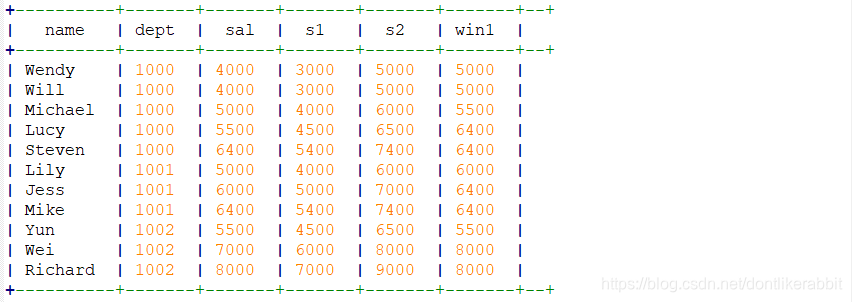
–order by:指定列排序
select
name,
dept_num,
employee_id,
salary
from employee_contract
order by salary desc;
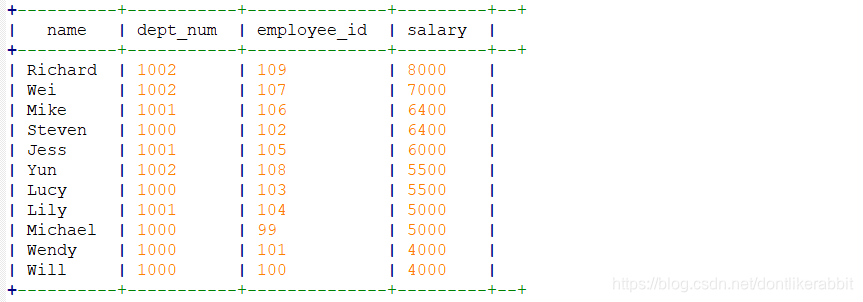
–按指定列的位排序
set hive.groupby.orderby.position.alias=true;
select
name,
dept_num,
employee_id,
salary
from employee_contract
order by 3 desc;
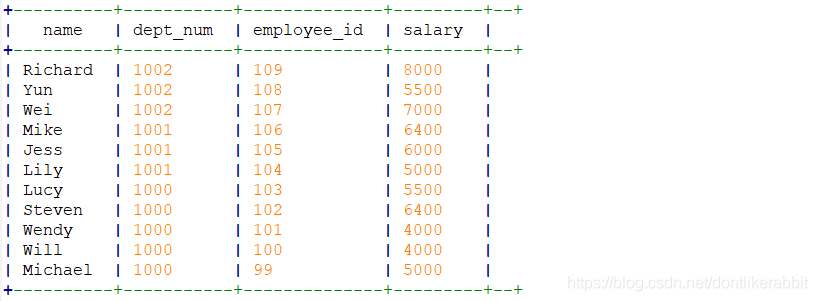
–查询reduces个数
set mapreduce.job.reduces;
–sort by:没设置mapreduce数量前
select
name,
dept_num,
employee_id,
salary
from employee_contract
sort by salary desc;
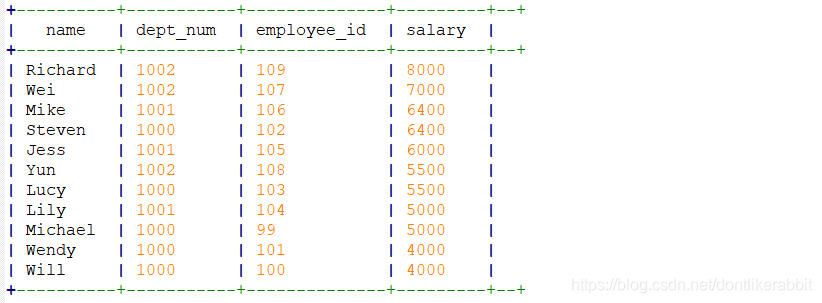
–sort by:设置mapreduce数量
set mapreduce.job.reduces=2;
select
name,
dept_num,
employee_id,
salary
from employee_contract
sort by salary desc;
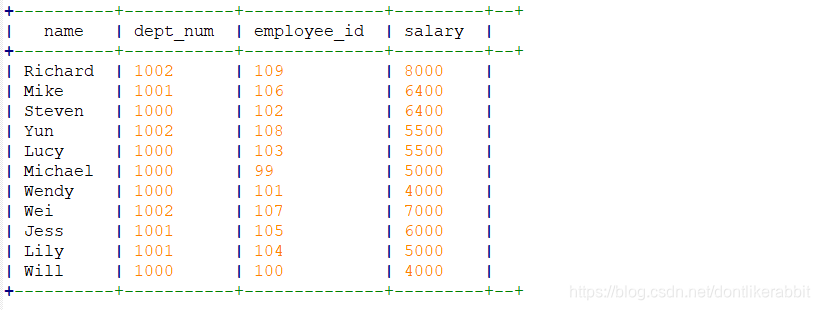
–distribute by + sort by
select
name,
dept_num,
employee_id,
salary
from employee_contract
distribute by dept_num sort by salary;
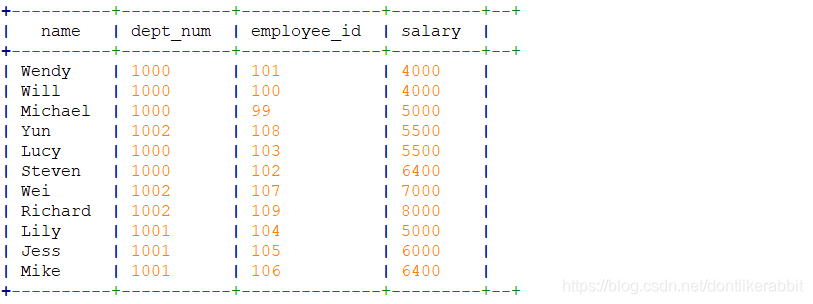
–强行设置mapreduce=1后,就还是全局排序
set mapreduce.job.reduces=1;
select
name,
dept_num,
employee_id,
salary
from employee_contract
distribute by dept_num sort by salary;
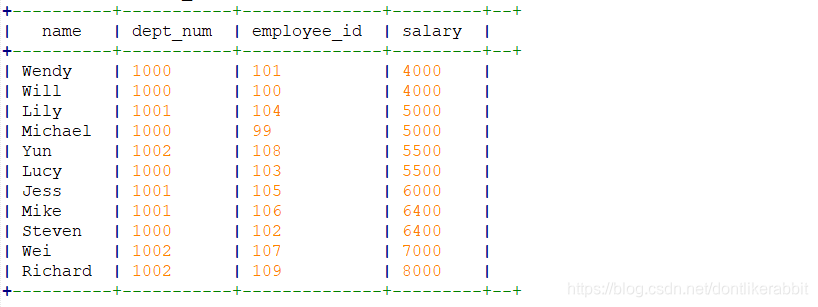
