个人理解: a(bean) 实例化的时候去缓存(一级->二级-> 三级)中找,没有就将工厂bean放到三级缓存,实例化完成后放到二级缓存同时删掉三级缓存中的a,然后赋值属性初始化,如果没有循环依赖初始化完成,便删除二级缓存中的半成品,将完整对象当到一级缓存(单例池中),完成初始化
bean的声明周期
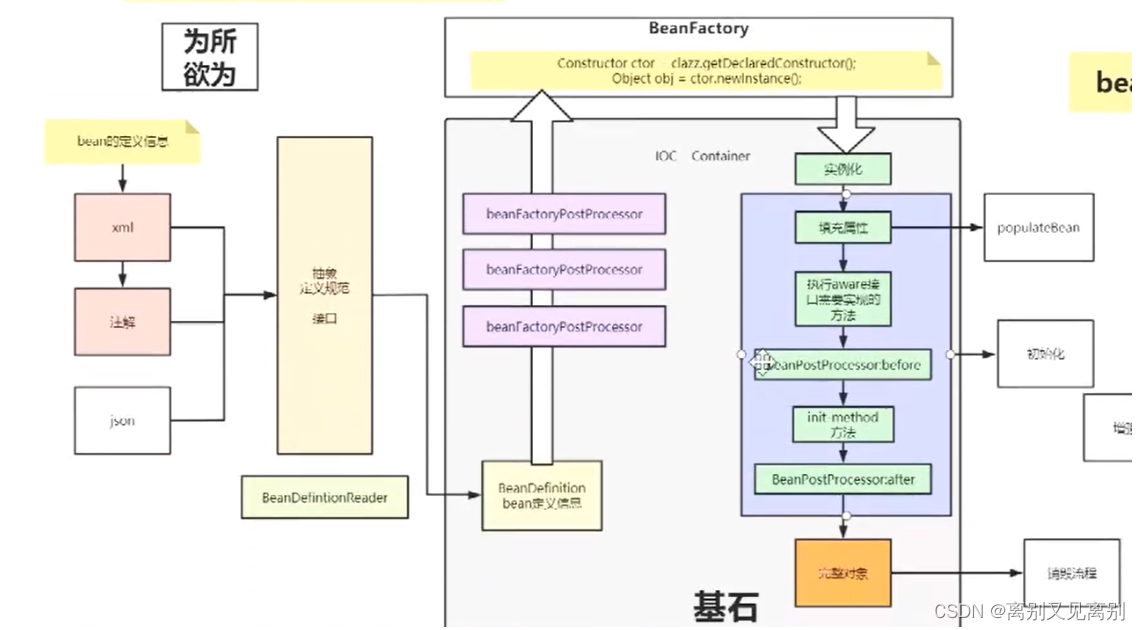
-
beanDefintionReader: 配置读取
-
BeanDefintionBean: 配置的解析
-
beanFactorypostProcessor: bean的扩展方法(实例化前执行,操作元数据)
…(此期间便是实例化过程)
-
populateBean: 填充Bean的属性
-
aware:执行实现了此接口的方法
-
Beanpostprocessor:before:bean的前置增强
-
int method: 初始化里面的方法
-
BeanPostProcessor:after: bean的后置增强
bean的循环依赖
属性的初始化基本上使用的是两种,一种set,,一种构造函数,所以spring中循环依赖问题set方式初始化时可以解决的,构造函数解决不了.
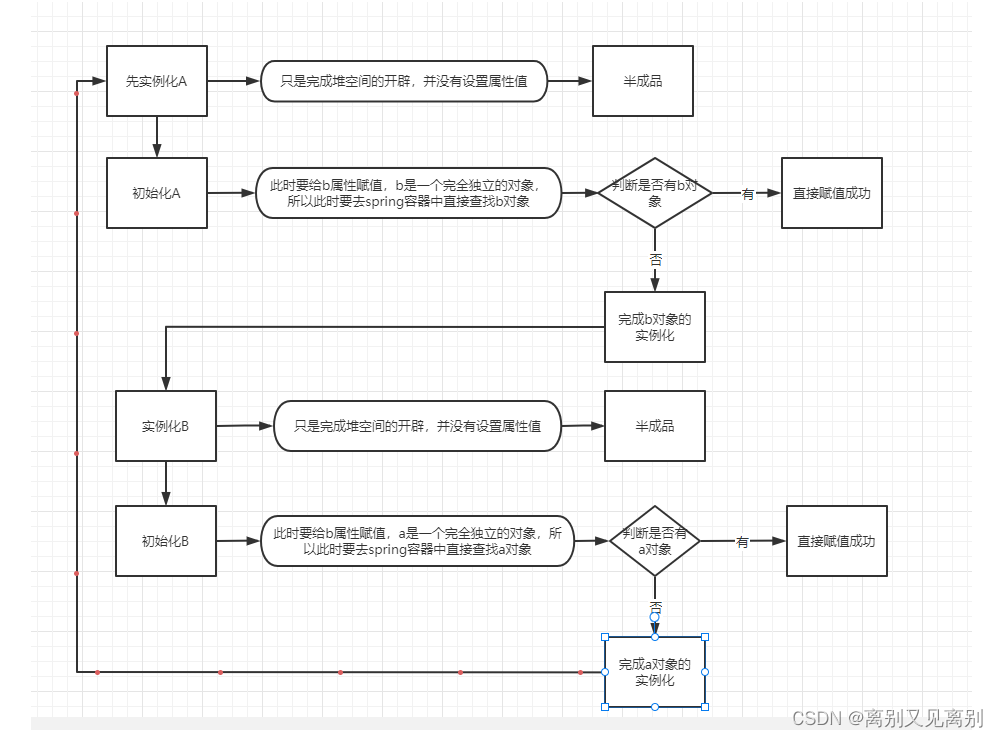
解决方式
