当代码出现问题的时候参考的文章
- 处理下载的数据集
- Python3异常-AttributeError: module ‘sys’ has no attribute ‘setdefaultencoding’
- 通过搜狗新闻语料用word2Vec训练中文模型
- 代码存放仓库
1、在RNN中词使用one_hot表示的问题(使用词嵌入的意义)

-
假设有10000个词
- 每个词的向量长度都为10000,整体大小太大
-
没能表示出词与词之间的关系
- 例如Apple与Orange会更近一些,Man与Woman会近一些,取任意两个向量计算内积都为0
2、词嵌入
定义:指把一个维数为所有词的数量的高维空间
嵌入到一个维数低得多的连续向量空间中
,每个单词或词组被映射为实数域上的向量。
注:这个维数通常不定,不同实现算法指定维度都不一样,通常在30~500之间。
如下图所示:
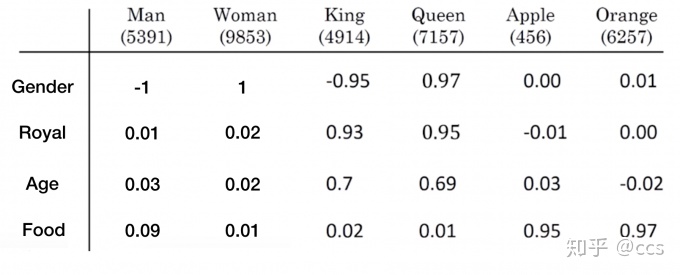
增加维度的说明:
2.1 特点
-
能够体现出词与词之间的关系
- 比如说我们用Man – Woman,或者Apple – Orange,都能得到一个向量
-
能够得到相似词,例如Man – Woman = King – ?
- ? = Queen
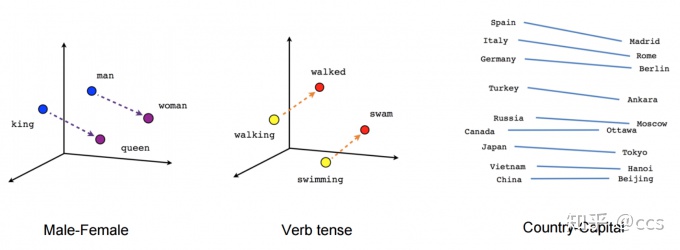
计算说明:

2.2 算法类别
Bengio等人在一系列论文中使用了神经概率语言模型使机器“习得词语的分布式表示。
2013年,谷歌托马斯·米科洛维(Tomas Mikolov)领导的团队发明了一套工具word2vec来进行词嵌入。
- skip-gram
算法学习实现:https://www.tensorflow.org/tutorials/representation/word2vec
- CBow
下载gensim库
pip install gensim
4.3 Word2Vec案例
4.3.1 训练语料
由于语料比较大,就提供了一个下载地址:http://www.sogou.com/labs/resource/cs.php
- 搜狗新闻中文语料(2.7G)
- 做中文分词处理之后的结果
- 下载下来的语料需要进行一些处理请参考通过搜狗新闻语料用word2Vec训练中文模型
4.3.2 步骤
- 1、训练模型
- 2、测试模型结果
4.3.3 代码
-
训练模型API
- from gensim import Word2Vec
-
Word2Vec(LineSentence(inp), size=400, window=5, min_count=5)
- LineSentence(inp):把word2vec训练模型的磁盘存储文件
- 转换成所需要的格式,如:[[“sentence1”],[”sentence1”]]
- size:是每个词的向量维度
- window:是词向量训练时的上下文扫描窗口大小,窗口为5就是考虑前5个词和后5个词
- min-count:设置最低频率,默认是5,如果一个词语在文档中出现的次数小于5,那么就会丢弃
-
方法:
- inp:分词后的文本
- save(outp1):保存模型
trainword2vec.py训练的代码如下
if len(sys.argv) < 3:
sys.exit(1)
# inp表示语料库(分词),outp:模型
inp, outp = sys.argv[1:3]
model = Word2Vec(LineSentence(inp), size=400, window=5, min_count=5, workers=multiprocessing.cpu_count())
model.save(outp)
import sys
import multiprocessing
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
if len(sys.argv) < 3:
sys.exit(1)
# inp表示语料库(分词),outp:模型
inp, outp = sys.argv[1:3]
model = Word2Vec(LineSentence(inp), size=400, window=5, min_count=5, workers=multiprocessing.cpu_count())
model.save(outp)运行命令
python trainword2vec.py ./corpus_seg.txt ./model/*指定好分词的文件以及,保存模型的文件
-
加载模型测试代码
-
model = gensim.models.Word2Vec.load(“*.model”)
- model.most_similar(‘警察’)
- model.similarity(‘男人’,’女人’)
- most_similar(positive=[‘女人’, ‘丈夫’], negative=[‘男人’], topn=1)
-
model = gensim.models.Word2Vec.load(“*.model”)

版权声明:本文为weixin_29817863原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。