文章总结自:【深度学习的模型压缩与加速】台湾交通大学 張添烜教授
文章目录
模型参数计算方法:
Params
:模型的参数量。
FLOPs
:FLoating point OPerations,前向推理forward的计算量,每秒浮点运算次数,理解为计算速度。
MAC
:Memory Access Cost。
MADD
(也叫MACC):multiply-accumulate operations:先乘起来再加起来的运算次数。
TFLOPS
(Tera FLoating-point Operations Per-second) :描述某种操作的计算密度
(第一个参数Params衡量的是模型的参数量,后面几个衡量的是模型的计算量。)
# 计算参数量total_num与可训练参数量trainable_num
def get_parameter_number(model):
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return {'Total': total_num, 'Trainable': trainable_num}
# 第三方工具,计算总参数量、总内存大小、MAdd、Flops、Mem+W
from torchstat import stat
import torchvision.models as models
model = models.alexnet()
stat(model, (3, 224, 224))
# 第三方工具,计算flops、总参数量
from torchvision.models import alexnet
import torch
from thop import profile
model = alexnet()
input = torch.randn(1, 3, 224, 224)
flops, params = profile(model, inputs=(input, ))
print(flops, params)
模型压缩方法
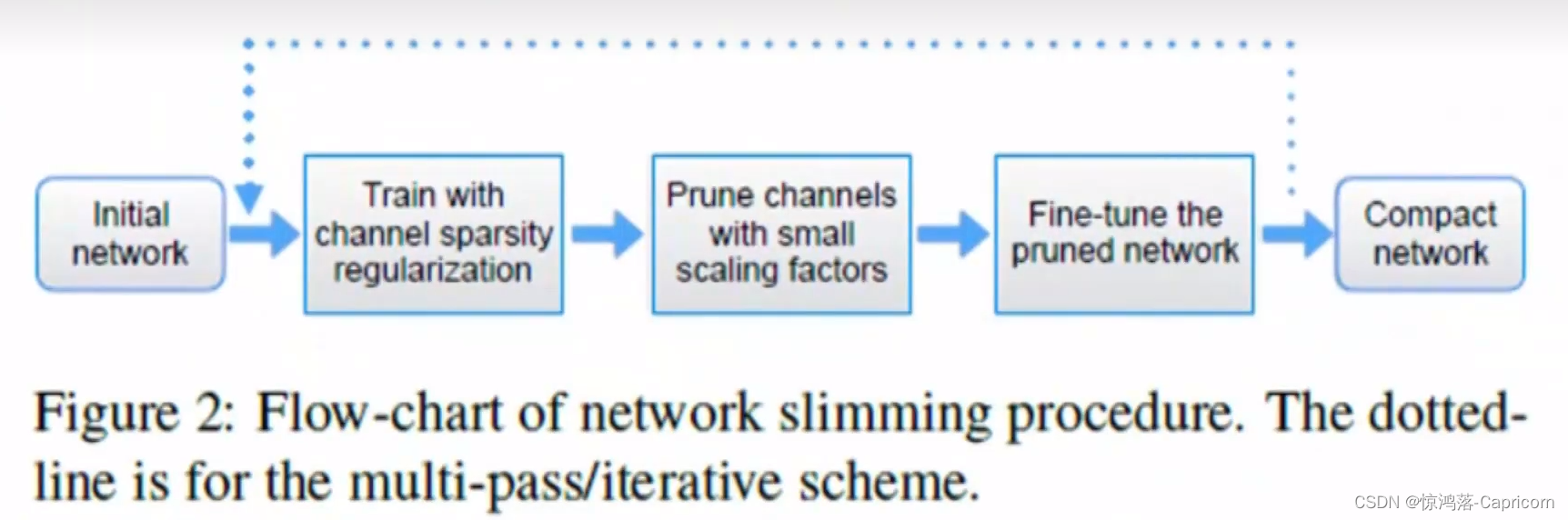
1.剪枝(Pruning)
结构复杂的网络具有非常好的性能,其参数也存在冗余,因此对于已训练好的模型网络,可以寻找一种有效的评判手段,将不重要的connection或者filter进行裁剪来减少模型的冗余。
方法一:
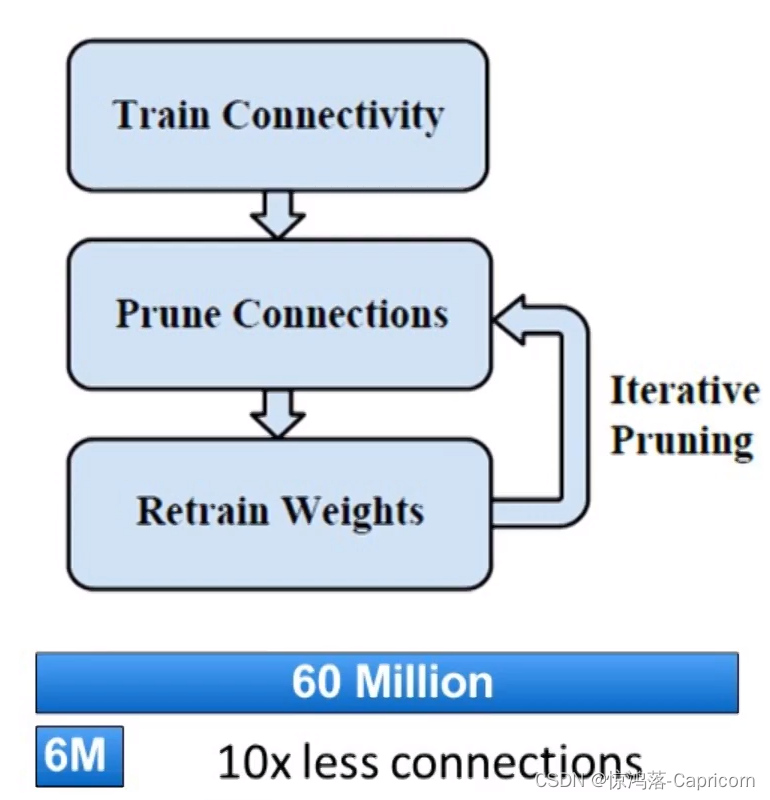
算法流程:
训练、迭代(L2、Mask剪枝、重新训练)
剪枝方法基本流程如下:
- 正常流程训练一个神经网络,得到训练好的model;
- 确定一个需要剪枝的层,一般为全连接层,设定一个裁剪阈值或者比例。实现上,通过修改代码加入一个与参数矩阵尺寸一致的mask矩阵。mask矩阵中只有0和1,实际上是用于重新训练的网络。
- 重新训练微调,参数在计算的时候先乘以该mask,则mask位为1的参数值将继续训练通过BP调整,而mask位为0的部分因为输出始终为0则不对后续部分产生影响。
-
输出模型参数储存的时候,因为有大量的稀疏,所以需要重新定义储存的数据结构,仅储存非零值以及其矩阵位置。重新读取模型参数的时候,就可以还原矩阵。
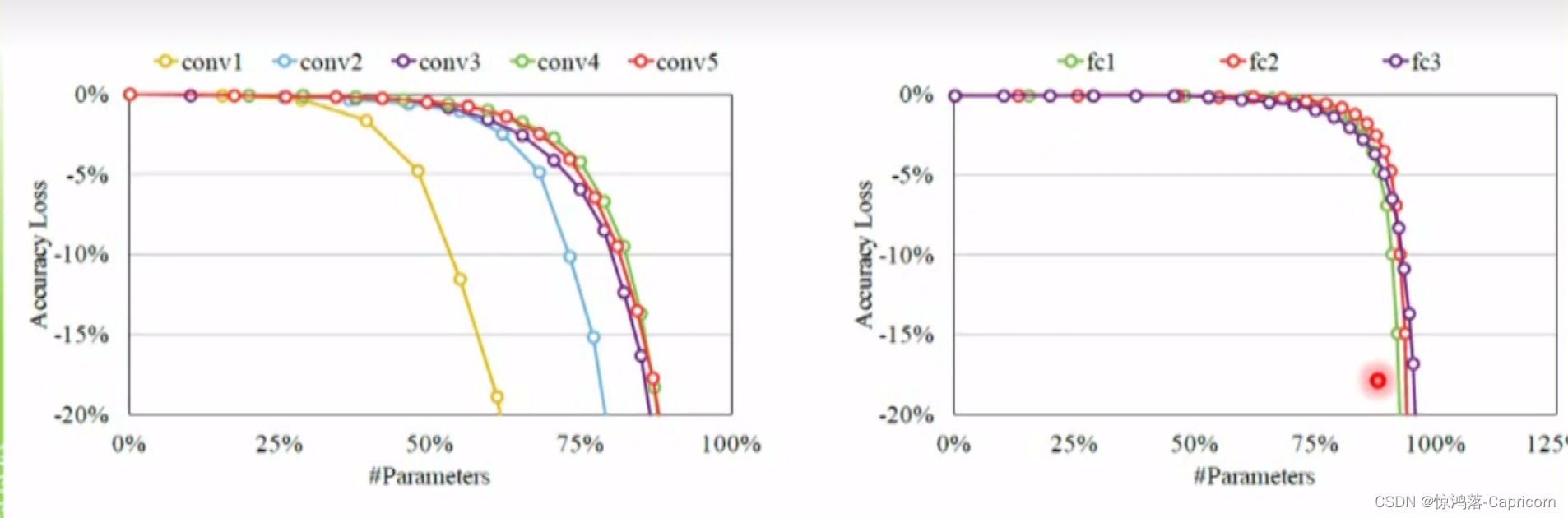
对卷积层剪枝会导致准确率下降,对fc层剪枝影响不大。
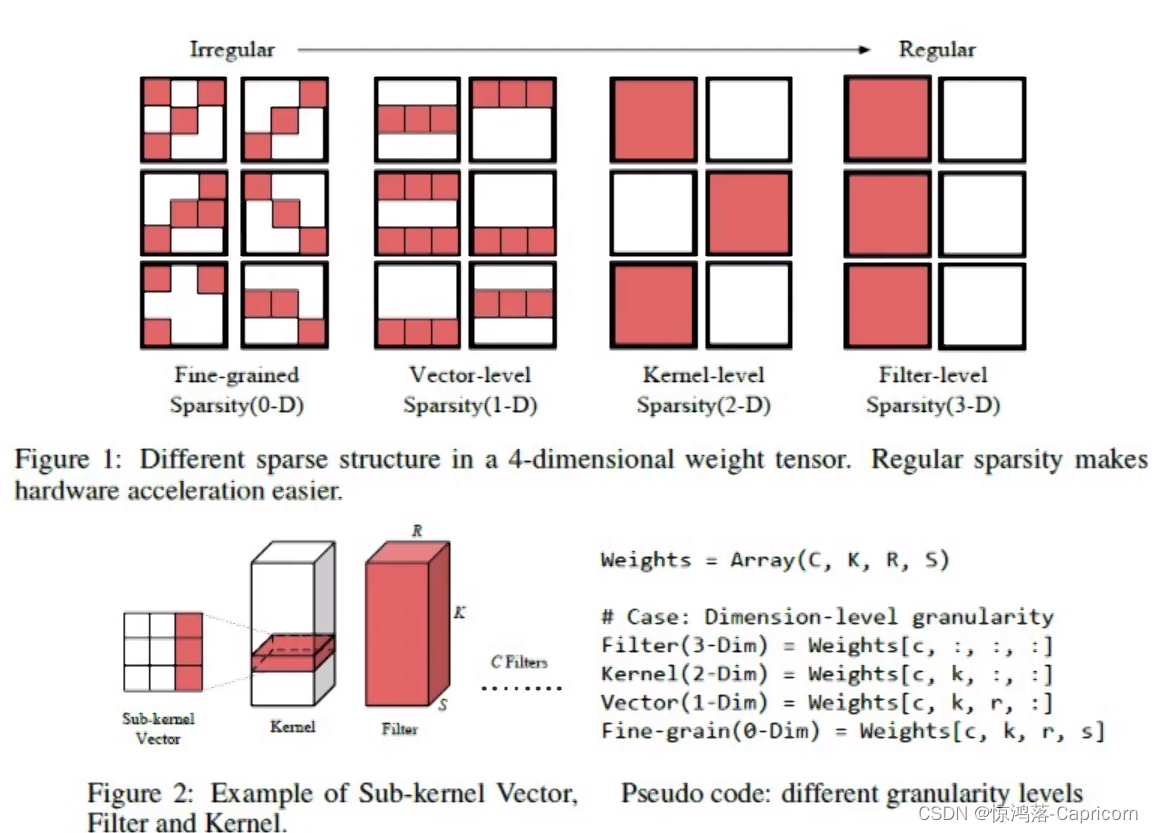
规则的稀疏矩阵(mask)使得模型加速效果更好
若 权重<剪枝阈值γ,此连接直接砍掉,自适应设定的γ也是训练的参数。
通过剪枝操作可以使网络变得稀疏,需要存储的参数量减少,但是剪枝操作同样会降低整个模型的容量(参数量减少),在实际训练时,有时候会通过调整优化函数,诱导网络去利用模型的所有参数,实质上就是减少接近于零的参数量。
2.量化(Quantization)
神经网络的参数类型一般是32位浮点型,通过对网络中的浮点值进行量化处理,一来可以降低权重所需的比特数,二来浮点数计算可以转换为位操作(或者小整数计算),不仅能够减少网络的存储,而且能够大幅度进行加速。
量化后的权值张量是一个高度稀疏的有很多共享权值的矩阵,对非零参数,我们还可以进行定点压缩,以获得更高的压缩率。常见的量化方法有:
二值神经网络(-1,1)、同或网络、三值权重网络(-1,0,1)、量化神经网络
等。
最为典型就是
二值神经网络BNN、XNOR网络
等。其主要原理就是采用1 bit对网络的输入、权重、响应进行编码,BNN要求不仅对权重做二值化,同时也要对网络中间每层的输入值进行二值化,这一操作使得所有参与乘法运算的数据都被强制转换为“-1”、“+1”二值,:将二值浮点数“-1”、“+1”分别用一个比特“0”、“1”来表示,这样,原本占用32个比特位的浮点数现在只需1个比特位就可存放。减少模型大小的同时,原始网络的卷积操作可以被bit-wise运算代替,极大提升了模型的速度。但是,如果原始网络结果不够复杂,由于二值网络会较大程度降低模型的表达能力。因此现阶段有相关的论文开始研究n-bit编码方式成为n值网络或者多值网络或者变bit、组合bit量化来克服二值网络表达能力不足的缺点。
