AutoLeaders算法组——numpy&pandas库学习笔记
numpy库
一、创建numpy库和创建数组
1.导入numpy库并命名为np
import numpy as np
2.创建一维数组
np.array([3, 6, 9])
3.创建二维数组
np.array([(3, 6, 9),(2, 4, 7)])
4.创建全为0或1的三维数组
np.zeros(2, 3, 4)
np.ones(2, 3, 4)
(数组个数, 每个数组的行数, 列数)
5.创建单位矩阵
np.eye(3)##创建一个三阶的单位矩阵
注意:np.eye(
X
),
X
为单位矩阵的阶数
二、简单运算
1.tile
print(a)
[(1, 2), (4, 6)]
np.tile(a, (1, 2))#把a转换成一行两列
[[1 2 1 2]
[4 6 4 6]]
2.矩阵乘法
A = np.array([[1, 2],
[3, 4]])
B = np.array([[1, 2],
[3, 4]])
np.dot(A, B)
[[ 7 10]
[15 22]]
3.矩阵求逆
A = np.array([[1, 2],
[3, 4]])
np.linalg.inv(A)
[[-2. 1. ]
[ 1.5 -0.5]]
4.广播
a = np.array([[1, 2, 3],
[4, 5, 6],
[6, 6, 6]])
b = np.array([1, 2, 3])
a + b
[[2 4 6]
[5 7 9]
[7 8 9]]
5.矩阵合并
a = np.array([1, 2, 3])
b = np.array([1, 2, 3])
c = np.vstack((a, b))#上下合并 vertical stack
d = np.hstack((a, b))#左右合并 horizontal stack
print(c, "\n", d)
[[1 2 3]
[1 2 3]]
[1 2 3 1 2 3]
6.array的分割
a = np.arange(1, 13).reshape(3, 4)
b = np.split(a, 3, axis=0)##axis=0时,横向分割;axis=1时,纵向分割
print(a)
print(b)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[array([[1, 2, 3, 4]]), array([[5, 6, 7, 8]]), array([[ 9, 10, 11, 12]])]
pandas库
一、生成数据表
1.导入pandas库
import numpy as np
import pandas as pd
2.csv或者xlsx文件的导入和导出
df = pd.read_csv('name.csv')#导入csv文件
df = pd.read_excel('name.xlsx')#导入xlsx文件
df_inner.to_csv('name1.csv')#导出csv文件
df_inner.to_xlsx('name1.xlsx',sheet_name='name2_cc')#导出xlsx文件
3.用字典创建数据表
dates = pd.date_range('20220101', periods=3)
df = pd.DataFrame({
'a': [1, 2, 3],
'b': [4, 5, 6],
'c': [4, 5, 6]
}, index=dates, columns=['a', 'b', 'c'])
print(df)
a b c
2022-01-01 1 4 4
2022-01-02 2 5 5
2022-01-03 3 6 6
二、选择数据
1.查看某列的数据
print(df['a'])
print(df[0,2])
print(df['20220101','20220103'])#三种形式得到的结果相同
2.查看某行的数据
print(df.loc['20220101'])
print(df.iloc[0])#输出第一行
print(df[df.a >= 2])#查看a大于等于2的行
3.查看某列数据
print(df.loc[:, ['a','b']])
print(df.iloc[:, 0:2])
三、设置值
1.对单个值或一行进行更改
df.iloc[1,1] = 123
df.loc['20220102', 'b']=123#以上两种方式更改效果相同
df[df.a>1] = 0#把df里面a>1的行全部置0
df.a[df.a>1] = 0#把df里面a>1行的a值置0
2.增加一列
df['d'] = np.nan
df['e'] = pd.Series([1, 2, 3], index=pd.date_range('20220101', periods=3))
print(df)
3.删除一列
df.drop(labels=['a', 'b'], axis=1)#删除a,b列
四、处理丢失数据
1.删除缺失行
df.dropna(axis = 0,how = 'any')#丢掉出现一个或以上的NaN的行,若how='all',则是丢掉全部为NaN的行
2.查找缺失值
df.isnull()
3.填充缺失值
df.fillna(value=1)#用1填充缺失值
五、合并DataFrame
1.append
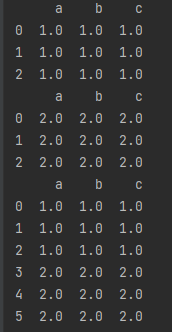
df1 = pd.DataFrame(np.ones((3, 3))*1, index=[0, 1, 2], columns=['a', 'b', 'c'])
df2 = pd.DataFrame(np.ones((3, 3))*2, index=[0, 1, 2], columns=['a', 'b', 'c'])
df3 = df1.append(df2, ignore_index=True)
print(df1)
print(df2)
print(df3)
2.concat
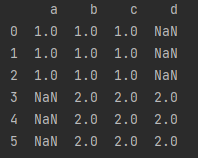
df1 = pd.DataFrame(np.ones((3, 3))*1, index=[0, 1, 2], columns=['a', 'b', 'c'])
df2 = pd.DataFrame(np.ones((3, 3))*2, index=[0, 1, 2], columns=['b', 'c', 'd'])
df3 = pd.concat([df1, df2], ignore_index=True, join='outer')#join='outer'取并集,#join='inner'取交集
3.merge
按列合并
left = pd.DataFrame({
'key': ['K1', 'K2', 'K3'],
'a': ['a0', 'a1', 'a2'],
'b': ['b0', 'b1', 'b2']
})
right = pd.DataFrame({
'key': ['K1', 'K2', 'K3'],
'c': ['c0', 'c1', 'c2'],
'd': ['d0', 'd1', 'd2']
})
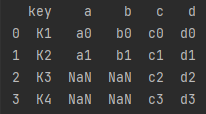
df = pd.merge(left, right, on='key')#按key合并
print(df)
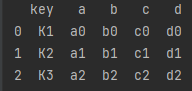
df = pd.merge(left, right, on='key', how="inner")
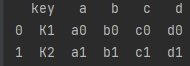
df = pd.merge(left, right, on='key', how="outer")
按行合并
left = pd.DataFrame({
'a': ['a0', 'a1', ],
'b': ['b0', 'b1', ]
}, index=['K1', 'K2'])
right = pd.DataFrame({
'c': ['c0', 'c1', 'c2'],
'd': ['d0', 'd1', 'd2']
}, index=['K1', 'K2', 'K3'])
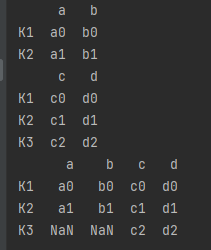
df = pd.merge(left, right, left_index=True, right_index=True, how='outer')
print(left)
print(right)
print(df)
六、对列的简单运算
form = pd.DataFrame({
'a': [1, 2],
'b': [3, 4]
}, index=['K1', 'K2'])#一张简单的DataFrame
print(form.a.sum())#总和
print(form.a.max())#最大值
print(form.a.min())#最小值
print(form.a.mean())#平均值

版权声明:本文为weixin_65446588原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。