将半成品(也可以说是获取半成品bean的方法或工厂对象)放到三级缓存中(二级缓存存放的是属性没有赋值的bean,这次才是真正的半成品,一级缓存存放的成品bean,专有名词是单例池),ioc(包含单例池)没有就去二三级缓存中找
1.三级缓存(专有名词:对象提前暴露):
- singletonObjects:一级缓存
- earlySingletonObjects: 二级缓存
-
singletonFactories: 三级缓存
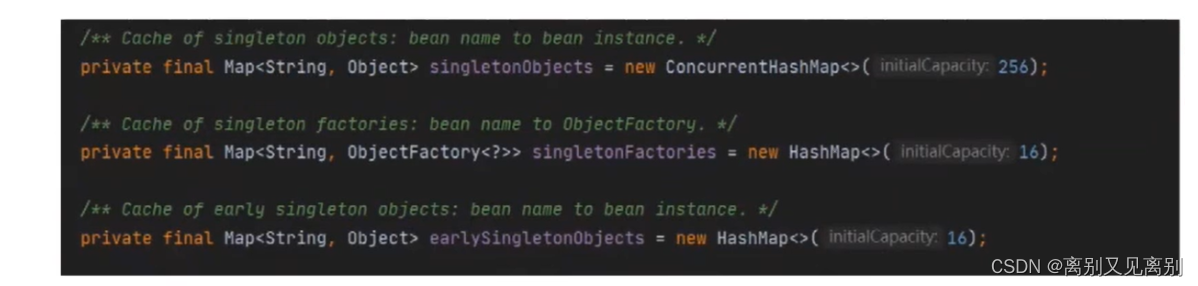
中ObjectFactory是一个函数式接口,仅有一个方法,可以传入lambda表达式,,可以是匿名内部类,通过调用getObject方法来执行具体的逻辑
执行流程
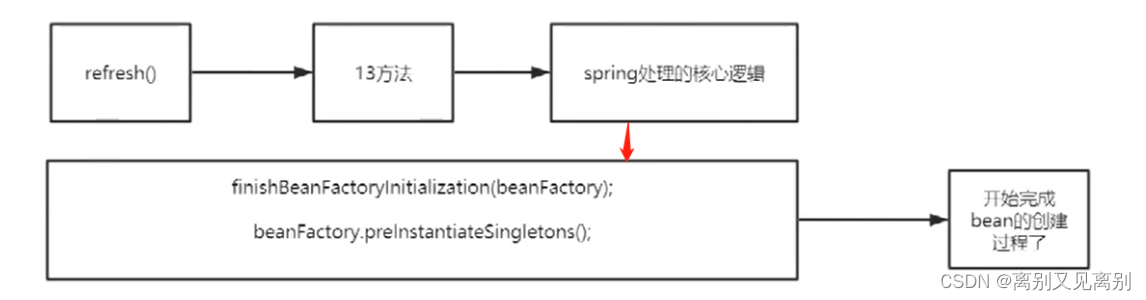
1.配置文件的bean被加载但是还没有实例化
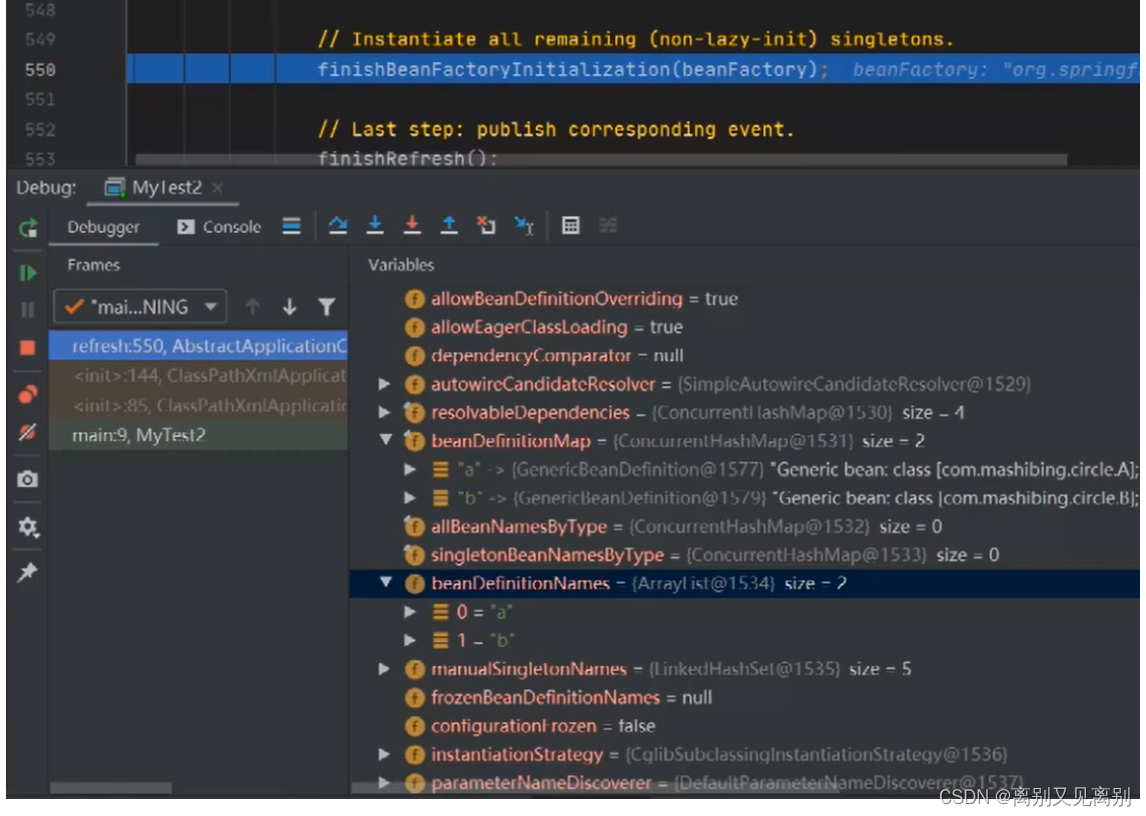
2.会先实例化a
-
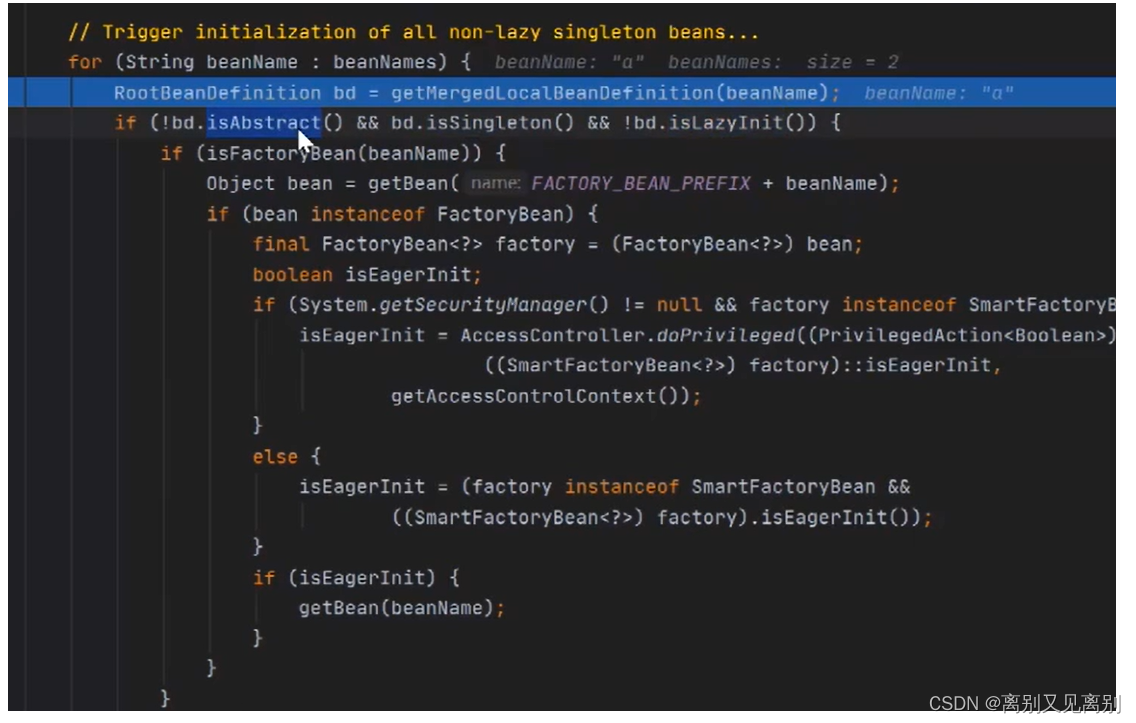
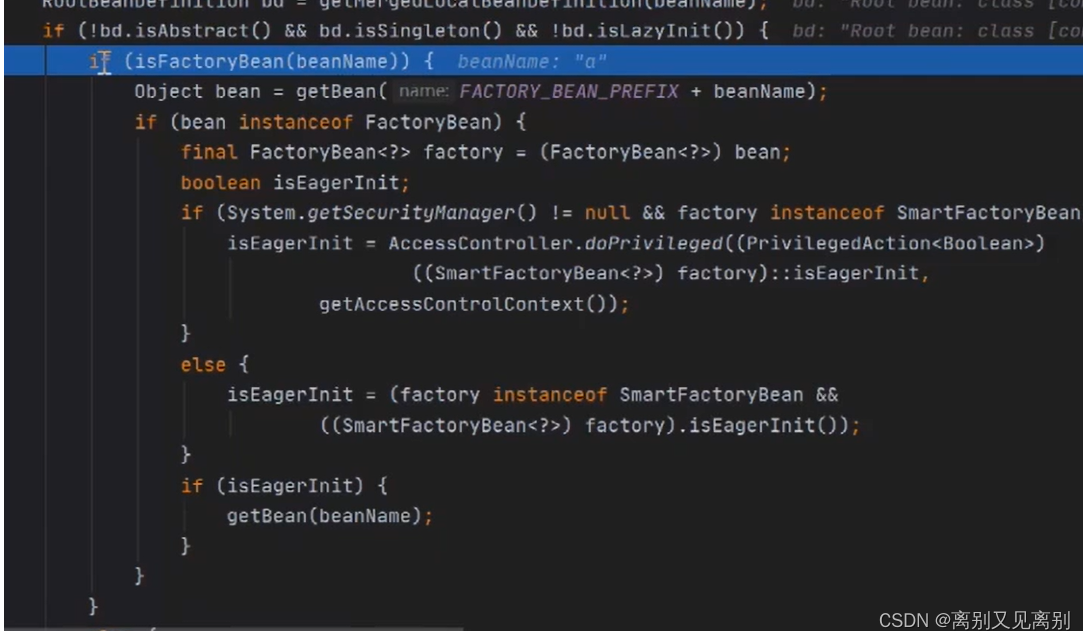
bd.isAbstract: 是否是抽象的 false
-
bd.isSingleton():是否是单例的 true
-
bd.isLazyInit(): 是否是懒加载 false
2.1 进一步执行
2.2.执行getBean() –> doGetBean()
