前缀和
对于整型一维数组,前缀和算法就是构造
(这里说的构造不是说做题时一定要构造出这么一个数组出来,这里的讲解只是为了理解前缀和的思想,理解了思想之后就可以用自己的想法运用这个算法了)
出一个与原数组nums等长的的前缀和数组sum,且在前缀和数组中,sum[i]表示的是原数组中[0,i]的元素之和
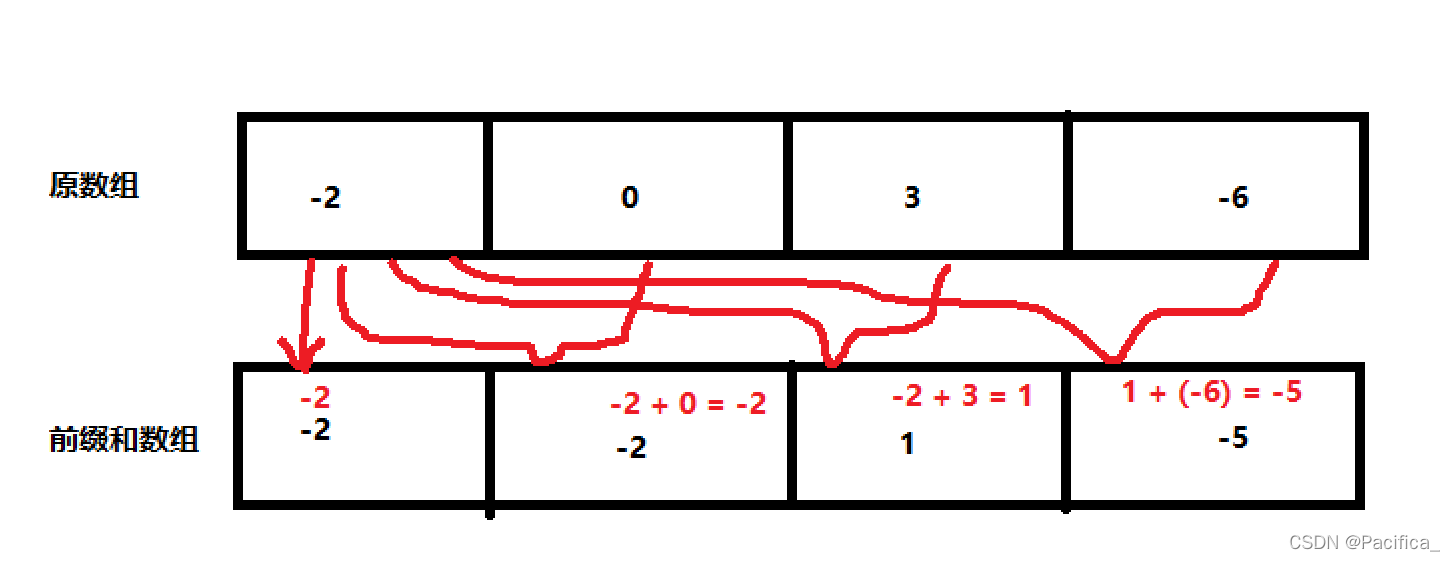
对于一维数组求区间和问题,可以使用前缀和来解题,特别是对同一个一维数组进行多次求区间和的话,只需O(n)的复杂度遍历一遍数组生成前缀和数组,然后每次求区间和只需借助前缀和数组,用区间右边界对应的前缀和减去区间左边界对应的前缀和即可得到答案,复杂度为O(1)
303.区域和检索
class NumArray {
private int[] sum;
public NumArray(int[] nums) {
int len = nums.length;
if(len == 0) sum = null;
else{
//开始生成前缀和数组
sum = new int[len];
sum[0] = nums[0];
for(int i = 1;i < len;i++){
//生成前缀和数组的递推公式
sum[i] = sum[i - 1] + nums[i];
}
}
}
public int sumRange(int left, int right) {
if(sum == null) return 0;
if(left == 0) return sum[right];
return sum[right] - sum[left - 1];
}
}
304.二维区域和检索
这道题相当于是对
二维数组
进行前缀和的算法,类似一维数组的做法,构建一个行跟列跟原二维数组相等的二维前缀和数组sum,其中sum[i][j]表示的是原数组中对0 <= row <= i以及0 <= col <= j的所有元素num[row][col]之和,即以[0,i]为长,[0,j]为宽的矩形中所有元素的和
那么如何求(row1,col1)到(row2,col2)范围内的矩形中的元素和:
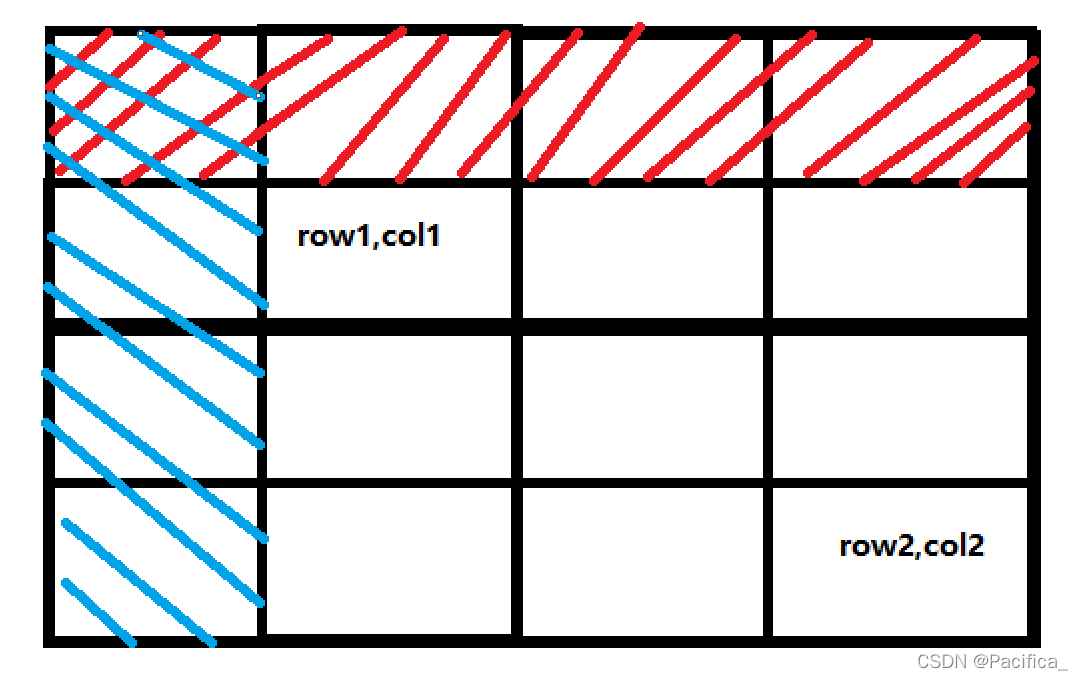
可以看出(row1,col1)到(row2,col2)范围内的矩形就是(0,0)到(row2,col2)的大矩形减去图中红色区域跟蓝色区域的小矩形再加上被减去两次的红色区域跟蓝色区域交叉的区域,也就是sum[row2][col2] – sum[row1 – 1][col2] – sum[row2][col1 – 1] + sum[row1 – 1][col1 – 1]
class NumMatrix {
private int[][] sum;
public NumMatrix(int[][] matrix) {
int m = matrix.length;
int n = matrix[0].length;
sum = new int[m][n];
sum[0][0] = matrix[0][0];
//矩形的第一行跟第一列的前缀和计算方法与其它位置的不同
for(int i = 1;i < n;i++) sum[0][i] = sum[0][i - 1] + matrix[0][i];
for(int i = 1;i < m;i++) sum[i][0] = sum[i - 1][0] + matrix[i][0];
for(int i = 1;i < m;i++){
for(int j = 1;j < n;j++){
sum[i][j] = matrix[i][j] + sum[i][j - 1] + sum[i - 1][j] - sum[i - 1][j - 1];
