目录
说明:
本篇文字主要在 Linux 系统上搭建 Hadoop ,采用伪分布式的形式搭建,因为只有一个服务器,如果有多个服务器的话,就可以采用分布式搭建了。
一、准备 Linux 系统
-
可以有以下三种方法拥有一个 Linux 系统:
- 安装一个虚拟机并建一个 Linux 系统;
- 在裸机上装双系统(Linux 和 Windows 两个系统);
- 申请一个云服务器(阿里云或腾讯云的)。
- 笔者采用的是腾讯云服务器,所以主要介绍腾讯云服务器申请步骤(主要是方便又便宜),其它方法可自行百度:
-
首先进入
腾讯云官网
-
点击【菜单】→【产业人才培养中心】→【动手实验室】。

-
这里面有许多的教程可以学习,随便进入一个教程,可以免费上机学习教程,不过到了一定时间就不能用了,重点不在这里,点击推荐活动中的【学生主机10元起】。

-
学生就可以很便宜的购买腾讯云的服务器了,选择 Ubuntu18.04 系统。

- 申请成功后,也可以更改系统、密码等。
-
点击右上方的【控制台】。

-
可以看到已有的一个云服务器。

-
【更多】内可以配置云服务器。

- 点击【登录】,然后扫描二维码,使用标准登录方式,输入密码或选择密匙文件即可远程连接云服务器。
二、安装 Xshell 与 Xfpt
说明:
Windows 主机上安装 Xshell 与 Xfpt ,为后续上传文件到云服务器用。
-
官网下载地址:
https://www.netsarang.com/en/all-downloads/
-
点击【DOWNLOAD】。

-
作为学生学习,下载免费的。

-
输入信息以及正确的邮箱后,点击【DOWNLOAD】后,下载链接在邮箱里,点击链接即可下载。

- Xshell 与 Xftp 下载完成后,双击开始安装,安装过程简单,就不赘述了。
三、配置服务器
说明:
由于 root 环境下操作比较危险,所以这里新建一个普通用户来进行 hadoop 的搭建。
3.1 创建普通用户
- 创建一个普通用户 hadoop 。
sudo useradd -m hadoop -s /bin/bash

- 设置密码并重复一次。
sudo passwd hadoop

- 给 hadoop 用户增加 sudo 管理员权限。
sudo adduser hadoop sudo

-
关闭终端,重新登录,将用户名更改为 hadoop ,并输入密码登录。

3.2 安装 SSH
- Ubuntu 一般默认安装了 SSH 客户端(openssh-client),所以还需要安装 SSH 服务端(openssh-server)。
sudo install openssh-server

- 安装后就可以使用以下命令登录:
ssh localhost

-
首次使用 SSH 登录时会提示如下,需要输入 yes 及 hadoop 用户密码。

- 可以使用命令 exit 退出。
3.3 安装 Java 环境
- 进入 /usr/lib 文件夹下。
cd /usr/lib

- 创建 jvm 文件夹。
sudo mkdir jvm

-
Windows 上下载 jdk1.8 安装包:
https://pan.baidu.com/s/1pYqMOW49cq9IrYOtLwMb5Q
——提取码:
6fat
-
打开 Xshell 软件,点击【新建】。

-
填写名称(随便填)、SSH 协议、主机(服务器的 IP)、端口号 22,然后点击【确定】。

-
双击刚刚建立的会话,点击【接受并保存】。

-
输入用户名 hadoop,再打开会话,输入登录密码,即可连接成功。

-
点击文件传输快捷键。
-
直接从左侧窗口拖动到右侧即可。

-
可以看到云服务器上已经有了该文件。

- 解压缩到 jvm 文件夹中。
sudo tar -zxvf jdk-8u291-linux-x64.tar.gz -C /usr/lib/jvm
- 编辑环境变量文件。
vim ~/.bashrc
- 在文件头添加如下内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_291
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
- 保存后退出,并让 bashrc 文件重新生效。
source ~/.bashrc

- 输入命令查看 Java 是否配置成功,显示如下即表示成功了。
java -version

3.4 安装 Hadoop
-
Hadoop 下载地址:
http://mirrors.cnnic.cn/apache/hadoop/common/
- 建议使用迅雷下载到本地,再用 Xftp 上传到云服务器,相当的快,使用 wget 以及浏览器下载那是慢得跟个蜗牛似的。
- 解压缩文件到 /usr/local 中。
sudo tar -zxf hadoop-3.3.0.tar.gz -C /usr/local

