sql 是对大小写不敏感的
SQL 使用
1,安装,配置
2,navicat安装使用
+,命令行启动/关闭:
1,启动:net start mysql
2,关闭; net stop mysql
-- 函数
-- 查看mysql 版本
select version()
-- null值判断
select column1, ifnull(column2, column2为null时的默认值) from table-name;
-- 转义字符
select * from table-name where column1 like "\_%"; # 查询字段第一个字符为_的数据
-- 指定转义字符 escape
select * from table-name where column1 like "@_%" escape "@";
数据库 数据表语句
-- 显示数据库
show databases;
-- 显示数据表
show tables;
-- 使用数据库
use database-name;
-- 查询数据表结构
show columns from table-name;
-- 查询表的索引
show index from table-name;
-- 查询数据库中所有表的性能和统计信息
show table status from database-name;
-- 查询数据库中匹配的表的性能和统计信息
show table status from database-name like '%some like%';
-- 查询数据库中所有表的性能和统计信息,结果以列的方式打印
show table status from database-name \G;
-- 显示表结构
desc table-name;
-- 查看创建表的语句
show create table table-name;
-- 创建数据库
create database database-name;
-- 删除数据库
drop database database-name;
-- 创建表
create table if not exists table-name (column_name column_type, column_name column_type, ...);
-- 删除表
drop table if exists table-name;
-- 清空表数据,保留表结构
trancate table table-name;
-- 修改表
alter table table-name add/drop/modify/change column column-name column-type column-约束;
-- 在最前面添加字段
alter table table-name add column-name column-type first;
-- 在某一个字段后面添加字段
alter table table-name add column-name column-type after old-column-name;
-- 默认自增字段从1开始 ,修改自增字段初始值
alter table table-name auto_increment=xx
-- 表名重命名
ALTER TABLE table_name RENAME TO new_table_name;
-- 复制表结构
create table new_table_name like table-name;
-- 复制表内全部数据,新建一个表
create table new_table_name select * from table-name;
-- 复制部分表结构
create table new_tbale_name select column1, column2,... from teble-name where conditon1 = condition2 # 条件不满足时,只有结构复制
数值类型
MySQL支持多种数据类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型
。
MySQL支持所有标准SQL数值数据类型。
这些类型包括严格数值数据类型(INTEGER、SMALLINT、DECIMAL和NUMERIC),以及近似数值数据类型(FLOAT、REAL和DOUBLE PRECISION)。
关键字INT是INTEGER的同义词,关键字DEC是DECIMAL的同义词。
BIT数据类型保存位字段值,并且支持MyISAM、MEMORY、InnoDB和BDB表。
作为SQL标准的扩展,MySQL也支持整数类型TINYINT、MEDIUMINT和BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
|---|---|---|---|---|
| TINYINT | 1 byte | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2 bytes | (-32 768,32 767) | (0,65 535) | 大整数值 |
| MEDIUMINT | 3 bytes | (-8 388 608,8 388 607) | (0,16 777 215) | 大整数值 |
| INT或INTEGER | 4 bytes | (-2 147 483 648,2 147 483 647) | (0,4 294 967 295) | 大整数值 |
| BIGINT | 8 bytes | (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4 bytes | (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) | 0,(1.175 494 351 E-38,3.402 823 466 E+38) |
单精度 浮点数值 |
| DOUBLE | 8 bytes | (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) | 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) |
双精度 浮点数值 |
| DECIMAL | 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 | 依赖于M和D的值 | 依赖于M和D的值 | 小数值 |
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个”零”值,当指定不合法的MySQL不能表示的值时使用”零”值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
| 类型 |
大小 ( bytes) |
范围 | 格式 | 用途 |
|---|---|---|---|---|
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | ‘-838:59:59’/’838:59:59’ | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999-12-31 23:59:59 | YYYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 |
1970-01-01 00:00:00/2038
结束时间是第 |
YYYYMMDD HHMMSS | 混合日期和时间值,时间戳 |
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
| 类型 | 大小 | 用途 |
|---|---|---|
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| TINYBLOB | 0-255 bytes | 不超过 255 个字符的二进制字符串 |
| TINYTEXT | 0-255 bytes | 短文本字符串 |
| BLOB | 0-65 535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65 535 bytes | 长文本数据 |
| MEDIUMBLOB | 0-16 777 215 bytes | 二进制形式的中等长度文本数据 |
| MEDIUMTEXT | 0-16 777 215 bytes | 中等长度文本数据 |
| LONGBLOB | 0-4 294 967 295 bytes | 二进制形式的极大文本数据 |
| LONGTEXT | 0-4 294 967 295 bytes | 极大文本数据 |
注意
:char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY 和 VARBINARY 类似于 CHAR 和 VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。这说明它们没有字符集,并且排序和比较基于列值字节的数值值。
BLOB 是一个二进制大对象,可以容纳可变数量的数据。有 4 种 BLOB 类型:TINYBLOB、BLOB、MEDIUMBLOB 和 LONGBLOB。它们区别在于可容纳存储范围不同。
有 4 种 TEXT 类型:TINYTEXT、TEXT、MEDIUMTEXT 和 LONGTEXT。对应的这 4 种 BLOB 类型,可存储的最大长度不同,可根据实际情况选择。
-- 插入数据,指定字段插入
insert into table-name (field1, field2, ...) values (value1, value2, ...);
-- 插入数据根据字段顺序插入
insert into table-name values (value1, value2, ...);
-- 插入从其他表内查找到的数据
insert info table-name (field1, field2, ...) select (field1, field2, ...) from table-name2 where condition;
-- 如果表内存在数据忽略插入
insert ignore into table-name values(field1, field2, ...);
-- 查询表内的所有数据
select * from table-name;
-- 查询表内指定字段的数据
select column1, column2 from table-name;
-- 根据条件查找数据;
select * from table-name where id > 10;
select * from table-name where create_time=NOW();
select * from table-name where name like "%张三%";
-- 限制查询数量
select * from table-name limit 10;
select * from table-name where id>100 limit 10;
-- 分页 使用offset -- page_size:每页大小, page_offset:排除前几条数据
select * from table-name limit page_size offset page_offset
-- 查询数据 where查询条件默认不区分大小写
select * from table-name where name="test"; -- 查询出name=TEST/test/Test/teST...