–cluster by=distribute by + sort by
set mapreduce.job.reduces=2;
select
name,
dept_num,
employee_id,
salary
from employee_contract
cluster by salary;
–group by
–每个部门所有员工的薪资总和
select
dept_num,sum(salary)
from employee_contract
group by dept_num;

select
dept_num,name,sum(salary)
from employee_contract
group by dept_num;
—如果select聚合字段前的字段比group by的字段多的话,会报错:Error: Error while compiling statement: FAILED: SemanticException [Error 10025]: Line 2:9 Expression not in GROUP BY key ‘name’ (state=42000,code=10025)
select
sum(salary)
from employee_contract
group by dept_num;
–select聚合字段前的字段可以没有,group by的字段随意写

–给薪资分组
select
if(salary>5000,'good','bad') as s,sum(salary)
from employee_contract
group by if(salary>5000,'good','bad');

–row_number()
–给所有员工薪资排序
–从低到高,针对所有员工
select name,dept_num,salary,
row_number() over(order by salary) as rn
from employee_contract;
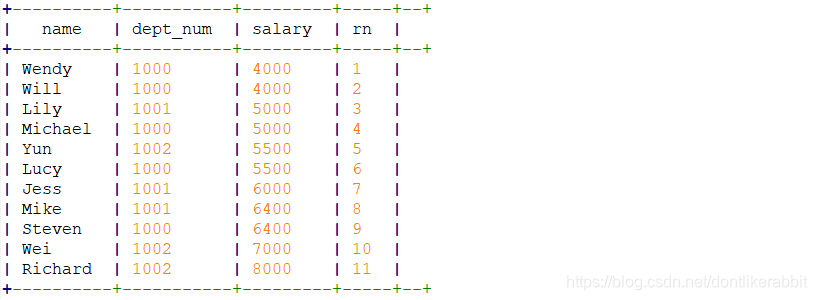
–rank()
select name,dept_num,salary,
rank() over(order by salary) as rn
from employee_contract;
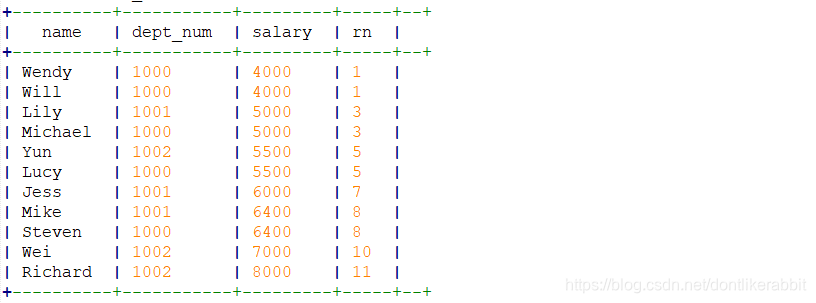
–dense_rank()
select name,dept_num,salary,
dense_rank() over(order by salary) as rn
from employee_contract;

