
主要需要解决的问题有两个:
- 高并发对数据库产生的压力
- 竞争状态下如何解决库存的正确减少(超卖问题)
优化的思路:
1) 尽量将请求拦截在系统上游
2)读多写少经量多使用缓存
3) redis缓存 +RabbitMQ+ mysql 批量入库
1. 初始秒杀设计
1.1 业务分析
秒杀系统业务流程如下:
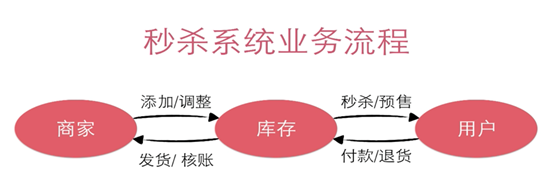
由图可以发现,整个系统其实是针对库存做的系统。用户成功秒杀商品,对于我们系统的操作就是:
1.
减库存。2.
记录用户的购买明细。
下面看看我们用户对库存的业务分析:
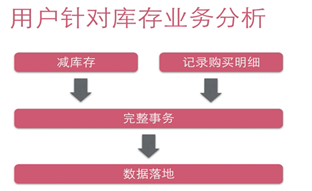
记录用户的秒杀成功信息,我们需要记录:
1.
谁购买成功了。2.
购买成功的时间/
有效期
。这些数据组成了用户的秒杀成功信息,也就是用户的购买行为。
为什么我们的系统需要事务
?
1.若是用户成功秒杀商品我们记录了其购买明细却没有减库存。导致商品的
超卖
。
2.减了库存却没有记录用户的购买明细。导致商品的
少卖
。对于上述两个故障,若是没有事务的支持,损失最大的无疑是我们的用户和商家。在MySQL中,它内置的事务机制,可以准确的帮我们完成减库存和记录用户购买明细的过程。
1.2 难点分析
当用户A秒杀id为10的商品时,此时
MySQL
需要进行的操作是:
1.开启事务。2.更新商品的库存信息。3.添加用户的购买明细,包括用户秒杀的商品id以及唯一标识用户身份的信息如电话号码等。4.提交事务。
若此时有另一个用户B也在秒杀这件id为10的商品,他就需要等待,等待到用户A成功秒杀到这件商品,然后MySQL成功的提交了事务他才能拿到这个id为10的商品的锁从而进行秒杀,而同一时间是不可能只有用户B在等待,肯定是有很多很多的用户都在等待
竞争行级锁
。秒杀的难点就在这里,如何高效的处理这些竞争?如何高效的完成事务?
1.3 功能实现
我们只是实现秒杀的一些功能
:1.
秒杀接口的暴露。2.
执行秒杀的操作。3.
相关查询
,比如说列表查询,详情页查询。我们实现这三个功能即可。
1.4 数据库设计
Seckill秒杀表单

Success_seckill购买明细表

在购买明细表中seckill_id和user_phone是联合主键,当重复秒杀的时候,加入ignore防止报错,只是会返回0,表示重复秒杀。
INSERT
ignore
INTO success_killed(seckill_id,user_phone,state)
VALUES (#{seckillId},#{userPhone},0)
在购买明细表中seckill_id和user_phone是联合主键,当重复秒杀的时候,加入ignore防止报错,只是会返回0,表示重复秒杀。
INSERT
ignore
INTO success_killed(seckill_id,user_phone,state)
VALUES (#{seckillId},#{userPhone},0)
1.5 DAO层设计
秒杀表的DAO:减库存(id,nowtime)、由id查询商品、由偏移量查询商品
购买明细表的DAO:插入购买明细、根据商品id查询明细SucceesKill对象(携带Seckill对象)—mybatis的复合查询
减库存和增加明细的
sql

<update id="reduceNumber">
UPDATE seckill
SET number = number-1
WHERE seckill_id=#{seckillId}
AND start_time <![CDATA[ <= ]]> #{killTime}
AND end_time >= #{killTime}
AND number > 0;
</update>
<insert id="insertSuccessKilled">
<!--当出现主键冲突时(即重复秒杀时),会报错;不想让程序报错,加入ignore-->
INSERT ignore INTO success_killed(seckill_id,user_phone,state)
VALUES (#{seckillId},#{userPhone},0)
</insert>