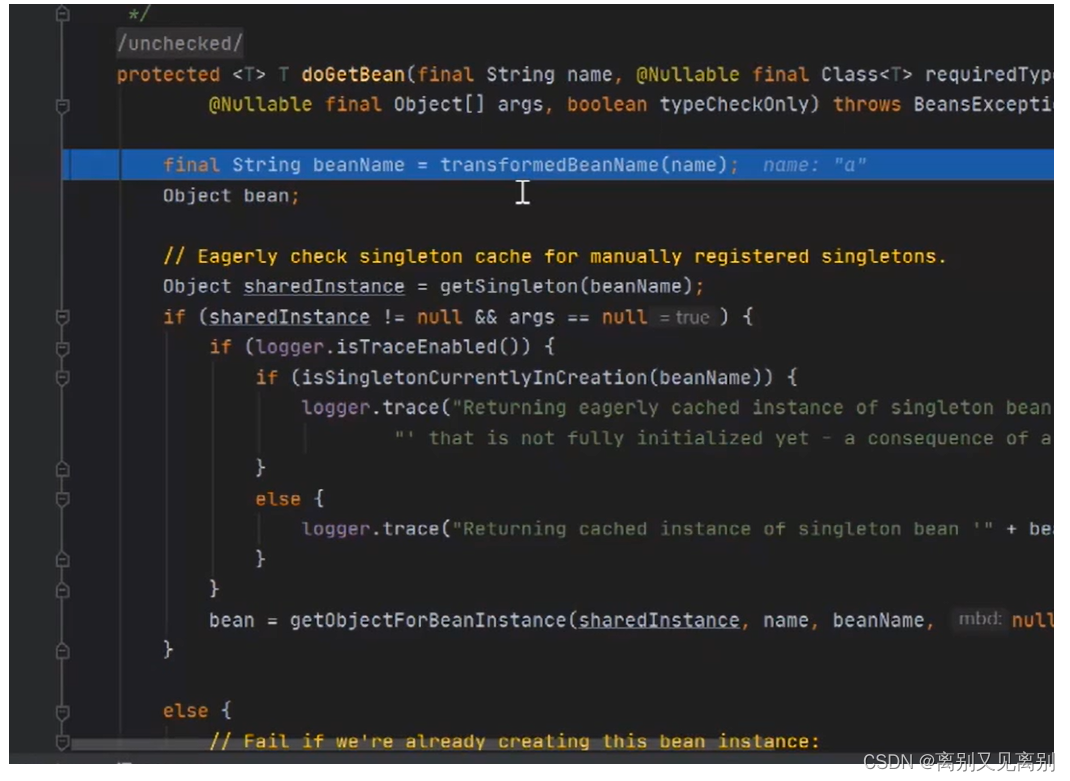
2.3.getSingleton() 去容器中查找
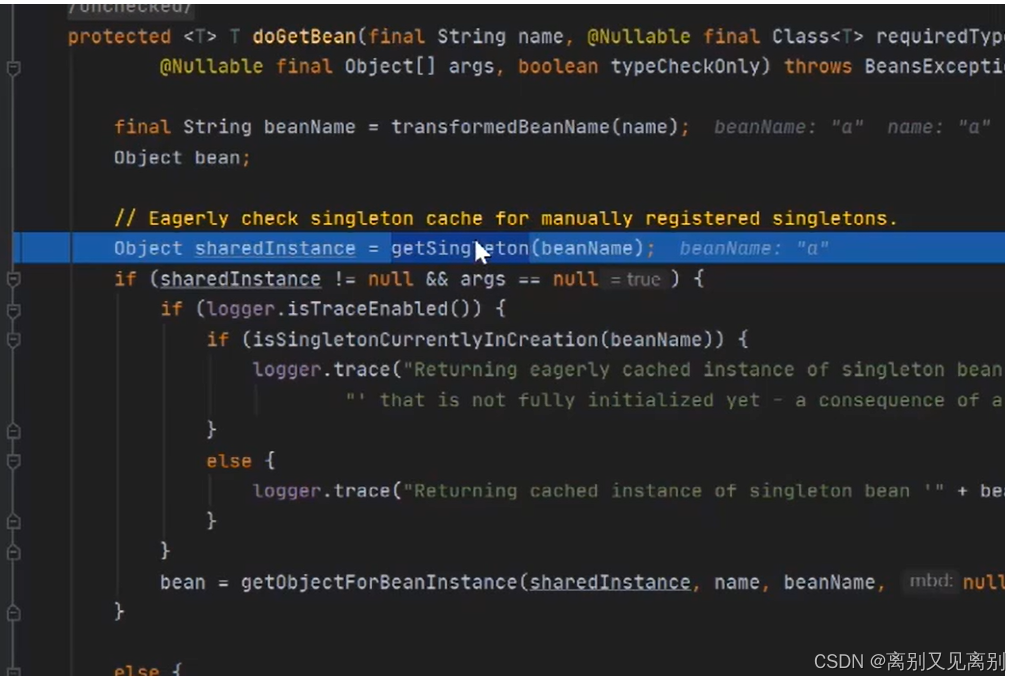
2.3.1.调用里面的this.singletonObjects.get(beanName) [ 一级缓存 ]
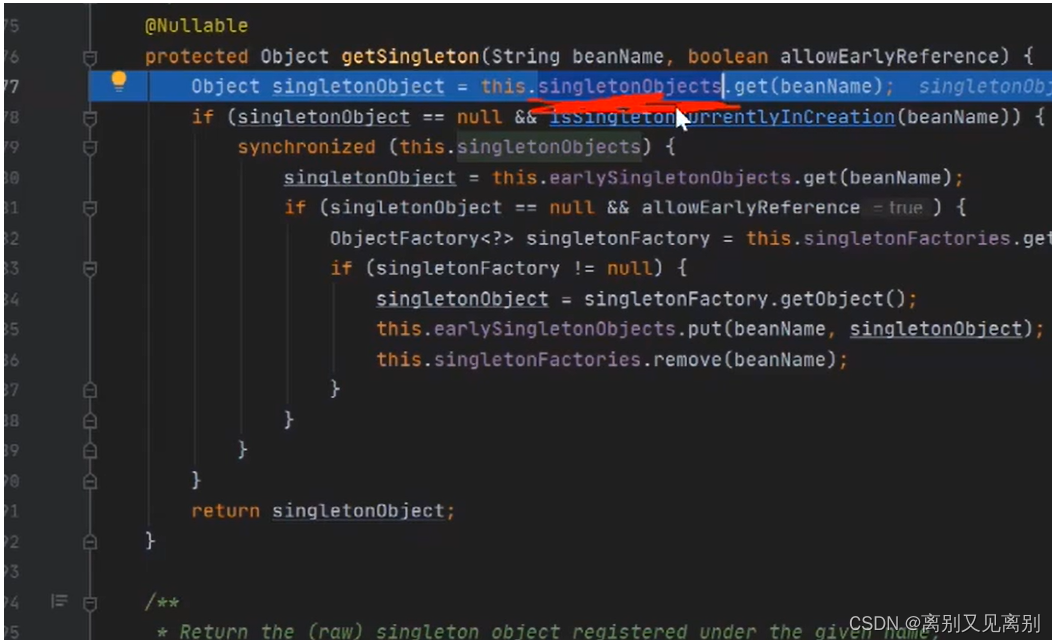
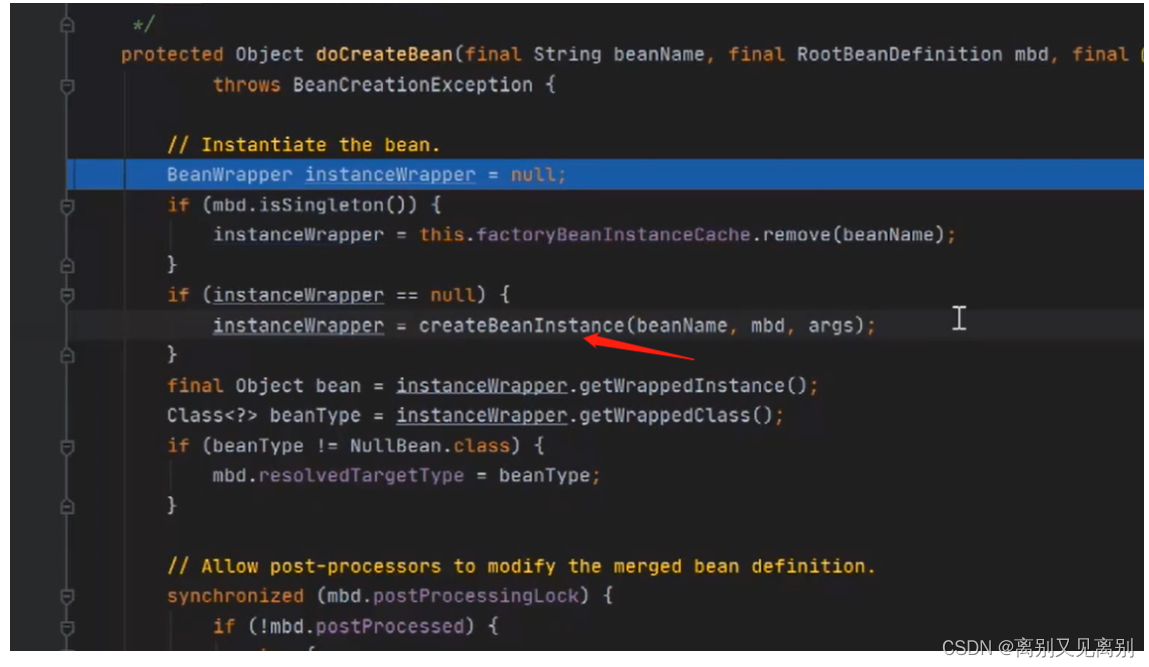
2.4.刚开始一级缓存中是找不到的,因为还没有被创建,所以要调用后面的createBean() -> doCreateBean() 方法
此处的creatBean(),便是执行的(
需要存到三级缓存中的objectFunction中的getObject
)中的getObject
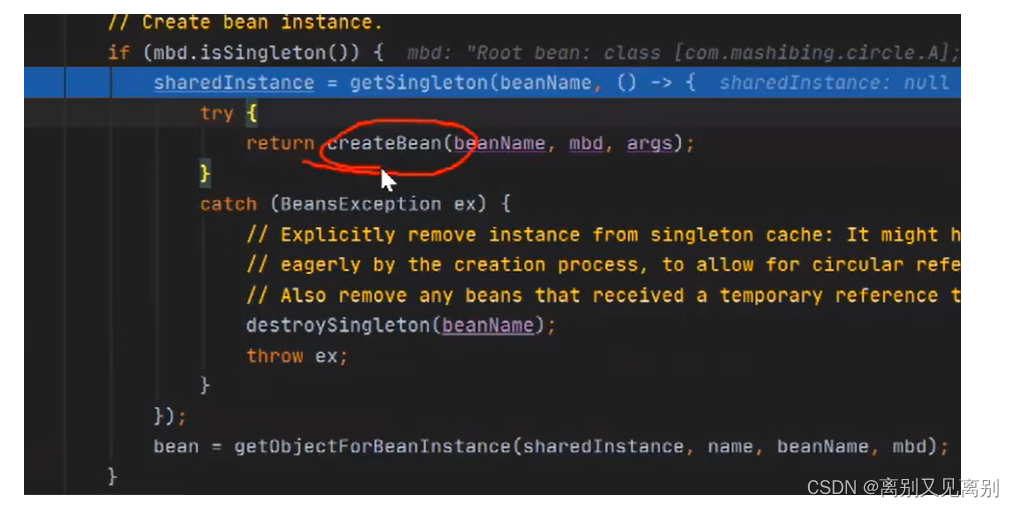
2.5执行singletonFactory.getObject()方法**
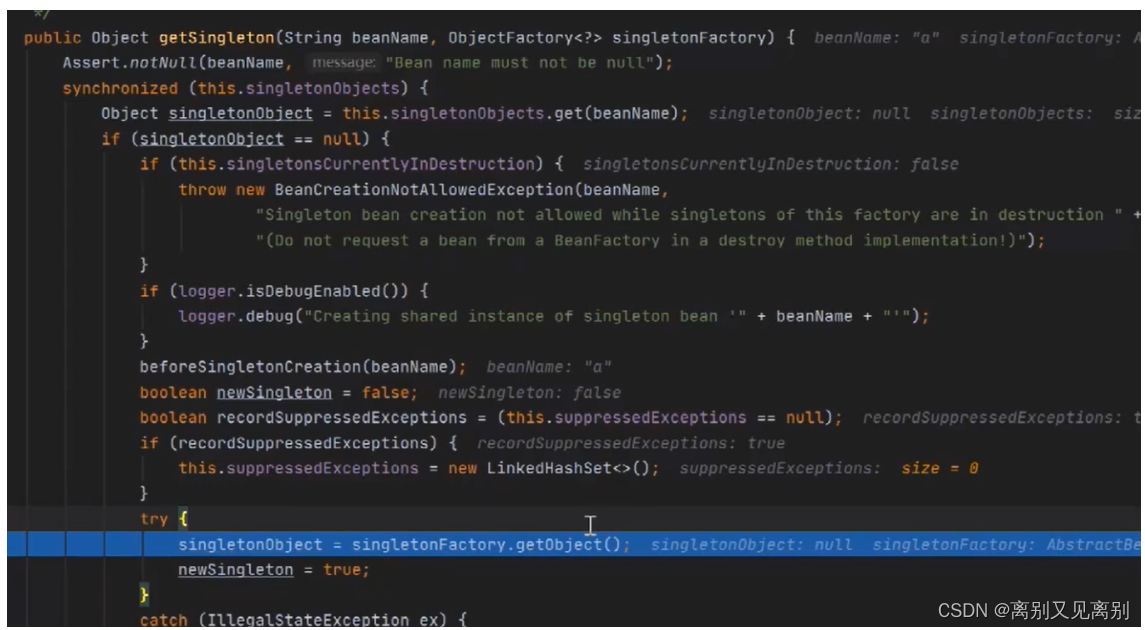
2.5.1执行creatBean()
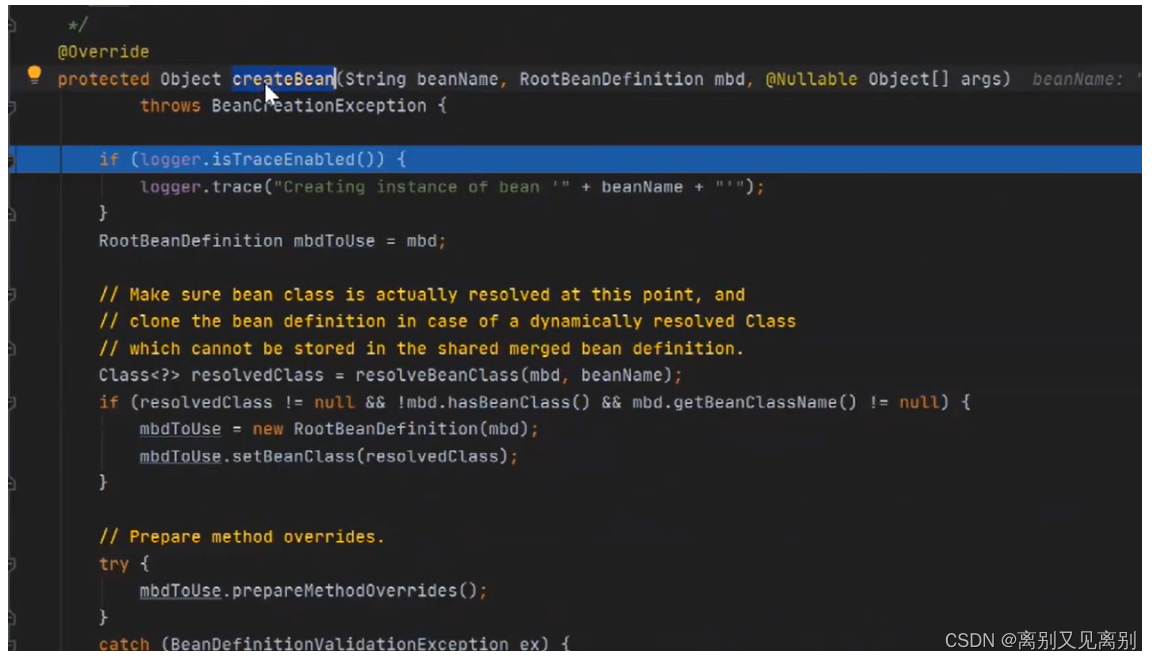
2.5.2完成bean的实例化(反射)
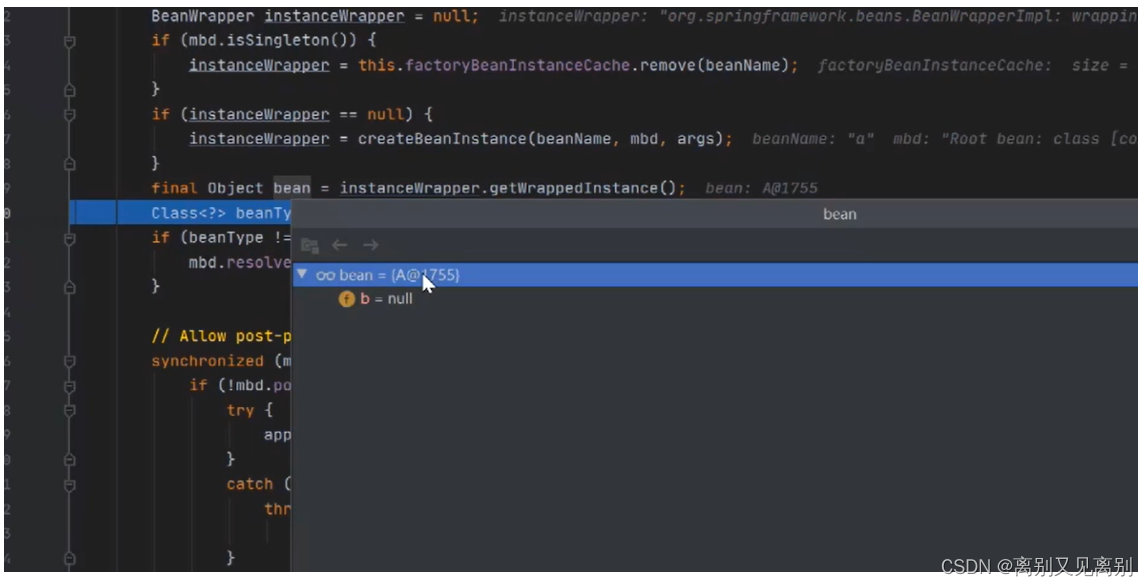