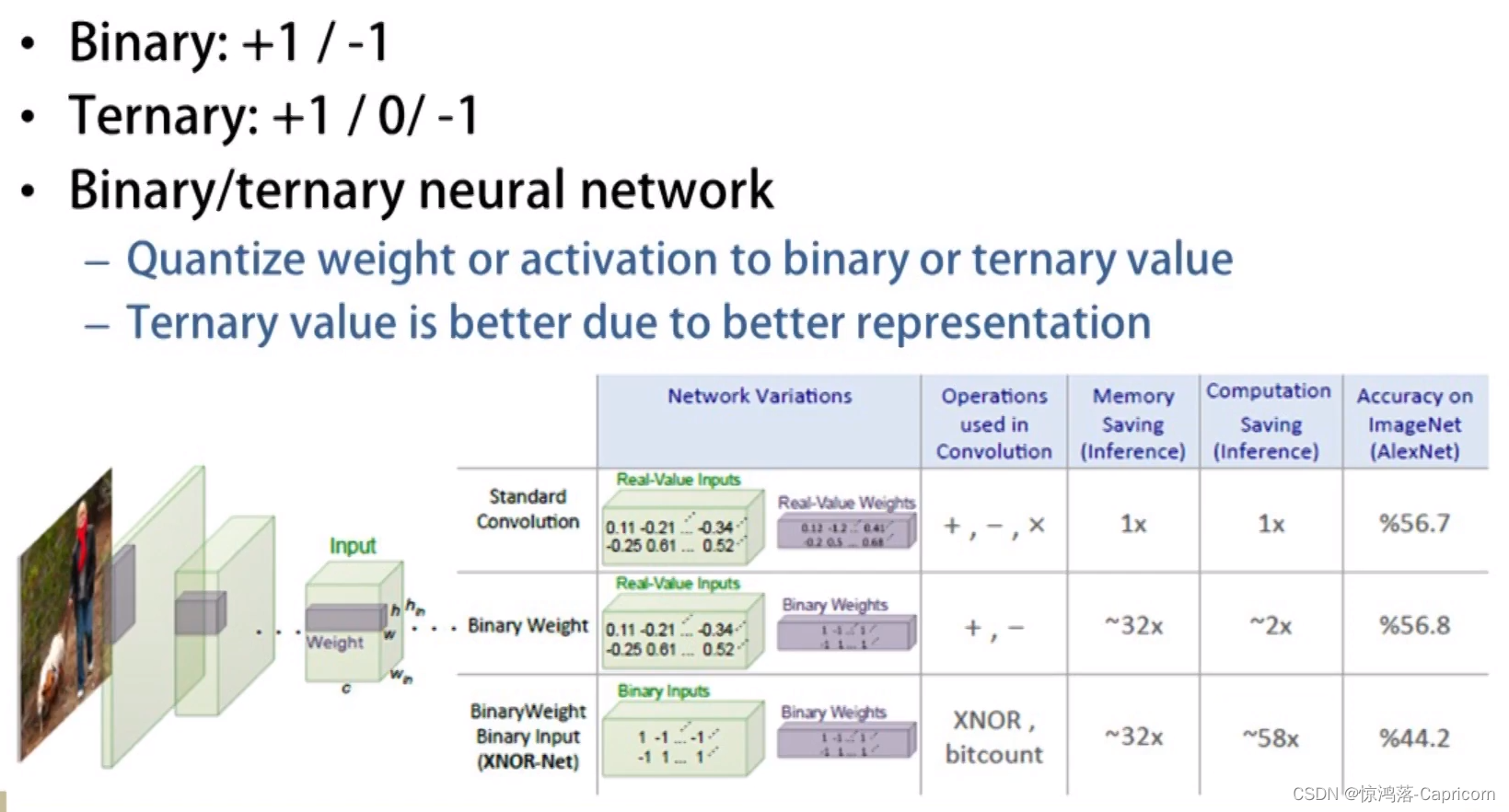
TenserRT采用的模型压缩加速方法
Batch推理
在GPU上使用较大的batch几乎总是更有效,batch的作用在于能尽可能多地并行计算。模型的输入只有单个batch的时候,单个batch的计算量并不能充分的利用CUDA核心的计算资源,有相当一部分的核心在闲置等待中;当输入有多个batch的时候,由于GPU的并行计算的特性,
不同的batch会同步到不同的CUDA核心中进行并行计算
,提高了单位时间GPU的利用率。
计算图合并与优化
TensorRT对于网络结构进行了重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化。一个深度学习模型,在没有优化的情况下,比如一个卷积层、一个偏置层和一个激活层,这三层是需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起的,TensorRT会对一些可以合并网络进行合并。
量化

量化是将数值x映射到 y的过程,其中 x的定义域是一个大集合(通常是连续的),而 y 的定义域是一个小集合(通常是可数的)。大部分深度学习框架在训练神经网络时网络中的张量都是
32位浮点
数的精度(Full 32-bit precision,FP32)。一旦网络训练完成,在部署推理的过程中由于不需要反向传播,完全可以适当降低数据精度,比如
降为FP16或INT8的精度
。量化后模型的体积更小,将带来以下的优势:减少内存带宽和存储空间、提高系统吞吐量(throughput),降低系统延时(latency)。
FP16
TensorRT支持高度自动化的FP16推断(Inference)。与FP32或FP64相比,使用半精度(FP16)可以降低神经网络的内存使用。FP16支持部署更大的网络,同时比FP32或FP64花费更少的时间。当使用FP16检测到推理时,TensorRT会自动使用硬件Tensor Cores。
Tensor Cores
在NVIDIA Tesla V100上的峰值性能比双精度(FP64)快一个数量级,而吞吐量比单精度(FP32)提高了4倍。
INT8
TensorRT可以将以单精度(FP32)或者半精度(FP16)训练的模型转化为以INT8量化部署的模型,同时可以最小化准确率损失。由于INT8的表达范围远远小于FP32,生成8位整数精度的网络时不能像FP16一样直接缩减精度,TensorRT对精度为FP32的模型进行校验来确定中间激活的动态范围,从而确定适当的用于量化的缩放因子。
