目录
1 概述
Java 程序运行时,需要在内存中分配空间。为了提高运算效率,就对空间进行了不同区域的划分,因为每一片区域都有特定的处理数据方式和内存管理方式。
一、栈:储存局部变量
- 局部变量:在方法的定义中或者在方法声明上的变量称为局部变量。
- 特点:栈内存的数据用完就释放。
二、堆:储存 new 出来的东西
-
特点:
- 每一个 new 出来的东西都有地址值;
- 每个变量都有默认值 (byte, short, int, long 的默认值为 0;float, double 的默认值为 0.0;char 的默认值为 “\u0000”;boolean 的默认值为 false;引用类型为 null);
- 使用完毕就变成垃圾,但是并没有立即回收。会有垃圾回收器空闲的时候回收。

每运行一个java程序会产生一个java进程,每个java进程可能包含一个或者多个线程,每一个Java进程对应唯一一个JVM实例,每一个JVM实例唯一对应一个堆,每一个线程有一个自己私有的栈。进程所创建的所有类的实例(也就是对象)或数组(指的是数组的本身,不是引用)都放在堆中,并由该进程所有的线程共享。Java中分配堆内存是自动初始化的,即为一个对象分配内存的时候,会初始化这个对象中变量。虽然Java中所有对象的存储空间都是在堆中分配的,但是这个对象的引用却是在栈中分配,也就是说在建立一个对象时在堆和栈中都分配内存,在堆中分配的内存实际存放这个被创建的对象的本身,而在栈中分配的内存只是存放指向这个堆对象的引用而已。局部变量 new 出来时,在栈空间和堆空间中分配空间,当局部变量生命周期结束后,栈空间立刻被回收,堆空间区域等待GC回收。
2 内存区域分配
1、Java内存区域
(1)线程私有
虚拟机栈:主要是来描述
java方法
的内存模型。每个方法在执行时都会创建一个
栈帧
,用户存储
局部变量表
,操作数栈,动态链接,方法出口的信息。每一个方法从调用直至完成的过程,就对应着一个栈帧在虚拟机栈中入栈到出栈的过程。
本地方法栈:为虚拟机使用到的Native方法服务
程序计数器:当前线程所执行的字节码的行号指示器
(2)线程公有
堆:JVM所管理的内存中最大的一块。唯一目的就是存放
实例对象
。几乎所有对象实例都在这里分配。java堆是垃圾收集器管理的主要区域
方法区:用户存储已被虚拟机加载的
类信息
,
常量
,
静态常量
,即时编译器编译后的代码等数据
常量池:用户存放编译器生成的各种
字面量
和符号引用。
2、内存分配
java程序需要通过栈上的reference数据来操作堆上的对象
对象的访问定位:句柄访问、直接指针访问
(1)句柄访问
Java堆中划分出一块内存来作为句柄池,reference中存储的是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息,需要两次寻址。
(2)直接指针访问
Java堆中对象的布局中需要考虑如何放置访问类型数据的相关信息,而reference中存储的直接就是对象地址。
使用句柄访问的最大好处就是reference中存储的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为)时只会改变句柄中实例数据指针,而reference本身不需要修改。
3、方法区中的常量池
1、静态常量池:即*.class文件中的常量池,class文件中的常量池不仅仅包含字符串字面量,还包含类、方法的信息,占用class文件绝大部分空间。
2、运行时常量池,则是jvm虚拟机在完成类装载后,将class问文件中的常量池载入到内存中,并保存在方法区中,我们常说的常量池,就是指方法区中的运行时常量池。
String s1 = "Hello";
String s2 = "Hello";
String s3 = "Hel" + "lo";
String s4 = "Hel" + new String("lo");
String s5 = new String("Hello");
String s6 = s5.intern();
String s7 = "H";
String s8 = "ello";
String s9 = s7 + s8;
System.out.println(s1 == s2); // true
System.out.println(s1 == s3); // true
System.out.println(s1 == s4); // false
System.out.println(s1 == s9); // false
System.out.println(s4 == s5); // false
System.out.println(s1 == s6); // true
s1 == s2 : s1、s2在赋值时,均使用的字符串字面量。在编译期间,这种字面量会直接放入class文件中的常量池中,从而实现复用,载入运行时常量池后,s1、s2指向的是同一内存地址,所以相等。
s1 == s3:s3虽然是动态拼接出来的字符串,但是所有参与拼接的部分都是已知的字面量,在编译期间,这种拼接会被优化,编译器直接帮拼好,因此s3 = “Hel” + “lo” 最终被优化成s3 = “Hello”,所以相等。
s9 是由s7与s8两个变量拼接好的。s7与s8在方法区中,拼接后s9被分配到了堆内存中。所以s1与s9不等