-- 查询数据 指定where条件 大小写
select * from table-name where binary name='test'; -- 值查询处name=test的数据
-- 去重
select distinct column1, distinct column2 from table-name;
-- 直接处理非表内数据 例如:统计“10,A,B” 内的逗号个数
-- 下面语句的解释:将逗号替换为空字符串 然后统计字符串前后的个数差 就是逗号的个数
select (char_length("10,A,B") - char_length(replace("10,A,B", ",", ""))) as nums
-- 修改指定字段的所有数据
update table-name set column1=value1, column2=value2;
-- 修改符合条件的指定字段的数据
update table-name set column1=value1, column2=value2 where condition=...;
-- 将某个int类型的字段数据修改
update table-name set age=age+1 where name='张三';
-- 替换指定字段指定数据的值
update table-name set column_name=replace(column_name, 'old_column_value', 'new_column_value');
-- 删除表内所有数据
delete from table-name;
-- 删除表内符合条件的数据
delete from table-name where codition=...;
-- 执行的速度上,drop>truncate>delete
-- 模糊匹配like,和 % _ 一起使用
-- % 匹配一个或多个字符
select * from table-name where name like "张%"; -- 查询姓张的所有人的信息
-- _为匹配单个字符
select * from table-name where name like "张_"; -- 查询姓张 名字里只有一个字的所有人的信息
select * from table-name where nema like "_三_"; -- 查询姓名为三个字,并且中间的字为三的所有人的信息
-- 排序, 默认为正序asc排列
select * from table-name order by age;
select * from table-name order by age asc;
-- 排序,根据某个字段倒叙排序
select * from table-name order by age desc;
-- 条件排序
select * from table-name where name like "张%" order by age desc;
-- 多条件 和and
select * from table-name where id=1 and name like "_三_";
-- 多条件 或 or 注意:通过or查询出来的结果是去重后的结果要想不去重就要使用union all链接两侧select查询
select * from table-name where id=1 or name='李四';
-- 拼音排序:如果字符集采用的是 utf8(万国码),需要先对字段进行转码然后排序
select * from table-name order by counvert(column_name usering gbk);
-- group by 指定多个列对结果集进行分组
select age, class from table-name group by class, age;
-- group by...with rollup 对分组数据进行汇总。一般和ifnull(column, default value)配置使用
select ifnull(age, '年龄'), ifnull(class, '班级') from table_name group by class, age with rollup
-- 内连接,获取两个表中字段匹配关系的记录
-- 内连接,查询两个表内某些字段数据一致的信息
select a.column1, a.column2, b.column1 from table-a as a inner join table-b as b on a.name = b.name and a.age = b.age;
-- 内连接,查询符合条件的数据
select a.column1, a.column2, b.column1 from table-a a, table-b b where a.name = b.name;
-- 左连接,获取左表所有记录,即使右表没有对应匹配的记录
-- 左连接,读取左表的所有数据,和右表内字段一直的/即使右表字段无数据
select a.column1. a.column2, b.column1 from table-left a left join table-right b on a.name = b.name;
-- 右连接,用于获取右表所有记录,即使左表没有对应匹配的记录
-- 右链接,读取右表所有数据,和左表匹配的数据/即使坐标字段五数据
select a.column1, b.column1 from table-left a right join table-right b on a.name = b.name;
-- 外连接,获取两个表内所有的记录,没有匹配上的字段为null
select a.colimn1, b.column2 from table-a outer join table-b on tablea.column-a = tableb.colimn-b;
-- 空值处理
select * from table-name where column1 is null;
select * from table-name where column1 is not null;
连接查询
-- 内连接
select column1, column2, from table-1, table2 where table-1.column-x = table-1.column-x;
-- 内连接-等值连接
select a.column1, b.column1 from table-1 a 【inner】 join tatble-2 b on a.column-x=b.column-x;
-- 内连接-非等值连接
select a.column1, b.column1 from table-1 a 【inner】 join table-2 b on a.column-x between b.column-a and b.column-b;
-- 自连接
select a.column1, b.column2 from table-1 a 【inner】 join table-1 b on a.column-a=b.column-a;