}
}
}
public int sumRegion(int row1, int col1, int row2, int col2) {
if(row1 == 0 && col1 == 0) return sum[row2][col2];
if(row1 == 0) return sum[row2][col2] - sum[row2][col1 - 1];
if(col1 == 0) return sum[row2][col2] - sum[row1 - 1][col2];
//下面这个计算公式是应对于普通情况的,可以发现不适用的情况是 col1 == 0 或者 row1 == 0,对应的就有三种输入情况
//分别是row1跟col1都为0,row1为0col1不为0.row1不为0col1为0
return sum[row2][col2] - sum[row1 - 1][col2] - sum[row2][col1 - 1] + sum[row1 - 1][col1 - 1];
}
}
560.和为 K 的子数组
对于一维数组,它的连续子数组要么是从0号元素开始(包含0号元素);要么是不从0号元素开始
对于前者,用前缀和解题就是找出前缀和数组sum中,值为k的元素有多少个
对于后者,假设子数组[i,j]中的元素和为k,0 < i <= j,那么相应的,子数组[0,i)的元素和就是sum[j] – k,也就是前缀和数组中的sum[i]。具体对这道题来说,可以遍历整个数组,然后记录当前遍历过的元素的总和 sum,并用 map 记录每个总和出现的个数,然后判断 map 中键为 sum – k 的值为多少,即已遍历过的前缀和中有多少个为 sum – k
public int subarraySum(int[] nums, int k) {
int len = nums.length;
Map<Integer,Integer> map = new HashMap<>();
//map记录数组中,前缀和为某个值的前缀子数组的个数
//初始设置一个前缀和为0时有一个子数组,这一个表示的是一个数组元素都不选时长度为0的子数组
//这样后续遇到刚好有前缀和为k的时候,按照上面说的第二种情况来处理即可
map.put(0,1);
int sum = 0;
int res = 0;
for(int i = 0;i < len;i++){
//这里就不用真的去构造一个前缀和数组,只需遍历计算出每一个前缀和直接使用即可
sum += nums[i];
int key = sum - k;
if(map.containsKey(key)){
res += map.get(key);
}
map.put(sum,map.getOrDefault(sum,0) + 1);
}
return res;
}
1442. 形成两个异或相等数组的三元组数目(每日一题)
以下讲解来自
LeetCode官方题解

需要注意s[0]表示的是0。要满足 a = b,需要 s[i] = s[k + 1] (根据0 <= i < j <= k < arr.length的条件,可以得到 i < k) ,而与 j 无关,所以 j 只需要符合 (i,k] 区间范围内都可以,也就是说,每找到一组 s[i] = s[k + 1],对应的三元组就有 k – i 个,据此可以得到下面的代码
public int countTriplets(int[] arr) {
int n = arr.length;
int[] s = new int [n + 1];
for(int i = 1;i <= n;i++){
s[i] = arr[i - 1] ^ s[i - 1];
