownHostException。这是因为在worker容器的/etc/hosts找不到客户端主机名称和IP的映射关系。
解决办法:
使用 HostAliases 向 Pod /etc/hosts 文件添加条目
hostAliases:
- ip: "127.0.0.1"
hostnames:
- "foo.local"
- "bar.local"
- ip: "10.1.2.3"
hostnames:
- "foo.remote"
- "bar.remote"
我在yaml文件添加了hostAliases之后,提示主机名不符合规定,然后修改了自己虚拟机上的主机名。
修改主机名后遇到:
java.net.UnknownHostException:Name or Service not known
修改了/etc/hosts文件可以解决。
因为spark集群是部署在一台虚拟机上,本地不能和虚拟机通信,所以要把spring boot项目打包成jar在虚拟机上执行。
Main方法输出:

worker日志输出(k8s容器和宿主机时间相差了8个小时):