前言
关于SQLAlchemy的教程,在网络上已经有许多,这里之所以再写一份教程,原因之一是由于近期在整理一个多年前的软件时,发现数据库MySQL与界面库PyQt5很难匹配,由于当时是用PyQt5中的QtSql模块直接与MySQL连接,这就导致了修改程序的困难,目前比较好的办法是先临时更换一个数据库,即将原来的MySQL数据库转为SQLite3,这样可以确保程序运行,但未来如何在网络上运行,又是一个不得不考虑的问题。
原因之二是在对该旧程序深入思考后,发现之所以采用PyQt5中的QtSql模块,还是贪图其中的QTableView与数据库的便捷关联,其实当年有考虑过SQLAlchemy,这从程序中还保留的该部分模块能看得出来,但估计当时还是想图一时之方便,结果现如今却因一个关键的连接问题迟迟无法使程序运行起来。
从网络上看到的解决方案一般是重新安装Qt环境再结合所用的MySQL版本编绎生成一新驱动供程序调用,可我实在不愿意做这样泛味的事,于是思来想去,还是决定用SQLAlchemy重写与数据库相关的部分。这种做法也符合软件设计的低耦合原则。
早知如此,何必当初!
不过,从另一个角度来看,也正因为这件事,所以才有今日这一系列的SQLAlchemy教程整理,失乎?得乎?
SQLAlchemy是什么?
上面说了许多没啥用的话,也只是交待一下背景,但要说明SQLAlchemy是什么,也许很容易。
如果熟悉数据库查询的同学,应该知道SQL查询语句,比如select * from …等,这种直接写SQL查询语句的方式,我们称之为硬编码,它的好处在于便捷快速,但其坏处也是很让人头疼,尤其是在写网络程序时,由于要将用户输入信息拼接到特定的SQL语句中,那么这种情况下很容易给别有用心的人进行SQL注入式攻击,关于这种攻击方式这里不展开谈(笔者曾于十多年前某次程序测试中利用该漏洞查出某离线版系统的所有用户名和密码),有兴趣的同学可以网络搜索即知该种攻击方法。
在这种情况下,编写安全的代码,避免SQL硬编码中的缺陷就是当务之急的事,而SQLAlchemy就提供了这样一种解决方案,它将数据库中的每一个表映射为一个类,将每个表中的字段映射为对应类中的成员函数,这样处理以后,对表的增删改查均可通过对应的类进行操作,而将类转换为SQL语句的部分由这个软件包底层进行了专业实现,这样,只要使用该软件包,我们就可以让程序安全地接受用户的所有数据!
安装SQLAlchemy
在系统中安装该软件包是容易的,熟悉python的同学应该已经知道如何安装了,即在命令窗口输入以下代码即可:
pip install sqlalchemy
等待安装完成后,打开python窗口,输入以下代码来查询一下我们所安装的版本:
import sqlalchemy
sqlalchemy.__version__

连接数据库
在SQLAlchemy中,首先要连接数据库,这里需要说明的是,如果要连接MySQL之类的数据库,首先要在MySQL中先建立一个空数据库,才能确保连接成功,即该软件包本身并不创建数据库,它连接数据库的语句是:
from sqlalchemy import create_engine
engine = create_engine(“数据库+数据库驱动://用户名:密码@地址/数据库名”)
为了演示方便,在教程中,我们采用SQLite的内存数据库来演示SQLAlchemy的用法,因为一旦用SQLAlchemy编码完成后,无论换什么数据库,都只需要用上述的create_engine重新连接一个新数据库即可,其余的代码完全无须改变,这就实现了程序与数据库的分离。
创建SQLite内存数据库的代码如下:
from sqlalchemy import create_engine
engine = create_engine(‘sqlite:///:memory:’, echo=True)
上述代码中的echo标志是设置SQLAlchemy记录的快捷方式,它本质上是调用python中的logging模块。
上面语句成功运行后,我们将得到一个Engine的实例engine,当然也可以通过engine的execute方法来执行sql语句,可这样一来,与我们进行SQL语句的硬编码有什么区别呢?
我们真正想要的是ORM(对象关系模型),即将数据库中的表转换为python中的类,反之亦然。
创建第一个基于类的数据表
为了演示SQLAlchemy的强大,我们先来创建一个类,该类包含三个成员:用户ID、姓名、呢称,为了创建该类,首先我们先声明一个基于SQLAlchemy的基类:
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
接着,我们再创建我们的User类,该类是对上述基类的继承,只有按照这种方式创建类,才能充分利用SQLAlchemy的功能来直接生成对应的表:
from sqlalchemy import Column, Integer, String
class User(Base):
__tablename__ = ‘users’
id = Column(Integer, primary_key=True)
name = Column(String)
nickname = Column(String)
按照这样的方式,我们创建了第一个可以对应数据库中表的类,我们来看一下这个类的属性__table__中有些什么:
User.__table__