s1 == s6是因为intern方法,s5在堆中,intern会将hello字符串添加到常量池中,并返回其在常量池中的地址,因为常量池中已经有了hello字符串,所以intern方法直接返回地址。所以s1与s6相等
必须要关注编译期的行为,才能更好的理解常量池
。
运行时常量池中的常量,基本来源与class文件中的常量
程序运行时,除非手动向常量池中添加常量(比如调用intern方法),否则JVM不会自动添加常量到常量池。
3 内存分配机制
内存分配,主要指的是在
堆
上的分配,
一般的,对象的内存分配都是在堆上进行,但现代技术也支持将对象拆成标量类型(标量类型即原子类型,表示单个值,可以是基本类型或String等),然后在栈上分配,在栈上分配的很少见,我们这里不考虑。
Java内存分配和回收的机制
概括的说,就是:
分代分配,分代回收
。
对象将根据存活的时间被分为:年轻代(Young Generation)、年老代(Old Generation)、永久代(Permanent Generation,也就是方法区)。
年轻代(
Young Generation
)
:对象被创建时,内存的分配首先发生在年轻代(大对象可以直接 被创建在年老代),大部分的对象在创建后很快就不再使用,因此很快变得不可达,于是被年轻代的GC机制清理掉(IBM的研究表明,98%的对象都是很快消 亡的),这个GC机制被称为Minor GC或叫Young GC。注意,Minor GC并不代表年轻代内存不足,它事实上只表示在Eden区上的GC。
年轻代上的内存分配是这样的,年轻代可以分为3个区域:Eden区(伊甸园,亚当和夏娃偷吃禁果生娃娃的地方,用来表示内存首次分配的区域,再 贴切不过)和两个存活区(Survivor 0 、Survivor 1)。
- 绝大多数刚创建的对象会被分配在Eden区,其中的大多数对象很快就会消亡。Eden区是连续的内存空间,因此在其上分配内存极快;
- 当Eden区满的时候,执行Minor GC,将消亡的对象清理掉,并将剩余的对象复制到一个存活区Survivor0(此时,Survivor1是空白的,两个Survivor总有一个是空白的);
- 此后,每次Eden区满了,就执行一次Minor GC,并将剩余的对象都添加到Survivor0;
- 当Survivor0也满的时候,将其中仍然活着的对象直接复制到Survivor1,以后Eden区执行Minor GC后,就将剩余的对象添加Survivor1(此时,Survivor0是空白的)。
- 当两个存活区切换了几次(HotSpot虚拟机默认15次,用-XX:MaxTenuringThreshold控制,大于该值进入老年代)之后,仍然存活的对象(其实只有一小部分,比如,我们自己定义的对象),将被复制到老年代。
从上面的过程可以看出,Eden区是连续的空间,且Survivor总有一个为空。经过一次GC和复制,一个Survivor中保存着当前还活 着的对象,而Eden区和另一个Survivor区的内容都不再需要了,可以直接清空,到下一次GC时,两个Survivor的角色再互换。因此,这种方 式分配内存和清理内存的效率都极高,这种垃圾回收的方式就是著名的
“停止-复制(Stop-and-copy)”清理法(将Eden区和一个Survivor中仍然存活的对象拷贝到另一个Survivor中)
,这不代表着停止复制清理法很高效,其实,它也只在这种情况下高效,如果在老年代采用停止复制,则挺悲剧的。
在Eden区,HotSpot虚拟机使用了两种技术来加快内存分配。分别是bump-the-pointer和TLAB(Thread- Local Allocation Buffers),这两种技术的做法分别是:由于Eden区是连续的,因此bump-the-pointer技术的核心就是跟踪最后创建的一个对象,在对 象创建时,只需要检查最后一个对象后面是否有足够的内存即可,从而大大加快内存分配速度;而对于TLAB技术是对于多线程而言的,将Eden区分为若干 段,每个线程使用独立的一段,避免相互影响。TLAB结合bump-the-pointer技术,将保证每个线程都使用Eden区的一段,并快速的分配内 存。
年老代(Old Generation)
:对象如果在年轻代存活了足够长的时间而没有被清理掉(即在几次 Young GC后存活了下来),则会被复制到年老代,年老代的空间一般比年轻代大,能存放更多的对象,在年老代上发生的GC次数也比年轻代少。当年老代内存不足时, 将执行Major GC,也叫 Full GC。
可以使用-XX:+UseAdaptiveSizePolicy开关来控制是否采用动态控制策略,如果动态控制,则动态调整Java堆中各个区域的大小以及进入老年代的年龄。
如果对象比较大(比如长字符串或大数组),Young空间不足,则大对象会直接分配到老年代上(大对象可能触发提前GC,应少用,更应避免使用短命的大对象)。用-XX:PretenureSizeThreshold来控制直接升入老年代的对象大小,大于这个值的对象会直接分配在老年代上。
可能存在年老代对象引用新生代对象的情况,如果需要执行Young GC,则可能需要查询整个老年代以确定是否可以清理回收,这显然是低效的。解决的方法是,年老代中维护一个512 byte的块——”card table“,所有老年代对象引用新生代对象的记录都记录在这里。Young GC时,只要查这里即可,不用再去查全部老年代,因此性能大大提高。
4 内存调用示意图
1.