INT8量化的本质是一种缩放(scaling)操作,通过缩放因子将模型的分布值从FP32范围缩放到 INT8 范围之内。简单的将一个tensor 中的 -|max| 和 |max|的FP32值映射到-127和 127 ,中间值按照线性关系进行映射。这种对称映射关系为不饱和的(No saturation)。
3.轻量化模型设计(Low complexity architecture)
轻量网络设计方向的主要代表论文是 MobileNet v1 / v2,ShuffleNet v1 / v2 等。其主要思想是利用
Depthwise Convolution、Pointwise Convolution、Group Convolution
等
计算量更小、更分散的卷积
代替
标准卷积
。也有将
5×5卷积替换为两个3×3卷积、深度可分离卷积
(3×3卷积替换为1
1卷积(降维作用)+3
3卷积)等轻量化设计。
分组卷积
分组卷积即将输入的feature maps分成不同的组(沿channel维度进行分组),然后对不同的组分别进行卷积操作,即每一个卷积核至于输入的feature maps的其中一组进行连接,而普通的卷积操作是与所有的feature maps进行连接计算。分组数k越多,卷积操作的总参数量和总计算量就越少(减少k倍)。然而分组卷积有一个致命的缺点就是不同分组的通道间减少了信息流通,即输出的feature maps只考虑了输入特征的部分信息,因此在实际应用的时候会在分组卷积之后进行信息融合操作。
ShuffleNet

如上图所示,图a是一般的group convolution的实现效果,其造成的问题是,输出通道只和输入的某些通道有关,导致全局信息 流通不畅,网络表达能力不足。图b就是shufflenet结构,即
通过均匀排列,
把group convolution后的feature map按通道进行均匀混合
,这样就可以更好的获取全局信息了。 图c是操作后的等价效果图。在分组卷积的时候,每一个卷积核操作的通道数减少,所以可以大量减少计算量。
MobileNet
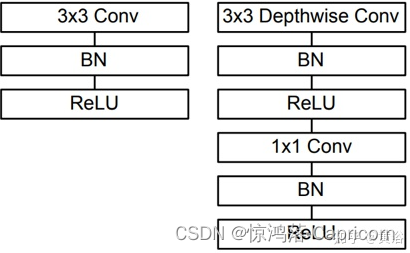
如上图所示,mobilenet采用了depthwise separable convolutions(深度可分离卷积)的思想,
采用depthwise (或叫channelwise)和1×1 pointwise的方法进行分解卷积
。其中depthwise separable convolutions即对每一个通道进行卷积操作,可以看成是每组只有一个通道的分组卷积,最后使用开销较小的1×1卷积进行通道融合,可以大大减少计算量。