2.5.3完成A的实例化,但是b还没有赋值,是个半成品
2.5.4此方法beanName 此时传的是a,但是函数不会执行,只有调用get时才会执行
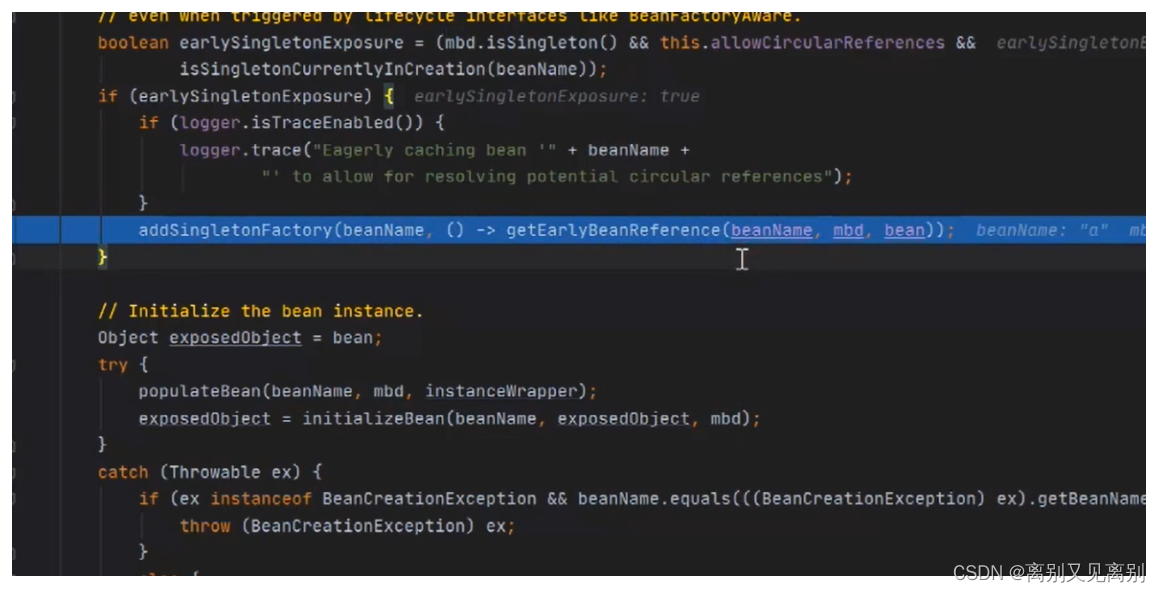
2.5.5查看一级缓冲是否有a,没有就像三级缓存中放入a,
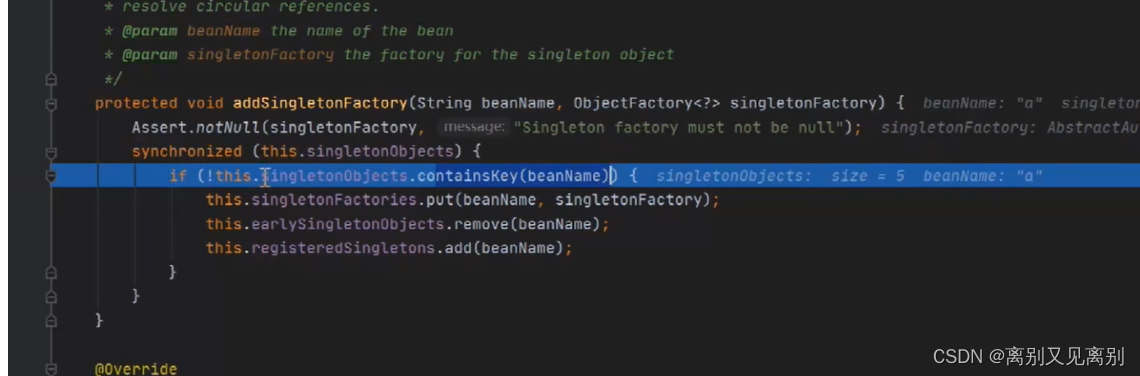
其中beanName是此时的bean名称a,singletonFactory便是上一步传过来的函数
三级缓存中的数据格式: k:a,v:lambda 表达式
2.5.6填充属性
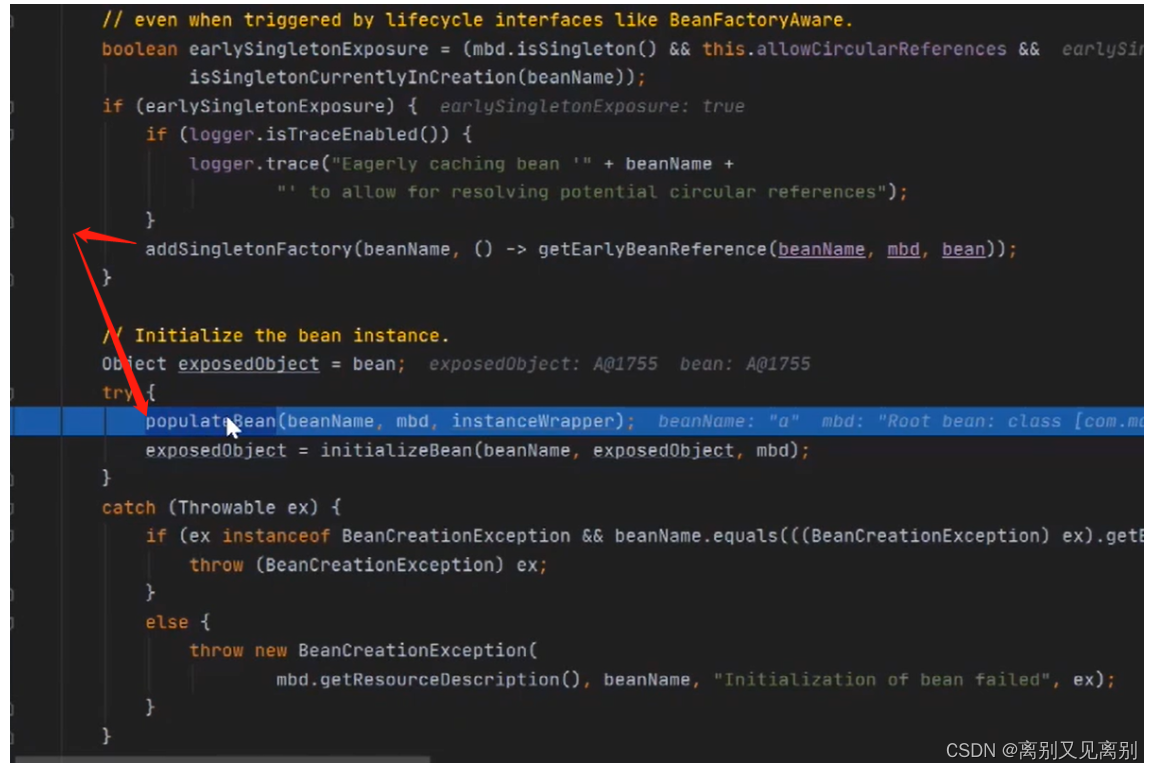
此时的填充属性是b
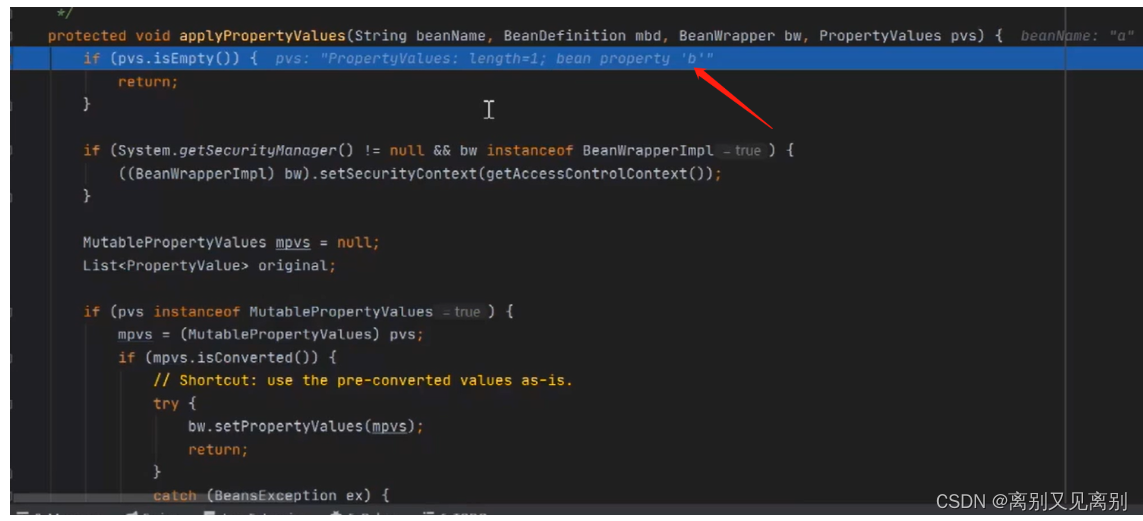
填充进一步执行
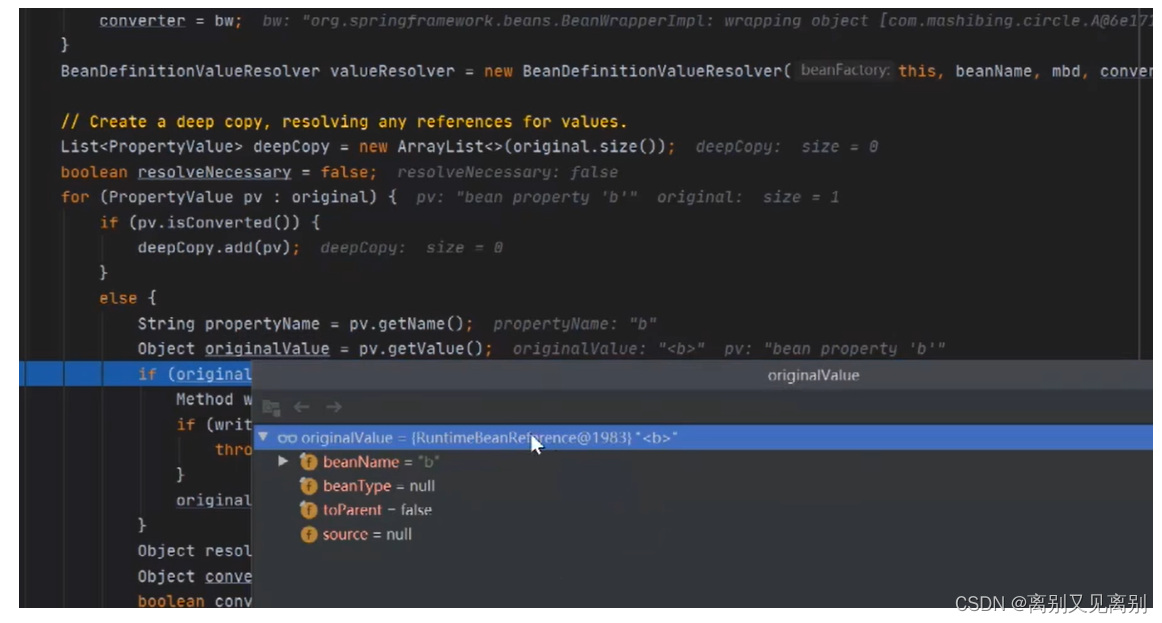
此时的originalValue 是
运行时的bean引用
并不是b对象
然后会执行getBean -> doGetBean -> getSingleton -> 查找B
3 实例化B
流程与a相同,createBean -> doCreateBean -> createBeanInstance() -> populateBean() (填充属性 a) -> 去容器中找