一个Java文件,只要有main入口方法,我们就认为这是一个Java程序,可以单独编译运行。
2.
无论是普通类型的变量还是引用类型的变量(俗称实例),都可以作为局部变量,他们都可以出现在栈中。只不过普通类型的变量在栈中直接保存它所对应的值,而引用类型的变量保存的是一个指向堆区的指针,通过这个指针,就可以找到这个实例在堆区对应的对象。因此,普通类型变量只在栈区占用一块内存,而引用类型变量要在栈区和堆区各占一块内存。
示例:
1.
JVM自动寻找main方法,执行第一句代码,创建一个Test类的实例,在栈中分配一块内存,存放一个指向堆区对象的指针110925。
2.
创建一个int型的变量date,由于是基本类型,直接在栈中存放date对应的值9。
3.
创建两个BirthDate类的实例d1、d2,在栈中分别存放了对应的指针指向各自的对象。他们在实例化时调用了有参数的构造方法,因此对象中有自定义初始值。
调用test对象的change1方法,并且以date为参数。JVM读到这段代码时,检测到i是局部变量,因此会把i放在栈中,并且把date的值赋给i。
把1234赋给i。很简单的一步。
change1方法执行完毕,立即释放局部变量i所占用的栈空间。
调用test对象的change2方法,以实例d1为参数。JVM检测到change2方法中的b参数为局部变量,立即加入到栈中,由于是引用类型的变量,所以b中保存的是d1中的指针,此时b和d1指向同一个堆中的对象。在b和d1之间传递是指针。
change2方法中又实例化了一个BirthDate对象,并且赋给b。在内部执行过程是:在堆区new了一个对象,并且把该对象的指针保存在栈中的b对应空间,此时实例b不再指向实例d1所指向的对象,但是实例d1所指向的对象并无变化,这样无法对d1造成任何影响。
change2方法执行完毕,立即释放局部引用变量b所占的栈空间,注意只是释放了栈空间,堆空间要等待自动回收。
调用test实例的change3方法,以实例d2为参数。同理,JVM会在栈中为局部引用变量b分配空间,并且把d2中的指针存放在b中,此时d2和b指向同一个对象。再调用实例b的setDay方法,其实就是调用d2指向的对象的setDay方法。
调用实例b的setDay方法会影响d2,因为二者指向的是同一个对象。
change3方法执行完毕,立即释放局部引用变量b。
change3方法执行完毕,立即释放局部引用变量b。
以上就是Java程序运行时内存分配的大致情况。其实也没什么,掌握了思想就很简单了。无非就是两种类型的变量:基本类型和引用类型。二者作为局部变量,都放在栈中,基本类型直接在栈中保存值,引用类型只保存一个指向堆区的指针,真正的对象在堆里。作为参数时基本类型就直接传值,引用类型传指针。
小结:
1.
分清什么是实例什么是对象。Class a= new Class();此时a叫实例,而不能说a是对象。实例在栈中,对象在堆中,操作实例实际上是通过实例的指针间接操作对象。多个实例可以指向同一个对象。
2.
栈中的数据和堆中的数据销毁并不是同步的。方法一旦结束,栈中的局部变量立即销毁,但是堆中对象不一定销毁。因为可能有其他变量也指向了这个对象,直到栈中没有变量指向堆中的对象时,它才销毁,而且还不是马上销毁,要等垃圾回收扫描时才可以被销毁。
3.
以上的栈、堆、代码段、数据段等等都是相对于应用程序而言的。每一个应用程序都对应唯一的一个JVM实例,每一个JVM实例都有自己的内存区域,互不影响。并且这些内存区域是所有线程共享的。这里提到的栈和堆都是整体上的概念,这些堆栈还可以细分。
4.