MobileNetV2
随后谷歌提出了一种改进模型称为MobileNet V2,其提高了它在多个任务和基准、不同模型尺寸范围内的性能,并定义了一种称为SSDLite的新框架。其特点是:
(1)基于逆残差结构(inverted residual structure),其中薄的瓶颈(bottleneck)层之间设置快捷连接(skip connection)。
(2)中间扩展层使用轻型深度卷积来过滤特征作为非线性的来源。
(3)另外,去除窄层中的非线性以保持表征能力是很重要的。
(4)最后,它允许输入/输出域与变换的表达相分离。
SqueezeNet
SqueezeNet思想非常简单,就是将原来简单的一层conv层变成两层:squeeze层+expand层,各自带上Relu激活层。在squeeze层里面全是
1×1的卷积kernel
,数量记为S11;在expand层里面有1×1和3×3的卷积kernel,数量分别记为E11和E33,要求S11 < input map number。expand层之后将 1×1和3×3的卷积output feature maps在channel维度拼接起来。
4.知识蒸馏(Knowledge distillation)
一般认为模型的参数保留了模型学到的知识,因此最常见的迁移学习的方式就是在一个大的数据集上先做预训练,然后使用预训练得到的参数在一个小的数据集上做微调(两个数据集往往领域不同或者任务不同)。
我们可以先训练好一个teacher网络,然后
将teacher的网络的输出结果 q作为student网络的目标
,训练student网络,使得student网络的结果p接近q ,因此,我们可以将损失函数写成 L=CE(y,p)分类损失+αCE(q,p)学习损失。这里CE是交叉熵(Cross Entropy),y是真实标签的onehot编码,q是teacher网络的输出结果,p是student网络的输出结果。
知识蒸馏,可以将一个网络的知识转移到另一个网络,两个网络可以是同构或者异构。做法是先训练一个teacher网络,然后使用这个teacher网络的输出和数据的真实标签去训练student网络。可以用来将网络从大网络转化成一个小网络,并保留接近于大网络的性能;也可以将多个网络的学到的知识转移到一个网络中,使得单个网络的性能接近emsemble的结果。
5.低秩近似/分解(low-rank Approximation/factorization)
这一部分的思路比较简单,如果把原先网络的权值矩阵当作满秩矩阵来看,我们可以使用多种矩阵低秩近似方法,
