文章目录
前言
内容大部分参考这篇
文章
。从必应上搜索并下载相应关键词的图片。
获取API
-
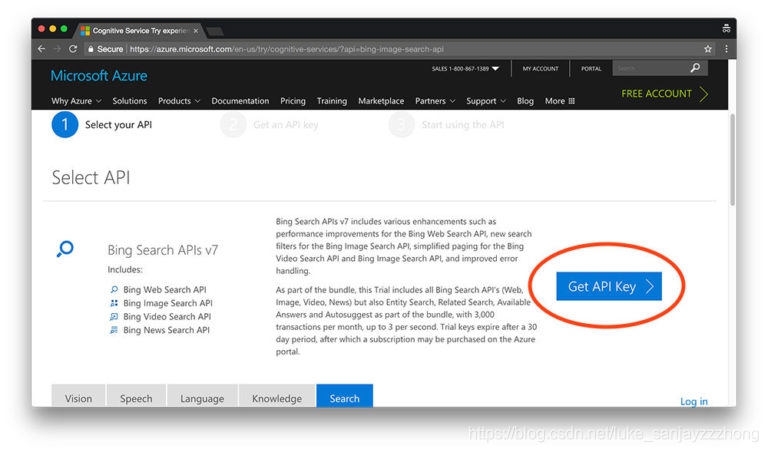
创建一个识别服务账号,这里是
Bing Image Search API
网址。然后点
Get API Key
,如下图:
-
注册或登录如果你有Microsoft 的账户,选择
免费试用
或者
送你xx刀
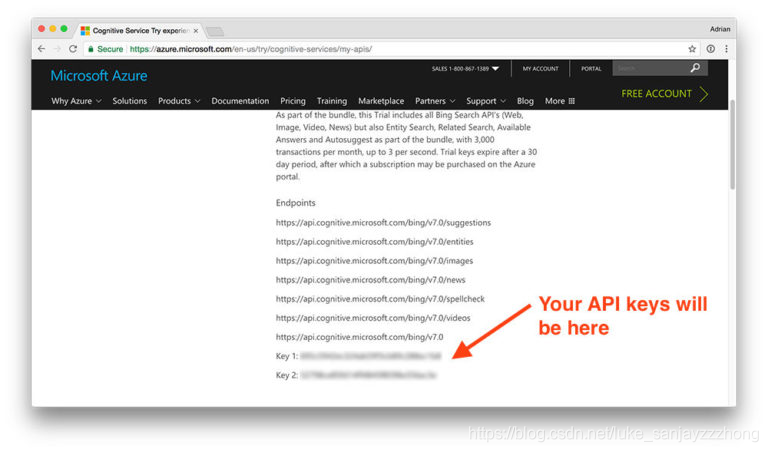
那个。注册完毕,你会在
You APIs page
这里找到你的APK keys,一般来说有两个。如下图:
写python代码获取
这里有两种代码,一种是通过命令行输入参数来指定搜索的
图片
和
图片保存路径
,另一种则是在代码里直接指明,这里都给出来
。
-
用命令行输入参数的代码
# filename: search_ging_api.py # import the necessary packages from requests import exceptions import argparse import requests import cv2 import os # construct the argument parser and parse the arguments # parse: 解析器 ''' --query: the images search query you're using, which could be anything such as "manhole" --output: the output directory for your images. ''' ap = argparse.ArgumentParser() ap.add_argument("-q", "--query", required=True, help="search query to search Bing Image API for") ap.add_argument("-o", "--output", required=True, help="path to output directory of images") args = vars(ap.parse_args()) ##-----------------this part is about global variables ------------------------------------- # set your Microsoft Cognitive Services API key along with (1) the # maximum number of results for a given search and (2) the group size # for results (maximum of 50 per request) # your API_KEY from Microsoft Azure #------------------------------------------------------------ API_KEY = "这里填你的API_KEY" #------------------------------------------------------------ # You can think of the GROUP_SIZE parameter as the number of search results to return “per page”. # Therefore, if we would like a total of 250 images, # we would need to go through 5 “pages” with 50 images “per page”. MAX_RESULTS = 250 GROUP_SIZE = 50 # set the endpoint API URL URL = "https://api.cognitive.microsoft.com/bing/v7.0/images/search" ##----------------------------------------handle exceptions--------------------------- # when attempting to download images from the web both the Python # programming language and the requests library have a number of # exceptions that can be thrown so let's build a list of them now # so we can filter on them EXCEPTIONS = set([IOError, FileNotFoundError, exceptions.RequestException, exceptions.HTTPError, exceptions.ConnectionError, exceptions.Timeout]) # store the search term in a convenience variable then set the # headers and search parameters term = args["query"] headers = {"Ocp-Apim-Subscription-Key" : API_KEY} params = {"q": term, "offset": 0, "count": GROUP_SIZE} # make the search print("[INFO] searching Bing API for '{}'".format(term)) search = requests.get(URL, headers=headers, params=params) search.raise_for_status() # grab the results from the search, including the total number of # estimated results returned by the Bing API results = search.json() estNumResults = min(results["totalEstimatedMatches"], MAX_RESULTS) print("[INFO] {} total results for '{}'".format(estNumResults, term)) # initialize the total number of images downloaded thus far total = 0 # loop over the estimated number of results in `GROUP_SIZE` groups for offset in range(0, estNumResults, GROUP_SIZE): # update the search parameters using the current offset, then # make the request to fetch the results print("[INFO] making request for group {}-{} of {}...".format( offset, offset + GROUP_SIZE, estNumResults)) params["offset"] = offset search = requests.get(URL, headers=headers, params=params) search.raise_for_status() results = search.json() print("[INFO] saving images for group {}-{} of {}...".format( offset, offset + GROUP_SIZE, estNumResults)) # loop over the results for v in results["value"]: # try to download the image try: # make a request to download the image print("[INFO] fetching: {}".format(v["contentUrl"])) r = requests.get(v["contentUrl"], timeout=30) # build the path to the output image ext = v["contentUrl"][v["contentUrl"].rfind("."):] p = os.path.sep.join([args["output"], "{}{}".format( str(total).zfill(8), ext)]) # write the image to disk f = open(p, "wb") f.write(r.content) f.close() # catch any errors that would not unable us to download the # image except Exception as e: # check to see if our exception is in our list of # exceptions to check for if type(e) in EXCEPTIONS: print("[INFO] skipping: {}".format(v["contentUrl"])) continue # try to load the image from disk image = cv2.imread(p) # if the image is `None` then we could not properly load the # image from disk (so it should be ignored) if image is None: print("[INFO] deleting: {}".format(p)) os.remove(p) continue # update the counter total += 1要注意的是,代码里的
API_KEY = "这里填你的API_KEY"
