一、LeNet-5网络结构

Lenet是一个 7 层的神经网络,包含 3 个卷积层,2 个池化层,1 个全连接层。其中所有卷积层的所有卷积核都为 5×5,步长 stride=1,池化方法都为全局 pooling,激活函数为 Sigmoid。
整个 LeNet-5 网络总共包括7层(不含输入层),分别是:C1、S2、C3、S4、C5、F6、OUTPUT。
二、Lenet的keras实现
如今各大深度学习框架中所使用的LeNet都是简化改进过的LeNet-5,和原始的LeNet有些许不同,把激活函数改为了现在很常用的ReLu。
import tensorflow as tf
from tensorflow import keras
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D, Flatten
from keras.layers import Dense
def LeNet():
# model = tf.keras.models.Sequential()
model = Sequential()
model.add(Conv2D(32, (5,5), strides=(1,1), input_shape=(28,28,1), padding='valid',
activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (5,5), strides=(1,1), padding='valid',
activation='relu', kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(100, activation='relu'))
model.add(Dense(10, activation='softmax'))
return model
model = LeNet()
model.summary()
三、Lenet的pytorch实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet5(nn.Module):
def __init__(self, num_classes, grayscale=False):
'''
:param num_classes: 分类的数量
:param grayscale: 是否为灰度图
'''
super(LeNet5, self).__init__()
self.grayscale = grayscale
self.num_classes = num_classes
if self.grayscale: # 可以适用单通道和三通道的图像
in_channels = 1
else:
in_channels = 3
# 卷积神经网络
self.features = nn.Sequential(
nn.Conv2d(in_channels, 6, kernel_size=5),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(6, 16, kernel_size=5),
nn.MaxPool2d(kernel_size=2)
)
# 分类器
self.classifier = nn.Sequential(
nn.Linear(16*5*5, 120), # 这里把第三个卷积当作是全连接层
nn.Linear(120, 84),
nn.Linear(84, num_classes)
)
def forward(self, x):
x = self.features(x) # 输出16*5*5特征图
x = torch.flatten(x, 1) # 展平(1,16*5*5)
logits = self.classifier(x) # 输出10
probas = F.softmax(logits, dim=1)
return logits, probas
num_classes = 10 # 分类数目
grayscale = True # 是否为灰度图
data = torch.rand((1, 1, 32, 32))
print('input data:\n', data, '\n')
model = LeNet5(num_classes, grayscale)
logits, probas = model(data)
print('logits:\n', logits)
print('probas:\n', probas)
四、手写数字识别(keras)
4.1 手写数字识别代码1
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
# from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# 1.导入数据
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 2.归一化
# 将像素的值标准化至0到1的区间内
train_images, test_images = train_images/255.0, test_images/255.0
train_images.shape, test_images.shape, train_labels.shape, test_labels.shape
# 输出:((60000, 28, 28), (10000, 28, 28), (60000,), (10000,))
# 3.可视化图片
plt.figure(figsize=(20,20))
for i in range(20):
plt.subplot(5, 10, i+1)
plt.xticks([])
plt.yticks([])
plt.grid(False)
plt.imshow(train_images[i], cmap='gray')
# plt.imshow(train_images[i], cmap=plt.cm.binary)
plt.xlabel(train_labels[i])
plt.show()
# 4.调整图片格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images, test_images = train_images/255.0, test_images/255.0
train_images.shape, test_images.shape, train_labels.shape, test_labels.shape
# 输出:((60000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))
# 5. 模型构建
# 构建LeNet-5网络模型
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
# 6. 打印网络结构
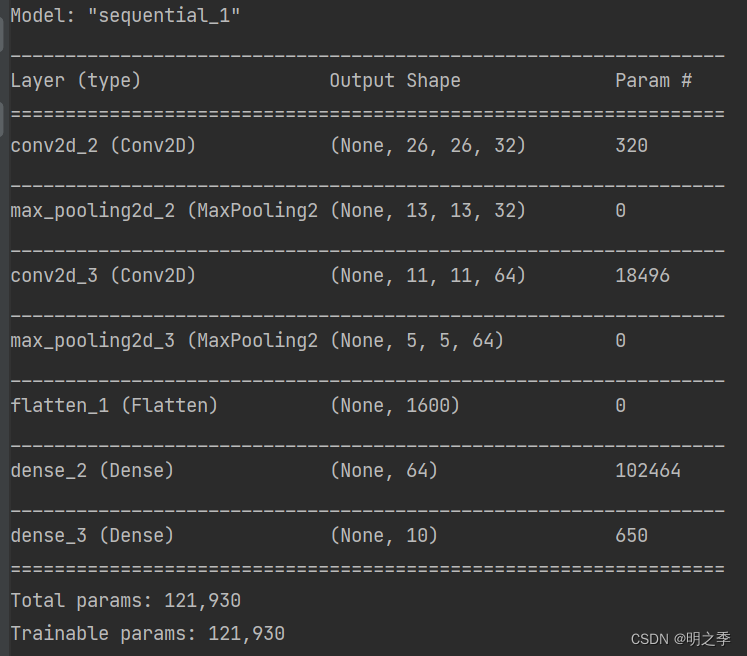
model.summary()
# 7. 模型编译
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
# 8. 模型训练
history = model.fit(train_images, train_labels, epochs=2,
validation_data=(test_images, test_labels))
# 显示第一张图片
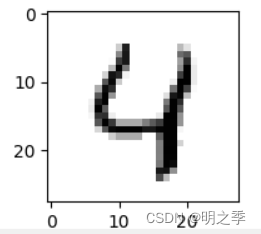
plt.imshow(test_images[1], cmap='gray')
# 输出预测结果
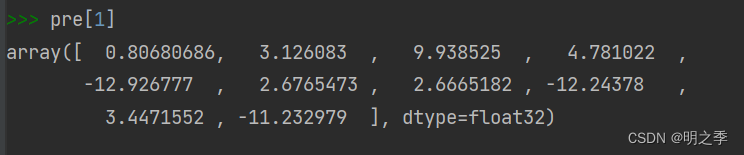
pre = model.predict(test_images)
# 输出测试集中第一张图片的预测结果
pre[1]
可视化图片