-- 外连接
-- 外连接-左连接:左边为主表,没有匹配值的时候显示 NULL
select a.column1, b.column2 from table-1 a left join table-2 b on a.column-a=b.column-b;
-- 外连接-右链接:右边为主表,没有匹配值的时候显示 NULL
select a.column1, b.column2 from table-1 a right join table-2 b on a.column-a=b.column-b;
-- 交叉连接: 只显示匹配的行
select a.column1, b.column2 from table-1 a cross join table-2 b on a.column-a=b.column-b;
-- 子查询: 出现在其他语句(增删改查)中的查询语句
select column1 from (select a.column1, b.column2 from table-1 a cross join table-2 b on a.column-x=b.column-x) as a;
/*
子查询分类--按照结果集的行列数分:
标量子查询(结果集只有一行一列)
列子查询(结果集只有一列)
行子查询(结果集只有一行)
表子查询(结果集为多行多列)
子查询分类--按照出现的位置分:
select:
仅支持标量子查询
from:
表子查询
where/hving:
标量子查询
行子查询
列子查询
exists:
表子查询
*/
联合查询
-- 联合查询:将多个查询语句使用 union 连接
select * from table where ... union select * from table where ...;
/*
两条查询语句的查询字段必须一致;
两条查询语句的查询字段数量必须一致;
union 默认去重;
要使结果显示两个表里所有的查询结果,可以使用union all
*/
条件判断操作符
| 操作符 | 描述 | 实例 |
|---|---|---|
| = | 等号,检测两个值是否相等,如果相等返回true | (A = B) 返回false。 |
| <>, != | 不等于,检测两个值是否相等,如果不相等返回true | (A != B) 返回 true。 |
| > | 大于号,检测左边的值是否大于右边的值, 如果左边的值大于右边的值返回true | (A > B) 返回false。 |
| < | 小于号,检测左边的值是否小于右边的值, 如果左边的值小于右边的值返回true | (A < B) 返回 true。 |
| >= | 大于等于号,检测左边的值是否大于或等于右边的值, 如果左边的值大于或等于右边的值返回true | (A >= B) 返回false。 |
| <= | 小于等于号,检测左边的值是否小于或等于右边的值, 如果左边的值小于或等于右边的值返回true | (A <= B) 返回 true。 |
MySQL 的 WHERE 子句的字符串比较是不区分大小写的。
查询语句指定顺序
- FROM, including JOINs
- WHERE
- GROUP BY
- HAVING
- WINDOW functions
- SELECT
- DISTINCT
- UNION
- ORDER BY
- LIMIT and OFFSET
MySQL 字符串函数
| 函数 | 描述 | 实例 |
|---|---|---|
| ASCII(s) | 返回字符串 s 的第一个字符的 ASCII 码。 |
返回 CustomerName 字段第一个字母的 ASCII 码: |
| CHAR_LENGTH(s) | 返回字符串 s 的字符数 |
返回字符串 RUNOOB 的字符数 |
| CHARACTER_LENGTH(s) | 返回字符串 s 的字符数 |
返回字符串 RUNOOB 的字符数 |
| CONCAT(s1,s2…sn) | 字符串 s1,s2 等多个字符串合并为一个字符串 |
合并多个字符串 |
| CONCAT_WS(x, s1,s2…sn) | 同 CONCAT(s1,s2,…) 函数,但是每个字符串之间要加上 x,x 可以是分隔符 |
合并多个字符串,并添加分隔符: |
| FIELD(s,s1,s2…) | 返回第一个字符串 s 在字符串列表(s1,s2…)中的位置 |
返回字符串 c 在列表值中的位置: |
| FIND_IN_SET(s1,s2) | 返回在字符串s2中与s1匹配的字符串的位置 |
返回字符串 c 在指定字符串中的位置: |
| FORMAT(x,n) | 函数可以将数字 x 进行格式化 “#,###.##”, 将 x 保留到小数点后 n 位,最后一位四舍五入。 |
格式化数字 “#,###.##” 形式: |
| INSERT(s1,x,len,s2) | 字符串 s2 替换 s1 的 x 位置开始长度为 len 的字符串 |
从字符串第一个位置开始的 6 个字符替换为 runoob: |
| LOCATE(s1,s) | 从字符串 s 中获取 s1 的开始位置 |
获取 b 在字符串 abc 中的位置: 返回字符串 abc 中 b 的位置: |
| LCASE(s) | 将字符串 s 的所有字母变成小写字母 |
字符串 RUNOOB 转换为小写: |
| LEFT(s,n) | 返回字符串 s 的前 n 个字符 |
返回字符串 runoob 中的前两个字符: |
| LOWER(s) | 将字符串 s 的所有字母变成小写字母 |
字符串 RUNOOB 转换为小写: |
| LPAD(s1,len,s2) | 在字符串 s1 的开始处填充字符串 s2,使字符串长度达到 len |
将字符串 xx 填充到 abc 字符串的开始处: |
| LTRIM(s) | 去掉字符串 s 开始处的空格 |
去掉字符串 RUNOOB开始处的空格: |
| MID(s,n,len) | 从字符串 s 的 n 位置截取长度为 len 的子字符串,同 SUBSTRING(s,n,len) |
从字符串 RUNOOB 中的第 2 个位置截取 3个 字符: |
| POSITION(s1 IN s) | 从字符串 s 中获取 s1 的开始位置 |
返回字符串 abc 中 b 的位置: |
| REPEAT(s,n) | 将字符串 s 重复 n 次 |
将字符串 runoob 重复三次: |
| REPLACE(s,s1,s2) | 将字符串 s2 替代字符串 s 中的字符串 s1 |
将字符串 abc 中的字符 a 替换为字符 x: |
| REVERSE(s) | 将字符串s的顺序反过来 |
将字符串 abc 的顺序反过来: |
| RIGHT(s,n) | 返回字符串 s 的后 n 个字符 |
返回字符串 runoob 的后两个字符: |
| RPAD(s1,len,s2) | 在字符串 s1 的结尾处添加字符串 s2,使字符串的长度达到 len |
将字符串 xx 填充到 abc 字符串的结尾处: |
