hive的列转行&行转列&拼接函数
列转行(一列转多行)
常用的列转行函数有:
lateral view explode(array或map类型的字段) tableAlias AS columnAlias
可以理解为,一个select子句只能获得一个explode产生的视图,但是炸裂后的返回视图无法与其它字段一同输出,如果想要显示多个列,就需要将多个视图合并,lateral view 侧视图就解决了这个问题。首先通过explode函数将array或map类型的字段炸裂为多行,接着将炸裂后的多行数据与原表的每行数据进行一个笛卡尔积的join,将结果形成一个虚拟表,同时可以对udtf炸裂后的字段设置别名
| udtf | 函数说明 | 示例 | 输出 |
|---|---|---|---|
| explode(ARRAY a) | explode函数会将数组中的元素拆分,按行输出每个元素 | select explode(array(‘zs’,‘ls’,‘ww’)) |
col zs ls ww |
| explode(MAP<Tkey,Tvalue> m) | explode函数会将一个map类型字段的键值对拆分成两列输出,键一列,值一列。需要注意的是,该udtf输出的是两列,因此取别名时需要注意别名的数量与列数一致 | select explode(map(‘zs’,99,‘ls’,66)) as (name,score); |
name score zs 99 ls 66 |
| posexplode(ARRAY a) | 将数组炸裂为多行,返回两列,一列为数组中各元素所对应的索引下标(从0开始),一列为对应的元素。起别名时需要注意别名数量 | select posexplode(array(‘zs’,‘ls’,‘ww’)) as (id,stu); |
id stu 0 zs 1 ls 2 ww |
| inline(ARRAY<STRUCT<f1:T1,…,fn:Tn>> a) | 将结构体数组炸裂为多行。返回一个包含 N 列的行集,数组中的每个结构体都对应一行。行数为数组大小即结构体的个数,列数为结构体中元素的个数N | select inline(array(named_struct(‘name’,‘zs’,‘sex’,‘0’,‘age’,58),named_struct(‘name’,‘ls’,‘sex’,‘1’,‘age’,99))); |
name sex age zs 0 58 ls 1 99 |
| stack(int r,T1 V1,…,Tn/r Vn) | 将 n列值 V1,… ,Vn 分解成 r 行。每行有 n/r 列。 r 必须是常数。n必须是r的整数倍 | select stack(3,‘a’,‘1’,‘2’,‘s’,‘3’,‘x’); –将6个字段分解为3行,每行6/3=2个字段 |
col0 col1 a 1 2 s 3 x |
| json_tuple(string jsonStr,string k1,…,string kn) | 从一个JSON字符串中获取n个键的值并作为一个元组返回。该udtf至少需要传入两个参数,第一个参数为JSON字符串,从第二个参数开始为要获取的n个键。比get_json_object更有效便捷,只需要一个调用就可以获得多个键值 | select json_tuple(‘{“name”:“zs”,“sex”:“0”,“age”:18}’,‘name’,‘sex’,‘age’) as (name,sex,age); |
name sex age zs 0 18 |
| parse_url_tuple(string urlStr,string p1,…,string pn) | 解析URL字符串,可以同时提取url的多个部分并以元组的形式返回,所有输入参数和输出列类型都是string。提取部分的有效参数为:HOST, PATH, QUERY, REF, PROTOCOL, AUTHORITY, FILE, USERINFO, QUERY: | select parse_url_tuple(‘https://www.baidu.com/zs?user_id=9999&platform=android’, ‘HOST’, ‘PATH’, ‘PROTOCOL’); |
c0 c1 c2 www.baidu.com /zs https |
语法
:LATERAL VIEW udtf(expression) tableAlias AS columnAlias (‘,’ columnAlias)*
用法
:和UDTF函数一起使用,为原始表的每行数据调用UDTF函数炸裂为多行数据,lateral view 将原始表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表,可以对UDTF产生的记录设置字段名称。
作用
:主要解决在select使用UDTF做查询的过程中查询只能包含单个UDTF,不能包含其它字段以及多个UDTF的情况,可以扩展原来的表数据。UDTF炸裂后的字段可以使用在 GROUP BY 、 CLUSTER BY 、 DISTRIBUTE BY 、 SORT BY 等语句中,无需再嵌套一层子查询。