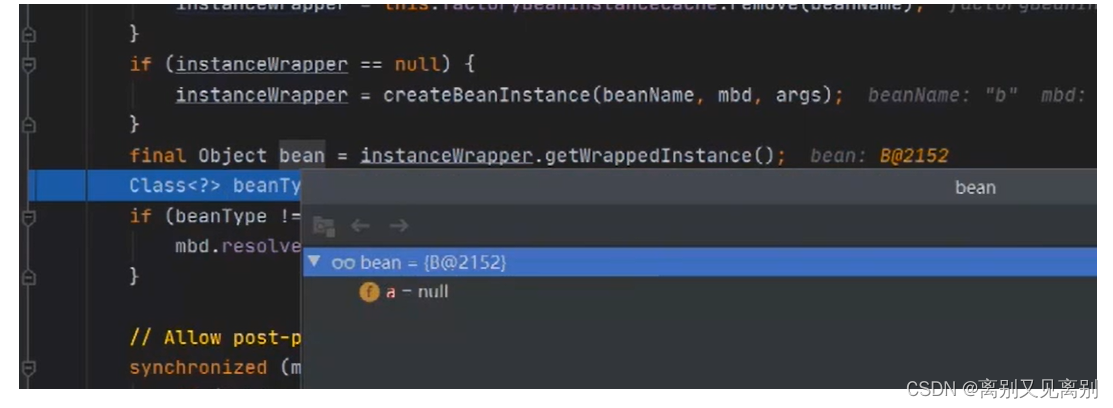
赋值a属性
-
此时一级缓存中没有a(实例化a的过程中,是将a放入了三级缓存中)[ this.singletonObjects() 返回null ]
-
此时a也在创建中(因为我们在a实例化的过程中引用了b属性,所以要在实例化及初始化b后,才能完成a的实例化及初始化) [ isSingletonCurrentlyInCreation 返回true ]
-
向二级缓存中查找,返回null
-
向三级缓存中查找,此时执行的便是三级缓存中存储的lambda表达式[ () -> getEarlyBeanReference 方法 ],
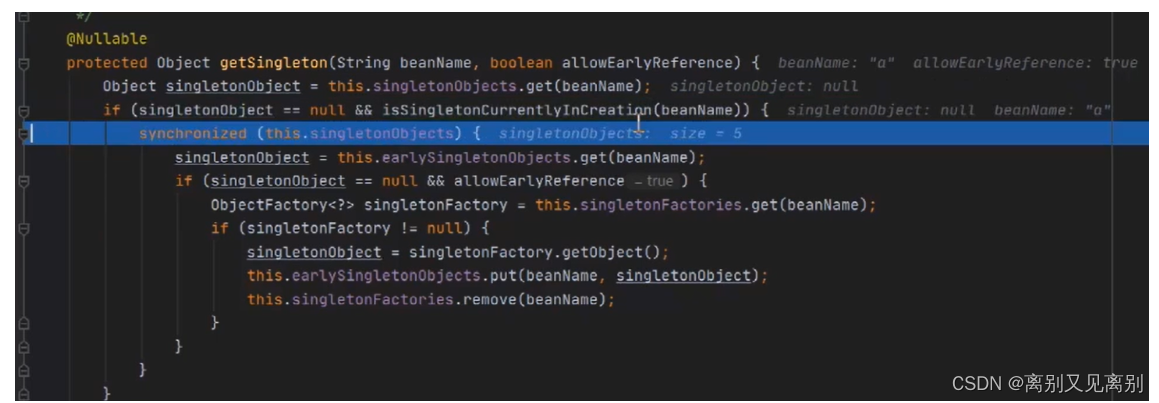

在三级缓存中获取到的对象,并不是完成对象而是半成品对象,
,此时 放入二级缓存中[ 格式: k: a , v: A@1755 ]
下一步便是删除三级缓存中的a,然后返回a,
4.初始化B
将B中的a属性赋值,但是此时a属性中的b属性还是null
,此时B的实例化和初始化完成
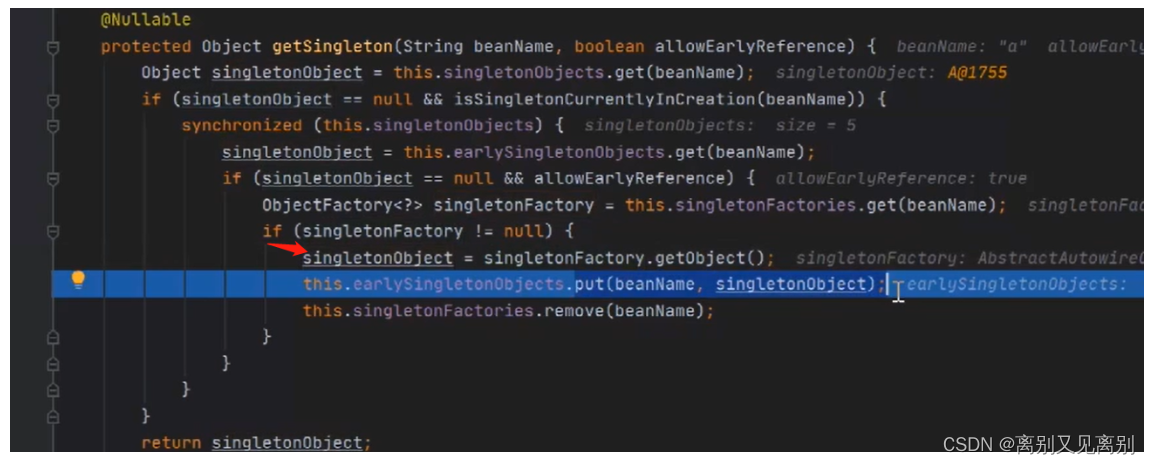
此时a的状态还是半成品,b是完整对象
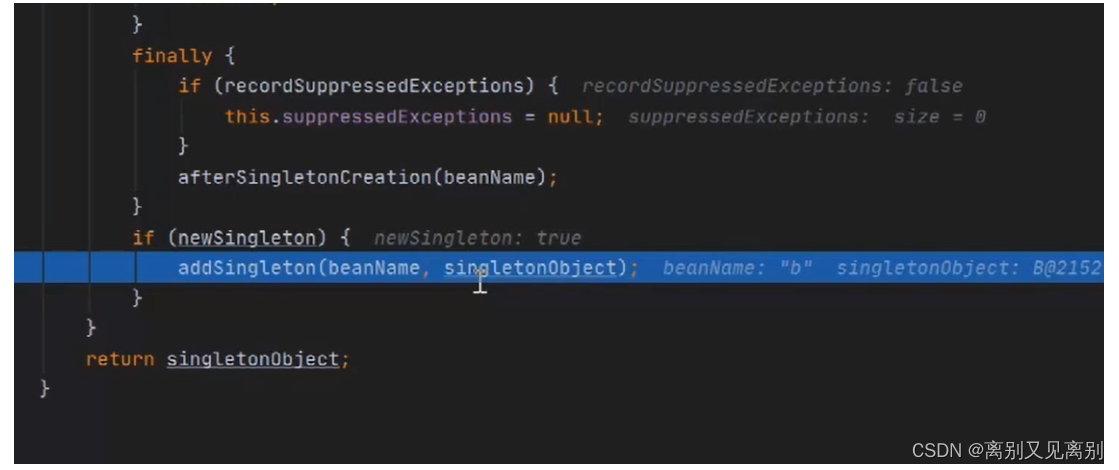
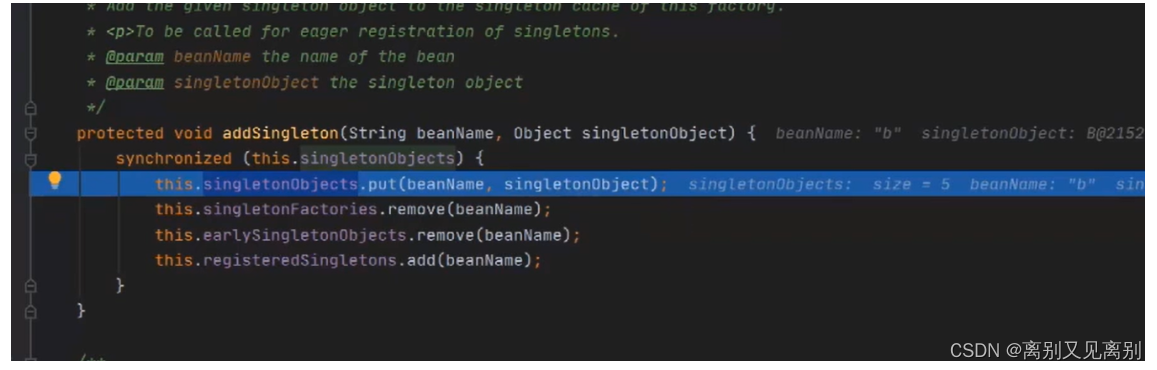