| RTRIM(s) | 去掉字符串 s 结尾处的空格 |
去掉字符串 RUNOOB 的末尾空格: |
| SPACE(n) | 返回 n 个空格 |
返回 10 个空格: |
| STRCMP(s1,s2) | 比较字符串 s1 和 s2,如果 s1 与 s2 相等返回 0 ,如果 s1>s2 返回 1,如果 s1<s2 返回 -1 |
比较字符串: |
| SUBSTR(s, start, length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串 |
从字符串 RUNOOB 中的第 2 个位置截取 3个 字符: |
| SUBSTRING(s, start, length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串 |
从字符串 RUNOOB 中的第 2 个位置截取 3个 字符: |
| SUBSTRING_INDEX(s, delimiter, number) |
返回从字符串 s 的第 number 个出现的分隔符 delimiter 之后的子串。 如果 number 是正数,返回第 number 个字符左边的字符串。 如果 number 是负数,返回第(number 的绝对值(从右边数))个字符右边的字符串。 |
|
| TRIM(s) | 去掉字符串 s 开始和结尾处的空格 |
去掉字符串 RUNOOB 的首尾空格: |
| UCASE(s) | 将字符串转换为大写 |
将字符串 runoob 转换为大写: |
| UPPER(s) | 将字符串转换为大写 |
将字符串 runoob 转换为大写: |
这里加一个 group_concat 拼接一组数据
select dept_no, group_concat(emp_no) as employees
from dept_emp
group by dept_no
-- 分隔符默认为逗号 ,
-- 指定分隔符如下
select dept_no, group_concat(emp_no SEPARATOR "*") as employees
from dept_emp
group by dept_no
MySQL 数字函数
| 函数名 | 描述 | 实例 |
|---|---|---|
| ABS(x) | 返回 x 的绝对值 |
返回 -1 的绝对值: |
| ACOS(x) | 求 x 的反余弦值(参数是弧度) |
|
| ASIN(x) | 求反正弦值(参数是弧度) |
|
| ATAN(x) | 求反正切值(参数是弧度) |
|
| ATAN2(n, m) | 求反正切值(参数是弧度) |
|
| AVG(expression) | 返回一个表达式的平均值,expression 是一个字段 |
返回 Products 表中Price 字段的平均值: |
| CEIL(x) | 返回大于或等于 x 的最小整数 |
|
| CEILING(x) | 返回大于或等于 x 的最小整数 |
|
| COS(x) | 求余弦值(参数是弧度) |
|
| COT(x) | 求余切值(参数是弧度) |
|
| COUNT(expression) | 返回查询的记录总数,expression 参数是一个字段或者 * 号 |
返回 Products 表中 products 字段总共有多少条记录: |
| DEGREES(x) | 将弧度转换为角度 |
|
| n DIV m | 整除,n 为被除数,m 为除数 |
计算 10 除于 5: |
| EXP(x) | 返回 e 的 x 次方 |
计算 e 的三次方: |
| FLOOR(x) | 返回小于或等于 x 的最大整数 |
小于或等于 1.5 的整数: |
| GREATEST(expr1, expr2, expr3, …) | 返回列表中的最大值 |
返回以下数字列表中的最大值: 返回以下字符串列表中的最大值: |
| LEAST(expr1, expr2, expr3, …) | 返回列表中的最小值 |
返回以下数字列表中的最小值: 返回以下字符串列表中的最小值: |
| LN | 返回数字的自然对数,以 e 为底。 |
返回 2 的自然对数: |
| LOG(x) 或 LOG(base, x) | 返回自然对数(以 e 为底的对数),如果带有 base 参数,则 base 为指定带底数。 |
|
| LOG10(x) | 返回以 10 为底的对数 |
|
| LOG2(x) | 返回以 2 为底的对数 |
返回以 2 为底 6 的对数: |
| MAX(expression) | 返回字段 expression 中的最大值 |
返回数据表 Products 中字段 Price 的最大值: |
| MIN(expression) | 返回字段 expression 中的最小值 |
返回数据表 Products 中字段 Price 的最小值: |
| MOD(x,y) | 返回 x 除以 y 以后的余数 |
5 除于 2 的余数: |
| PI() | 返回圆周率(3.141593) |
|
| POW(x,y) | 返回 x 的 y 次方 |
2 的 3 次方: |
| POWER(x,y) | 返回 x 的 y 次方 |
2 的 3 次方: |
| RADIANS(x) | 将角度转换为弧度 |
180 度转换为弧度: |
| RAND() | 返回 0 到 1 的随机数 |
|
| ROUND(x) | 返回离 x 最近的整数 |
|
| SIGN(x) | 返回 x 的符号,x 是负数、0、正数分别返回 -1、0 和 1 |
|
| SIN(x) | 求正弦值(参数是弧度) |
|
| SQRT(x) | 返回x的平方根 |
25 的平方根: |
| SUM(expression) | 返回指定字段的总和 |
计算 OrderDetails 表中字段 Quantity 的总和: |
| TAN(x) | 求正切值(参数是弧度) |
|
| TRUNCATE(x,y) | 返回数值 x 保留到小数点后 y 位的值(与 ROUND 最大的区别是不会进行四舍五入) |
|
MySQL 日期函数
-- 这里加一个 时间比较 ,函数返回根据不同时间计算的差值。
-- 比如timestampdiff(minute,'2021-01-01 10:00:00', '2021-01-01 10:10:39') 返回的是开始时间和结束时间相差10分钟
timestampdiff(second/minute/hour/day/month/year,starttime,endtime)
-- 毫秒级时间戳
select REPLACE(unix_timestamp(current_timestamp(3)),'.','');
-- 秒级时间戳
select UNIX_TIMESTAMP(NOW());| 函数名 | 描述 | 实例 |
|---|---|---|
| ADDDATE(d,n) | 计算起始日期 d 加上 n 天的日期 |
|