将两个大矩阵的乘法操作拆解为多个小矩阵之间的一系列乘法操作
,降低整体的计算量,加速模型的执行速度。
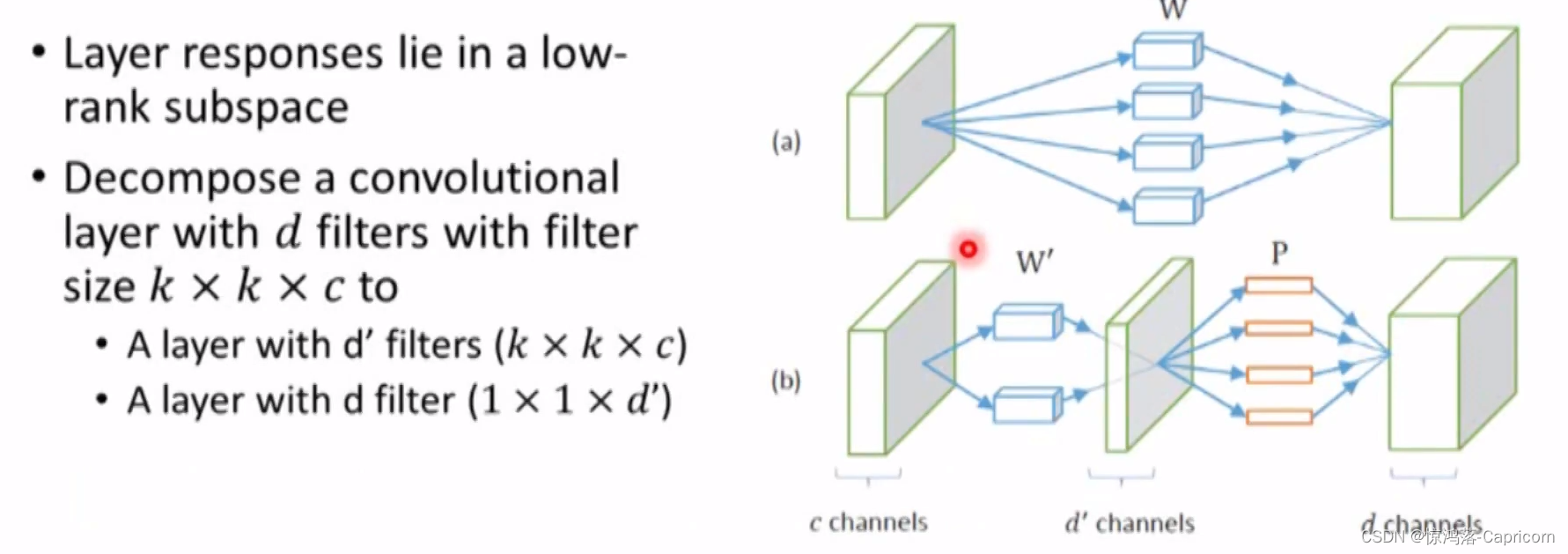
也可以进行Winograd transformation。
那么为什么Low-Rank在这两年不再流行了呢?除了刚才提及的分解方法显而易见、比较容易实现之外,另外一个比较重要的原因是现在越来越多网络中采用1×1的卷积,而这种小的卷积使用矩阵分解的方法很难实现网络加速和压缩。
6.动态执行(Dynamic Execution)
在一个典型的场景中,仅有少部分被观测数据是重要的;我们将这个现象称为稀疏性(sparsity)。
输入时,动态选择有用的数据(使用Mask选择)进入模型计算,并动态进入需要的部分模型结构计算。
如SBnet,SGAD,动态通道剪枝。
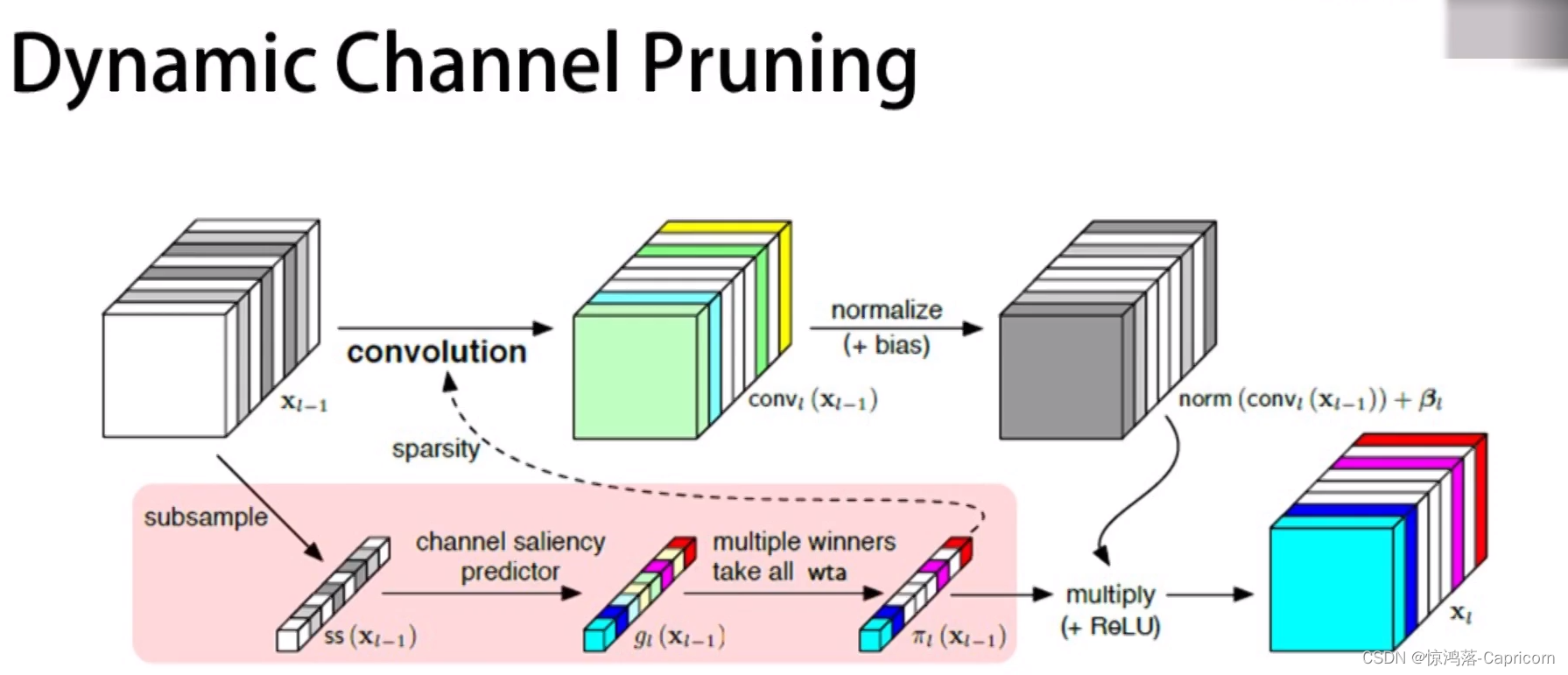
7.神经结构搜索(Neural Architecture Search)
NAS是一种自动设计神经网络的技术,可以通过算法根据样本集
自动设计出高性能的网络结构
,在某些任务上甚至可以媲美人类专家的水准,甚至发现某些人类之前未曾提出的网络结构,这可以有效的降低神经网络的使用和实现成本。
NAS的原理是给定一个称为搜索空间的候选神经网络结构集合,用某种策略从中搜索出最优网络结构。神经网络结构的优劣即性能用某些指标如精度、速度来度量,称为性能评估,可以通过NAS自动搜索出高效率的网络结构。
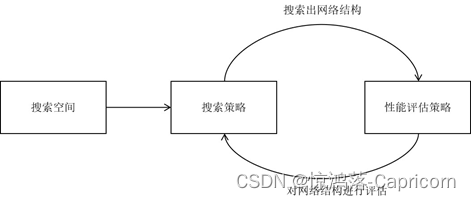
在搜索过程的每次迭代中,从搜索空间产生“样本”即得到一个神经网络结构,称为“子网络”。在训练样本集上训练子网络,然后在验证集上评估其性能。逐步优化网络结构,直至找到最优的子网络。
搜索空间,搜索策略,性能评估策略
是NAS算法的核心要素。搜索空间定义了可以搜索的神经网络结构的集合,即解的空间。搜索策略定义了如何在搜索空间中寻找最优网络结构。性能评估策略定义了如何评估搜索出的网络结构的性能,对这些要素的不同实现得到了各种不同的NAS算法。
搜索空间
搜索空间定义了NAS算法可以搜索的神经网络的类型,同时也定义了如何描述神经网络结构。神经网络所实现的计算可以抽象成一个无孤立节点的有向无环图(DAG),图的节点代表神经网络的层,边代表数据的流动。每个节点从其前驱节点(有边射入)接收数据,经过计算之后将数据输出到后续节点(有边射出)。
