原子操作
所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch(切换到另一个线程)。原子操作是不可分割的,在执行完毕之前不会被任何其它任务或事件中断。
下面看一个例子
#include<iostream>
#include<thread>
#include<atomic>
#include<time.h>
#include<mutex>
using namespace std;
mutex mtx; //定义互斥锁
#define MAX 2000000
#define THREAD_COUNT 10
//atomic_int total(0);
int total = 0;
void thread_task()
{
for (int i = 0; i < MAX; i++)
{
//mtx.lock();
total += 1;
total -= 1;
//mtx.unlock();
}
}
int main()
{
clock_t start = clock();
thread t[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; ++i)
{
t[i] = thread(thread_task);
}
for (int i = 0; i < THREAD_COUNT; ++i)
{
t[i].join();
}
clock_t finish = clock();
cout << "result:" << total << endl;
cout << "time:" << finish - start << endl;
return 0;
}这是一个程序,创建10个线程,在函数中将0加一再减一重复2000000次,最终得到的结果应该还是0,我们运行结果如下
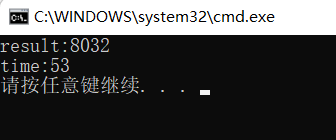
为什么呢???我们不难想到是线程同步问题。我们尝试给函数的操作加锁。
#include<iostream>
#include<thread>
#include<atomic>
#include<time.h>
#include<mutex>
using namespace std;
mutex mtx; //定义互斥锁
#define MAX 2000000
#define THREAD_COUNT 10
//atomic_int total(0);
int total = 0;
void thread_task()
{
for (int i = 0; i < MAX; i++)
{
mtx.lock();
total += 1;
total -= 1;
mtx.unlock();
}
}
int main()
{
clock_t start = clock();
thread t[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; ++i)
{
t[i] = thread(thread_task);
}
for (int i = 0; i < THREAD_COUNT; ++i)
{
t[i].join();
}
clock_t finish = clock();
cout << "result:" << total << endl;
cout << "time:" << finish - start << endl;
return 0;
}此时答案正确但是效率显著降低,这也是情理之中的。

这时候引入原子操作
#include<iostream>
#include<thread>
#include<atomic>
#include<time.h>
#include<mutex>
using namespace std;
mutex mtx; //定义互斥锁
#define MAX 2000000
#define THREAD_COUNT 10
atomic_int total(0);
//int total = 0;
void thread_task()
{
for (int i = 0; i < MAX; i++)
{
//mtx.lock();
total += 1;
total -= 1;
//mtx.unlock();
}
}
int main()
{
clock_t start = clock();
thread t[THREAD_COUNT];
for (int i = 0; i < THREAD_COUNT; ++i)
{
t[i] = thread(thread_task);
}
for (int i = 0; i < THREAD_COUNT; ++i)
{
t[i].join();
}
clock_t finish = clock();
cout << "result:" << total << endl;
cout << "time:" << finish - start << endl;
return 0;
}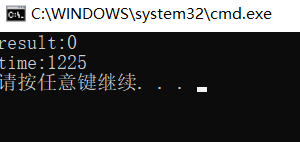
此时可见性能得到了大幅优化。
版权声明:本文为weixin_65743593原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。