| ADDTIME(t,n) | n 是一个时间表达式,时间 t 加上时间表达式 n |
加 5 秒: 添加 2 小时, 10 分钟, 5 秒: |
| CURDATE() | 返回当前日期 |
|
| CURRENT_DATE() | 返回当前日期 |
|
| CURRENT_TIME | 返回当前时间 |
|
| CURRENT_TIMESTAMP() | 返回当前日期和时间 |
|
| CURTIME() | 返回当前时间 |
|
| DATE() | 从日期或日期时间表达式中提取日期值 |
|
| DATEDIFF(d1,d2) | 计算日期 d1->d2 之间相隔的天数 |
|
| DATE_ADD(d,INTERVAL expr type) |
计算起始日期 d 加上一个时间段后的日期,type 值可以是:
|
|
| DATE_FORMAT(d,f) | 按表达式 f的要求显示日期 d |
|
| DATE_SUB(date,INTERVAL expr type) | 函数从日期减去指定的时间间隔。 |
Orders 表中 OrderDate 字段减去 2 天: |
| DAY(d) | 返回日期值 d 的日期部分 |
|
| DAYNAME(d) | 返回日期 d 是星期几,如 Monday,Tuesday |
|
| DAYOFMONTH(d) | 计算日期 d 是本月的第几天 |
|
| DAYOFWEEK(d) | 日期 d 今天是星期几,1 星期日,2 星期一,以此类推 |
|
| DAYOFYEAR(d) | 计算日期 d 是本年的第几天 |
|
| EXTRACT(type FROM d) |
从日期 d 中获取指定的值,type 指定返回的值。 type可取值为:
|
|
| FROM_DAYS(n) | 计算从 0000 年 1 月 1 日开始 n 天后的日期 |
|
| HOUR(t) | 返回 t 中的小时值 |
|
| LAST_DAY(d) | 返回给给定日期的那一月份的最后一天 |
|
| LOCALTIME() | 返回当前日期和时间 |
|
| LOCALTIMESTAMP() | 返回当前日期和时间 |
|
| MAKEDATE(year, day-of-year) | 基于给定参数年份 year 和所在年中的天数序号 day-of-year 返回一个日期 |
|
| MAKETIME(hour, minute, second) | 组合时间,参数分别为小时、分钟、秒 |
|
| MICROSECOND(date) | 返回日期参数所对应的微秒数 |
|
| MINUTE(t) | 返回 t 中的分钟值 |
|
| MONTHNAME(d) | 返回日期当中的月份名称,如 November |
|
| MONTH(d) | 返回日期d中的月份值,1 到 12 |
|
| NOW() | 返回当前日期和时间 |
|
| PERIOD_ADD(period, number) | 为 年-月 组合日期添加一个时段 |
|
| PERIOD_DIFF(period1, period2) | 返回两个时段之间的月份差值 |
|
| QUARTER(d) | 返回日期d是第几季节,返回 1 到 4 |
|
| SECOND(t) | 返回 t 中的秒钟值 |
|
| SEC_TO_TIME(s) | 将以秒为单位的时间 s 转换为时分秒的格式 |
|
| STR_TO_DATE(string, format_mask) | 将字符串转变为日期 |
|
| SUBDATE(d,n) | 日期 d 减去 n 天后的日期 |
|
| SUBTIME(t,n) | 时间 t 减去 n 秒的时间 |
|
| SYSDATE() | 返回当前日期和时间 |
|
| TIME(expression) | 提取传入表达式的时间部分 |
|
| TIME_FORMAT(t,f) | 按表达式 f 的要求显示时间 t |
|
| TIME_TO_SEC(t) | 将时间 t 转换为秒 |
|
| TIMEDIFF(time1, time2) | 计算时间差值 |
|
| TIMESTAMP(expression, interval) | 单个参数时,函数返回日期或日期时间表达式;有2个参数时,将参数加和 |
|
| TO_DAYS(d) | 计算日期 d 距离 0000 年 1 月 1 日的天数 |
|
| WEEK(d) | 计算日期 d 是本年的第几个星期,范围是 0 到 53 |
|
| WEEKDAY(d) | 日期 d 是星期几,0 表示星期一,1 表示星期二 |
|
| WEEKOFYEAR(d) | 计算日期 d 是本年的第几个星期,范围是 0 到 53 |
|
| YEAR(d) | 返回年份 |
|
| YEARWEEK(date, mode) | 返回年份及第几周(0到53),mode 中 0 表示周天,1表示周一,以此类推 |
|
MySQL 高级函数
| 函数名 | 描述 | 实例 |
|---|---|---|
| BIN(x) | 返回 x 的二进制编码 |
15 的 2 进制编码: |
| BINARY(s) | 将字符串 s 转换为二进制字符串 |
|
|
CASE 表示函数开始,END 表示函数结束。如果 condition1 成立,则返回 result1, 如果 condition2 成立,则返回 result2,当全部不成立则返回 result,而当有一个成立之后,后面的就不执行了。 |
|
| CAST(x AS type) | 转换数据类型 |
字符串日期转换为日期: |
| COALESCE(expr1, expr2, …., expr_n) | 返回参数中的第一个非空表达式(从左向右) |
|
| CONNECTION_ID() | 返回唯一的连接 ID |
|
| CONV(x,f1,f2) | 返回 f1 进制数变成 f2 进制数 |
|
| CONVERT(s USING cs) | 函数将字符串 s 的字符集变成 cs |
|
| CURRENT_USER() | 返回当前用户 |
|
| DATABASE() | 返回当前数据库名 |
|
| IF(expr,v1,v2) | 如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2。 |
|
|
IFNULL(v1,v2) |
如果 v1 的值不为 NULL,则返回 v1,否则返回 v2。 |
|
| ISNULL(expression) | 判断表达式是否为 NULL |
|
| LAST_INSERT_ID() | 返回最近生成的 AUTO_INCREMENT 值 |
|
| NULLIF(expr1, expr2) | 比较两个字符串,如果字符串 expr1 与 expr2 相等 返回 NULL,否则返回 expr1 |
|
| SESSION_USER() | 返回当前用户 |
|
| SYSTEM_USER() | 返回当前用户 |
|
| USER() | 返回当前用户 |
|
| VERSION() | 返回数据库的版本号 |
|
算术运算符
