
今天读了一篇小目标检测的综述性文章,所以就做了下面的笔记进行学习自用。
目标检测
一般分为两类:
第一:
在所给定的图像中对目标进行定位,即获得目标的回归框。
第二:
对图像中的目标进行分类,得出该目标的所属类别。
在深度学习蓬勃发展之前呢,目标检测方法依赖于人工设计的特征,并基于人类如何理解对象设计分类器。最近几年,因为CNN的成功,目标检测的任务取得了非常大的进步,尤其是在大目标和中目标二者上面。但是对小目标检测仍然存在着短板,小目标检测困难的原因是因为:
特征不可区分、分辨率低、背景复杂、上下文信息有限等。
在这片文章中,作者进行分析了小目标的挑战:(1)由基本CNN中的各个层生成的特征不包含用于小对象检测的足够信息;(2) 小对象检测缺少上下文信息;(3) 前景和背景训练示例的不平衡使得分类困难;(4)针对小物体的正面训练示例不足。然后,从以下角度总结了小对象的现有技术:1)组合多个特征图,2)添加上下文信息,3)平衡类示例,以及4)创建足够数量的正面示例(样本的平衡性)。
一般的主干网络是以非常优秀的分类网络为主,这些分类网络在非常大的数据集中进行训练完成之后,再将分类层给去除,然后再加上一些特征层,从而组成比较不错的目标检测网络结构。一些热门的主干网络有:
Vgg(2014) 、 ResNet92016 、Inception networks(2016)、DenseNet (2017)以及一些改进的网络结构
,并且现在transformer网络结构也被提出了。
为了更好地进行目标框回归,也提出了一种锚(anchor box),它是根据数据集中的真实框,直接进行聚类得到几种大小不同,比例不同的锚框,
在训练阶段是如何起作用的呢
?锚通过IoU(相交于联合)分数(在后面也产生了一系列其他的IOU计算方式,并且有些作者觉得单纯通过IUO计算的得到的结果并不是最好的,然后由提出了一种规划问题的方式
,可以查看yolox的方式
)与真实边界框匹配。通常,对于每个边界框,得分最高的anchor box或其IoU与真实框边界框高于阈值的anchor box被标记为正面示例。那些anchor box的IoU分数低于一个阈值,被贴上了负面的标签。 那么只有正例是用于进行目标框回归计算,即用正例与预测框进行计算,从而使预测框回归的更加准确。但是要注意的是,与预测框就进行计算的正例是真实框和锚框经过某种计算得到的标签
,计算过程如下图所示(看个大概就行)。
那么预测框的值也是需要和锚框进行计算得到后的某种值,这两点需要弄清楚,而这个锚框就是符合正例的锚框。可以将锚框理解为一座桥就行了!

那么对于损失函数,我们也就理清楚大概了,就是回归框损失+类别损失两者了。如下图所示。那么对于这两种损失当然也有很多改进了,具体的多种改进,并且为了实现正负样本的均衡以及难易样本的均衡,在何凯明大神的RetinaNet目标检测中提出了一种Focal Loss,可以自己多看论吧。
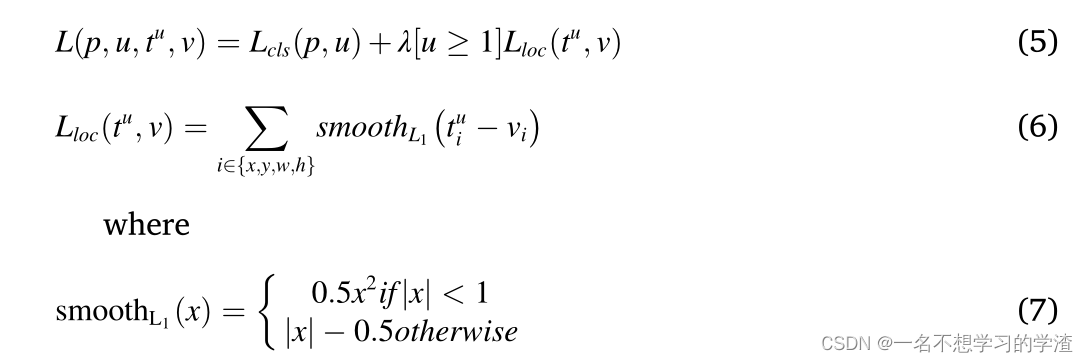
最后就是非极大值抑制算法,如下图所示,该算法的作用就是为了删除重复框,选择最优的框,即当两个框的置信度非常接近的时候,该算法会选择最好的框,而将另一个不错的框的置信度直接降为0,从而删除该框,因此该框有一个问题就是如果两个物体的重复度过高,那么该算法容易将另一个物体的框框直接删除,所以后面有提供了一个soft NMS,即软极大值抑制。即当两个框的置信度非常接近的时候,该算法会选择最好的框,而将另一个不错的框的置信度将低到某个阈值,从而达到一个不错的效果。并且后面又提出一种基于加权方式的非极大值抑制的方式,叫做WBF法,大家可以自己去网上了解。