}
int ans = 0;
for(int i = 0;i < n;i++){
for(int k = i + 1;k < n;k++){
if(s[i] == s[k + 1]){
ans += k - i; //k + 1 - i - 1
}
}
}
return ans;
}
上面的代码已经可以说是
最优解
了
让我们从k的视角出发:对于每个k,其实是在找它前面有多少个s[i] = s[k + 1],每找到一个,ans就加k,然后减掉i。也就是说,对于每个下标k,只要知道位于k前面有多少个下标i对应的s[i] = s[k + 1]以及所有这些下标i的总和,就可以求出每个k对最终答案ans的贡献了。实现思路就是用哈希记录遍历过的s[i]相同数值出现的次数以及对应的所有下标i之和,就可以实现O(n)的复杂度:
public int countTriplets(int[] arr) {
int n = arr.length;
int[] s = new int [n + 1];
//count即记录每个前缀和及其出现的次数
HashMap<Integer,Integer> count = new HashMap<>();
//indexSum记录每个相等的前缀和s[i]的下标i的总和
HashMap<Integer,Integer> indexSum = new HashMap<>();
int ans = 0;
//k从1开始,所以把s[0]对应的数据先放入哈希表
count.put(0,1);
indexSum.put(0,0);
for(int k = 1;k <= n;k++){
s[k] = arr[k - 1] ^ s[k - 1];
if(count.containsKey(s[k])){
ans += (k - 1) * count.get(s[k]) - indexSum.get(s[k]);
}
count.put(s[k],count.getOrDefault(s[k],0) + 1);
indexSum.put(s[k],indexSum.getOrDefault(s[k],0) + k);
}
return ans;
}
虽然对于测试数据来说是O(n)复杂度,但考虑到哈希表的查找跟设值,实际跑出来的时间效率还是上面第一种做法的更高
525. 连续数组
参考题解
整理如下:
定义 01数量差 为子数组中 0 的数目减去 1 的数目得到的差值。minus[i] 就表示子数组 [0,i] 的 01数量差
那么如果能找到下标 j 满足0 <= j < i 且 minus[j] == minus[i],不就能说明子数组 [j + 1,i] 的 01数量差为 0,即 0 的数目等于 1 的数目吗
这需要我们遍历到 i 时,计算出 minus[i],同时使用哈希表记录已遍历过的部分中 01数量差等于 minus[i] 的 j,就能计算出 [j + 1,i] 的长度。所有满足条件的子数组的长度中的最大值就是最终的答案
怎么计算 minus[i]?我们可以不用显式地计算 minus[i],我们使用一个前缀和数组 prefix,prefix[i] 表示 [0,i] 中 1 的数目,那么 [0,i] 中总元素个数为 i + 1,1 的数目为 prefix[i],0 的数目就为 i + 1 – prefix[i],那么 01 数量差就为 i + 1 – 2 * prefix[i]