1、在SELECT子句中不支持UDTF函数和其他字段同时出现,只能获得一个udtf产生的视图。
如explode函数炸裂后的返回视图无法与其它字段一同输出,只能单独使用explode炸裂后的返回视图。select 'zs' as uid, explode(array('chinese','math','english')) as info; Error: Error while compiling statement: FAILED: SemanticException [Error 10081]: UDTFs are not supported outside the SELECT clause, nor nested in expressions (state=42000,code=10081)解决:
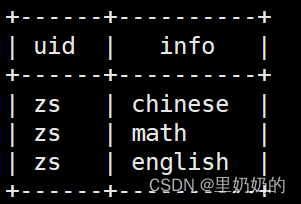
如果希望得到UDTF和其他字段的结果,需要结合lateral view使用
select uid,info from (select 'zs' as uid) a lateral view explode(array('chinese','math','english')) tb as info;
2、在SELECT子句中只支持单个UDTF表达式,无法同时使用多个UDTF函数
select explode(array(1,2,3)) as id, explode(array('zs','ls','ww')) as name ; Error: Error while compiling statement: FAILED: SemanticException 1:35 Only a single expression in the SELECT clause is supported with UDTFs. Error encountered near token 'name' (state=42000,code=40000)解决:
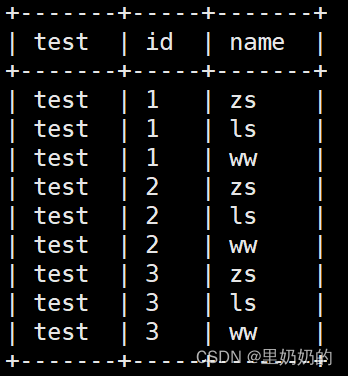
结合lateral view使用,可以同时使用多个UDTF函数
select test,id,name from (select 'test' as test) a lateral view explode(array(1,2,3)) t1 as id lateral view explode(array('zs','ls','ww')) t2 as name ;
3、不支持UDTF函数间的嵌套
select explode(explode(array(array(66,666),array(88,888),array(99,999)))) Error: Error while compiling statement: FAILED: SemanticException [Error 10081]: UDTFs are not supported outside the SELECT clause, nor nested in expressions (state=42000,code=10081)解决:
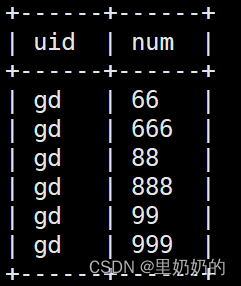
UDTF函数间不支持嵌套,结合lateral view逐层嵌套子查询
select uid,num from ( select uid,nums from (select 'gd' as uid)a lateral view explode(array(array(66,666),array(88,888),array(99,999))) t as nums )b lateral view explode(nums) t as num
4、在SELECT子句中UDTF不支持GROUP BY / CLUSTER BY / DISTRIBUTE BY / SORT BY语句
select explode(uinfo) as (name,info) from ( select 8 as class, map('zs',66,'ls',99,'ww',55) as uinfo union all select 2 as class, map('gd',888,'eg',77,'xq',66) as uinfo ) a sort by class Error: Error while compiling statement: FAILED: SemanticException [Error 10078]: SORT BY is not supported with a UDTF in the SELECT clause (state=42000,code=10078)解决:
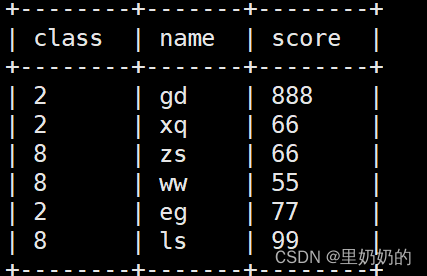
