大家有没有遇到过慢查询的情况,执行一条SQL需要几秒,甚至十几、几十秒的时间,这时候DBA就会建议你去把查询的 SQL 优化一下,怎么优化?你能想到的就是加索引吧?
为什么加索引就查的快了?这就要从索引的本质以及他的底层原理说起。
索引是什么
那索引到底是什么呢?你是不是还停留在大学学 『数据库原理 』时老师讲的“索引就像字典的目录”这样的概念?老师讲的没错,但没有深入去讲。
其实索引就是一种用于快速查找数据的数据结构,是帮助MySQL高效获取数据的排好序的数据结构。
索引的好处
举例说明索引的好处以及是怎么加快查询的。
假设我们有一个表t,它有俩字段,Col1和Col2,如下:
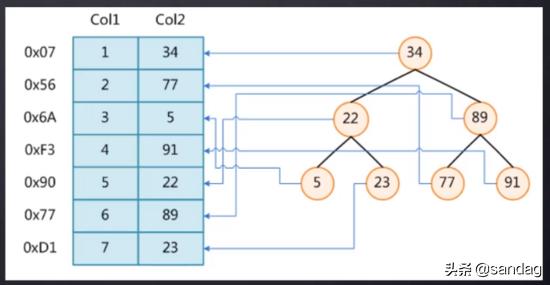
不加索引
不加索引的情况下,SQL: select * from t where t.col2=89 ,需要从表的第一行一行行遍历比对col2的值是否等于89,这样需要比对6次才能查到。这只是只有几行记录的表,那如果是百万级千万级的表呢?是不是就比较的次数就更多了,那还不得慢死。
加索引
如果col2这列加了索引,mysql内部会维护一个数据结构。假设mysql用的数据结构是红黑树(右子树的元素大于根节点,左子树的元素小于根节点)的数据结构建立索引,那就像上图右边那样。这样的话,刚才的那条SQL是不是只需要2次磁盘IO就查到了,是不是快很多了。
这就是索引的好处。索引使用比较巧妙的数据结构,利用数据结构的特性来大大减少查找遍历次数。
索引底层数据结构的探索
既然索引底层原理是利用一些巧妙的数据结构维护我们的数据,使得查询效率很高,那索引底层使用的什么数据结构呢?又是怎样来维护我们的数据呢?下面就带着大家一起探索一下索引的底层数据结构。
索引可选的数据结构 :
- 二叉树
- 红黑树
- hash
- B-tree
但mysql索引的底层用的并不是二叉树和红黑树。因为二叉树和红黑树在某些场景下都会暴露出一些弊端或者说缺点。
二叉树
我们看一下二叉树如果作为索引的底层数据结构在什么样的场景下有怎么样的缺点和不足。
假设把刚才的SQL改一下,用col1作为条件来查找,SQL: select * from t where t.col1 = 6 。
假如把col1作为索引,col1这列的数据特点是从上到下依次递增,类似于自增主键,那在每插入一行在维护二叉树这样一个数据结构的时候,我们看一下二叉树维护成什么样子了。
打开这个 网址 (国外的),可以演示数据结构维护的过程。依次插入1、2、3、4、5…
通过这个网站的演示插入这些数据,我们可以看到这样的一个二叉树是不是一直在单边增长,没有左子树。再仔细看一下和我们学过的链表是不是很像,也就是说
二叉树在某些场景下退化成了链表。


链表的查找是不是需要从头部遍历啊,这时候和没加索引从表的第一行遍历是不是没什么太大区别?这就是mysql索引底层没有使用二叉树这种数据结构的原因之一。
当二叉树像上图一样退化成链表后,我们去查col1=6的记录是不是从二叉树的根节点依次遍历,遍历6次才能查到,和不加索引从表里一行行的遍历没太大差别。这是二叉树所谓索引底层数据结构的弊端之一。
红黑树
那有没有更好的数据结构用来存储索引,帮助我们更快的查找呢?比方说红黑树或hash表。
我们先看下红黑树。红黑树是什么?
是一种平衡二叉树,JDK1.8的hashmap就用到了红黑树。
那我们把刚才的一样的数据用红黑树来看一下是什么样的效果,同样打开刚才的 网址 ,我们选择红黑树。

依次插入1、2、3、4、5、6、7看一下效果,可以看到,当有单边增长的趋势时红黑树会进行一个平衡(旋转)。这时,我们查询col1=6的数据时,查了3次,比二叉树又有了改进。