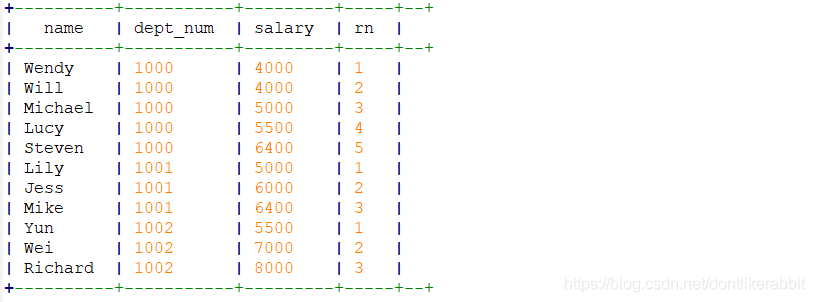
–按部门,对每个部门的员工薪资排序
select name,dept_num,salary,
row_number() over(partition by dept_num order by salary) as rn
from employee_contract;
–按部门分组,获取每个部门薪资最低的员工(考虑重复)
–分组求top n
select *
from(
select name,dept_num,salary,
dense_rank() over(partition by dept_num order by salary) as rn
from employee_contract
)t
where t.rn in (1,2,3);

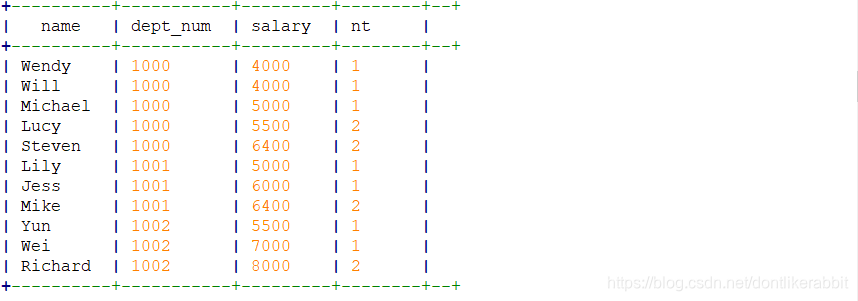
–ntile
select name,dept_num,salary,
ntile(2) over(partition by dept_num order by salary) as nt
from employee_contract;
–percent_rank
select name,dept_num,salary,
percent_rank() over(order by salary) as pr
from employee_contract;
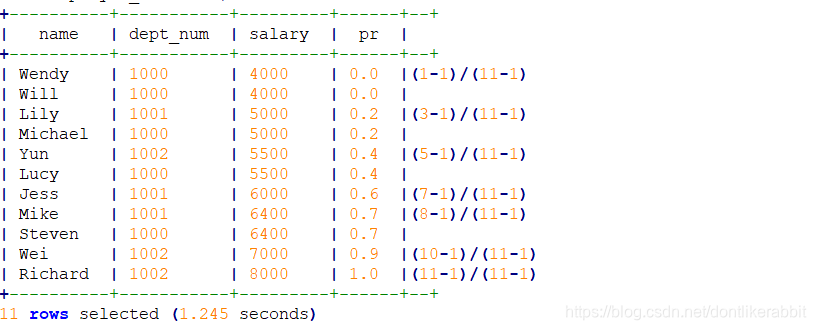
–组合窗口函数使用
–窗口函数序列
SELECT
name, dept_num, salary,
ROW_NUMBER() OVER () AS row_num,
RANK() OVER (PARTITION BY dept_num ORDER BY salary) AS rank,
DENSE_RANK() OVER (PARTITION BY dept_num ORDER BY salary) AS dense_rank,
PERCENT_RANK() OVER(PARTITION BY dept_num ORDER BY salary) AS percent_rank,
NTILE(2) OVER(PARTITION BY dept_num ORDER BY salary) AS ntile
FROM employee_contract
ORDER BY dept_num, salary;
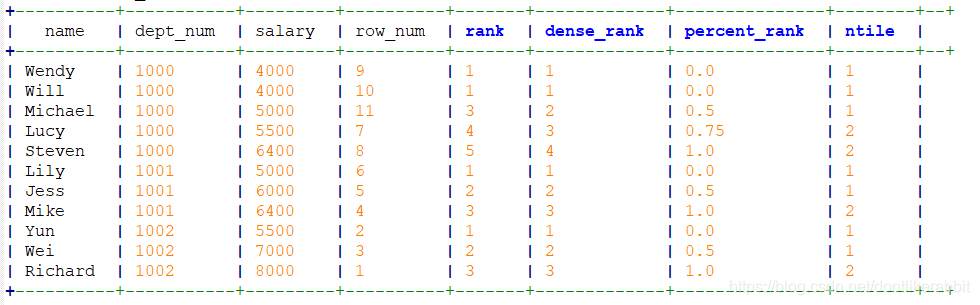