要填上你自己的API_KEY。
运行的命令是:
python search_bing_api.py --query "manhole" --output dataset/manhole
其中
--query
后面跟的是你想要搜索的东西名字,
--output
后面就是你的输出目录了。 -
直接在代码指定的
### filename: search_bing_api.py from requests import exceptions import requests import cv2 import os import gevent # poke name to download # 你的搜索名字和输出目录 pokemon = 'mewtwo' output = 'datasets/mewtwo' API_KEY = "你的api" MAX_RESULTS = 250 GROUP_SIZE = 50 # set the endpoint API URL URL = "https://api.cognitive.microsoft.com/bing/v7.0/images/search" # when attempting to download images from the web both the Python # programming language and the requests library have a number of # exceptions that can be thrown so let's build a list of them now # so we can filter on them EXCEPTIONS = {IOError, FileNotFoundError, exceptions.RequestException, exceptions.HTTPError, exceptions.ConnectionError, exceptions.Timeout} # store the search term in a convenience variable then set the # headers and search parameters term = pokemon headers = {"Ocp-Apim-Subscription-Key": API_KEY} params = {"q": term, "offset": 0, "count": GROUP_SIZE} # make the search print("[INFO] searching Bing API for '{}'".format(term)) search = requests.get(URL, headers=headers, params=params) search.raise_for_status() # grab the results from the search, including the total number of # estimated results returned by the Bing API results = search.json() estNumResults = min(results["totalEstimatedMatches"], MAX_RESULTS) print("[INFO] {} total results for '{}'".format(estNumResults, term)) # initialize the total number of images downloaded thus far total = 0 def grab_page(url, ext, total): try: # total += 1 print("[INFO] fetching: {}".format(url)) r = requests.get(url, timeout=30) # build the path to the output image #here total is only for filename creation p = os.path.sep.join([output, "{}{}".format( str(total).zfill(8), ext)]) # write the image to disk f = open(p, "wb") f.write(r.content) f.close() # try to load the image from disk image = cv2.imread(p) # if the image is `None` then we could not properly load the # image from disk (so it should be ignored) if image is None: print("[INFO] deleting: {}".format(p)) os.remove(p) return # catch any errors that would not unable us to download the # image except Exception as e: # check to see if our exception is in our list of # exceptions to check for if type(e) in EXCEPTIONS: print("[INFO] skipping: {}".format(url)) return # loop over the estimated number of results in `GROUP_SIZE` groups for offset in range(0, estNumResults, GROUP_SIZE): # update the search parameters using the current offset, then # make the request to fetch the results print("[INFO] making request for group {}-{} of {}...".format( offset, offset + GROUP_SIZE, estNumResults)) params["offset"] = offset search = requests.get(URL, headers=headers, params=params) search.raise_for_status() results = search.json() print("[INFO] saving images for group {}-{} of {}...".format( offset, offset + GROUP_SIZE, estNumResults)) # loop over the results jobs = [] for v in results["value"]: total += 1 ext = v["contentUrl"][v["contentUrl"].rfind("."):] url = v["contentUrl"] # create gevent job jobs.append(gevent.spawn(grab_page, url, ext, total)) # wait for all jobs to complete gevent.joinall(jobs, timeout=10) print(total)
看一下代码,我在上面都注释。
运行,会出来如下结果:

版权声明:本文为luke_sanjayzzzhong原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。