堆内存管理
堆内存分类
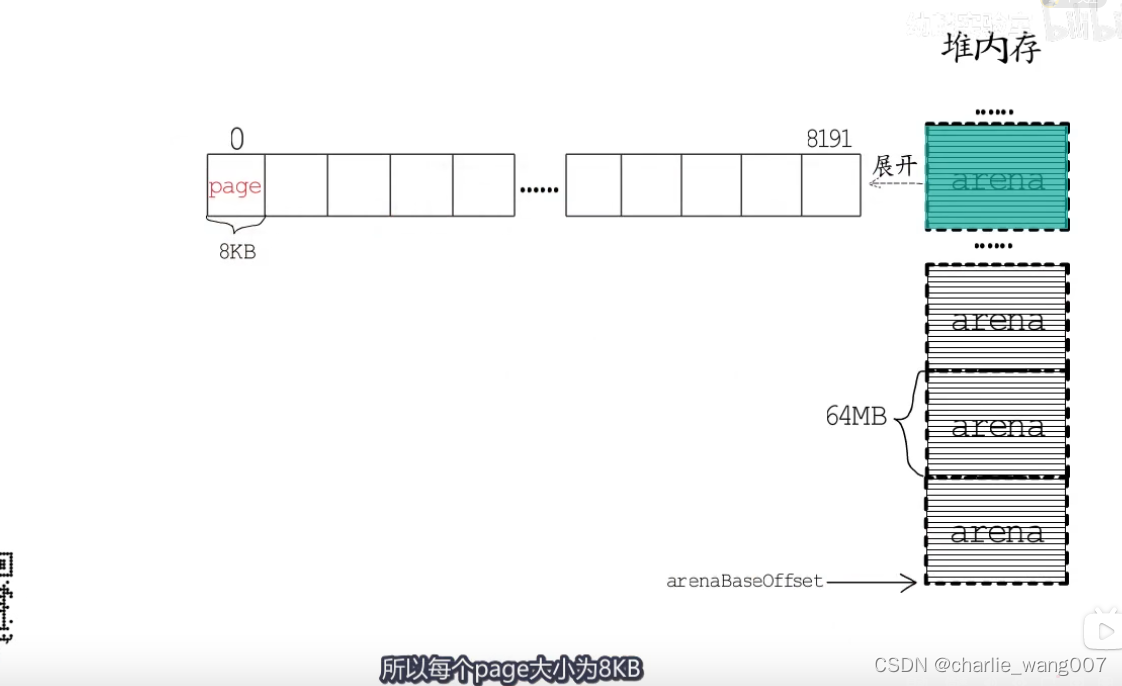
1 堆内存分为64M大小的arena,64*1024=65536
65536/8=8192 即每个arene分成8192个page。每个page为8kb
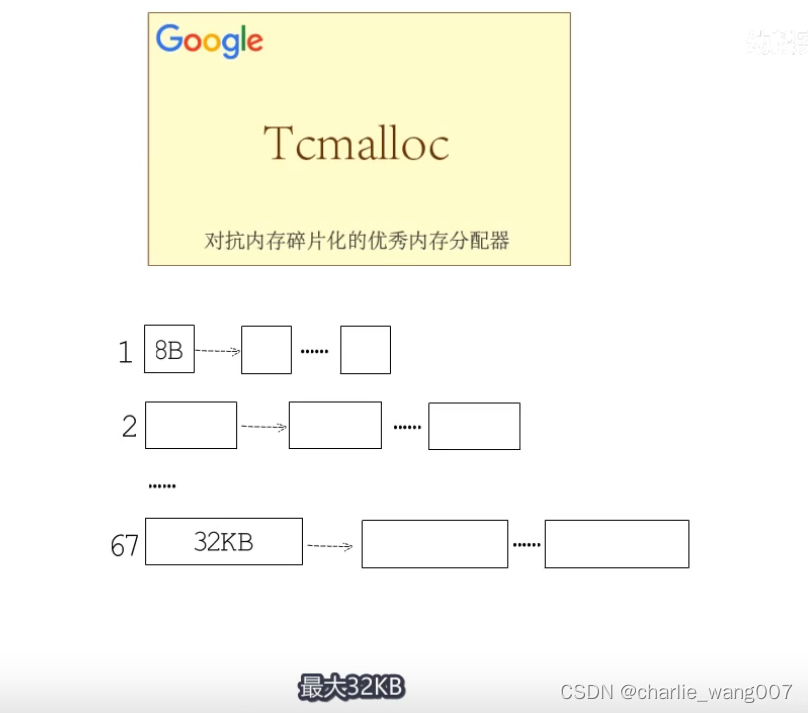
go在管理内存是,把内存划分成大小不同的67钟规格,最小8字节 最大32k字节
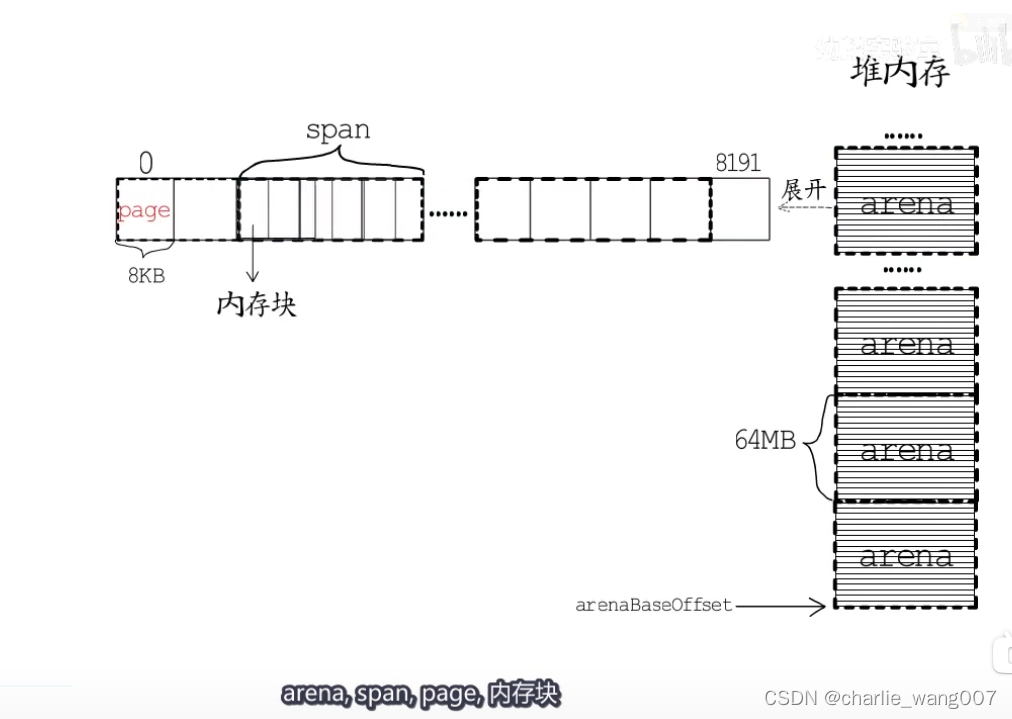
go把每个arena划分成大小不同的span,每个span包含一组连续的page
他们的关系是
堆内存>span>page>内存块
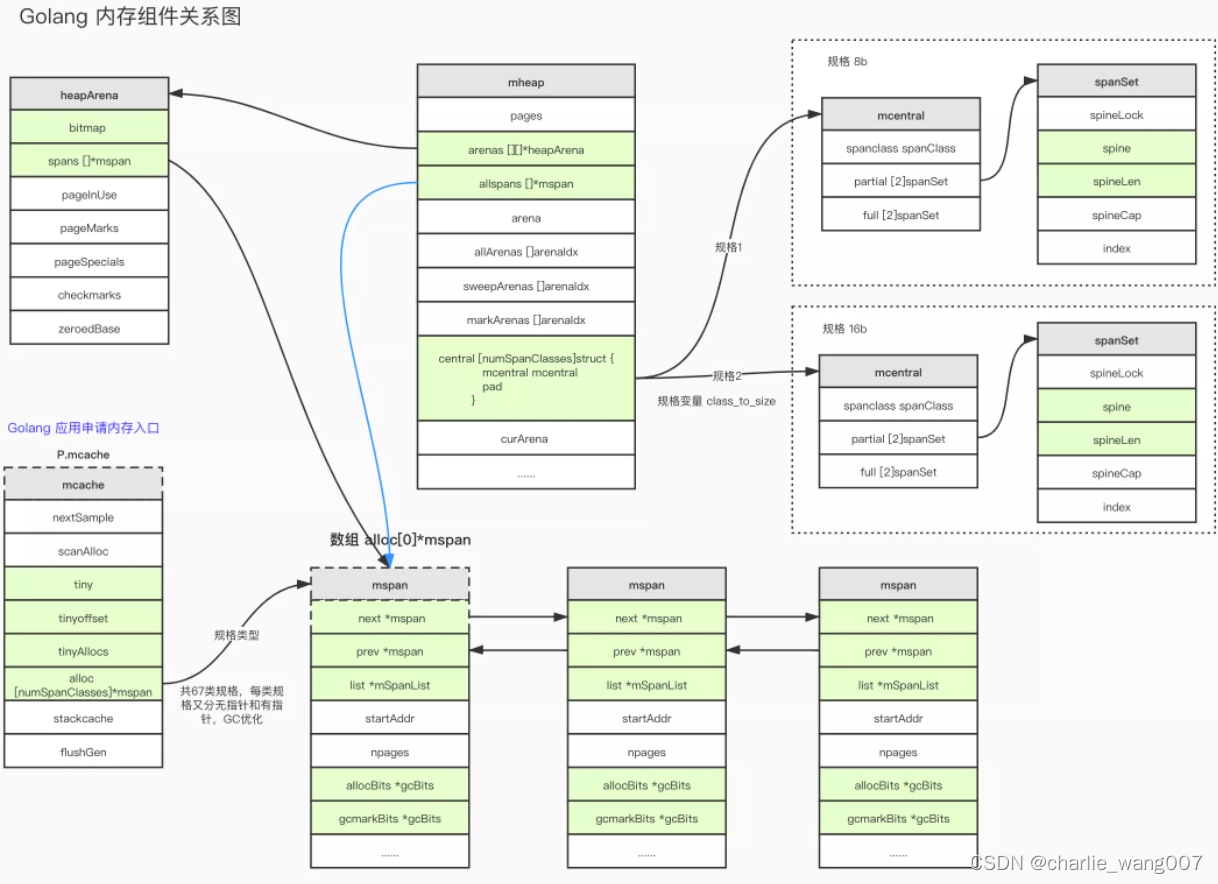
全局Span管理 mheap ,mheap.central
mheap:
//path: /usr/local/go/src/runtime/mheap.go
type mheap struct {
lock mutex
// spans: 指向mspans区域,用于映射mspan和page的关系
spans []*mspan
// 指向bitmap首地址,bitmap是从高地址向低地址增长的
bitmap uintptr
// 指示arena区首地址
arena_start uintptr
// 指示arena区已使用地址位置
arena_used uintptr
// 指示arena区末地址
arena_end uintptr
central [67*2]struct {
mcentral mcentral
pad [sys.CacheLineSize - unsafe.Sizeof(mcentral{})%sys.CacheLineSize]byte
}
}
复制代码
mheap:代表Go程序持有的所有堆空间,Go程序使用一个mheap的全局对象_mheap来管理堆内存。
当mcentral没有空闲的mspan时,会向mheap申请。而mheap没有资源时,会向操作系统申请新内存。mheap主要用于大对象的内存分配,以及管理未切割的mspan,用于给mcentral切割成小对象。
同时我们也看到,mheap中含有所有规格的mcentral,所以,当一个mcache从mcentral申请mspan时,只需要在独立的mcentral中使用锁,并不会影响申请其他规格的mspan。
mcentra:l
:
为所有mcache提供切分好的mspan资源。每个central保存一种特定大小的全局mspan列表,包括已分配出去的和未分配出去的。 每个mcentral对应一种mspan,而mspan的种类导致它分割的object大小不同。当工作线程的mcache中没有合适(也就是特定大小的)的mspan时就会从mcentral获取。
mcentral被所有的工作线程共同享有,存在多个Goroutine竞争的情况,因此会消耗锁资源
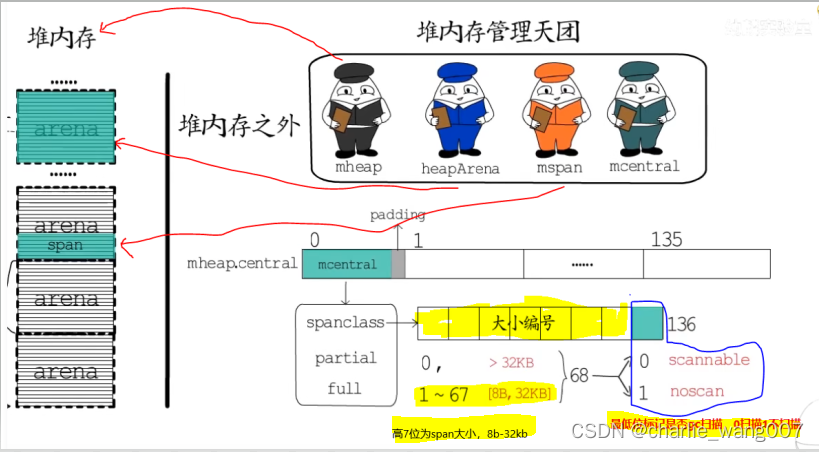
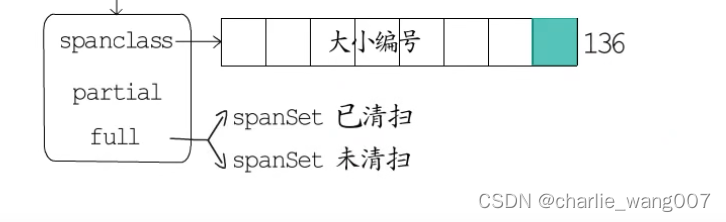
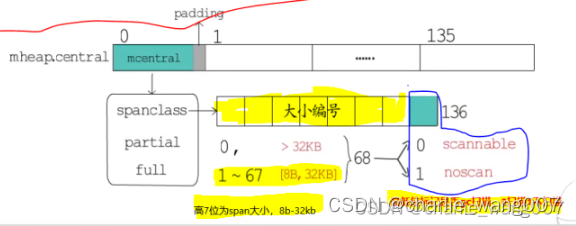
1mheap.central是一个数组,每个元素包含mcentral+padding,长度为136,每一个mcentral对应这一种规格的大小mspan(1-67种规格共68个,scan
68+noscan
68=136)
spancclass(高7位记录span的大小,最低位记录是否扫描),
partial-可用的span
full-已使用的span,分为已清扫和未清扫
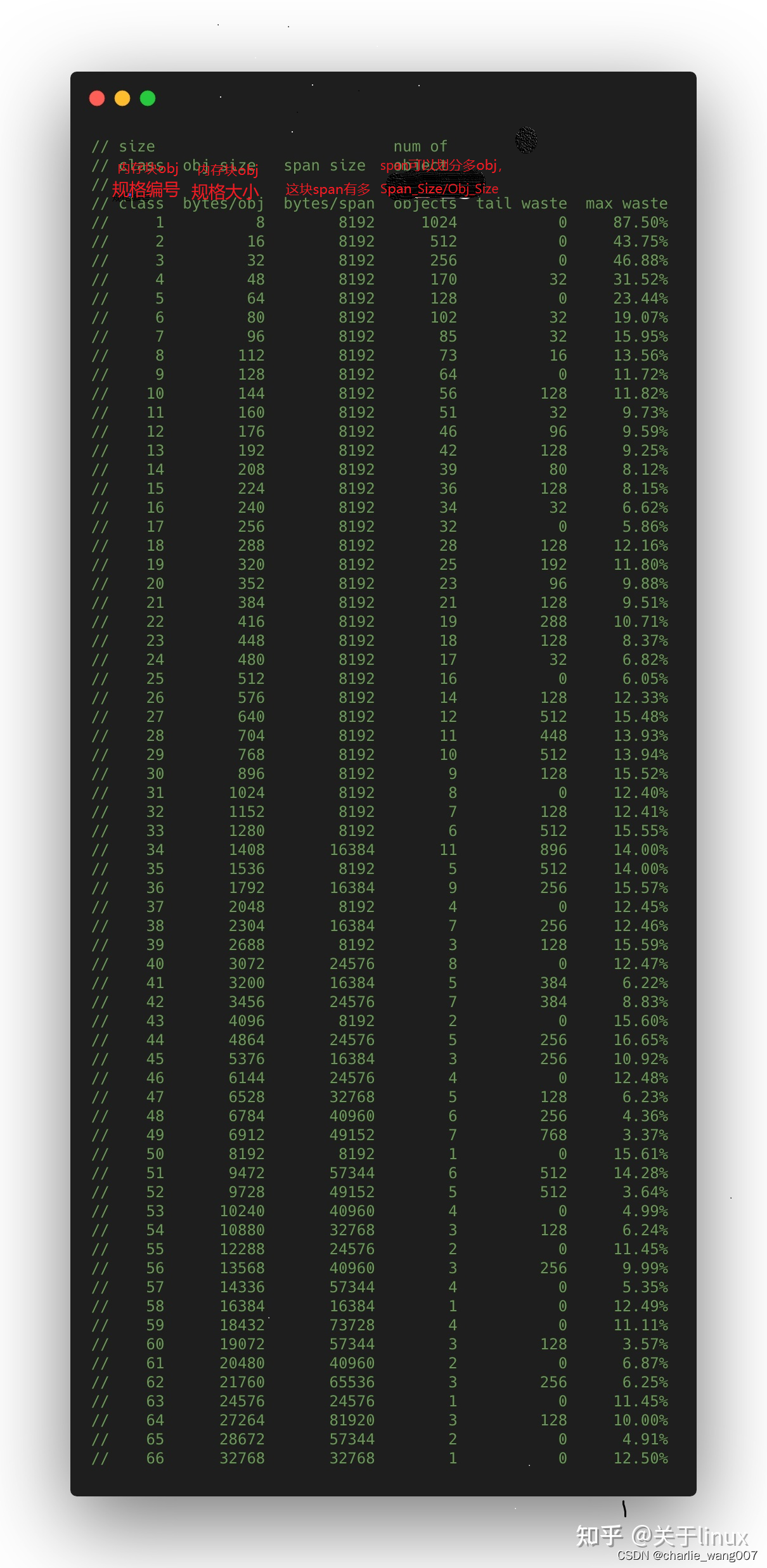
mspan规格:0-32kb
// path: /usr/local/go/src/runtime/sizeclasses.go
const _NumSizeClasses = 67
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536,1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
复制代码
规格对应的页数:
// path: /usr/local/go/src/runtime/sizeclasses.go
const _NumSizeClasses = 67
var class_to_allocnpages = [_NumSizeClasses]uint8{0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 2, 1, 2, 1, 3, 2, 3, 1, 3, 2, 3, 4, 5, 6, 1, 7, 6, 5, 4, 3, 5, 7, 2, 9, 7, 5, 8, 3, 10, 7, 4}
复制代码

对应关系:
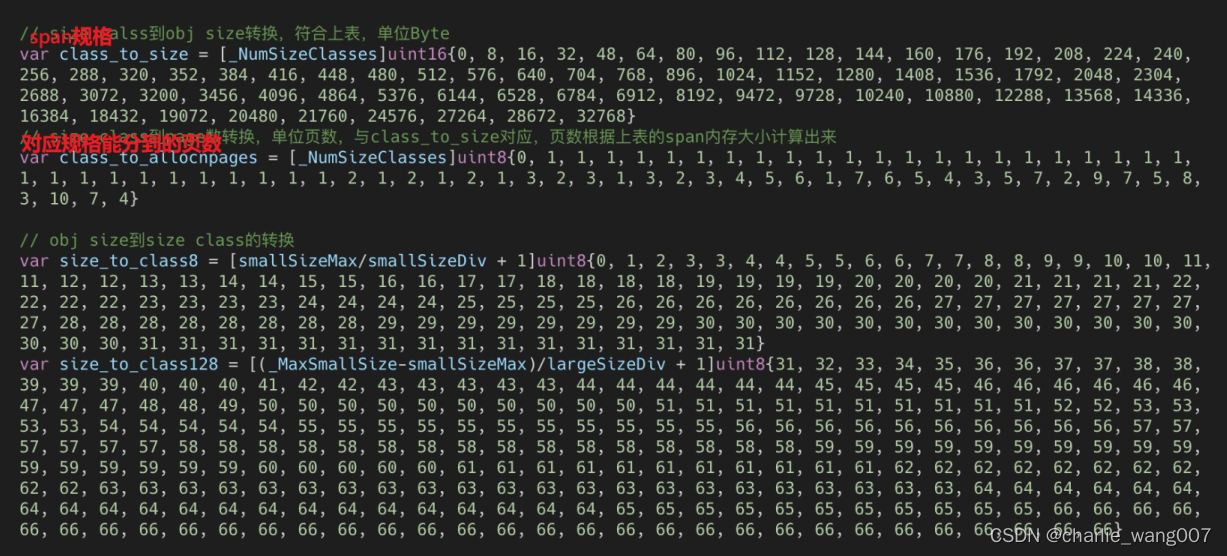
type mspan struct {
//指向下一个span的指针
next *mspan
//指向上一个span的指针
prev *mspan