–count
select name,dept_num,salary,
count(*) over(partition by dept_num) as rc
from employee_contract;

–sum
select name,dept_num,salary,
sum(salary) over(partition by dept_num order by salary) as rc
from employee_contract;
–分区内累计到当前行累加,salary相同时当成一个累加
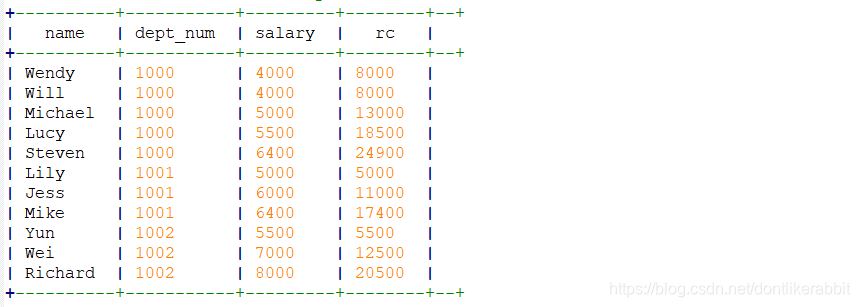
select name,dept_num,salary,
sum(salary) over(order by salary) as rc
from employee_contract;
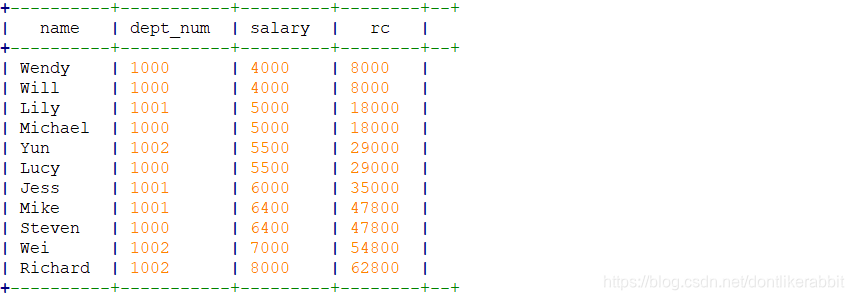
select name,dept_num,salary,
sum(salary) over(order by dept_num,name rows unbounded preceding) as rc
from employee_contract;
–累计到当前行累加
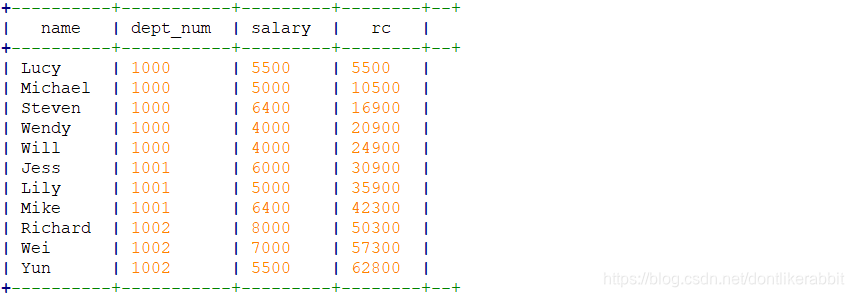
select name,dept_num,salary,
sum(salary) over(order by dept_num,name) as rc
from employee_contract;
–报错order by字段只能一个
Error: Error while compiling statement: FAILED: SemanticException Range based Window Frame can have only 1 Sort Key (state=42000,code=40000)
select name,dept_num,salary,
sum(salary) over(order by name) as rc
from employee_contract;
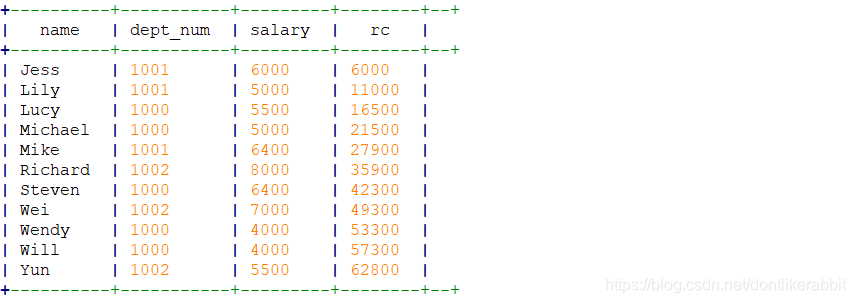
–求平均值,最大,最小
select name,dept_num,salary,
avg(salary) over(partition by dept_num) as avgDept,
min(salary) over(partition by dept_num) as minDept,