向一级缓存中放入b,同时删除二级及三级缓存中的b删除
5.初始化A
然后将a中的b属性赋值
,
现在a便是成品状态
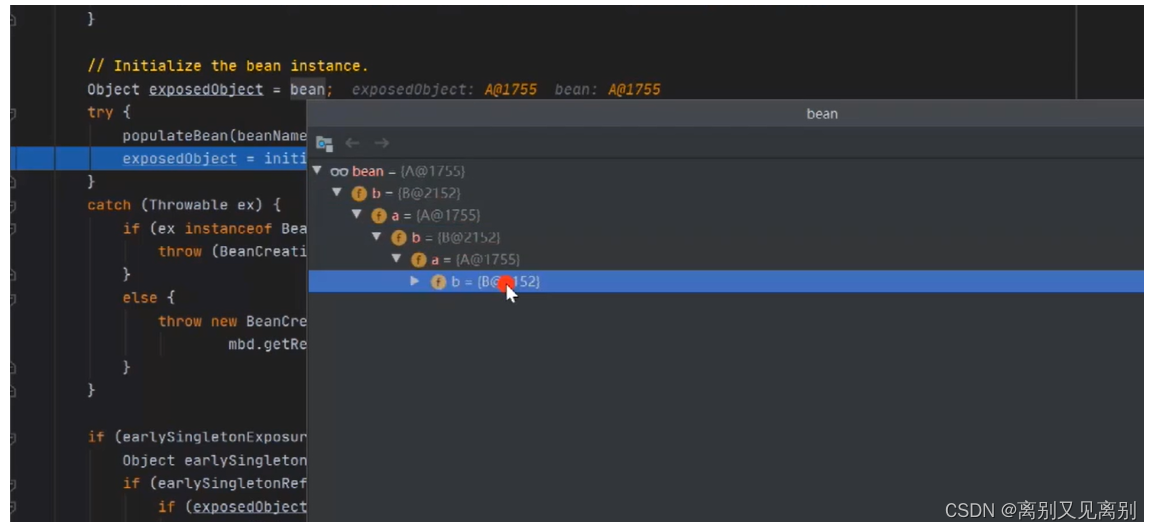
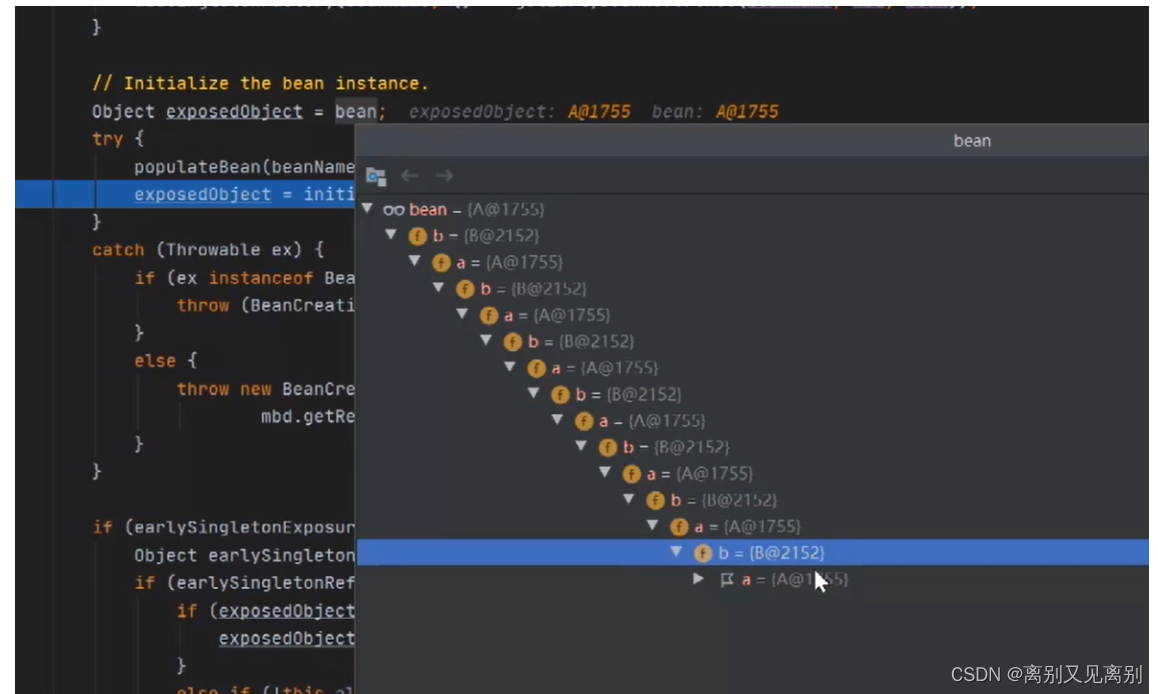
将a放入一级缓存,同时删除二级及三级缓存中的a
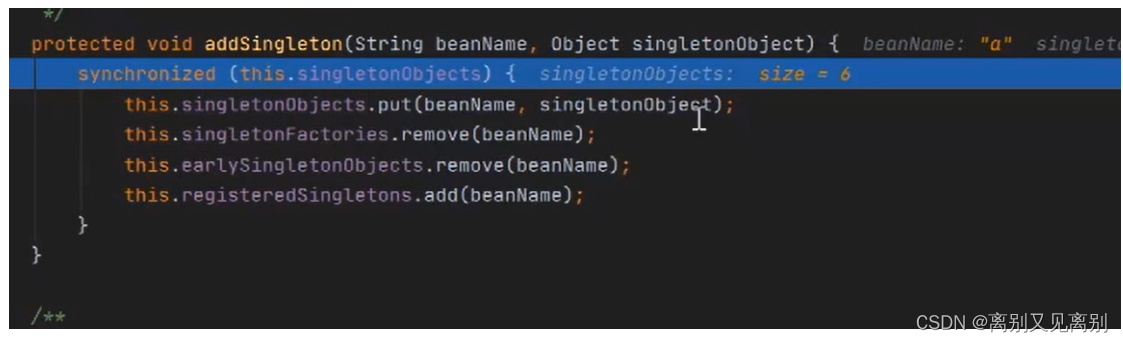
6.返回完成A的实例化和初始化,开始实例化和初始化B(流程与a一样,前提是一级缓存中没有)
下一步,实例化和初始化B,会去一级缓存中找,此时一级缓存中就会有b,取到直接返回,不用再次重新实例化和初始化
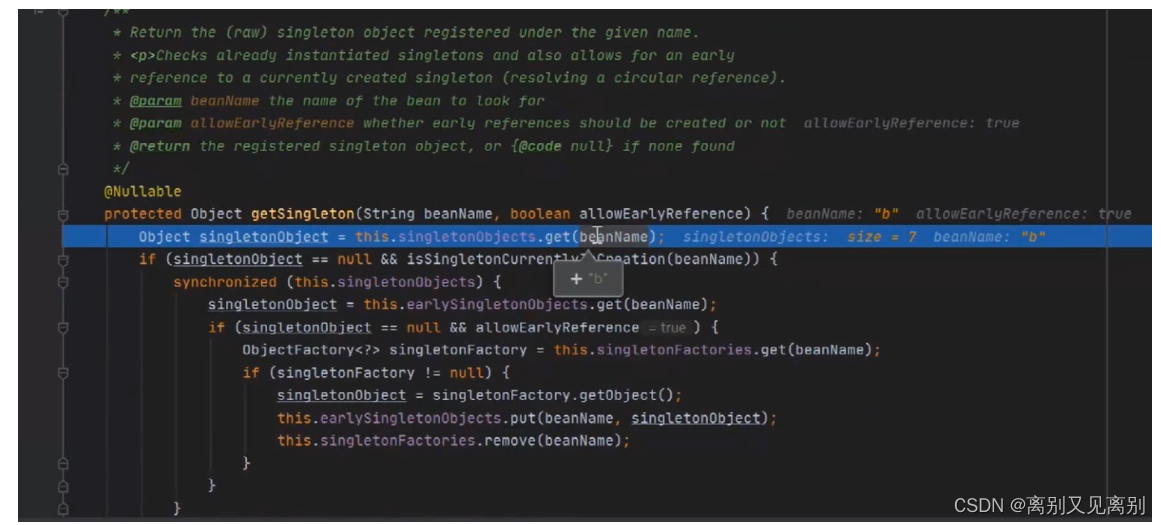
7.bean实例化和初始化完成
2.三级缓存解决循环依赖问题的关键是什么?为什么通过提前暴露对象能解决?
实例化和初始化分开操作,在中间过程中给其他对象赋值的时候,并不是一个完整对象,而是把半成品赋值给了其他对象。
3. 如果只使用一级缓存能不能解决问题?
不能,在整个处理过程中,缓存中放的是半成品和成品对象,如果只有一级缓存,那么成品和半成品都会放到一集缓存中,有可能在获取过程中获取到半成品对象,此时半成品对象无法使用,不能直接进行相关处理,因此要把半成品和成品的存放空间分割开.
4.只使用二级缓存行不行,为什么需要三级缓存?如果我能保证,所用的bean对象都不去调用getEarlyBeanReference从方法,使用二级缓存可以吗?