1.6 Service层设计
暴露秒杀地址
(
接口
)DTO

public class Exposer {
//是否开启秒杀
private boolean exposed;
//加密措施
private String md5;
private long seckillId;
//系统当前时间(毫秒)
private long now;
//秒杀的开启时间
private long start;
//秒杀的结束时间
private long end;}

封装执行秒杀后的结果
:
是否秒杀成功
public class SeckillExecution {
private long seckillId;
//秒杀执行结果的状态
private int state;
//状态的明文标识
private String stateInfo;
//当秒杀成功时,需要传递秒杀成功的对象回去
private SuccessKilled successKilled;}

秒杀过程
接口暴露:
public Exposer exportSeckillUrl(long seckillId) {
//缓存优化
Seckill seckill = getById(seckillId);
//若是秒杀未开启
Date startTime = seckill.getStartTime();
Date endTime = seckill.getEndTime();
//系统当前时间
Date nowTime = new Date();
if (startTime.getTime() > nowTime.getTime() || endTime.getTime() < nowTime.getTime()) {
return new Exposer(false, seckillId, nowTime.getTime(), startTime.getTime(), endTime.getTime());
}
//秒杀开启,返回秒杀商品的id、用给接口加密的md5
String md5 = getMD5(seckillId);
return new Exposer(true, md5, seckillId);
}
如果当前时间还没有到秒杀时间或者已经超过秒杀时间,秒杀处于关闭状态,那么返回秒杀的开始时间和结束时间;如果当前时间处在秒杀时间内,返回暴露地址(秒杀商品的id、用给接口加密的md5)
为什么要进行
MD5
加密?
我们用MD5加密的方式对秒杀地址(seckill_id)进行加密,暴露给前端用户。当用户执行秒杀的时候传递seckill_id和MD5,程序拿着seckill_id根据设置的盐值计算MD5,如果与传递的md5不一致,则表示地址被篡改了。
为什么要进行秒杀接口暴露的控制或者说进行秒杀接口的隐藏?
现实中有的用户回通过浏览器插件提前知道秒杀接口,填入参数和地址来实现自动秒杀,这对于其他用户来说是不公平的,我们也不希望看到这种情况。所以我们可以控制让用户在没有到秒杀时间的时候不能获取到秒杀地址,只返回秒杀的开始时间。当到秒杀时间的时候才
返回秒杀地址即seckill_id以及根据seckill_id和salt加密的MD5,前端再次拿着seckill_id和MD5才能执行秒杀。假如用户在秒杀开始前猜测到秒杀地址seckill_id去请求秒杀,也是不会成功的,因为它拿不到需要验证的MD5。这里的MD5相当于是用户进行秒杀的凭证。
执行秒杀:

//秒杀是否成功,成功: 增加明细,减库存;失败:抛出异常,事务回滚
@Transactional
public SeckillExecution executeSeckill(long seckillId, long userPhone, String md5) throws SeckillException, RepeatKillException, SeckillCloseException {
if (md5 == null || !md5.equals(getMD5(seckillId))) {
//秒杀数据被重写了
throw new SeckillException("seckill data rewrite");
}
//执行秒杀逻辑:增加购买明细+减库存
Date nowTime = new Date();
try {
//先增加明细,然后再执行减库存的操作
int insertCount = successKilledDao.insertSuccessKilled(seckillId, userPhone);
//看是否该明细被重复插入,即用户是否重复秒杀
if (insertCount <= 0) {
throw new RepeatKillException("seckill repeated");
} else {
//减库存,热点商品竞争
int updateCount = seckillDao.reduceNumber(seckillId, nowTime);
if (updateCount <= 0) {
//没有更新库存记录,说明秒杀结束或者是已经卖完 rollback
throw new SeckillCloseException("seckill is closed");
} else {
//秒杀成功,得到成功插入的明细记录,并返回成功秒杀的信息 commit
SuccessKilled successKilled = successKilledDao.queryByIdWithSeckill(seckillId, userPhone);
return new SeckillExecution(seckillId, SeckillStatEnum.SUCCESS, successKilled);
}
}
} catch (SeckillCloseException e1) {
throw e1;
} catch (RepeatKillException e2) {
throw e2;
} catch (Exception e) {
logger.error(e.getMessage(), e);
//所以编译期异常转化为运行期异常
throw new SeckillException("seckill inner error :" + e.getMessage());
}
}