list *mSpanList
//span第一个字节的地址
startAddr uintptr
//当前mspan的页数
npages uintptr // number of pages in span
//在mSpanManual的空闲对象
manualFreeList gclinkptr
//freeindex标记0~belems之间的插槽索引,标记的的是在span中的下一个空闲对象
//每次分配内存都从freeindex开始,直到遇到表示空闲对象的地方,之后调整freeindex使得下一次扫描能跳过上一次的分配
//若freeindex==nelem,则当前span没有了空余对象
//
//allocBits是这个span的位图
freeindex uintptr
// TODO: Look up nelems from sizeclass and remove this field if it
// helps performance.
nelems uintptr // number of object in the span.
//在freeindex处的allocBits的缓存.
//allocCache的最低位对应于freeindex位。
//allocCache保留allocBits的补码,从而允许ctz(计数尾随零)直接使用它。
//allocCache可能包含s.nelems以外的位; 呼叫者必须忽略这些。
//作用是记录未被使用的地址
allocCache uint64
//allocBits标记span中的elem哪些是被使用的,哪些是未被使用的
//gc,arkBits标记span中的elem哪些是被标记了的,哪些是未被标记的
allocBits *gcBits
gcmarkBits *gcBits
// sweep generation:
// if sweepgen == h->sweepgen - 2, the span needs sweeping
// if sweepgen == h->sweepgen - 1, the span is currently being swept
// if sweepgen == h->sweepgen, the span is swept and ready to use
// if sweepgen == h->sweepgen + 1, the span was cached before sweep began and is still cached, and needs sweeping