MySQL 支持的算术运算符包括:
| 运算符 | 作用 |
|---|---|
| + | 加法 |
| – | 减法 |
| * | 乘法 |
| / 或 DIV | 除法 |
| % 或 MOD | 取余 |
比较运算符
SELECT 语句中的条件语句经常要使用比较运算符。通过这些比较运算符,可以判断表中的哪些记录是符合条件的。比较结果为真,则返回 1,为假则返回 0,比较结果不确定则返回 NULL。
| 符号 | 描述 | 备注 |
|---|---|---|
| = | 等于 | |
| <>, != | 不等于 | |
| > | 大于 | |
| < | 小于 | |
| <= | 小于等于 | |
| >= | 大于等于 | |
| BETWEEN | 在两值之间 | >=min&&<=max |
| NOT BETWEEN | 不在两值之间 | |
| IN | 在集合中 | |
| NOT IN | 不在集合中 | |
| <=> | 严格比较两个NULL值是否相等 | 两个操作码均为NULL时,其所得值为1;而当一个操作码为NULL时,其所得值为0 |
| LIKE | 模糊匹配 | |
| REGEXP 或 RLIKE | 正则式匹配 | |
| IS NULL | 为空 | |
| IS NOT NULL | 不为空 |
逻辑运算符
逻辑运算符用来判断表达式的真假。如果表达式是真,结果返回 1。如果表达式是假,结果返回 0。
| 运算符号 | 作用 |
|---|---|
| NOT 或 ! | 逻辑非 |
| AND | 逻辑与 |
| OR | 逻辑或 |
| XOR | 逻辑异或 |
位运算符
位运算符是在二进制数上进行计算的运算符。位运算会先将操作数变成二进制数,进行位运算。然后再将计算结果从二进制数变回十进制数。
| 运算符号 | 作用 |
|---|---|
| & | 按位与 |
| | | 按位或 |
| ^ | 按位异或 |
| ! | 取反 |
| << | 左移 |
| >> | 右移 |
+,约束
1,主键(非空唯一): primary key
2,无符号: unsigned
3,自动递增: auto_increment
4,查
+查询顺序:
Select *
From
Join
Where
Group
Order
Limit
+,分组
group by 字段名,字段名;
分组后数据筛选:select * from 表名 group by 字段名 ,字段名 having 条件,聚合函数;
+,聚合函数(不能再where后面)
count()
max()
min()
avg()
sum()
+,排序
order by 字段 asc,字段desc;
中文排序;order by convert(字段名 using gbk);
+,获取部分行:
select * from 表名 limit 起始位置(默认从0开始),个数;
+,分页: select * from 表名 limit (n-1)*m,m
+,使用 UNION 对两个查询结果取并集 查询的字段可以不一样,但是查询的字段数量要一样(A和B是两个字段, C和D是两个字段)
select columnA, columnB from table1 union select solumnC, columnD from table2;
1,内连接
select * from 表1 inner join 表2 on 表1.字段=表2.字段 where 条件;
2,左连接(匹配不到的显示null)
select * from 表1 left join 表2 on 表1.字段=表2.字段 where 条件
3,右连接(匹配不到的显示null)
select * from 表1 right join 表2 on 表1.字段=表2.字段 where 条件
4,自关联(表名必须起别名)
select * from 表1 inner join 表1 as 别名 on 表1.字段=别名.字段 where 条件
5,子查询
select * from 表名1 where 字段名1 = (select 字段名2 from 表名2 where 条件);
行子查询:
select * from students where (class,age) in
(select class,age from students where name =’王昭君’);
子查询充当数据源(必须起别名)
select * from
(select * from courses where name in (‘数据库’,’系统测试’)) as temp
inner join scores on
temp.courseno = scores.courseno;
6,备份:
Mysqldump.exe 是备份工具
Mysql的路径 mysqldump -u root -p 数据库名 > 要保存的文件名
7,恢复:
Mysql -u root -p 数据库名 < 要恢复的文件名
8,内置函数:
1,字符串函数:
1,拼接字符串: concat(str1,str2)
2,长度: length(str)
3,截取字符串:
left(str,len)
Right(str,len)
Substring(str,pos,len)
4,删除空格:
Ltrim(str)
Rtrim(str)
5,大小写转换:
Lower(str)
Upper(str)
2,数学函数
四舍五入: select rounnd(数字,小数位);
x的y次幂: select pow(x,y);
圆周率: select pi();
随机数: select rand();
3,日期时间函数
当前日期: current_date();
当前时间:current_time();
当前日期时间:now();
日期格式化:date_format(date,format)
%Y 返回完整年份
%y 返回简写年份
%m 月份
%d 天
%H 24小时制
%h 12小时制
%i 分钟
%s 秒
9,流程控制
Case 值
when 比较值1 then 结果1
when 比较值2 then 结果2…
else 结果3 end
10,操作日志
show variables like ‘general%’; 查看日志 是否开启
set global general_log =1; 设置开启日志(0是关闭,1是开启)
tail -f var/log/mysql/mysql.log 实时查看数据库日志
11,重置密码
1打开my.ini 修改 找到[mysqld] 插入skip-grant-tables
2重启mysql服务 sudo service mysql restart;
3免密登录服务端
4设置新密码Update user set password=password(‘123456’); flush privileges;
5修改配置文件,删除skip-grant-tables,重启服务端
12,修改密码:
在mysql仓库user表中
Update user set password=password(‘123456’);