首先检查用户是否已经登录,查看cookie中是否有phone的信息,如果没有,返回没有注册的错误信息。
接着执行秒杀,首先验证md5,看地址是否被篡改。先增加明细(为什么要先增加明细见后面优化的过程),看是否该明细被重复插入,即用户是否重复秒杀,如果是,抛异常。然后减库存,因为sql在减库存的时候判断了当前时间和秒杀时间是否对应,如果数据库update返回0没有更新库存记录,说明秒杀结束;或者是库存已经没有主动抛出错误rollback。(前面在获取秒杀地址的时候已经挡住了秒杀关闭的请求(没到时间或者时间已过),然后从获取到秒杀地址到执行秒杀还可能会在这段时间秒杀结束)
最后秒杀成功,得到购买明细信息,接着commit。
注意事务在这里的处理:
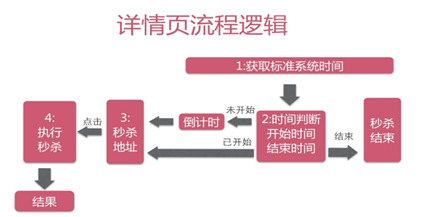
1.7 Web层设计
交互流程
2. 初始优化设计
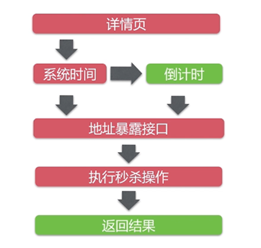
红色部分代表可能高并发的点,绿色表示没有影响
2.1 详情页缓存
通过
CDN
缓存静态资源,来抗峰值。
动静态数据分离
详情页静态资源是部署在CDN节点中,也就是说访问静态资源或者详情页是不用访问我们的系统的。
限流小技巧:
用户提交之后按钮置灰,禁止重复提交
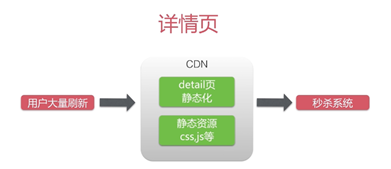
为什么要单独ajax
请求获取服务器的时间?
为了保持时间一致,因为详情页放在CDN上和系统存放的位置是分离的。
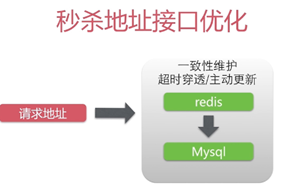
2.2 秒杀接口地址缓存
无法使用CDN是因为,CDN适合的请求的资源是不易变化的。
秒杀接口是变化的,可以使用redis服务端缓存可以用集群抗住非常大的并发。1秒钟可以承受10万qps。多个Redis组成集群,可以到100w个qps
一致性
:当秒杀的对象改变的时候修改我们的数据库同时修改缓存。
原本查询秒杀商品时是通过主键直接去数据库查询的,选择将数据缓存在Redis,在查询秒杀商品时先去Redis缓存中查询,以此降低数据库的压力。如果在缓存中查询不到数据再去数据库中查询,再将查询到的数据放入Redis缓存中,这样下次就可以直接去缓存中直接查询到。
这里有一个继续优化的点:在
redis
中存放对象是将对象序列化成
byte
字节。
通过Jedis储存对象的方式有大概三种
- 本项目采用的方式:将对象序列化成byte字节,最终存byte字节;
- 对象转hashmap,也就是你想表达的hash的形式,最终存map;
- 对象转json,最终存json,其实也就是字符串
其实如果你是平常的项目,并发不高,三个选择都可以,这种情况下以hash的形式更加灵活,可以对象的单个属性,但是问题来了,在秒杀的场景下,三者的效率差别很大。
|
|
|
|
|
存json |
10s |
14M |
|
存byte |
6s |
6M |
|
存jsonMap |
10s |
20M |
|
存byteMap |
4s |
4M |
|
取json |
7s |
|
|
取byte |
4s |
|
|
取jsonmap |
7s |
|
|
取bytemap |
4s |
bytemap最快啊,为啥不用啊,因为项目用了超级高性能的自定义序列化工具protostuff。
2.3 秒杀操作优化
Mysql真的低效吗?
在mysql端一条update压力测试约4wQPS,即使是现在最好的秒杀产品应该也达不到这个数字。
然而实际上远没有这么高的QPS,那么时间消耗在哪呢?
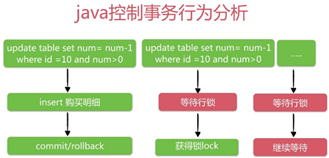
串行化操作,大量的堵塞
2.3.1 瓶颈分析
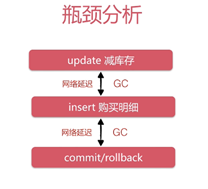
客户端执行update,当我们的sql通过网络发送到mysql的时候,这本身就有网络延迟在里面,并且还有GC的时间,GC又分为新生代GC和老年代GC,新生代会暂停所有的事务代码,也就是我们的java代码,一般在几十毫秒
也即是说如果由java客户端去控制这些事务的话,update减库存,网络延迟,update数据操作结果返回,然后执行GC;然后执行insert,发生网络延迟,等待insert执行结果返回,也可能出现GC,最后commit或者rollback。当这些执行完了之后,第二个等待行锁的线程才有可能拿到这个数据行的锁,再去执行update减库存。
不是我们的mysql慢,也不是java慢,可能存在我们的java客户端执行这些sql,然后等待这些sql的结果,再去做判断再去执行这些sql,这一长串的事务在java客户端执行,但是java客户端和数据库之间会有网络延迟,或者是GC这些时间也要加载事务的执行周期里面,而同一行的事务是串行化的。
那么我们的QPS分析就是所有的
sql
执行时间+
网络延迟时间+
可能的GC
,这就是当前执行一行数据的时间。
优化的方向