类的成员变量在不同对象中各不相同,都有自己的存储空间(成员变量在堆中的对象中)。而类的方法却是该类的所有对象共享的,只有一套,对象使用方法的时候方法才被压入栈,方法不使用则不占用内存。
5 运行实例
实例1
在计算机内存中主要来自四个地方:heap segment(堆区)、stack segment(栈区)、codesegment(代码区)、data segment(数据区);不同的地方存放不同数据:其中堆区主要存放Java程序运行时创建的所有引用类型都放在其中;栈区主要存放Java程序运行时所需的局部变量、方法的参数、对象的引用以及中间运算结果等数据;代码区主要存放Java的代码;数据区主要存放静态变量及全局变量;以下结合实例来探讨其具体机制。
class Student {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
}
public class Test {
static int i = 10;
public static void main(String[] args) {
Student s1 = new Student(“feng”, 21);
}
}当该程序运行起来后,其计算机内存分布大致如下:
对象在内部表示Java虚拟机规范并没有规定其在堆中是如何表示的。对象的内部的表示会直接影响到堆区的设计以及垃圾收集器(GC)的设计。
实例2
class Demo1_Car{
public static void main(String[] args) {
Car c1 = new Car();
//调用属性并赋值
c1.color = "red";
c1.num = 8;
//调用行为
c1.run();
Car c2 = new Car();
c2.color = "black";
c2.num = 4;
c2.run();
}
}
Class Car{
String color;
int num;
public void run() {
System.out.println(color + ".." + num);
}
}
-
首先运行程序,
Demo1_car.java
就会变为
Demo1_car.class
,
Demo1_car.class
加入方法区,检查是否字节码文件常量池中是否有常量值,如果有,那么就加入运行时常量池。 - 遇到main方法,创建一个栈帧,入虚拟机栈,然后开始运行main方法中的程序。
-
Car c1 = new Car()
, 第一次遇到Car这个类,所以将
Car.java
编译为
Car.class
文件,然后加入方法区.然后
new Car()
,在堆中创建一块区域,用于存放创建出来的实例对象,地址为
0X001
.其中有两个属性值
color
和
num
。默认值是
null
和 0 -
然后通过
c1
这个引用变量去设置
color
和
num
的值,调用
run
方法,然后会创建一个栈帧,用来存储run方法中的局部变量等。run 方法中就打印了一句话,结束之后,该栈帧出虚拟机栈。又只剩下main方法这个栈帧。 - 接着又创建了一个Car对象,所以又在堆中开辟了一块内存,之后就是跟之前的步骤一样了。
实例 3
一个对象的运行过程:
-
程序从 main 方法中进入;运行到 Phone p 时,在栈中开辟了一个空间;
-
new Phone() 时,在队中开了一个内存空间,此时会有一个内存值为 0x0001;此时会找到对应的 Phone 的 class 文件,发现有三个变量和三个方法,于是将三个成员变量放在了堆中,但是此时的值为默认值(具体默认值见上)。注意,在方法区里也有一个地址值,假设为 0x001,可以认为在堆中也有一个位置,在堆中的位置,可以找到方法区中相对应的方法;
-
继续运行,p.brand = “三星”;将三星赋值给 p.brand,通过栈中的 p 找到了堆中的 brand,此时的 null 值变为“三星”。剩下的类似;
-
当运行到 p.call(“乔布斯”) 时,通过栈中的 p 找到堆中存在的方法区的内存地址,从而指引到方法区中的 Phone.class 中的方法。从而将 call 方法加载到栈内存中,注意:当执行完毕后,call 方法就从栈内存中消失!剩余的如上。
-
最后,main 方法消失!