flush privileges;
13,事物:是一个操作序列,要么都成功,要么都失败
事物命令要求:服务器引擎是innodb
1,开启事务 begin;
事物操作
2,提交事物 commit;
3,回滚 rollback; (失败时使用)
14,索引:
作用:提升查询速度,降低更新表的速度
查询:
开启运行时间检测 set profiling=1;
查找第一万条数据 select * from test_index where title=’test10000’;
查看执行时间 show profiles;
为表test_index的title列创建索引 create index title_index on test_index(title(10));
执行查询语句 select * from test_index where title=’test10000’;
查看执行时间 show profiles;
删除索引 drop index 索引名 on 表名;
注意:给某个字段创建索引,相当于给他创建了目录,根据有索引的字段查询时速度要快
创建索引:
方式一新建表
设置主键 唯一 和建表的时候加入key(列)都可以创建索引
方式二已存在的表
创建索引
15,外键
作用:一个表中的某个字段的数据被另一个表的某一个字段约束,字段的值必须在另一个表的字段数据范围之内.
缺点:会降低表更新的效率
16,视图
语法:Create view 视图名 as select语句;
注意:创建视图时,select语句的返回结果不能有重复的字段.
视图的用途就是查询
作用:存在服务端,省流量,重复利用
Show tables; 显示视图
Drop view 视图名; 删除视图
17,自定义函数:
语法格式:
Delimiter 分隔符
Create function 函数名(参数列表)
Returns 返回类型
Begin
Sql 语句
end
Delimiter 分隔符
事务
/*
事务:主要用于处理操作量大,复杂度高的数据
事务的acid属性
1,原子性:事务时一个不可分割的单位,事务中的操作要么都执行,要么都不执行。
2,一致性:事务必须使数据库从一个一致性状态到另一个一致性状态。
3,隔离性:一个事务的执行不能被其他事务干扰。
4,持久性:事务一旦被提交,对数据库中的数据的修改时永久性的。
在 MySQL 中只有使用了 Innodb 数据库引擎的数据库或表才支持事务
事务默认是自动提交的。
像insert/update/delete 都是隐式事务
*/
-- 查看事务开启状态
show varailes like "%autocommit%";
-- 修改事务状态
set autocommit on/off;
变量
/*
设置的全局变量在数据库重启后回复默认值/重置
*/
-- 系统变量
-- 查看所有系统变量
show global variables
show global variables like '%user%'
-- 设置变量
set global 系统变量名= 值
-- 查询系统变量的值
select @@global.系统变量名
select @@global.autocommit;
-- 会话变量,在当前会话有效
-- 会话变量可以省略sission
show variables
show variables like '%user%'
-- 设置变量
set session 会话变量名= 值
-- 查询会话变量的值
select @@session.会话变量名
select @@session.autocommit;
select @@autocommit;
-- 自定义变量
-- 用户变量,对当前会话有效
-- 声明用户变量并初始化
set @用户变量名=值;
set @用户变量名:=值;
select @用户变量名:=值;
-- 赋值
set @用户变量名=值;
set @用户变量名:=值;
select @用户变量名:=值;
select 字段 into 变量名 from 表;
-- 查询
select @用户变量名
-- 局部变量,仅在begin end中有效
-- 定义
declare 变量名 数据类型;
declare 变量名 数据类型 default 值;
-- 赋值
select 字段 into 局部变量名 from 表;
-- 查询
select 变量名
存储过程
-- 存储过程
/* 格式
delimiter $
create procedure 存储过程名(参数模式 参数名 参数类型)
begin
存储过程体(一组合法的sql语句)
end $
-- 参数模式:
in: 指定该参数可以作为输入;
out: 指定该参数可以作为输出;
inout: 指定该参数可以作为输入输出。
-- 存储过程体 可以是一条或者多条sql语句;
-- 每条sql语句后都加 ;号;
-- 存储过程结尾使用 delimiter重写过的结尾标记。
*/
-- 删除存储过程
drop procedure 存储过程名;
-- 查看存储过程
show create procedure 存储过程名;
-- ----------------------------------------------------
-- 调用存储过程
call 存储过程名(实参列表);
delimiter ; # 恢复结尾标记
-- 不带参数的存储过程
delimiter $
create procedure testa()
begin
insert into test0(`name`, `age`) values('a', 1),('b', 2);
end $
call testa();
-- ----------------------------------------------------
-- 带输入参数的存储过程
delimiter $
create procedure testb(in user_age int)
begin
select * from test0 where age > user_age;
end $
call testb(10);
-- ----------------------------------------------------
-- 存储过程中使用变量
delimiter $
create procedure testc(in age int)
begin
declare result varchar(20) default ''; # 声明并初始化变量
select count(*) into result # 使用into给变量赋值
from test0
where test0.age > age;
select if(result > 0, '有', '没有'); # 调用变量 查询输出结构
end $
call testc(100);
-- ----------------------------------------------------
-- 存储过程中使用out参数
delimiter $
create procedure testd(out age int)