哈希表怎么记录?key 值表示 minus[j],value 值表示 j 即可,当遍历到 i 时,计算出 i 的 minus[i] 为 i + 1 – 2 * prefix[i],就可以查找哈希表有无键为 i + 1 – 2 * prefix[i],若有的话,取出值 j,计算出子数组的长度为 i – j (不是 i – j + 1,这里符合条件的子数组是 [j + 1,i]);若无,就放入键值对 k = i + 1 – 2 * prefix[i],v = i
遍历过程维护最大长度即可
此外,由于 01数量差 的范围很容易可以知道是 [-n,n],因此我们可以使用一个大小为 2n + 1 的数组来作为哈希表而不用使用 Map,节约掉 Map 结构所需的时间
public int findMaxLength(int[] nums) {
int n = nums.length, max = 0;
//计算前缀和数组
int[] prefix = new int[n];
prefix[0] = nums[0] ;
for (int i = 1; i < n; i++)
prefix[i] = prefix[i - 1] + nums[i];
int[] ht = new int[2 * n + 1]; //哈希表
//哈希表初始化,由于后续计算中ht中元素值可能为0,所以需要初始化为-1表示未被赋值过
Arrays.fill(ht,-1);
int minus,index;
for (int i = 0; i < n; i++) {
minus = i + 1 - 2 * prefix[i]; //计算i对应的 01数量差
index = minus + n; //计算 01数量差 对应的哈希表中的槽
//如果ht[index]不为-1说明该槽被覆盖过,可以计算[index + 1,i]的长度
if(ht[index] != -1) max = Math.max(max,i - ht[index]);
//如果01数量差为0说明[0,i]就符合条件,长度为i + 1
else if(minus == 0) max = Math.max(max,i + 1);
//如果ht[index]为-1才更新ht[index]的值,因为我们需要的是符合条件的子数组的最大长度
//对于不同的j拥有同一个01数量差,我们记录的应该是最小的j,这样计算得到的子数组长度i - j才会是最大的
else ht[index] = i;
}
return max;
}
差分
对于整形一维数组nums,构造一个与其等长度的差分数组dif,其中
dif[i]表示nums[i](i > 0)减去nums[i – 1]得到的差值,diff[0] = nums[0]
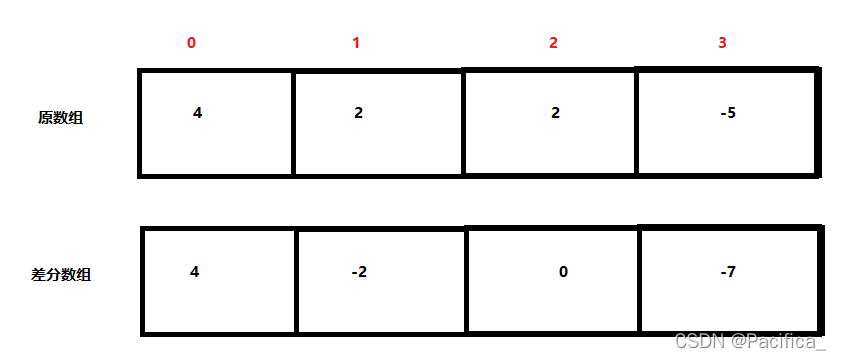
根据差分数组可以逆推得到原数组。差分数组的含义就是数组相邻元素之间的差值
当我们要对一维数组某一段区间所有的数组元素做相同的操作,如都加上一个数k(k可以为负数),操作完这个区间内中的所有数之间的差值跟操作前是一样的,也就是说在差分数组中,这一段区间的值是没有变化的,只有区间中的第一个数跟它的前一个数的差值增加了k,以及区间中的最后一个数的后一个数(如果有)跟它的差值减少了k,如对于[4,2,2,-5], 对区间[1,2]进行加3操作,即得到[4,5,5,-5],其差分数组为[4,1,0,-10],即操作完dif[1] = dif[1] + 3,dif[3] = dif[3] – 3
考虑到原数组中最后一个元素没有后一个数,所以如果区间操作包括了最后一个元素,只需要让区间中的第一个数对应在差分数组中的值加k即可,不需要对区间的右边界进行处理
如果没有借助差分数组,在原数组上进行区间操作的复杂度就是O(n),如果有m次区间操作,要得到最终的数组的话总复杂度就为O(n * m);借助差分数组,每次区间操作的复杂度为O(1),只需改变两个差分数组中的元素的值,经过m次区间操作后要得到最终的数组,只需遍历一遍差分数组逆推得到原数组即可,总的复杂度为O(1 * m + n) = O(m + n)