// if sweepgen == h->sweepgen + 3, the span was swept and then cached and is still cached
// h->sweepgen is incremented by 2 after every GC
sweepgen uint32
divMul uint16 // for divide by elemsize - divMagic.mul
baseMask uint16 // if non-0, elemsize is a power of 2, & this will get object allocation base
allocCount uint16 // number of allocated objects
spanclass spanClass // size class and noscan (uint8)
state mSpanState // mspaninuse etc
needzero uint8 // needs to be zeroed before allocation
divShift uint8 // for divide by elemsize - divMagic.shift
divShift2 uint8 // for divide by elemsize - divMagic.shift2
scavenged bool // whether this span has had its pages released to the OS
elemsize uintptr // computed from sizeclass or from npages
unusedsince int64 // first time spotted by gc in mspanfree state
limit uintptr // end of data in span
speciallock mutex // guards specials list
specials *special // linked list of special records sorted by offset.
//path: /usr/local/go/src/runtime/mcentral.go
type mcentral struct {
// 互斥锁
lock mutex
// 规格
sizeclass int32
// 尚有空闲object的mspan链表
nonempty mSpanList
// 没有空闲object的mspan链表,或者是已被mcache取走的msapn链表
empty mSpanList
// 已累计分配的对象个数
nmalloc uint64
}
复制代码
empty表示这条链表里的mspan都被分配了object,或者是已经被cache取走了的mspan,这个mspan就被那个工作线程独占了。而nonempty则表示有空闲对象的mspan列表。每个central结构体都在mheap中维护。
简单说下mcache从mcentral获取和归还mspan的流程:
1,获取 加锁;从nonempty链表找到一个可用的mspan;并将其从nonempty链表删除;将取出的mspan加入到empty链表;将mspan返回给工作线程;解锁。
2 ,归还 加锁;将mspan从empty链表删除;将mspan加入到nonempty链表;解锁。
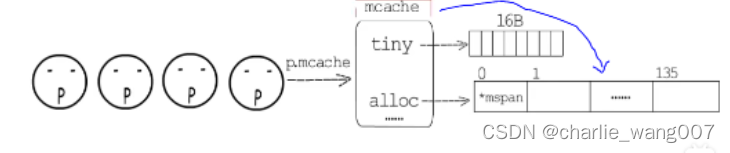
本地span管理-p.mcache
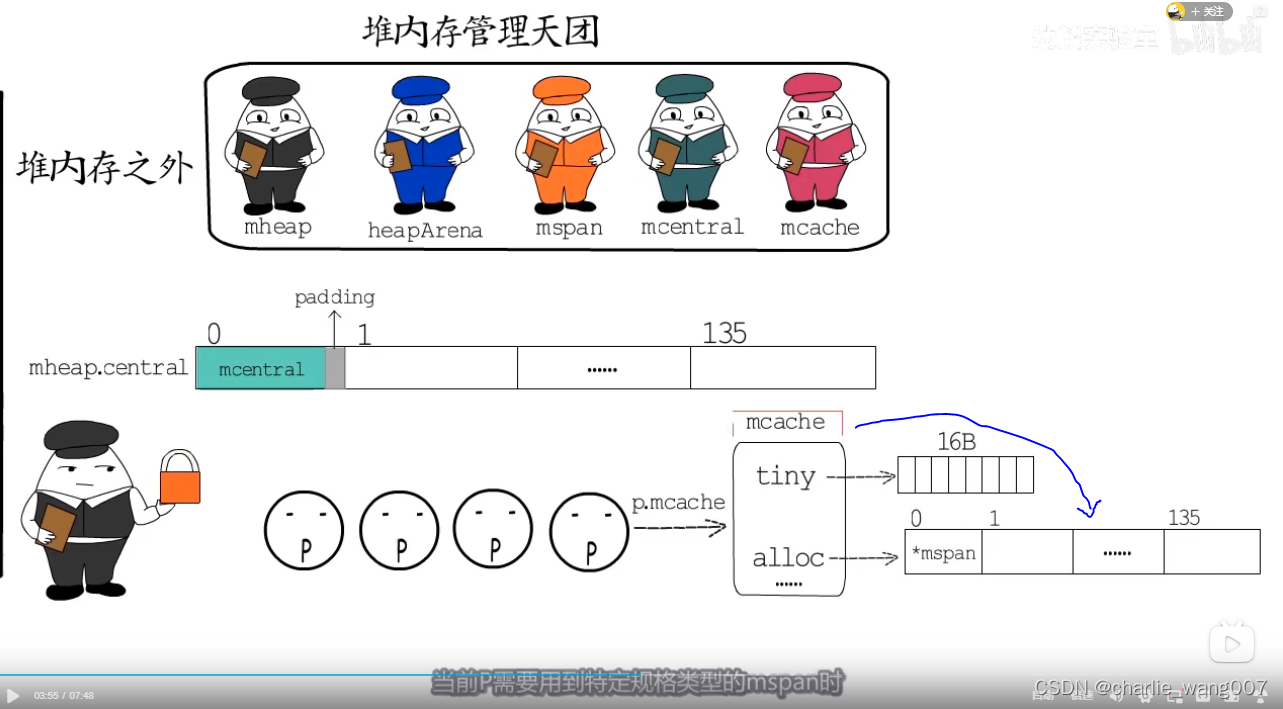
为了解决p的频繁加锁解锁,每一个p带有一个mcache,当p需要某一大小的内存时,先去本地mspan找对应的内存
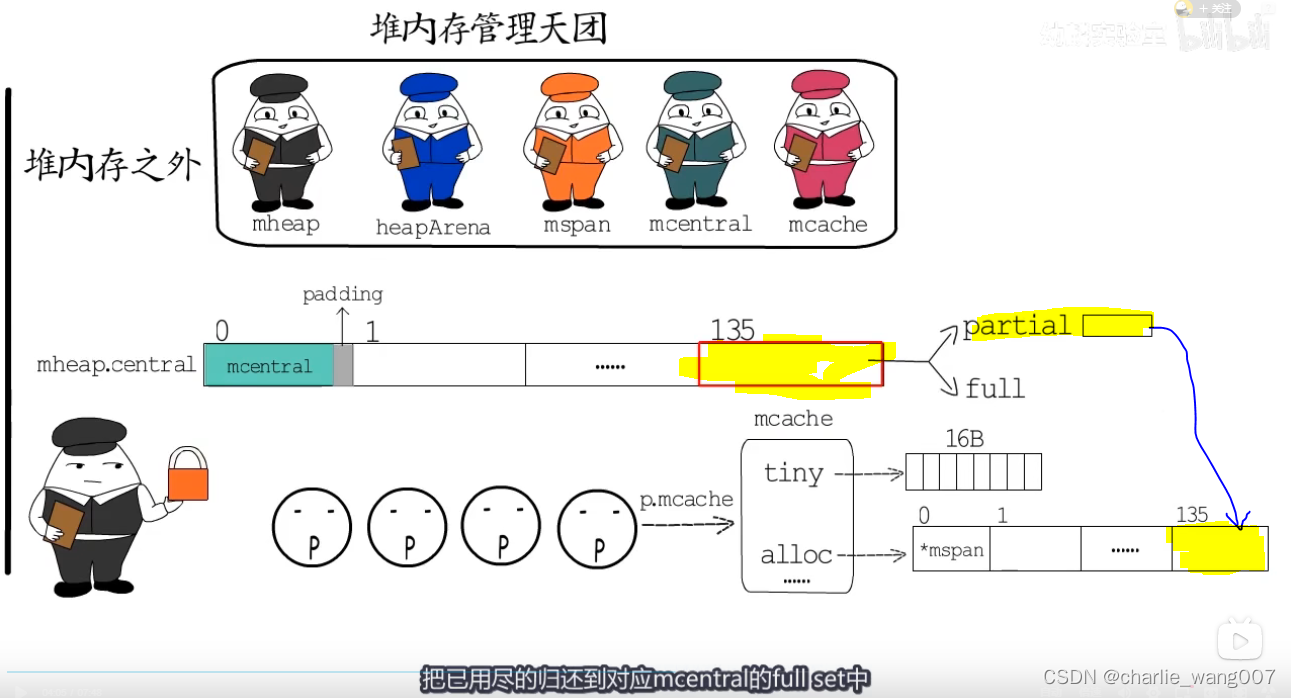
如果本地缓存找不到,则从mcentral可用span中找到对应大小的内存放到本地
把已用尽的放到mcertal的full中
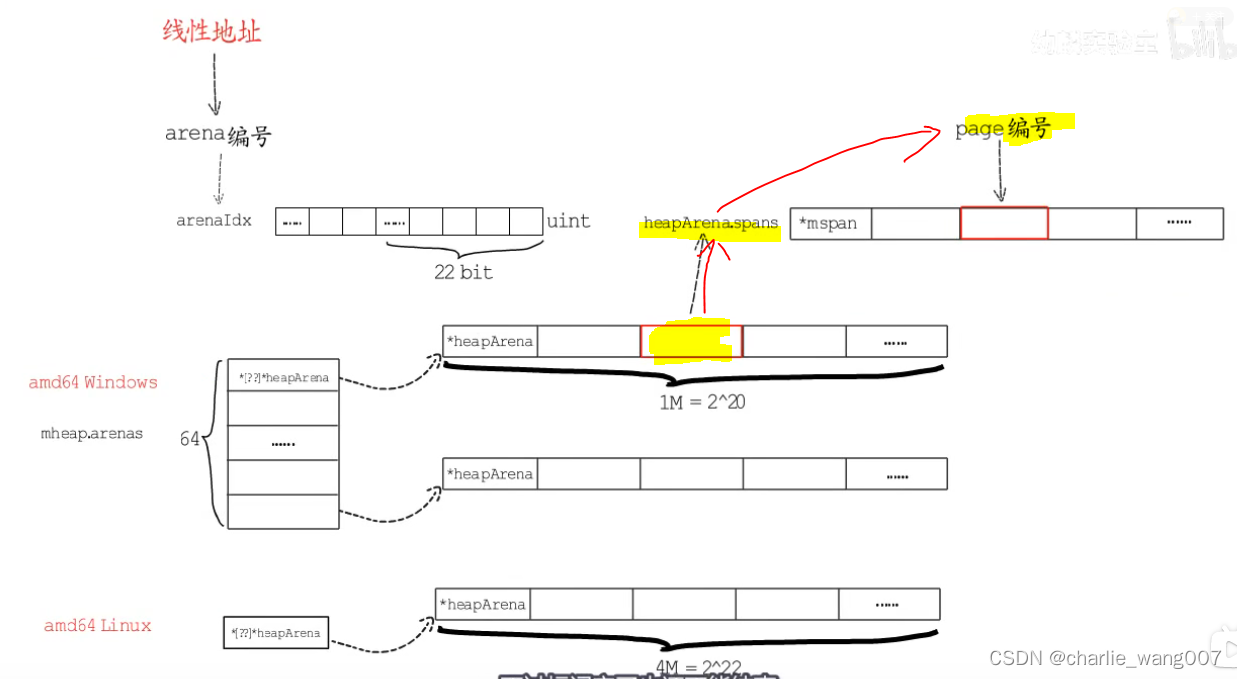
arena元数据–heaparena
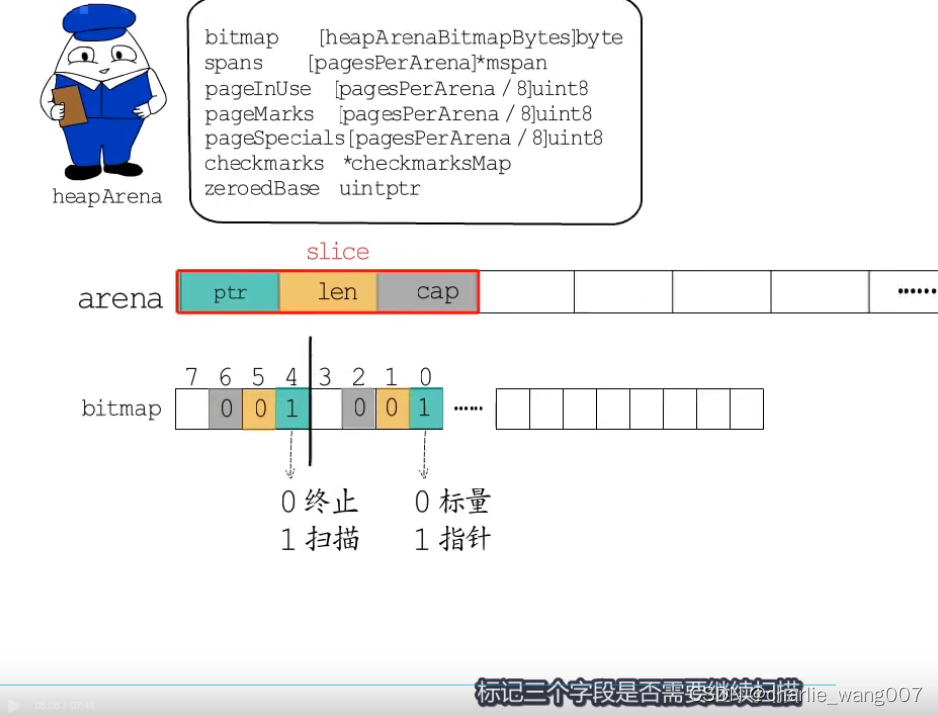
1 heaparena存储arena的元数据
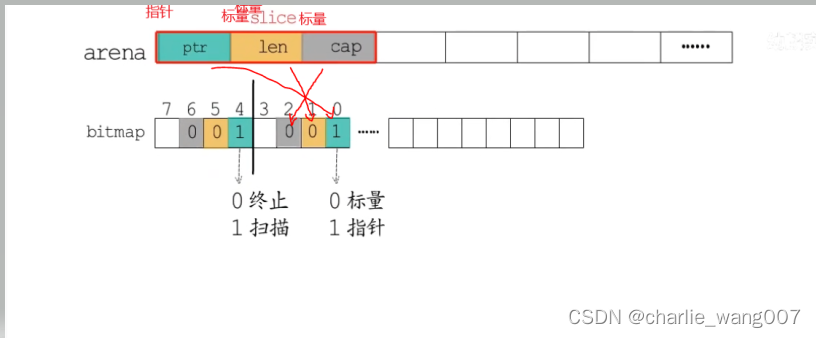
2 btimap用1位(bit)标记arena中一个指针大小的内存(8byte)是指针还是标量
3 bitmap用1字节(1byte)标记arena中4个指针大小的空间(4*8byte)
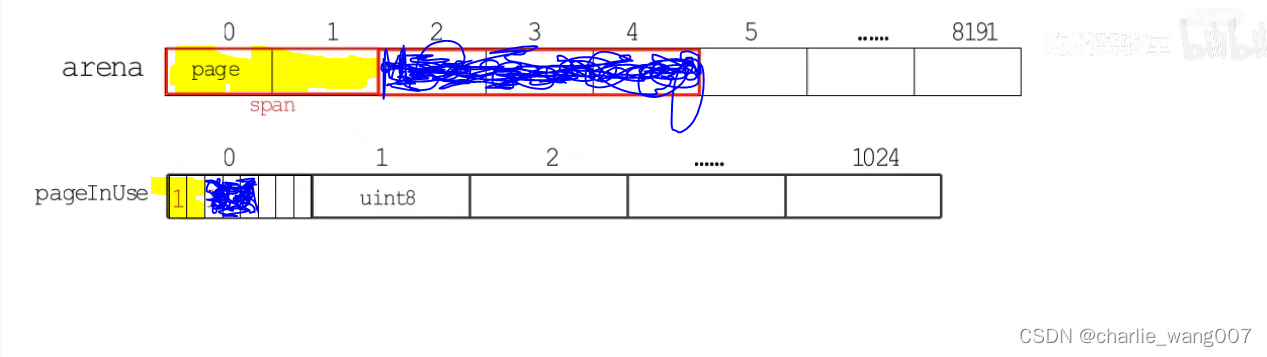
1 pageinuse长度为1024的数组,每一个元素分8位,8*1024=8192,标记使用中span
2 uint8的每一位对应span包含几个page,每个span的第一位标记为1
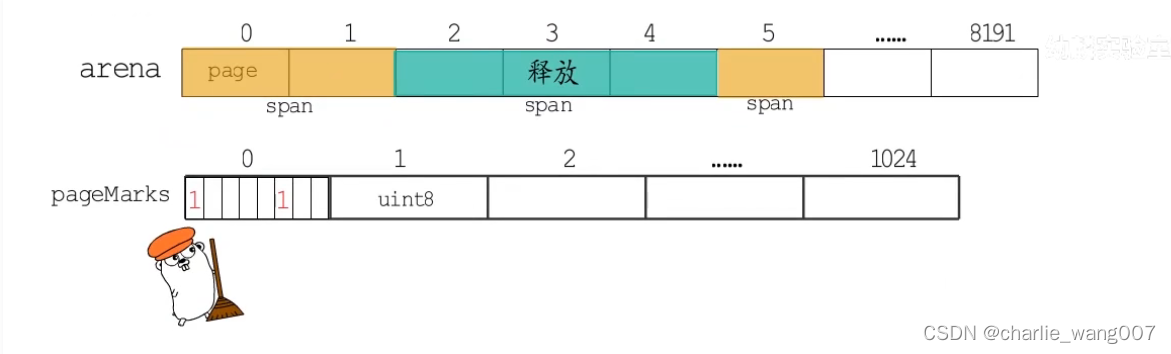
1 pagemarke用于gc标记,与pageinuse标记方法一样,标记span的首位
2 在gc标记阶段(gc工作过程的一个阶段)会修改这个位图,不需要清扫的做标记