模型结构及参数
显示第一张图片

输出测试集中第一张图片的预测结果
4.2 手写数字识别代码2
# Mnist手写数字识别
# 使用TensorFlow搭建LeNet-5网络模型,实现MNIST手写数字识别
import tensorflow as tf
from tensorflow import keras
from keras.datasets import mnist
from keras.utils import np_utils
from keras.models import Sequential
from keras.layers import Conv2D, MaxPooling2D, Flatten
from keras.layers.core import Dense, Activation, Dropout
from keras.utils.vis_utils import plot_model
import matplotlib.pyplot as plt
(X_train,Y_train), (X_test,Y_test) = mnist.load_data()
X_test1 = X_test
Y_test1 = Y_test
X_train = X_train.reshape(-1,28,28,1).astype('float32')/255.0
X_test = X_test.reshape(-1,28,28,1).astype('float32')/255.0
'''
x = tf.reshape(x, shape=[-1, 28, 28, 1])
x_image = tf.reshape(x, [-1, 28, 28, 1])
Mnist中数据,输入n个样本,每个样本是28*28=784个列构成的向量。所以输入的是n*784的矩阵。
但是输入到CNN中需要卷积,需要每个样本都是矩阵。
这里是将一组图像矩阵x重建为新的矩阵,该新矩阵的维数为(a,28,28,1),其中-1表示a由实际情况来定。
例如,x是一组图像的矩阵(假设是50张,大小为56×56),则执行则执行x_image = tf.reshape(x, [-1, 28, 28, 1])
可以计算a=50×56×56/28/28/1=200。即x_image的维数为(200,28,28,1)
'''
"""
astype:实现变量类型转换。使用 .astype() 方法在不同的数值类型之间相互转换。
a.astype(int) # 将a的数值类型转换为 int。
Python中与数据类型相关函数及属性有如下三个:type/dtype/astype
type() 返回参数的数据类型
dtype 返回数组中元素的数据类型
astype() 对数据类型进行转换
"""
# 标签预处理
nb_classes = 10
Y_train = np_utils.to_categorical(Y_train, nb_classes)
Y_test = np_utils.to_categorical(Y_test, nb_classes)
"""
np_utils.to_categorical()函数
to_categorical()用于分类,将标签转为one-hot编码。。
"""
# 模型搭建
model = Sequential()
model.add(Conv2D(filters=6, # 卷积核个数
kernel_size=(5,5), # 卷积核大小5*5
strides=1, # 步长
padding='same', # 像素填充方式
activation='tanh', # 激活函数
input_shape=(28,28,1) # 输入数据28*28
))
model.add(MaxPooling2D(pool_size=(2,2), # 池化窗口大小2*2
strides=2, # 池化步长为2
padding='same' # 像素填充方式为same
))
model.add(Conv2D(filters=16, kernel_size=(5,5), padding='same', activation='tanh'))
model.add(MaxPooling2D(pool_size=(2,2), strides=1, padding='same'))
model.add(Flatten())
# 全连接层
model.add(Dense(120))
model.add(Activation('tanh'))
model.add(Dropout(0.2))# 设置为0.2,改层会随机忽略20%的神经元
model.add(Dense(84))
model.add(Activation('tanh'))
# 输出层
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
# 显示模型摘要
model.summary()
plot_model(model=model, to_file='model_cnn.png', show_shapes=True)