看到题目有涉及到
区间操作
的,应先考虑一下是否能使用差分数组进行解题
1094.拼车
本题中的原数组就是长度为总车站个数,每个数组元素表示到达那个下标对应的车站时车上最多会有多少人
注意到每个 trips[i] 就是一个
区间操作
,即对原数组 [
start_location
,
end_location
) 区间上的所有数加上
num_passengers
,注意不包括
end_location
,因为
end_location
表示的是这个 trips[i] 中这
num_passengers
个乘客要下车的车站,就是说到达这个车站时不应该算上这几个人,所以需要进行+
num_passengers
操作的是差分数组中的 dif[
start_location
],而需要进行 –
num_passengers
操作的是 dif[
end_location
] 而不是 dif[
end_location
+ 1]
public boolean carPooling(int[][] trips, int capacity) {
int len = trips.length;
//题目中说到0 <= trips[i][1] < trips[i][2] <= 1000,说明
//车站的范围是[0,1000],所以数组最长为1001
int[] dif = new int[1001];
//记录区间操作过程中操作到的最右边的位置,在后面遍历差分数组时只需遍历到这个位置即可不用遍历到1000
int maxR = -1;
for(int i = 0;i < len;i++){
dif[trips[i][1]] += trips[i][0];
dif[trips[i][2]] -= trips[i][0];
maxR = Math.max(maxR,trips[i][2]);
}
//逆推得到原数组
for(int i = 1;i <= maxR;i++){
dif[i] += dif[i - 1];
}
//判断原数组中是否有超过capacity的元素,即一个站出现的人数会不会超出capacity
for(int i = 0;i <= maxR;i++){
if(dif[i] > capacity){
return false;
}
}
return true;
}
1109.航班预订统计
本题的原数组就是长度为 n 的数组 num,其中 num[i]表 示编号 i + 1 的航班被预订了多少个座位。每个 bookings[i] 就是一个区间操作,表示对 num 数组中指定区间的所有数组元素都加上 seats
public int[] corpFlightBookings(int[][] bookings, int n) {
int[] res = new int[n];
for(int i = 0;i < bookings.length;i++){
//数组下标从0开始,但是航班编号从1开始,所以区间操作的对象其实是
//[bookings[i][0] - 1,bookings[i][1] - 1]
res[bookings[i][0] - 1] += bookings[i][2];
//区间操作涉及到右边界的话,不对差分数组处理
if(bookings[i][1] == n) continue;
res[bookings[i][1]] -= bookings[i][2];
}
for(int i = 1;i < n;i++){
res[i] += res[i - 1];
}
return res;
}