3 在gc清扫阶段,扫描这个位图,没有被gc标记的释放
arena.spans.mspan:
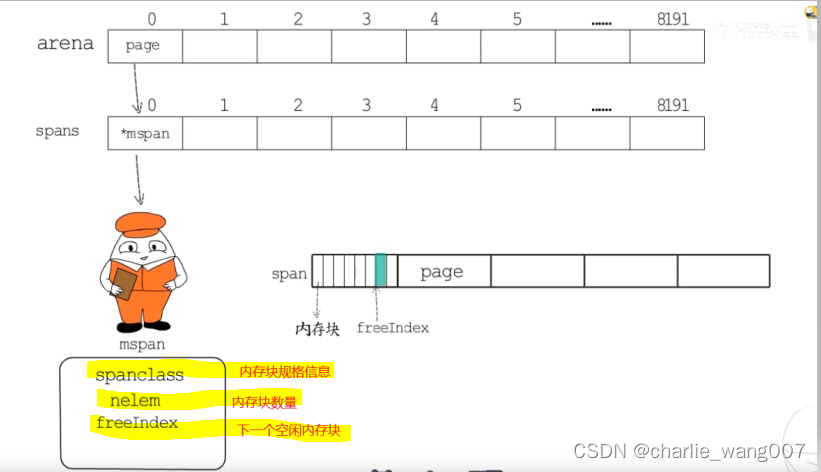
1 spans 也分成8192个长度的数组,存放mspan结构体,,用于定位arena中一个page对应的mspan在哪
2 mspan管理的是一个span中连续的page
3 mspan也将span划分成规格大小不同的内存块,
spaceclass记录内存块规格大小
nelem记录内存块数
freeindex记录下一个空闲内存块的位置
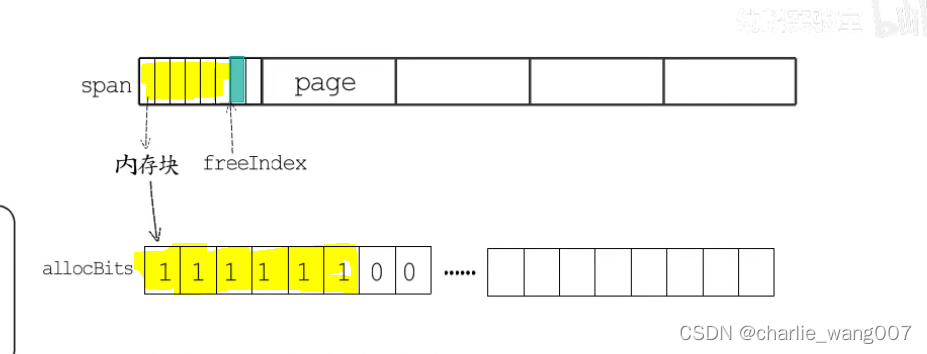
allocbits直接对应划分好的内存块,已经分配的标记为1,空闲的标记为0
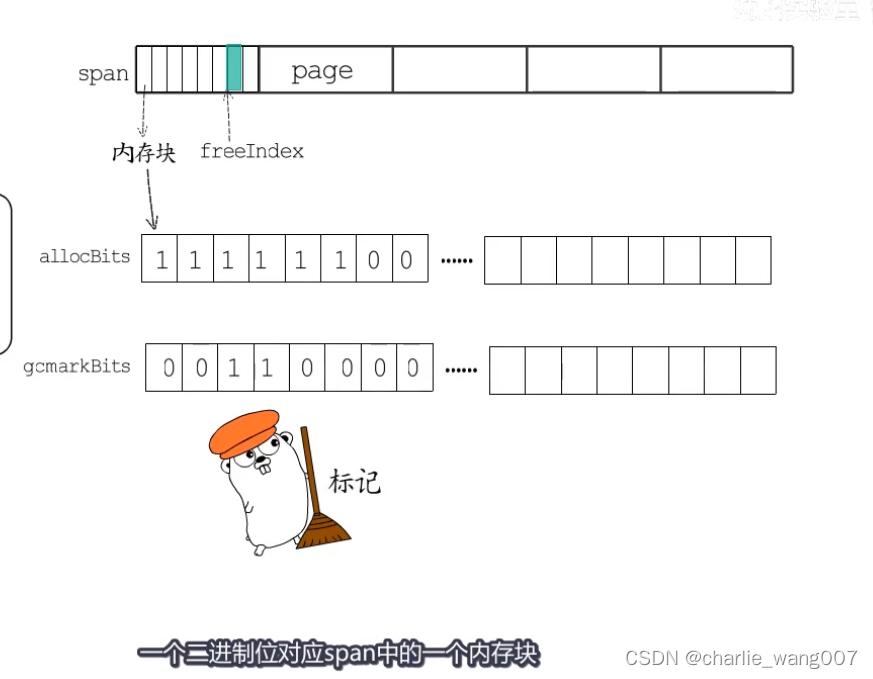
1 gcmarkbits用于gc标记,在gc标记阶段对这个位图标记,与span的内存块一一对应
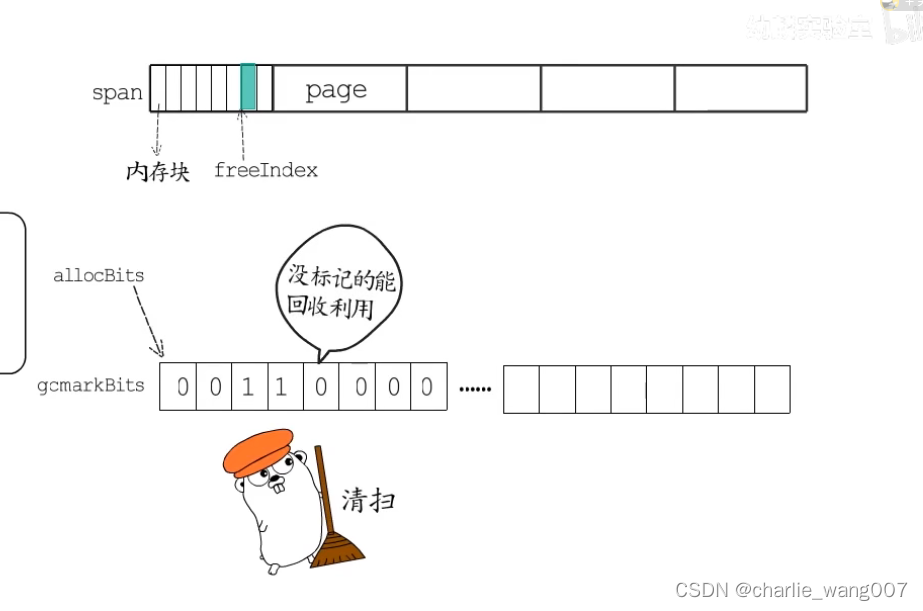
2 gc清扫阶段,释放掉旧的allocbits,gcmarkbits成为新的allocbits,没标记的被回收成为空闲内存块,标记的即是已分配内存块
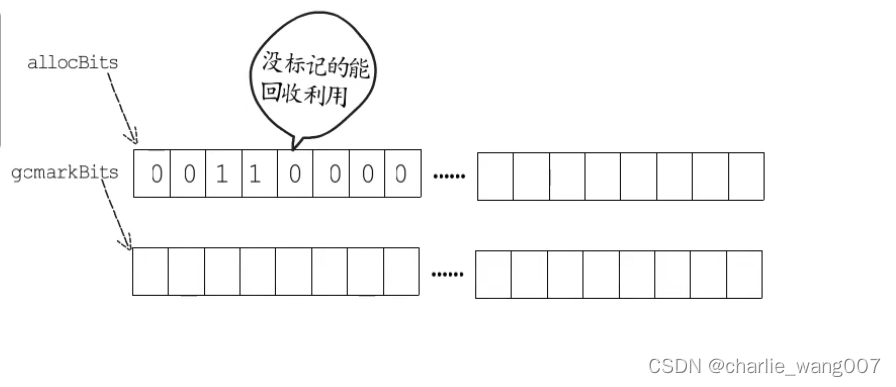
再重新分配一块内存给gcmarkbits
堆内存分配
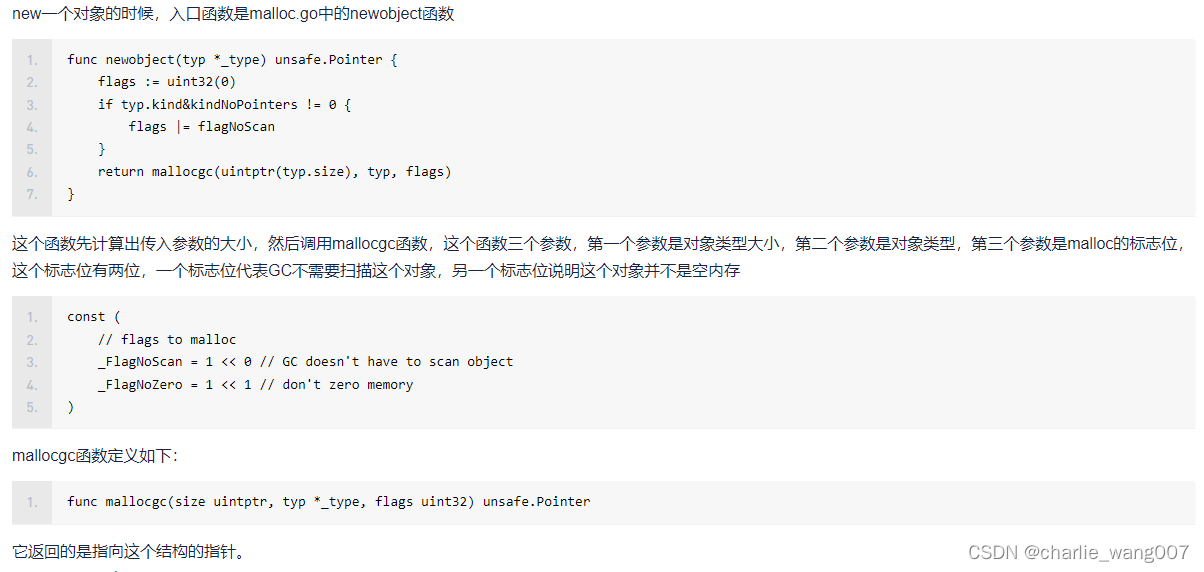
malloc函数时堆内存分配的关键函数,主要工作包含:
1 辅助gc
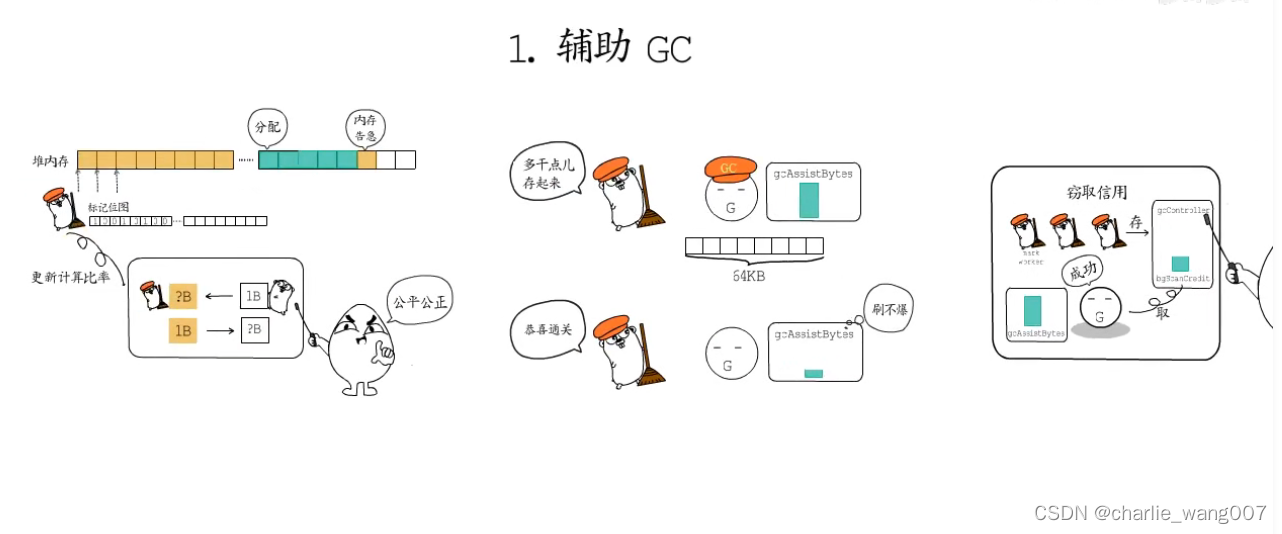
1 申请内存时gc还没有标记完成,当前协程需要辅助gc完成扫描,每次执行64kb的标记工作
2 借代偿还
3 信用窃取
2 空间分配
if size <= maxSmallSize {
if noscan && size < maxTinySize {
// 使用tiny allocator分配
} else {
// 使用mcache.alloc中对应的mspan分配
}
} else {
// 直接根据需要的页面数,分配大的mspan
}
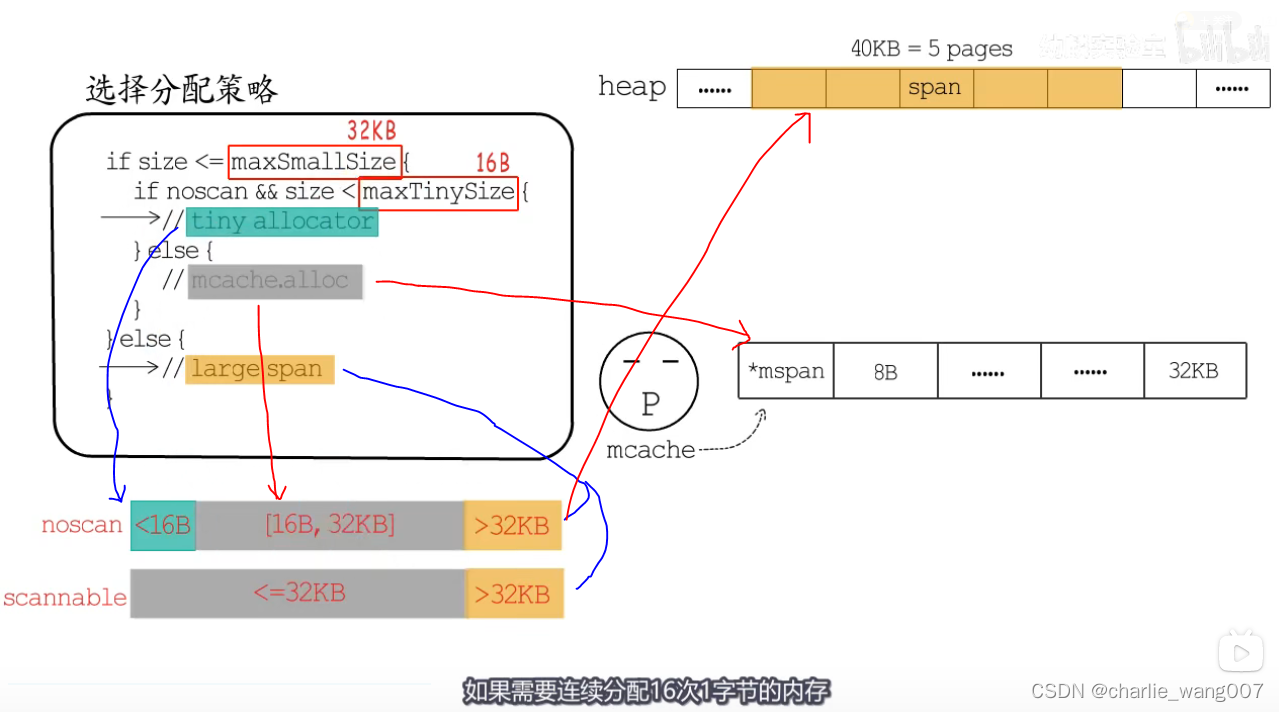
分配策略:
1依据申请内存的大小
2 依据scan noscan分配
a,tiny allocator:
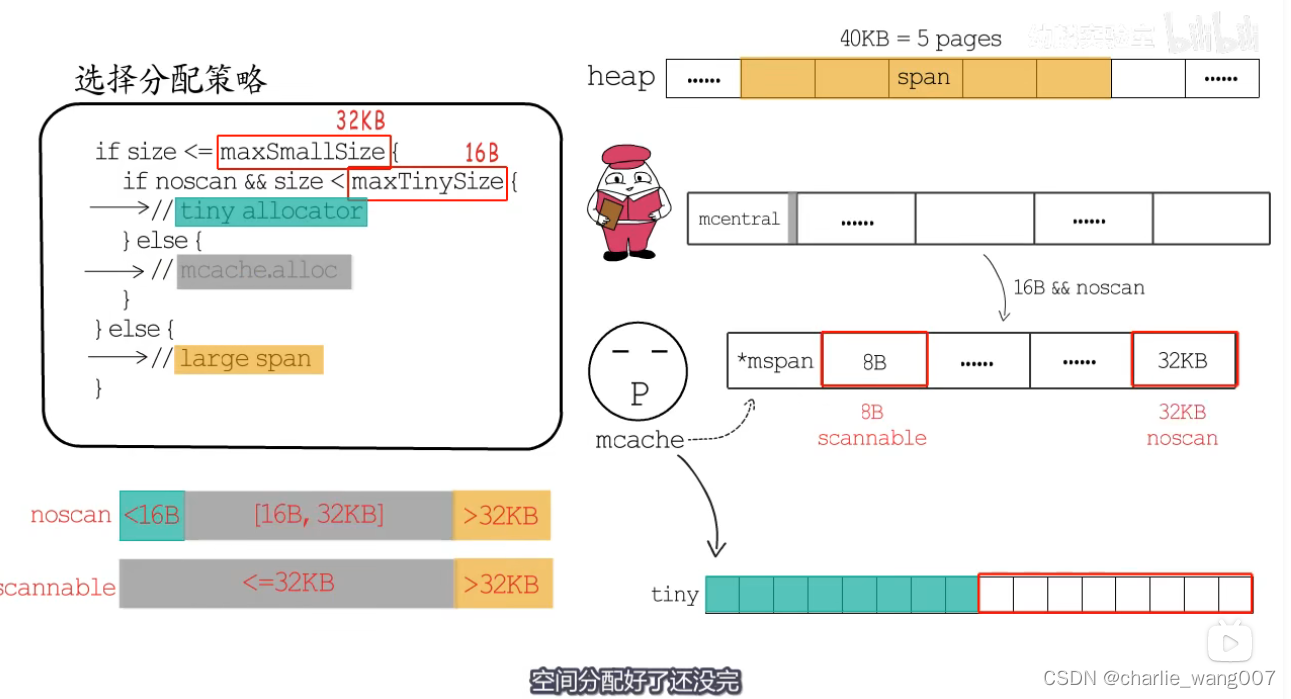
1 mcache有一段tiny内存 小16b专门用来给申请小内存的协程