- 进入到 /usr/local 文件夹下,更改 hadoop-3.3.0 的文件名为 hadoop 。
cd /usr/local
sudo mv ./hadoop-3.3.0/ ./hadoop

- 修改文件权限,让用户 hadoop 可以使用 hadoop 文件夹。
sudo chown -R hadoop ./hadoop

-
进入到 hadoop 文件夹中,运行 hadoop,显示版本号即表示配置成功。

3.5 配置 Hadoop
单机模式配置:
- Hadoop 默认模式为非分布式模式(本地模式),无需进行其他配置即可运行。
- Hadoop 附带了丰富的例子,运行如下命令可以查看所有例子:
cd /usr/local/hadoop
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar

- 这里运行 grep 例子:
cd /usr/local/hadoop
mkdir input
cp ./etc/hadoop/*.xml ./input #备份文件,将配置文件复制到input目录下
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep ./input ./output 'dfs[a-z.]+'

- 查看运行结果:
cat ./output/*

伪分布式模式配置:
- 进入到 etc/hadoop 文件夹下:
cd /usr/local/hadoop/etc/hadoop

- 使用命令 vim core-site.xml 编辑文件。
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
-
如下图所示:

- 再编辑 hdfs-site.xml 文件。
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>

- 要执行名称节点的格式化。
./bin/hdfs namenode -format

- 启动 hadoop。
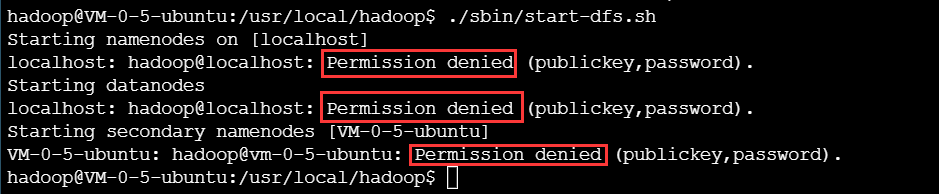
./sbin/start-dfs.sh
-
出现如下错误,权限不够。
- 导入公匙即可,具体步骤如下:
ssh-keygen -t rsa -P ""
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys

- 再次启动即可成功:
./sbin/start-dfs.sh

- 使用浏览器查看 HDFS 界面信息(9870 是 HDFS 默认端口)。
云服务器ip:9870

运行伪分布式实例
- 要使用 HDFS,首先需要在 HDFS 中创建用户目录。
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir -p /user/hadoop

- 接着需要把本地文件系统的 “/usr/local/hadoop/etc/hadoop” 目录中的所有 xml 文件作为输入文件,复制到分布式文件系统 HDFS 中的 “/user/hadoop/input” 目录中,命令如下:
./bin/hdfs dfs -mkdir input #在HDFS中创建hadoop用户对应的input目录
./bin/hdfs dfs -put ./etc/hadoop/*.xml input #把本地文件复制到HDFS中

- 在就可以运行Hadoop自带的grep程序,命令如下:
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep input output 'dfs[a-z.]+'

- 运行结束后,可以通过如下命令查看 HDFS 中的 output 文件夹中的内容:
./bin/hdfs dfs -cat output/*

- 关闭 hadoop 采用如下命令:
./sbin/stop-dfs.sh

- 配置 PATH 变量。
vim ~/.bashrc
- 添加如下语句:
export PATH=$PATH:/usr/local/hadoop/sbin

- 在后面的学习过程中,如果要继续把其他命令的路径也加入到 PATH 变量中,也需要继续修改 “~/.bashrc” 这个文件。当后面要继续加入新的路径时,只要用英文冒号 “:” 隔开,把新的路径加到后面即可,比如,如果要继续把 “/usr/local/hadoop/bin” 路径增加到 PATH 中,只要继续追加到后面,如下所示:
export PATH=$PATH:/usr/local/hadoop/sbin:/usr/local/hadoop/bin
- 添加后,执行命令 “source ~/.bashrc” 使设置生效。设置生效后,在任何目录下启动 Hadoop,都只要直接输入 start-dfs.sh 命令即可,同理,停止 Hadoop,也只需要在任何目录下输入 stop-dfs.sh 命令即可。
四、总结
- 由于经济实力不佳,所以只能买一个服务器,本篇文章就只有伪分布式的配置过程,如果想了解分布式配置的教程,可以下载参考资料的 ppt 文档。
五、参考资料
[1]
https://pan.baidu.com/s/1A6FB5yVcyufQUP6vg0gqYw
——提取码:
jg24
版权声明:本文为ssj925319原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。