(1)网络的拓扑结构。网络有多少个层,这些层的连接关系。在描述网络的拓扑结构时,一般采用前驱节点来定义,即定义每个节点的前驱节点,一旦该信息确定,则网络拓扑结构确定。
(2)每个层的类型。除了第一个层必须为输入层,最后一个层必须为输出之外,中间的层的类型是可选的,它们代表了各种不同的运算即层的类型。典型有全连接,卷积,反卷积,空洞卷积,池化,激活函数等。但这些层的组合使用一般要符合某些规则。
(3)每个层内部的超参数。卷积层的超参数有卷积核的数量,卷积核的通道数,高度,宽度,水平方向的步长,垂直方向的步长等。全连接层的超参数有神经元的数量。激活函数层的超参数有激活函数的类型,函数的参数(如果有)等。
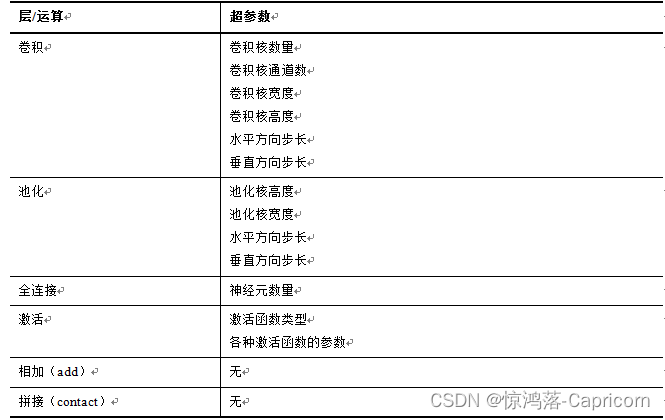
由于描述神经网络结构的参数含有离散数据(如拓扑结构的定义,层的类型,层内的离散型超参数),因此网络结构搜索是一个离散优化问题。定义结构的参数数量一般比较大,因此属于高维优化问题。另外,对于该问题,算法不知道优化目标函数的具体形式(每种网络结构与该网络的性能的函数关系),因此属于黑盒优化问题。这些特点为NAS带来了巨大的挑战。
搜索策略
搜索策略定义了如何找到最优的网络结构,通常是一个迭代优化过程,本质上是超参数优化问题。目前已知的搜索方法有随机搜索,贝叶斯优化,遗传算法,强化学习,基于梯度的算法。
其中强化学习,遗传学习,基于梯度的优化是目前的主流算法
。
强化学习
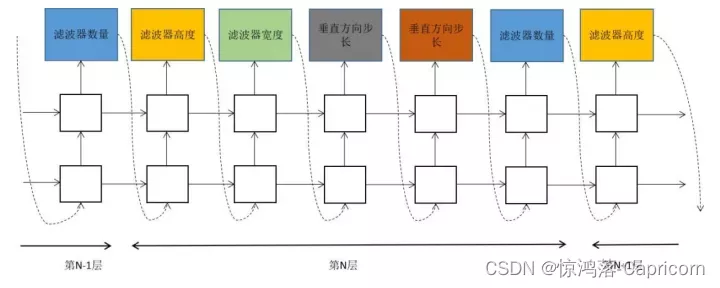
,将神经网络的设计看做一个动作序列,每次执行动作确定网络的一部分结构如层。神经网络在验证集上的性能值是强化学习中的奖励值。算法用一个称为控制器的循环神经网络生成描述子网络结构的串,从而确定子网络的结构。然后在训练集上训练子网络,在验证集上计算其精度值。以精度值作为反馈信号,采用策略梯度算法更新控制器网络的参数。在迭代时,控制器会以给予那些有更高精度值的神经网络以更高的概率值,从而确保策略函数能够输出最优网络结构。这一过程如下图所示。

控制器每一时刻的输出包括:卷积核的数量,卷积核的高度,卷积核的宽度,卷积操作在水平方向的步长,卷积操作在垂直方向的步长。
遗传算法
,将子网络结构编码成二进制串,运行遗传算法得到适应度函数值(神经网络在验证集上的精度值)最大的网络结构,即为最优解。首先随机初始化若干个子网络作为初始解。遗传算法在每次迭代时首先训练所有子网络,然后计算适应度值。接下来随机选择一些子网络进行交叉,变异生成下一代子网络,然后训练这些子网络,重复这一过程,最后找到最优子网络。
基于梯度优化法