2 mcache.offset记录这段内存用到哪里了
3 收到申请后,offset对其后如果够用就直接分配,如果不够用就从当前P的mcache中重新拿16字节大小的空间,如果本地mcache也没有足够的空间,就从mcentral中拿一个span过来
b,16b-32kb:
mspan分配
c,largespan:
直接从heap上分配对应大小的pages即可
3 位图标记
前面学习了
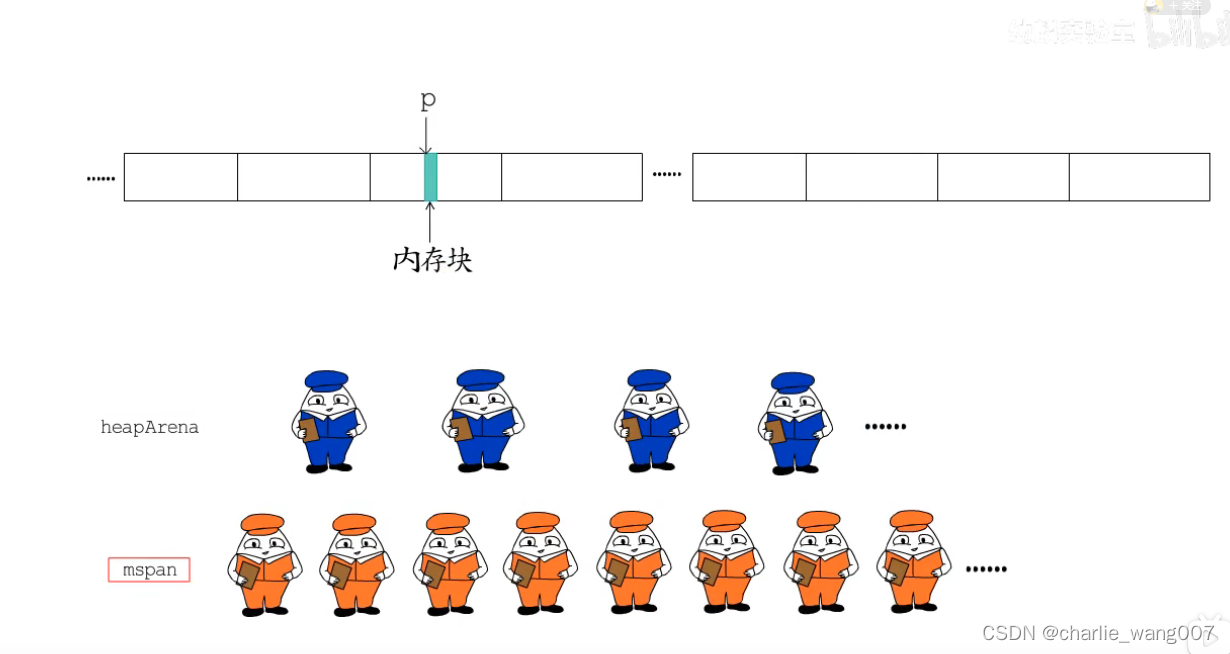
已知一块内存的地址,如何找到对应的heaparena和mspan
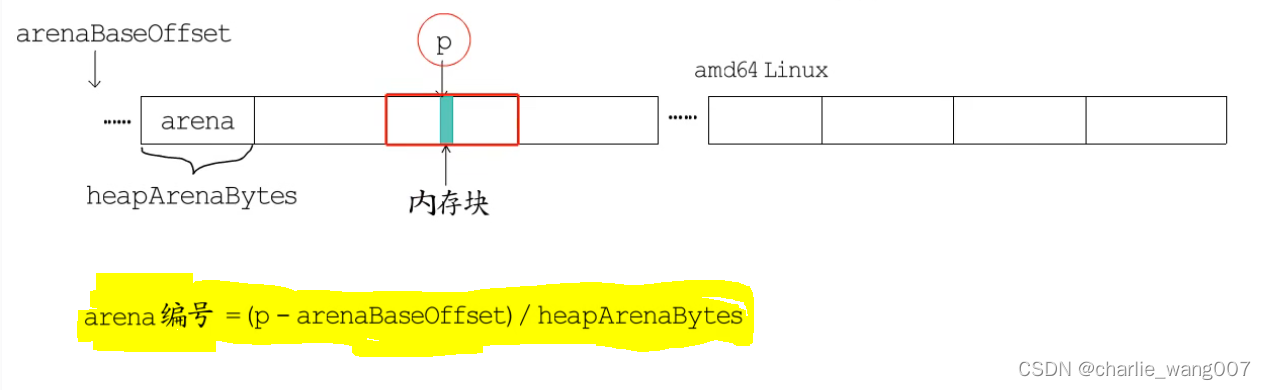
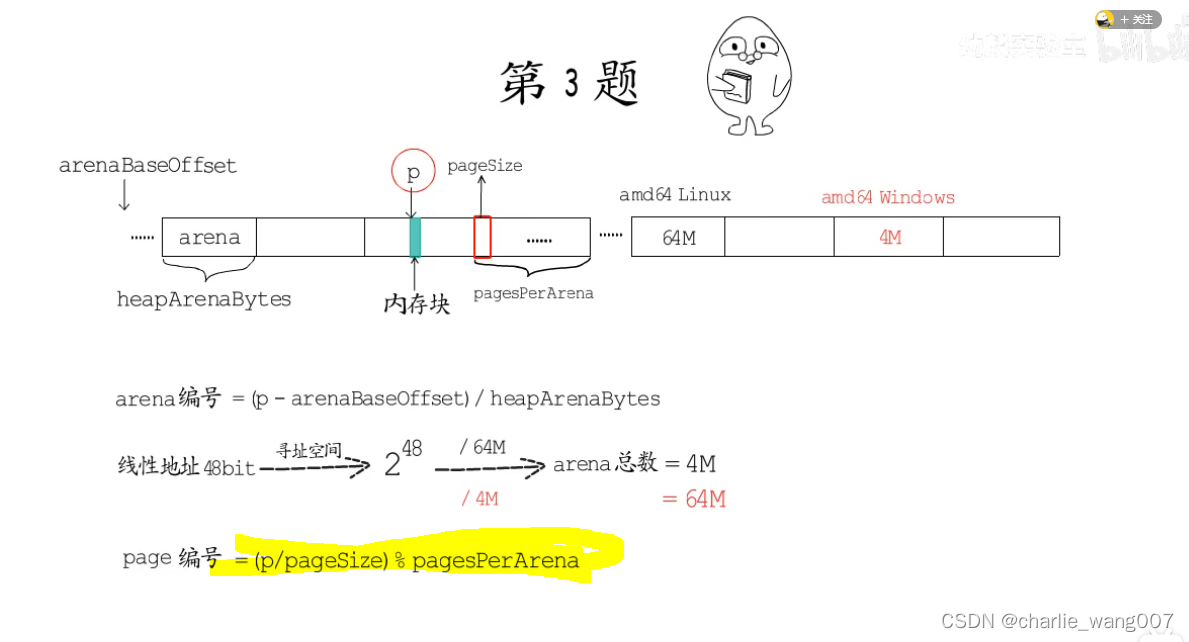
1 已知内存块的地址p,求这个内存块在第几个arena中
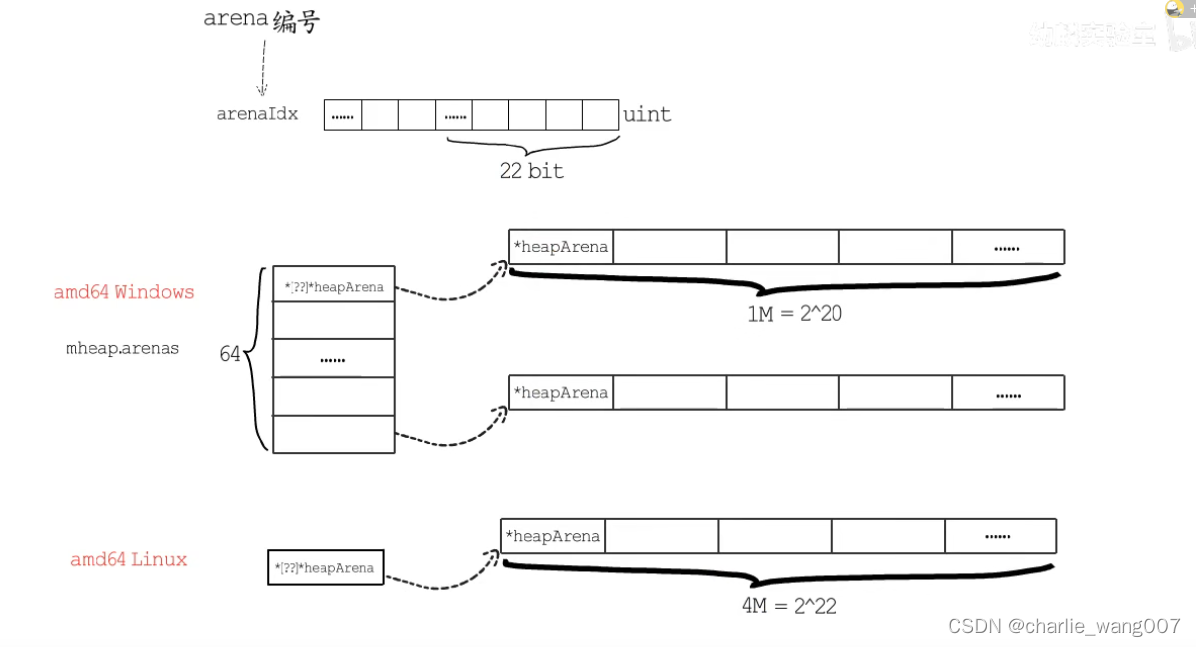
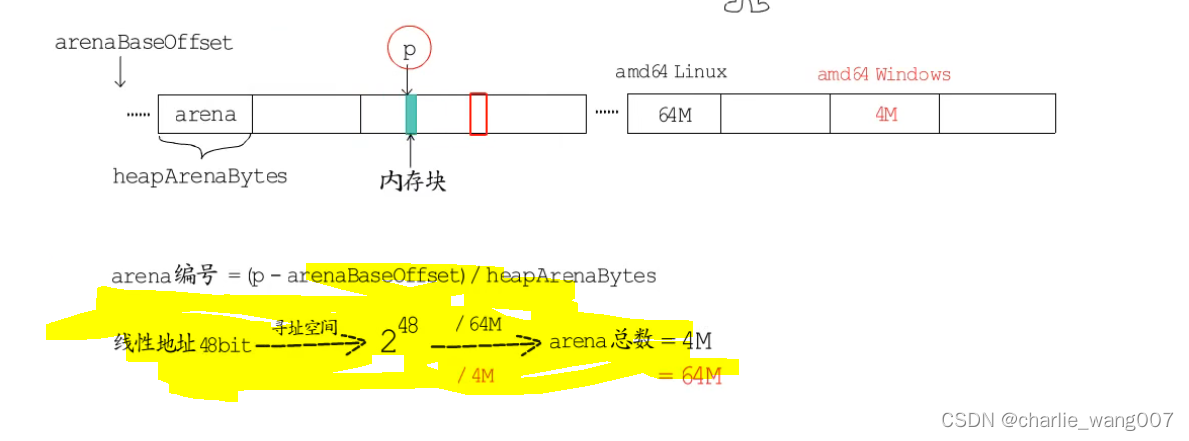
heaparena用二进制存储二维的地址信息
4 收尾工作
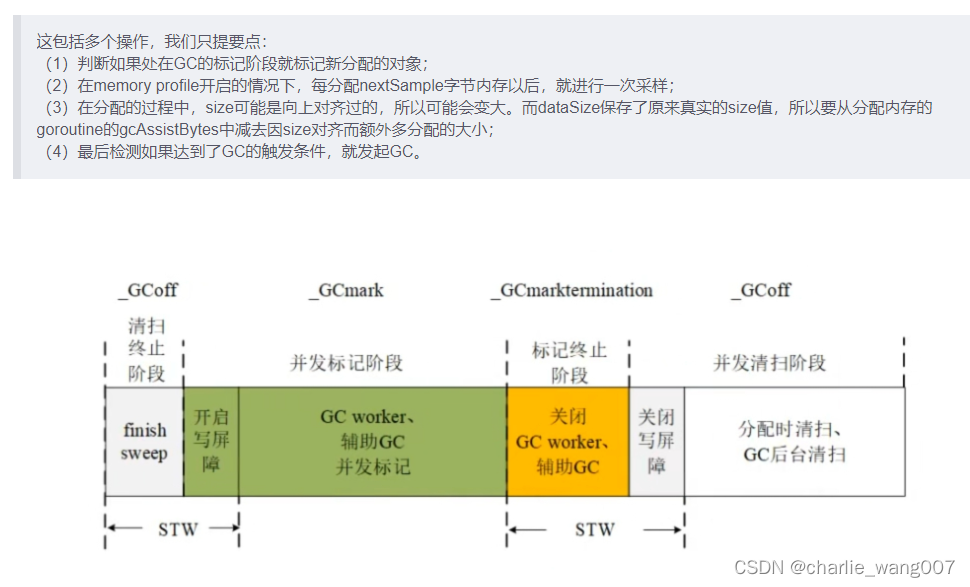
如果当前分配处在gc标记阶段,要对新分配的地址进行标记,如果达到触发gc的标准,也要进行gc标记
栈
1栈的空间来自于堆的span
2栈也分为全卷栈和本地栈
3栈也有分配和回收
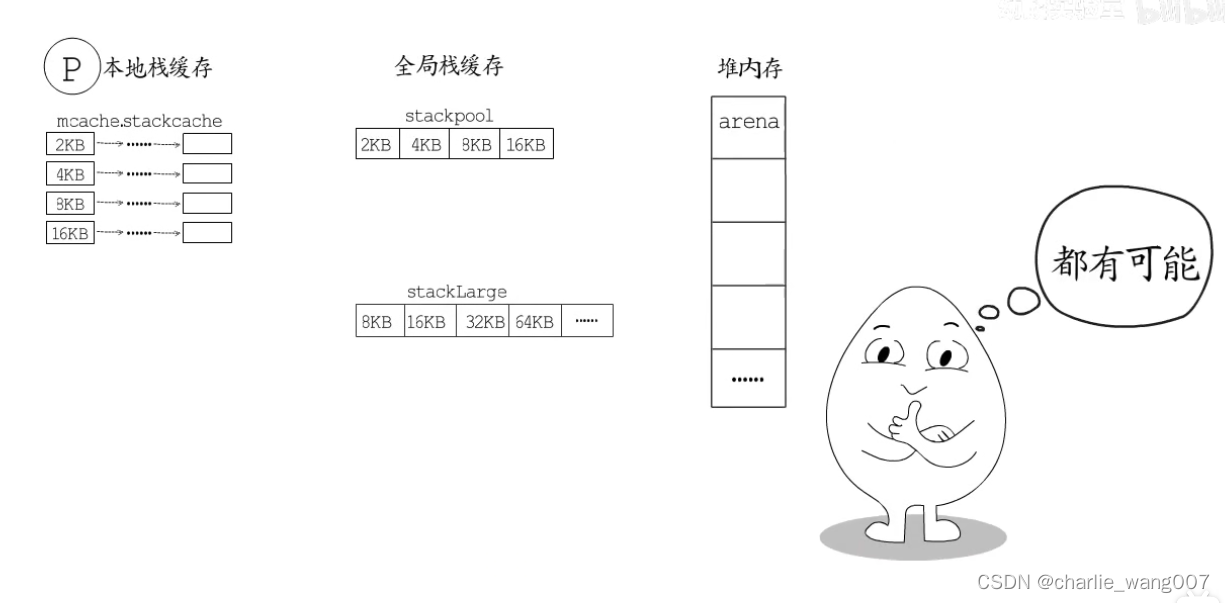
栈分配
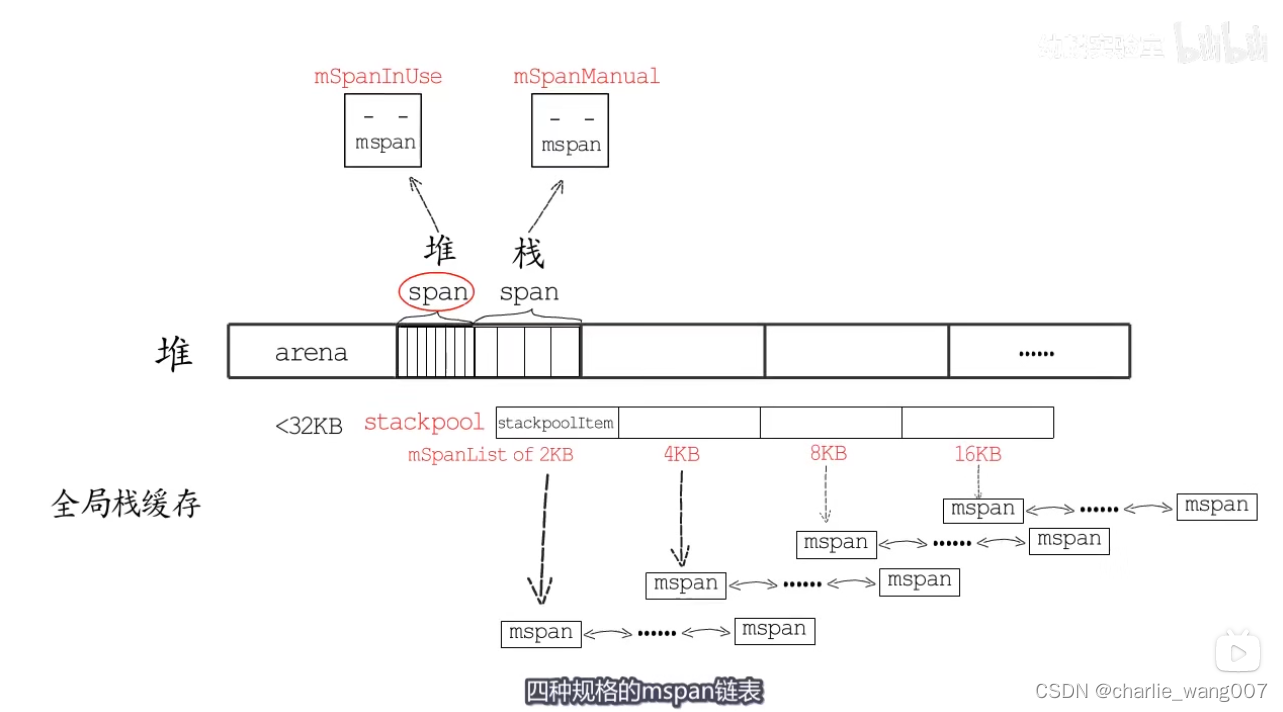
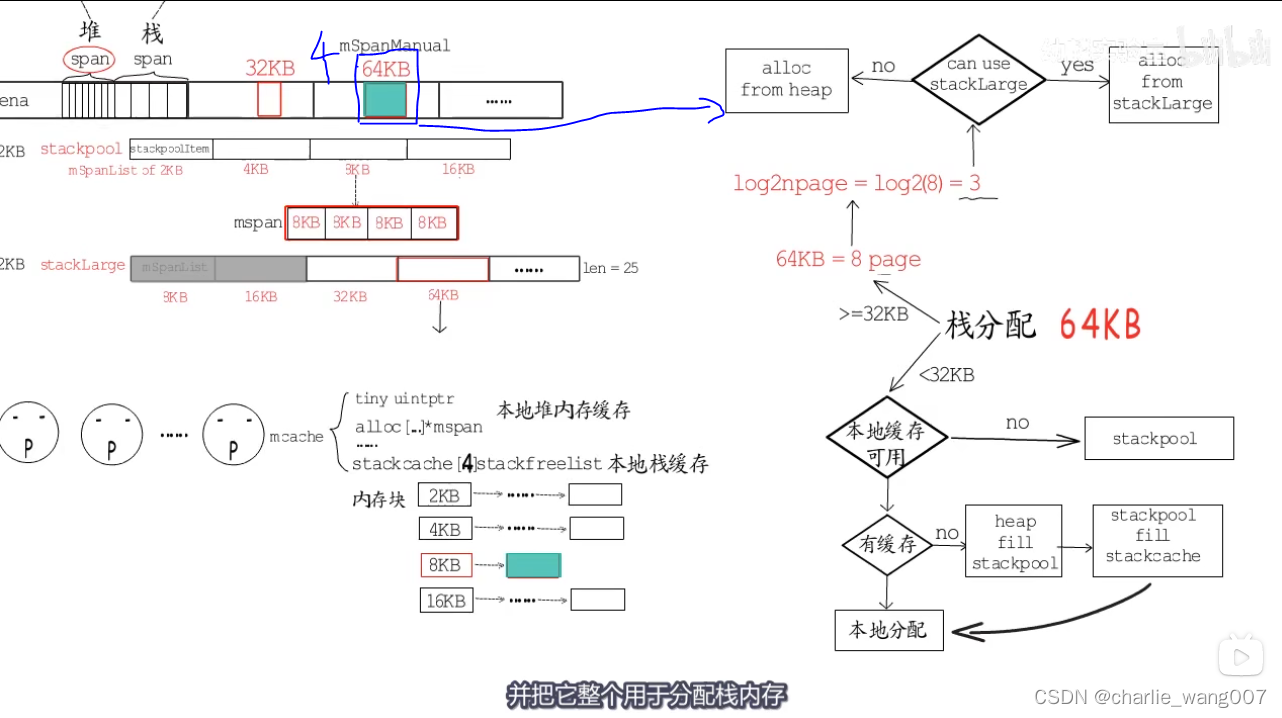
stackpool管理32kb以下的内存块
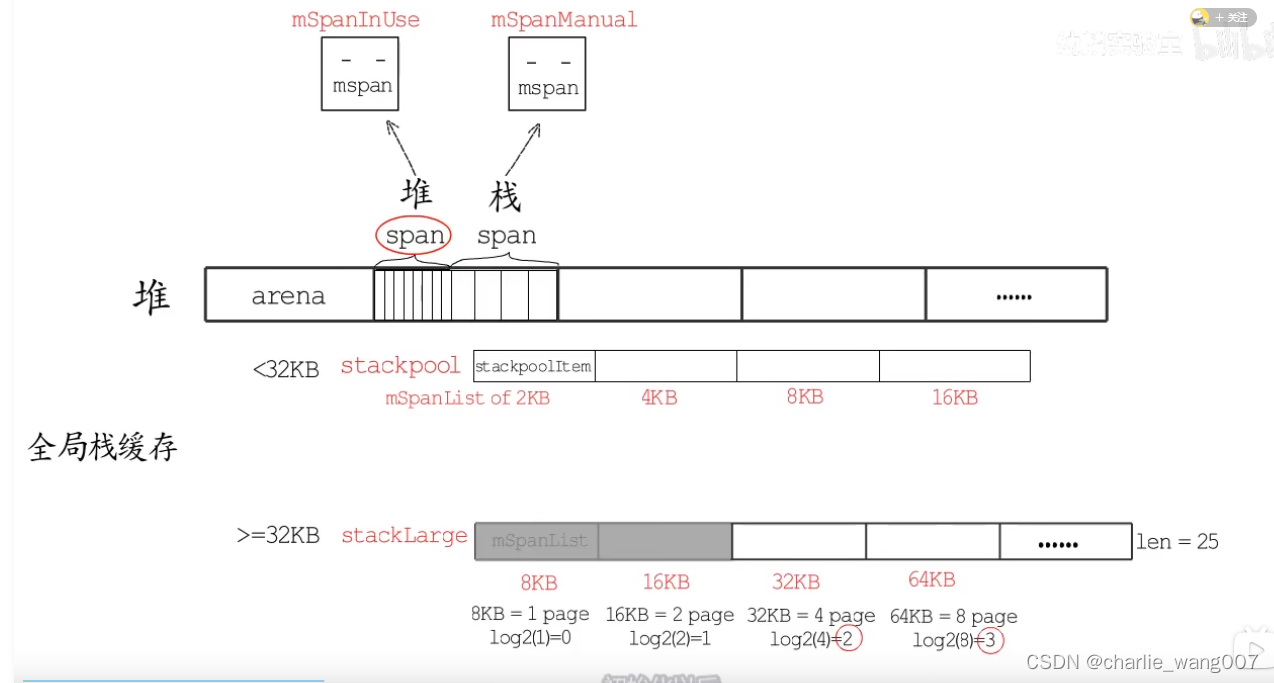
大于32kb由stacklarge分配
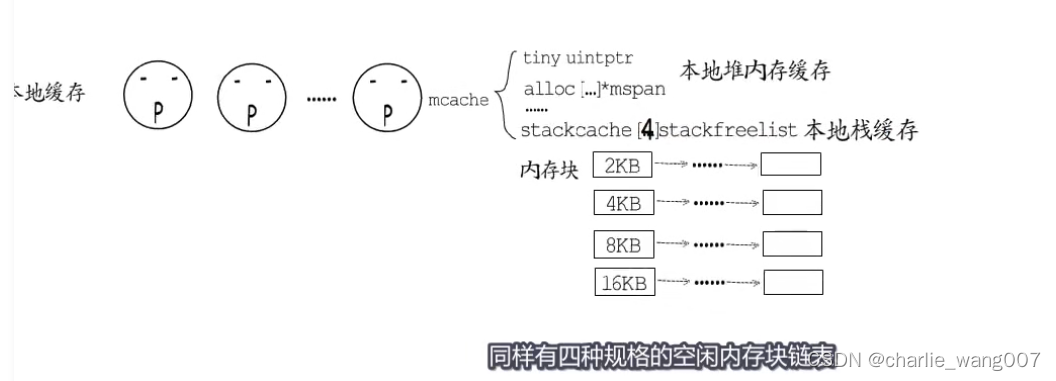
1 同时与堆内存一样,每个p也带有用于本地栈分配的本地缓存
2 本地栈缓存有四种规格,要分配栈缓存时,小于23kb,优先使用当前p的本地缓存
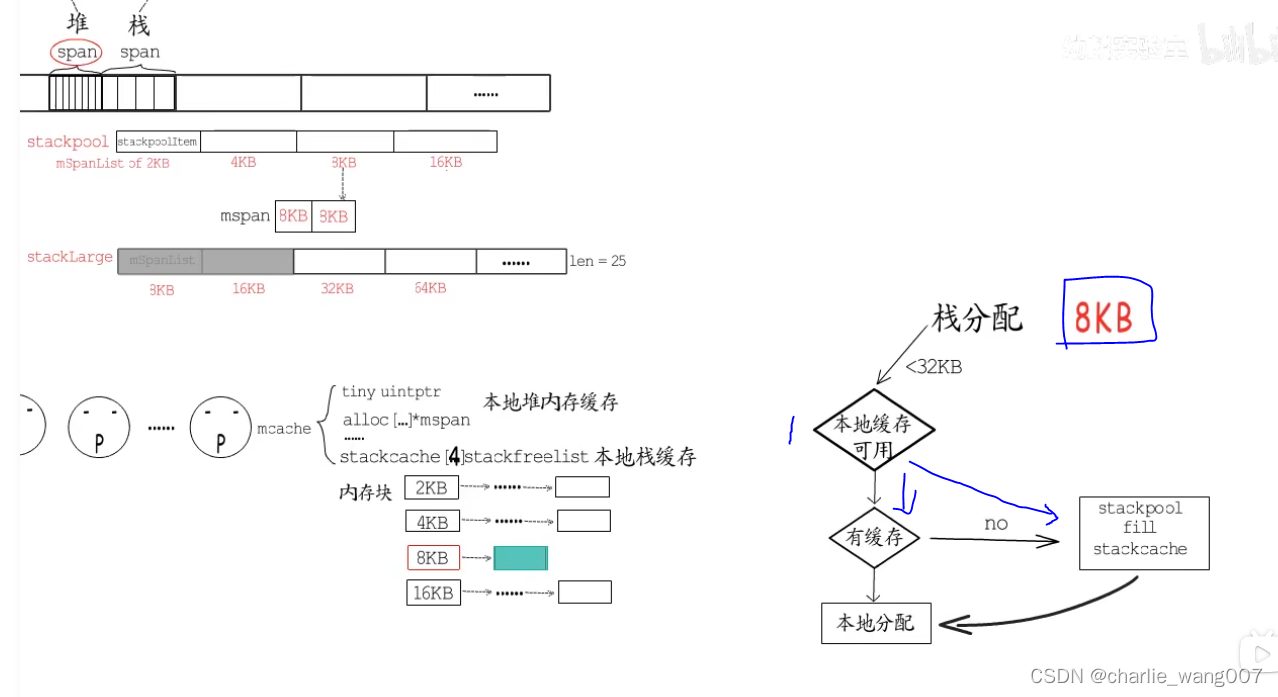
1,本地有对应规格的缓存,直接分配
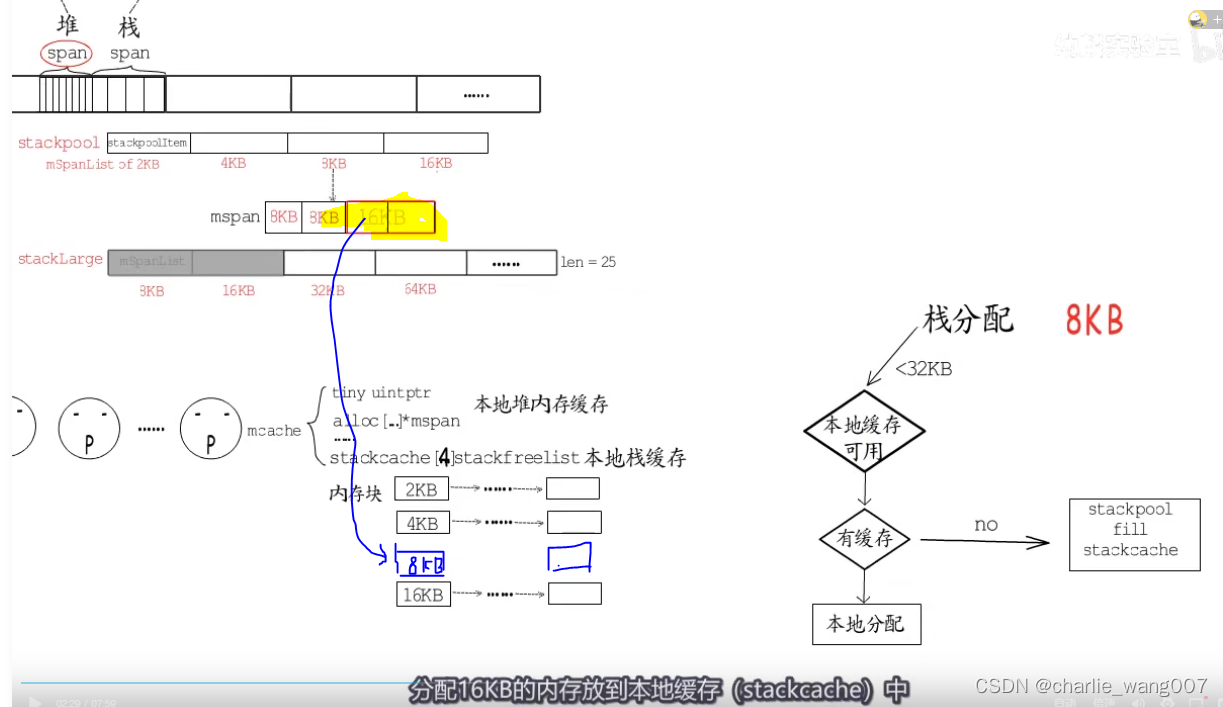
2本地没有对应规格的缓存,从stackpool分配16kb放到本地,分配给p
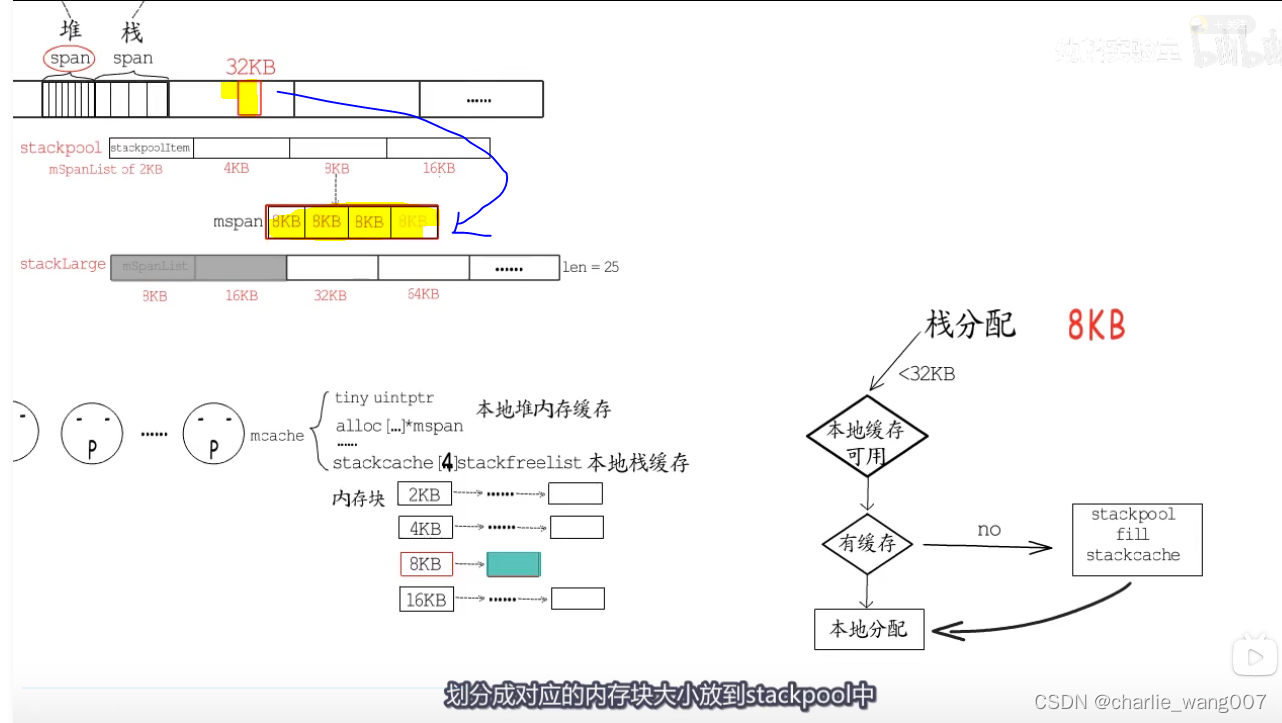