结合lateral view使用,UDTF炸裂后的字段可以使用在 GROUP BY 、 CLUSTER BY 、 DISTRIBUTE BY 、 SORT BY 等语句中,无需再嵌套一层子查询。
select class,name,score from ( select 8 as class, map('zs',66,'ls',99,'ww',55) as uinfo union all select 2 as class, map('gd',888,'eg',77,'xq',66) as uinfo ) a lateral view explode(uinfo) t as name,score sort by class
行转列(多行转一行)
将某列中的多行数据合并为一行,常用的行转列函数主要有:
collect_list()
与
collect_set()
。两者主要的区别是是否去重,通常结合group by使用,返回值都是array类型
collect_list()函数不去重
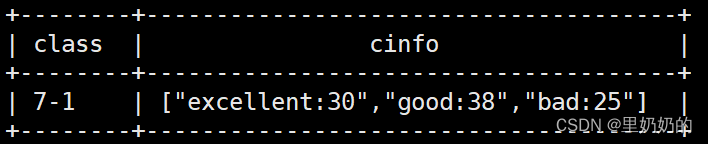
select class, collect_list(concat_ws(':',type,p_num)) cinfo from ( select '7-1' as class, 'excellent' as type, '30' as p_num union all select '7-1' as class, 'excellent' as type, '30' as p_num union all select '7-1' as class, 'good' as type, '38' as p_num union all select '7-1' as class, 'bad' as type, '25' as p_num )a group by class;

collect_set()函数去重
set集合是无序的,可以结合sort_array()函数进行排序select class, collect_set(concat_ws(':',type,p_num)) cinfo --sort_array(collect_set(concat_ws(':',type,p_num))) cinfo from ( select '7-1' as class, 'excellent' as type, '30' as p_num union all select '7-1' as class, 'excellent' as type, '30' as p_num union all select '7-1' as class, 'good' as type, '38' as p_num union all select '7-1' as class, 'bad' as type, '25' as p_num )a group by class;
拼接函数
常用的拼接函数有
concat()
、
concat_ws
常用于对表中的多列数据进行拼接处理合并,或对一列数据进行处理转换
concat()函数
可以输入任意个参数,主要可以用作字段间的拼接。返回类型为字符串。
concat函数
会跳过空字符串
, 但是需要注意的是,该函数
不会跳过null值
,也就是说,拼接时只要其中有
一个参数为null,则返回结果就为NULL
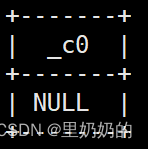
以下sql为例:select concat('a','-',null,'b'); --返回结果为null,因为该函数不会跳过null值
正常情况的拼接:select concat('a','-','','b'); --返回结果为 a-b,因为在拼接时会跳过空字符串

concat_ws(‘分割符’,str1,str2…)
- 可以理解为是特殊类型的concat函数,
第一个参数为参数间的分隔符
,之后的是带拼接的参数,将各个字符串通过一个指定的分隔符进行拼接。- 若分隔符为null,返回结果也将为NULL。但是该函数会跳过除分隔符外的所有NULL以及空字符串参数,不进行拼接。
- 在hive中,concat_ws()函数只接受string 或 array<string>类型的参数。
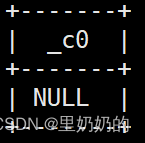
当分隔符为null时,返回结果为null
select concat_ws(null,'a','b'); --返回结果为 null,因为分隔符为null,因此返回结果为null
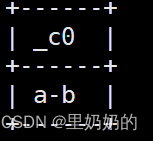
参数中有null时,会跳过null值
select concat_ws('-','a',null,'b',null); --返回结果为 a-b,不同于concat函数,会跳过除分隔符外的null值
拼接array<String>类型时,会对数组中的元素逐个拼接
select concat_ws('&',array('1','2'),'a'); --返回结果为 1&2&a,会对数组中的元素逐个拼接