2.3.2 简单优化

将原本先update(减库存)再进行insert(插入购买明细)的步骤改成:先insert再update。
为什么要先
insert
后
update
?
首先是在更新操作的时候给行加锁,插入并不会加锁,如果更新操作在前,那么就需要执行完更新和插入以后事务提交或回滚才释放锁。而如果插入在前,更新在后,那么只有在更新时才会加行锁,之后在更新完以后事务提交或回滚释放锁。
在这里,
插入是可以并行的,而更新由于会加行级锁是串行的
。
也就是说是更新在前加锁和释放锁之间两次的网络延迟和GC,如果插入在前则加锁和释放锁之间只有一次的网络延迟和GC,也就是减少的持有锁的时间。
这里先insert并不是忽略了库存不足的情况,而是因为insert和update是在同一个事务里,光是insert并不一定会提交,只有在update成功才会提交,所以并不会造成过量插入秒杀成功记录。
2.3.3 深度优化
客户端逻辑事务
SQL
在
MYSQL
端执行,完全屏蔽网络延迟和
GC
,
MYSQL
只需告诉最终结果。

1. 阿里巴巴做了一个mysql源码层的修改方案,当执行完update之后,它会自动做回滚,回滚的条件影响的记录数是1,就会commit;如果是0就会rollback,不由java客户端来控制commit或者rollback,不给java客户端和mysql之间通信的网络延迟,本质上减低了网络延迟或者GC的干扰,但是这个成本高,要修改mysql源码,只有大公司能做。
2.我们可以将执行秒杀操作时的insert和update放到MySQL服务端的存储过程里,而Java客户端直接调用这个存储过程,这样就可以避免网络延迟和可能发生的GC影响。另外,由于我们使用了存储过程,也就使用不到Spring的事务管理了,因为在存储过程里我们会直接启用一个事务。
2.3.4 优化总结