使用三次缓存是因为要调用 getEarlyBeanReference
如果能保证所有的bean都不调用getEarlyBeanReference,可以只使用二级缓存.
5.getEarlyBeanReference做了什么工作?
使用getEarlyBeanReference(三级缓存)的本质在于解决aop的代理问题!如果需要代理,就想原来的对象覆盖
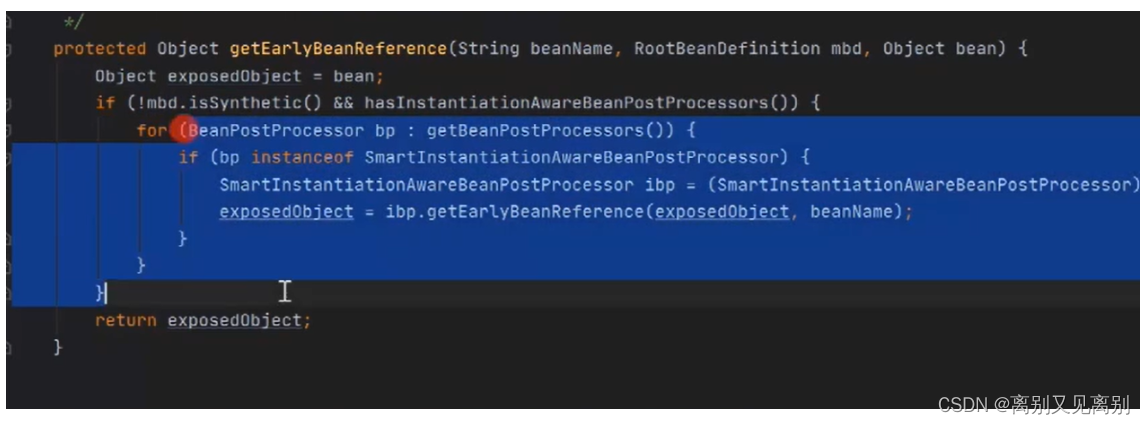
6.如果某个bean需要代理对象,那么会不会创建普通的bean对象?
必须会!,不管需不需要代理,bean一定会被创建的,但是会不会执行代理流程是不一定的 [ 不配置aop就不会代理 ]
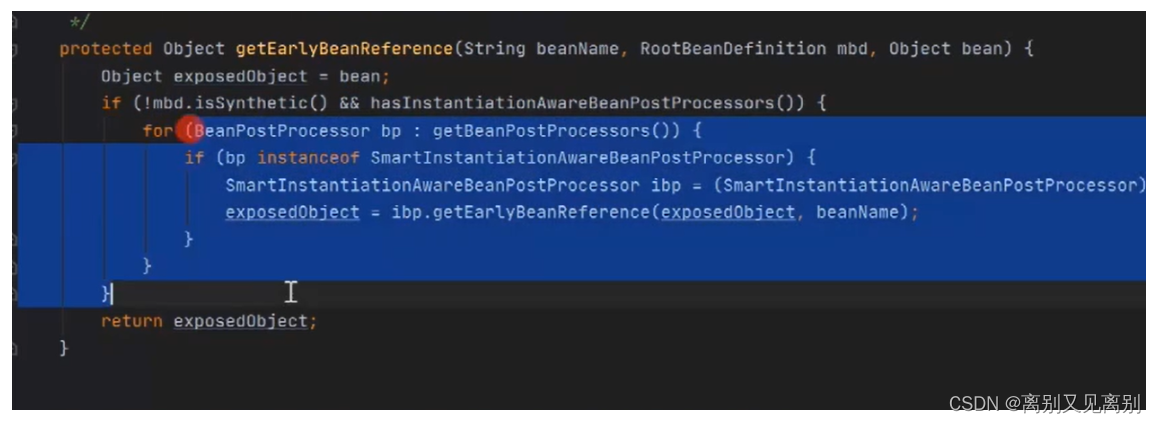
7.为什么使用了三级缓存就可以解决这个问题?
(本质在于解决aop的代理问题!)
当一个对象需要被代理的时候,在整个创建过程中,是包含两个对象。一个是普通对象,一个是代理生成的对象,bean默认都是单例的,那么我在整个生命周期的处理环节中,一个beanname能对应两个对象吗?不能,既然不能,保证我在使用的时候加一层判断,判断一下是否需要进行代理的处理。
8,我怎么知道你什么时候使用
因为不知道什么时候会调用,所以通过一个匿名内部类的方式,在使用的时候直接对普通对象进行覆盖操作,保证全局唯一!
beanFactory 属性初始化及扩展工作
public class MyClassPathXmlApplicationContext extends ClassPathXmlApplicationContext{
//有参构造
public MyClassPathXmlApplicationContext(String... configLocaltions){
super(configLocaltions);
}
//属性值扩展
@Override
protected void initPropertySources(){
getEnvironment().setRequiredProperties("OS");
}
//扩展 beanFactory
@Override
protected void customizeBeanFactory(DeffaultListableBeanFactory beanFactory){
//是否允许覆盖同名称的不同定义的对象
super.setAllowBeanDeffinitionOverriding(false);
//是否允许bean之间的循环依赖
super.setAllowCircularReferences(false);
//没有此行,扩展的东西不会生效
super.customizeBeanFactory(beanFactory);
}
}