max(salary) over(partition by dept_num) as maxDept
from employee_contract;
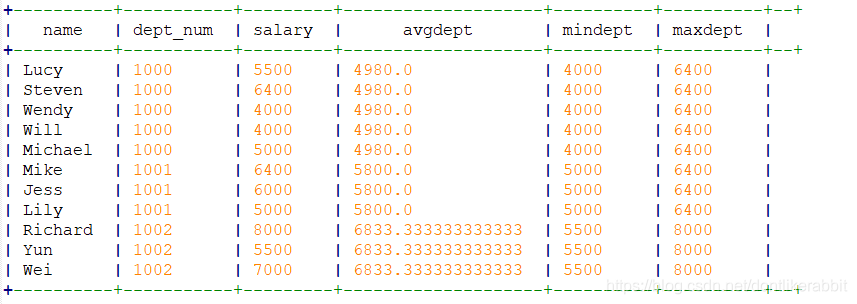
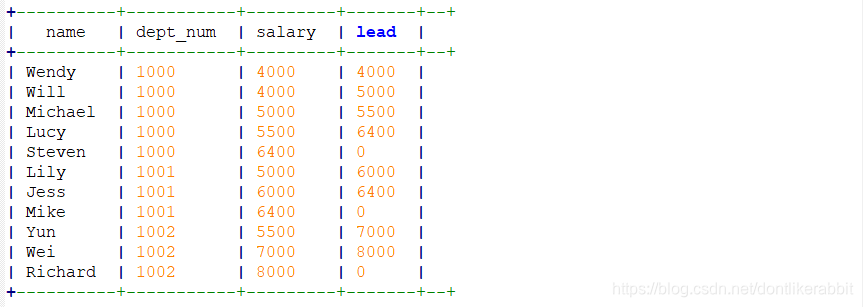
–lead
select name,dept_num,salary,
lead(salary,1) over(partition by dept_num order by salary) as lead
from employee_contract;
–分区内当前行的后1行,不存在则写null
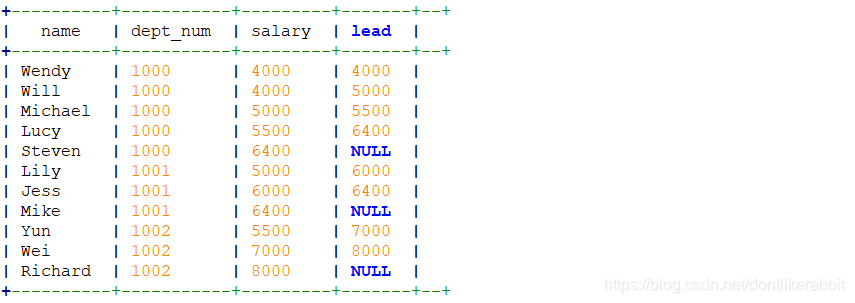
select name,dept_num,salary,
lead(salary,1,0) over(partition by dept_num order by salary) as lead
from employee_contract;
–分区内当前行的后1行,不存在则写0
–lag
select name,dept_num,salary,
lag(salary,1) over(partition by dept_num order by salary) as lag
from employee_contract;
–分区内当前行的前1行,不存在则null
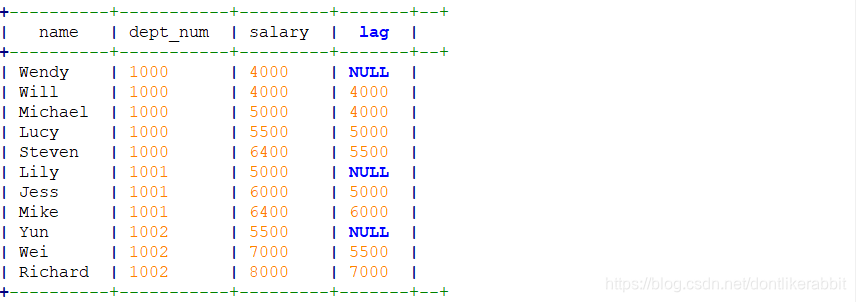
select name,dept_num,salary,
lag(salary,1,0) over(partition by dept_num order by salary) as lag
from employee_contract;
–分区内当前行的前1行,不存在则写0

–first_value last_value
select name,dept_num,salary,
first_value() over(partition by dept_num order by salary) as fv,last_value() over(partition by dept_num order by salary) as lv
from employee_contract;
–报错first_value()中要写参数
–Error: Error while compiling statement: FAILED: NullPointerException null (state=42000,code=40000)