,可微结构搜索(Differentiable Architecture Search,简称DARTS)的算法,将离散优化问题连续化,将网络结构搜索转化为连续空间的优化问题,采用梯度下降法求解,可高效地搜索神经网络架构,同时得到网络的权重参数。
其他实现方案,包括序列优化,蒙特卡洛树搜索(MCTS),贝叶斯优化等。
网络压缩未来研究方向有哪些?
网络剪枝、网络精馏和网络分解都能在一定程度上实现网络压缩的目的。回归到深度网络压缩的本质目的上,即提取网络中的有用信息,以下是一些值得研究和探寻的方向。
(1)
权重参数对结果的影响度量
。深度网络的最终结果是由全部的权重参数共同作用形成的,目前,关于单个卷积核/卷积核权重的重要性的度量仍然是比较简单的方式,但是由于计算难度大,并不实用。因此,如何通过更有效的方式来近似度量单个参数对模型的影响,具有重要意义。
(2)
学生网络结构的构造
。学生网络的结构构造目前仍然是由人工指定的,然而,不同的学生网络结构的训练难度不同,最终能够达到的效果也有差异。因此,如何根据教师网络结构设计合理的网络结构在精简模型的条件下获取较高的模型性能,是未来的一个研究重点。
(3)
参数重建的硬件架构支持
。通过分解网络可以无损地获取压缩模型,在一些对性能要求高的场景中是非常重要的。然而,参数的重建步骤会拖累预测阶段的时间开销,如何通过硬件的支持加速这一重建过程,将是未来的一个研究方向。
(4)
任务或使用场景层面的压缩
。大型网络通常是在量级较大的数据集上训练完成的,比如,在 ImageNet上训练的模型具备对 1 000 类物体的分类,但在一些具体场景的应用中,可能仅需要一个能识别其中几类的小型模型。因此,如何从一个全功能的网络压缩得到部分功能的子网络,能够适应很多实际应用场景的需求。
(5)
网络压缩效用的评价
。目前,对各类深度网络压缩算法的评价是比较零碎的,侧重于和被压缩的大型网络在参数量和运行时间上的比较。未来的研究可以从提出更加泛化的压缩评价标准出发,一方面平衡运行速度和模型大小在不同应用场景下的影响;另一方面,可以从模型本身的结构性出发,对压缩后的模型进行评价。
目前有哪些深度学习模型优化加速方法?
模型优化加速能够提升网络的计算效率,具体包括:
-
Op-level的快速算法
:FFT Conv2d (7×7, 9×9), Winograd Conv2d (3×3, 5×5) 等; -
Layer-level的快速算法
:Sparse-block net 等; -
优化工具与库
:
TensorRT
(Nvidia), Tensor Comprehension (Facebook) 和
Distiller
(Intel) 等;