两个对象的运行过程:
-
程序从 main() 方法进入,运行到 Phone p 时,栈内存中开内存空间;
-
new Phone() 时,在队中开了一个内存空间,内存值为 0x0001;此时会找到对应的 Phone 类,发现有三个变量,于是将三个成员变量放在了堆中,但是此时的值为默认值。又发现该类还存在方法,于是将该方法的内存值留在了堆中,在方法区里也有一个地址值,假设为 0x001,这个值与堆中的值相对应;
-
程序继续运行,到 p.brand 时,进行了负值,同上;
-
当程序运行到 Phone p2 时;到 new Phone() 时,在堆内存中开辟了内存空间 0x0002,赋值给 Phone p2;
-
剩下跟一个对象的内存相同。
三个对象的运行过程:
-
基本流程跟前两个无差别;
-
但是当运行到 Phone p3 时,在栈内存中分配了一个空间,然后将 p1 的内存赋值给了 p3,即此时 Phone p3 的内存是指向 0x0001 的;
-
继续给变量赋值,会将原来已经赋值的变量给替换掉。
实例 4
每当我们创建一个新的对象时,Java都会给该对象分配一个地址;对象本身存储在堆中,而该对象的引用存储在栈中。
来个简单的例子:
我们创建一个类:
public class Student {
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}在主方法中创建该类的对象:
public class StackAndHeap {
public static void main(String[] args){
Student student = new Student();
Student student1 = new Student();
System.out.println(student==student1);
}
}打印结果:false
画图分析:
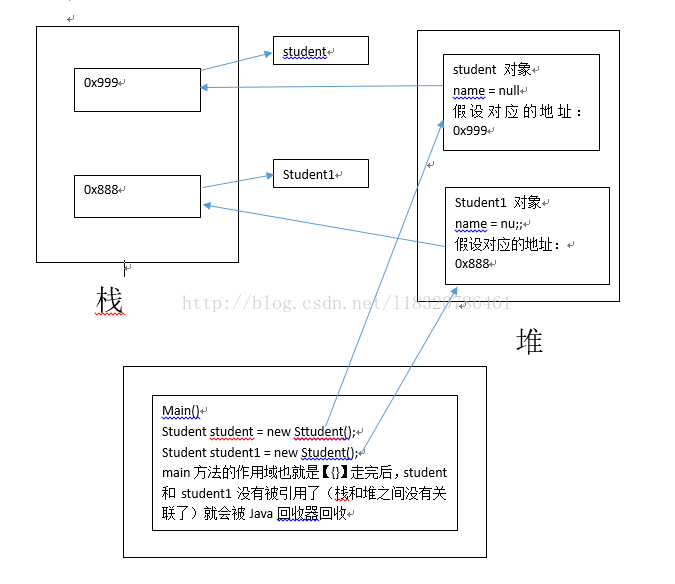
其实我们每次调用student或者student1时都会先从栈中找得到对应的内存地址,然后根据内存地址在堆中找到对应的对象,再对对象进行操作。对象不再被引用时,堆指向栈的那条线也就断开了,栈中的对象引用也会退出栈。
2、静态变量
静态变量是在.class文件被加载到jvm的时候就被加载到内存中的,它是这个类的共享数据,随着jvm消失其所占的内存才会释放。
比如我们常说的线程同步问题:卖票。假设我们不用Runnable(数据共享)实现线程,而是创建Thread类的话,那么我们的票的数量这个属性就必须要设为静态的,防止抢票意外的话同步锁也要设置为静态的。
在我们一般给方法设为静态时,较多的用在工具类上。
3、基本类型和常量池
基本类型分为:整数(byte【1字节】、short【2字节】、int【4字节】、long【8字节】)、小数(double【8字节】、float【4字节】)、字符、布尔。
Java为了提高性能提供了和String类一样的对象池机制,当然Java的八种基本类型的包装类(Packaging Type)也有对象池机制。
我们先来看个例子:
public static void main(String[] args){
int q=10;
int w = 10;
int e = 0;
Integer a = 10;
Integer s = 10;
Integer d = 0;
Integer z = new Integer(10);
System.out.println("q=w? "+(q==w));
System.out.println("q=a? "+(q==a));
System.out.println("a=s? "+(a==s));
System.out.println("q=w+e? "+(q==w+e));
System.out.println("a=s+d? "+(a==s+d));
System.out.println("a=z? "+(a==z));
System.out.println("a=z+e? "+(a==z+e));
}
输出结构:
q=w? true
q=a? true
a=s? true
q=w+e? true
a=s+d? true
a=z? false
a=z+e? true结果分析:
q和w普通类型变量,他们存储在栈中,而栈有一个很重要的特性:栈中的数据可以共享。当q=10时,会在栈中寻找是否有10,有的话就直接把10指向q,没有的话就生成一个内存里面的值为10,再把10指向q;当w=10时也会做同样的操作,所以他们2个的地址相等。
q和a对比:q==a对比时Integer会自动拆箱,把a转为int和q对比(intvalue());a==q对比时会把装箱成Integer(valueof())。
a=z+e,这里也是对z+e进行了拆箱处理,然后和a进行比较。
注意:new Integer()底层的常量池大小为-128-127,超出这个范围的话Integer i = 400和 Integer j = 400,这里的i和j不相等,因为超出-128-127的话回去调用new Integer()产生出来的对象地址不相等。