特征金字塔网络(FPN)后续又出现PANet,BiFPN等等方式,
专注于解决以下问题:较低层次的特征图包含更多的空间信息,但语义信息较少,而深度神经网络的后一层包含更多的高级语义信息,但空间信息较少。FPN利用了CNN网络的层次结构,通过横向连接实现了自下而上和自上而下的路径。在自下而上部分,输入图像通过CNN,并使用池层缩小特征图大小。
在自上而下的部分,特征图被上采样回与自下而上的部分相同的大小。此外,横向连接融合了相同尺寸的自下而上路径和自上而下路径中的特征图,并进行了逐元素添加。FPN生成的集成特征图显著提高了检测精度,特别是对于小物体。
众所周知,在深度CNN架构中多次下采样后,后一种特征图会丢失空间信息。因此单独的低级特征或单独的高级特征不足以用于小对象检测,如下图灰色部分所示。那么就出现了特征融合的方式。也就是上面所说的FPN网络结构。
通常小物体的分辨率很低,很难识别低分辨率物体。由于小对象本身包含有限的信息,上下文信息在小对象检测中起着关键作用。上下文信息已被用于从“全局”图像级别到“局部”图像级别的对象识别。全局图像级别考虑来自整个图像的图像统计,而局部图像级别考虑对象的相邻区域的上下文信息。上下文特征可分为三种类型:a.局部像素上下文:对象周围的斑块或像素,如边缘、颜色、纹理等。局部像素上下文可以通过增加对象检测网络中检测窗口的大小来捕获。b.语义上下文:对象在某些周围场景中被识别的概率,如事件、活动或场景类别。c.空间上下文:图像中其他对象的空间位置,例如。相对于图像中的其他对象,在某些位置找到对象的可能性。例如,在人脸检测系统中,受试者的肩膀和脖子总是靠近他们的脸。
解决方案:在检测网络中加入上下文信息。局部像素上下文通常通过放大过滤器大小来添加,以捕获对象周围的额外信息。语义上下文通常通过从图像中提取更深的特征来添加,例如在反褶积层或递归神经网络(RNN)中。
对于类不平衡的问题,有两种,一种是因为前景和背景的数量差距太大,比如说在RPN中生成的感兴趣区域。第二个就是在预定义锚框的时候,由于在选择正负样本的时候,许多锚框都被当成了负样本,从而导致负样本在主导损失函数的走向。并且由于锚框的遍历,也导致训练时会很慢,它的计算复杂度为O(mn).
针对这样的问题,主要有两种策略:
1)基于数据的策略 和 2)基于损失函数的策略。
基于数据的策略是改变前景和背景示例编号,使正负类的示例具有大致相同的权重。硬采样和软采样是两种流行的方法。硬采样选择样本的子集,而软采样为样本分配不同的权重。例如,随机抽样通常用于随机选择实例以满足特定比率。另一种抽样策略是对损失较大的硬样本进行更多的抽样。例如,可以首先训练机器学习模型,然后将误报视为硬示例,在第二轮训练中对其进行加权。即对计算出的感兴趣区域(RoI)执行一次前向传递,并计算所有RoI的损失。然后,基于实例的损失函数值对其进行排序,并选择损失最大的实例用于下一轮训练,因为当前训练的网络模型对它们的性能最差。
对于小目标的正样本少,该论文提出了这样的方式进行解决:
1) 多尺度机制。由小型、中型和大型对象的独立分支组成的多尺度体系结构可以生成不同尺度的锚。
2) 匹配策略。自适应地设置锚定尺度和比例,以帮助更多的锚定与小物体的地面真实性相匹配。
3) 增加小对象的正面示例。在区域提案阶段,通过允许锚相互重叠来生成更多锚。
论文后面还是提到了不同应用场景的一些解决方式,个人觉得就是上下文、注意力机制、特征融合等等方法。有兴趣的小伙伴可以自己研究研究。