select name,dept_num,salary,
first_value(salary) over(partition by dept_num order by salary) as fv,last_value(salary) over(partition by dept_num order by salary) as lv
from employee_contract;
–fv:分区内截至到当前行的第一行
–lv:分区内截至到当前行的最后一行,也就是分区内的当前行

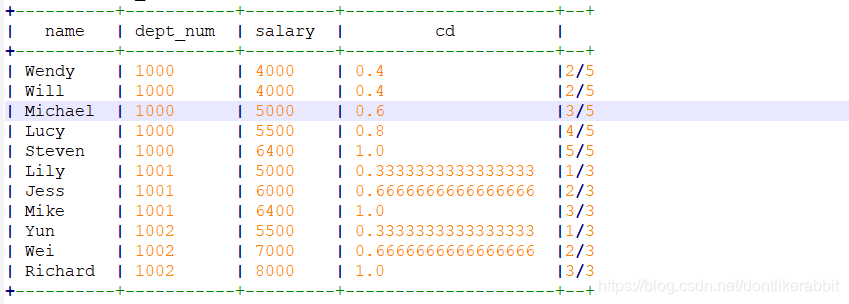
–cume_dist
select name,dept_num,salary,
cume_dist(salary) over(partition by dept_num order by salary) as cd
from employee_contract;
–报错cume_dist()中不能有参数
–Error: Error while compiling statement: FAILED: SemanticException Failed to breakup Windowing invocations into Groups. At least 1 group must only depend on input columns. Also check for circular dependencies.
Underlying error: Ranking Functions can take no arguments (state=42000,code=40000)
select name,dept_num,salary,
cume_dist() over(partition by dept_num order by salary) as cd
from employee_contract;
–range between
select name,dept_num As dept, salary As sal,salary-1000 as s1,salary+1000 as s2 ,max (salary)OVER (PARTITION BY dept_num ORDER BY salary RANGE BETWEEN 1000 PRECEDING AND 1000 FOLLOWING) win1 from employee_contract
–win1:分区内的值在(当前行-100~当前行+1000)范围内的最大值