若stackpool也没有对应规格的缓存,则从堆的span中分配32kb,分成4份放到stackpool中
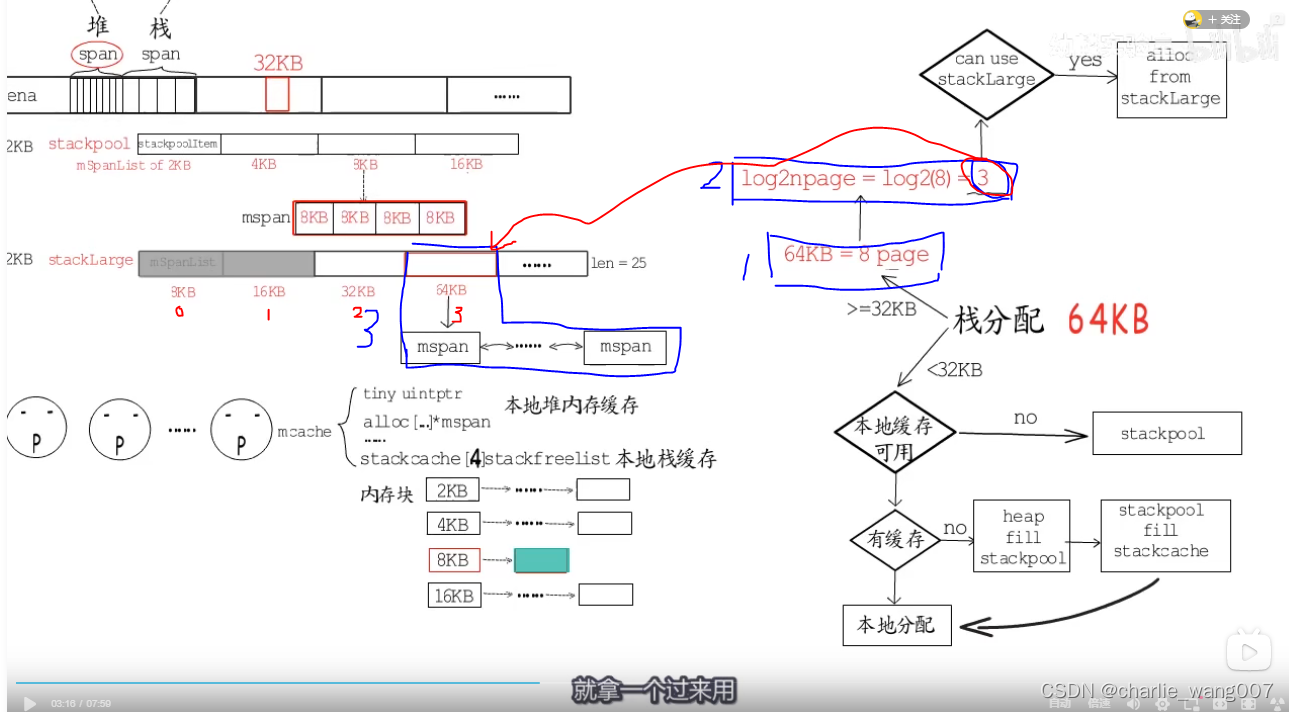
不能从本地栈缓存分配的情况
1 以64kb为例,先计算分几个page ,64/8=8个
2 计算对数,得到stacklarge的下标为3
3 找到stacklarge对应下标的位置,若找到的链表内存为空。直接使用
4 若找到的链表内存不为空,则直接从heap分配64kb的内存块来作为栈内存
栈增长
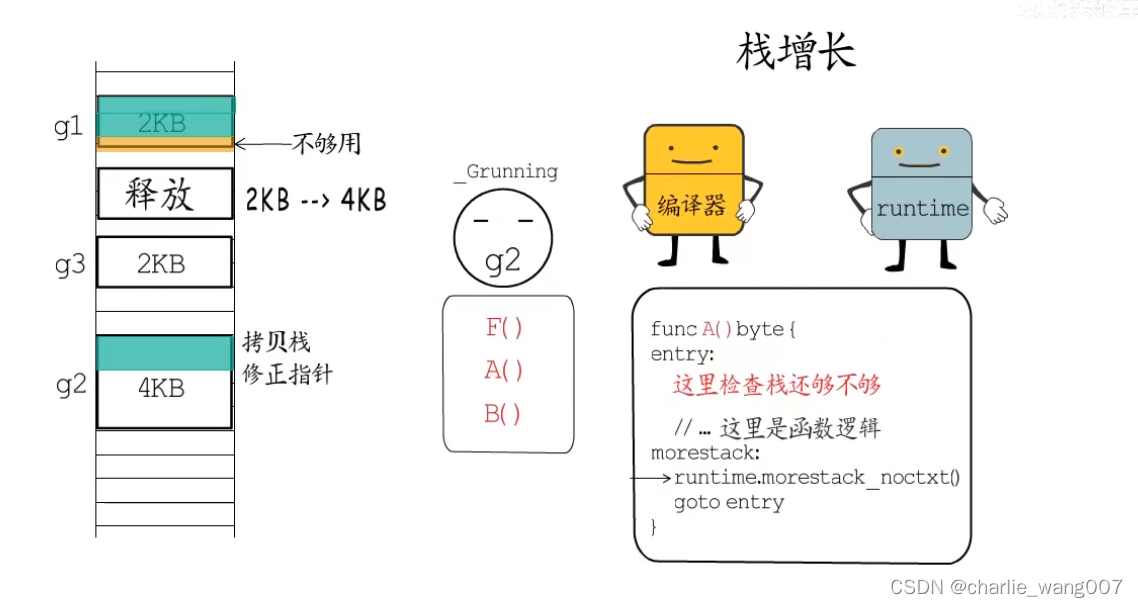
1 栈缓存在gorountine运行是创建,出世大小为2kb
2 栈的检查和增加由编译器和runtime共同完成,编译器在函数同步安插检测代码,检查剩余栈空间是否足够
3 不够用调用runtime函数来增长栈空间,一般*2,并将协程状态置为gcopystack,调用copystack函数拷贝旧栈数据到新栈,释放就栈缓存,更新指针,恢复协程运行
栈收缩
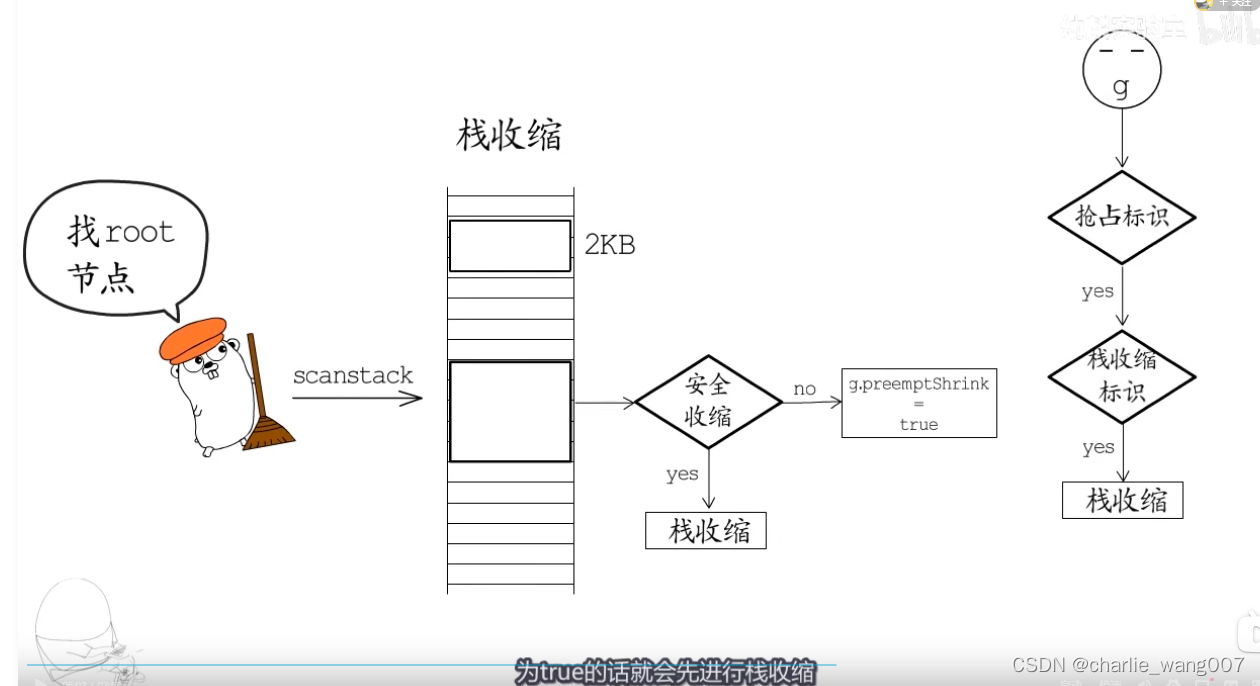
1 栈收缩有gc完成
2 gc调用scanstack函数进行栈扫描,确认可以安全收缩则收缩到初始大小
3 不能马上收缩的,先标记,在协程检测到抢占标识让出cpu时,再检查收缩标识,为true就可以收缩,收缩后让出cpu
结束运行的协程栈如何处理
1运行结束的goroutine一般会放到空闲队列,创建新的gotoutine是先从哲理获取,先获取有栈的协程
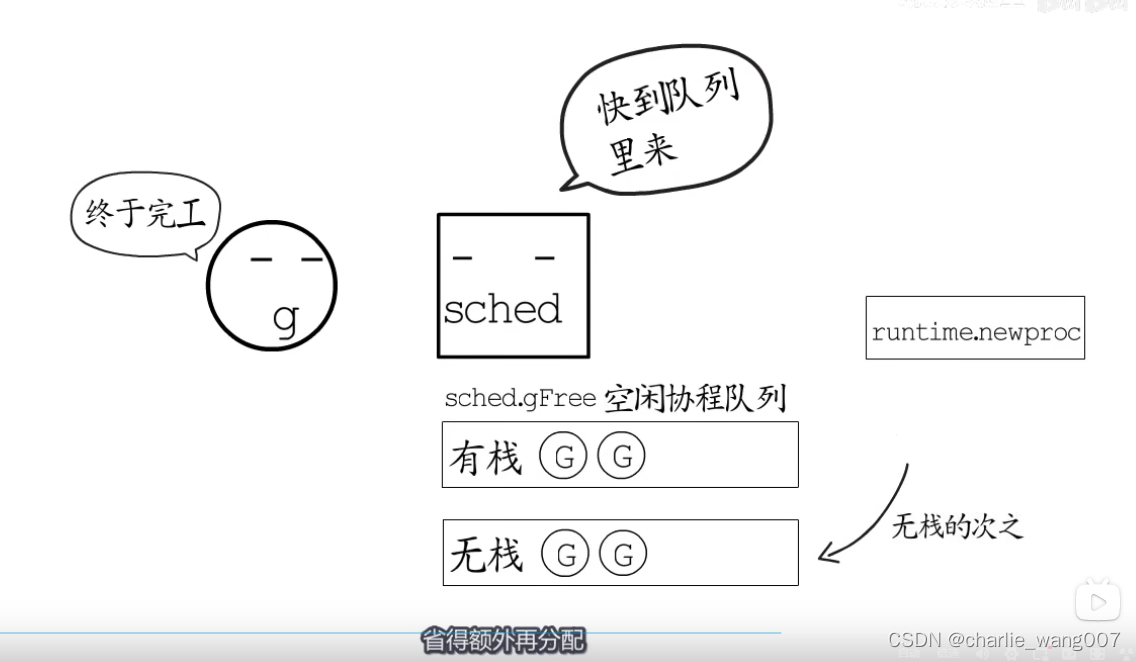
2 一般的协程都是有栈的协程,在进入空闲队列的时候,
a 如果是没有增长过的直接放进有栈队列,等待gc执行markroot时释放,加入无栈队列
b 增长过的先释放掉栈,再放入无栈队列
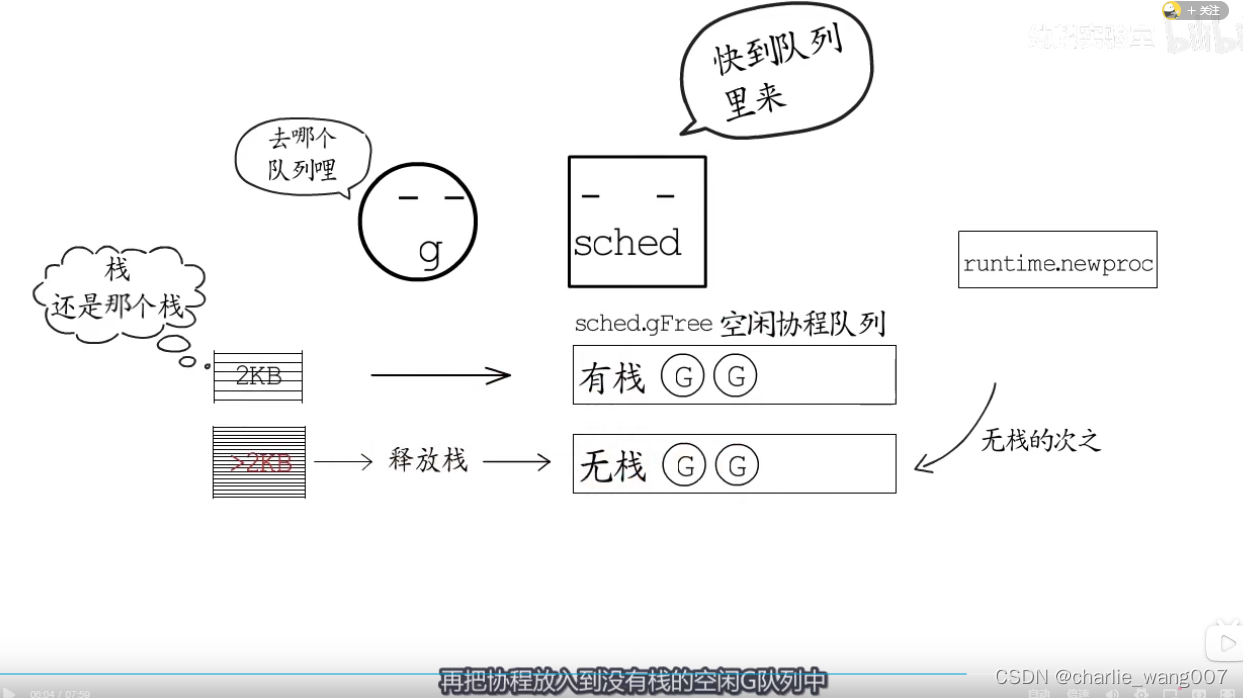
3 这些栈缓存放回到本地、/全局还是还给堆内存,以情况而定
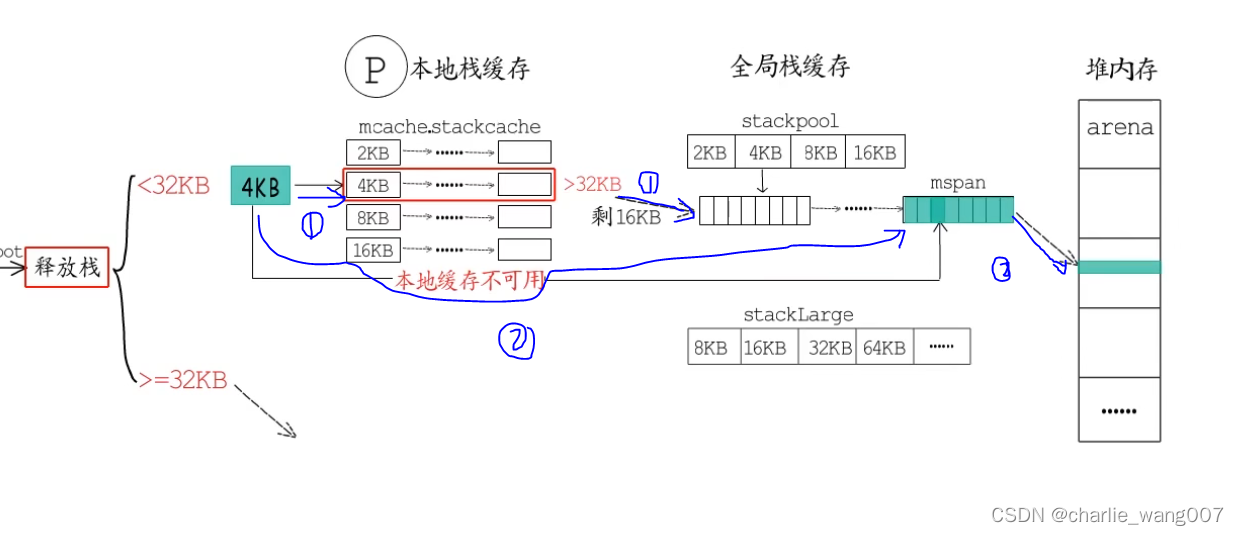
对于小于32kb的缓存,
a 直接归还本地缓存,若本地缓存大于32了,归还给stackpool
b 本地缓存不可用时,直接释放到stackpool,若这个stackpool中一整块mspan都被释放,则将这块mspan归还给堆
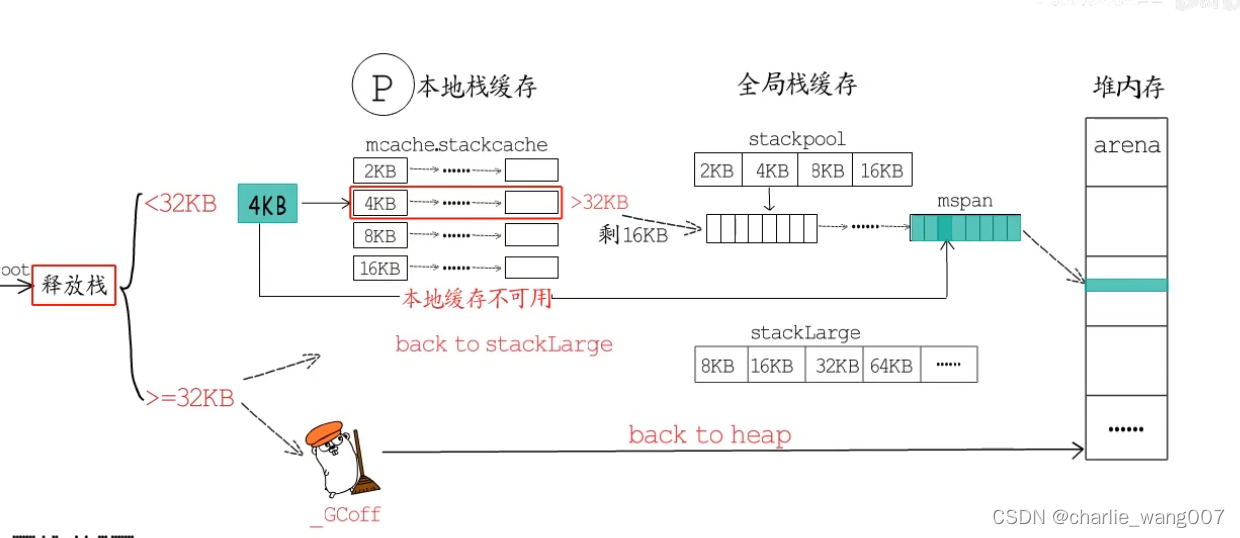
对于大于32kb的缓存
a 如果当前在gc清理阶段,就直接释放给堆
b 放在stacklarge这里