# 模型编译
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 模型训练
nb_epoch = 10
batchsize = 512
# training = model.fit(x=X_train, y=Y_train, batch_size=batchsize, epochs=nb_epoch,
# verbose=2, validation_split=0.2)
training = model.fit(x=X_train, y=Y_train, batch_size=batchsize, epochs=2,
verbose=2, validation_split=0.2)
# 画出训练过程随着迭代(epoch)准确率的变化图
def show_accuracy1(train_history, train, validation):
plt.plot(training.history[train], linestyle='-', color='b')
plt.plot(training.history[validation], linestyle='--', color='r')
plt.title('Training_accuray')
plt.xlabel('epoch')
plt.ylabel('train')
plt.legend(['train', 'validation'], loc='lower right')
plt.show()
show_accuracy1(training, 'accuracy', 'val_accuracy')
# 画出训练过程中随着迭代次数(epoch)误差的变化图
def show_accuracy2(train_history, train, validation):
plt.plot(training.history[train], linestyle='-', color='b')
plt.plot(training.history[validation], linestyle='--', color='r')
plt.title('Training_loss')
plt.xlabel('epoch')
plt.ylabel('train')
plt.legend(['train', 'validation'], loc='upper right')
plt.show()
show_accuracy2(training, 'loss', 'val_loss')
# 模型评估
test = model.evaluate(X_test, Y_test, verbose=1)
print('误差:', test[0])
print('准确率:', test[1])
# 误差: 0.07175197452306747
# 准确率: 0.9775000214576721
"""
model.evaluate()函数
评估模型,不输出预测结果。
输入数据和标签,输出损失和精确度.
loss, accuracy = model.evaluate(X_test, Y_test)
"""
"""
model.predict()函数
模型预测,输入测试数据,输出预测结果。
y_pred = model.predict(X_test, batch_size=1)
"""
"""
两者差异
(1)输入输出不同
model.evaluate:输入数据(data)和真实标签(label),然后将预测结果与真实标签相比较,得到两者误差并输出
model.predict:输入数据(data),输出预测结果
(2)是否需要真实标签
model.evaluate:需要,因为需要比较预测结果与真实标签的误差
model.predict:不需要,只是单纯的预测结果,不需要真实标签的参与
"""
# 模型预测
prediction = model.predict(X_test)
def plot_image(image):
fig = plt.gcf() # 获取当前的图像
fig.set_size_inches(2,2) # 设置图像大小
plt.imshow(image, cmap='binary')
plt.show()
def pre_result(i):
plot_image(X_test1[i])
print('真实值:', Y_test1[i])
print('预测值:', prediction[i])
pre_result(4)
随着迭代模型准确率的变化,由于笔记本性能有限,仅仅迭代2次

损失函数随模型迭代的变化

最后显示图片

参考链接:
https://blog.csdn.net/qq_42570457/article/details/81460807
https://zhuanlan.zhihu.com/p/116181964
https://zhuanlan.zhihu.com/p/379577547
https://blog.csdn.net/hgnuxc_1993/article/details/115566799