从这里可以看出,虽然User类是一个典型的Python类,但由于它继承的是SQLAlchemy中的内容,因此它又与普通的类不太一样,细心的同学看到了上述的__table__属性中有一个MetaData的单词,这叫元数据,是SQLAlchemy中最重要的概念之一,这个所谓的MetaData是包含表以及关系的更抽象实现,你可以将它理解为一个大家长,它拥有相当多的东西,也拥有相当多的权力。
下面我们就用metadata来将我们刚才所创建的类“投放”到engine连接的内存数据库中:
Base.metadata.create_all(engine)
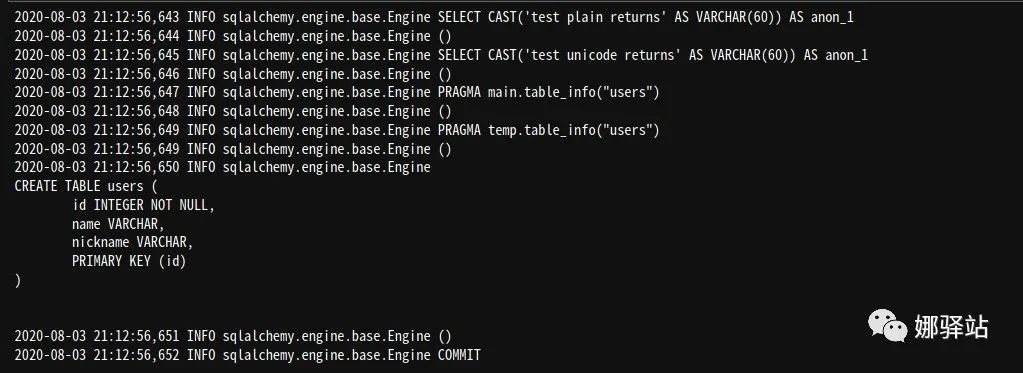
是不是很神奇?我们只用metadata中的create_all函数即完成了将我们所创建的一个类重新创建到了数据库中,而这中间并未用到一句SQL语句!
从上述显示可以看出(这里的显示可是要感谢刚才的echo=True语句哦),只要我们所创建的类是基于前面声明的Base,那么create_all即可以完成所有类的对应表的创建!
当然如果想指定所创建的字段长度,只需要在刚才创建类时,为相应的成员指定需要的长度即可,代码如下:
Column(String(50))
创建一个类的实例
由于User是典型的Python类,所以基于该类很容易创建一个实例,比如:
user1 = User(name=’sonny’, nickname=’娜驿站’)
print(user1.name, user1.nickname)

注意,如果我们调用user的id,会发生什么呢?
str(user1.id)

从上述测试可以看到,尽管我们已经实例化了user1,但它的id仍然是None,当将该数据插入数据表中时,该id字段将实现自动增长。
那么如何将上述的user1实例放入数据表中呢?这里先卖一个关子,下一篇将着重讲述这个重要的问题。
小结
本篇简述了SQLAlchemy的基本概念,并对如何连接数据库,如何创建基于该软件包的类,以及如何依据该类在数据库中创建对应的表进行了举例说明,请同学们可以跟着实际操作一下,更容易体会其中的道理。