begin
select count(*) into age # 使用into给变量赋值
from test0
where test0.age > 10;
end $
-- 调用带输入参数的存储过程
call testd(@test_variable0); # 使用@+变量名设置一个新的变量,用户接受数据
select @test_variable0; # 查询变量数据信息
-- ----------------------------------------------------
-- inout类型参数存储过程
delimiter $
create procedure teste(inout a int, inout b int)
begin
set a=a*10;
set b=b*10;
end $
-- 先设置全局变量,使用全局变量调用存储过程,最后查询
set @a=2;
set @b=3;
call teste(@a, @b);
select @a a, @b b;
if(条件,满足的结构,不满足的结果)
-- case语句 可以嵌套在其他语句中 也可以直接使用
-- 使用方式一 case后面跟参数/表达式 when 后面直接填值
case 变量/表达式/字段
when 要判断的值 then 返回的值
when 要判断的值 then 返回的值
...
else 返回的值
end
-- 使用方式二 case后面不带参数,when 后面跟条件
case
when 要判断的条件 then 返回的值
when 要判断的条件 then 返回的值
...
else 返回的值
end
-- case在存储过程中使用
delimiter $
create procedure testf(in input_num int)
begin
case
when input_num between 90 and 100 then select 'A';
when input_num between 80 and 90 then select 'B';
when input_num between 70 and 80 then select 'C';
when input_num between 60 and 70 then select 'D';
else select 'xx';
end case;
end $
call testf(90)
drop procedure testf
-- if 在存储过程中使用
delimiter $
create procedure testg(in input_num int)
begin
if input_num = 0 then select input_num;
elseif input_num > 0 then select 1;
elseif input_num < 0 then select -1;
else select -2;
end if;
end $
call testg(0)
-- 循环
delimiter $
create procedure testh(in input_num int)
begin
declare i int default 0;
while input_num >=i do
insert into test0 values(default, concat('jack', input_num), input_num);
set input_num=input_num-1;
end while;
end $
call testh(5)
-- 循环内判断
delimiter $
create procedure testi(in input_num int)
begin
declare i int default 0;
a:while input_num >=i do
if input_num - i > 50 then leave a;
end if;
insert into test0 values(default, concat('jack', input_num), input_num);
set input_num=input_num-1;
end while a;
end $
call testi(90)
函数
-- 函数
-- 创建函数
create function 函数名(参数名 参数类型, 参数名 参数类型) returns 返回值类型
begin
函数体
return 返回值;
end
-- 调用函数
select 函数名(参数);
-- 创建不带变量的函数
delimiter $
create function func1() returns int
begin
declare result int default 0;
select count(*) into result
from test0
where test0.age > 10;
return result;
end $
select func1()
-- 创建带变量的函数
delimiter $
create function func2(uname varchar(20)) returns int
begin
set @result=0;
select test0.age into @result
from test0
where test0.name = uname;
return @result;
end $
-- 调用函数
select func2('zhangsan')
-- 删除函数
drop function func2
/*
创建函数时报错
这是我们开启了bin-log, 我们就必须指定我们的函数是否是
1 DETERMINISTIC 确定性的
2 NO SQL 没有SQl语句,当然也不会修改数据
3 READS SQL DATA 只是读取数据,当然也不会修改数据
4 MODIFIES SQL DATA 要修改数据
5 CONTAINS SQL 包含了SQL语句
解决方法:
select @@global.log_bin_trust_function_creators
set global log_bin_trust_function_creators=TRUE;
*/
类型转换
CAST函数语法规则是:Cast(字段名 as 转换的类型 ),其中类型可以为:
CHAR[(N)] 字符型
DATE 日期型
DATETIME 日期和时间型
DECIMAL float型
SIGNED int
TIME 时间型
-- 插入卡片数量
delimiter $
create procedure insert_activity_card_detail(in userid int, in card int)
begin
INSERT INTO activity_card_detail
VALUES (default, userid, 60, concat('card_', cast(card as char)), CURRENT_TIMESTAMP(), 1, card, CURRENT_TIMESTAMP(), 0);
end $替换同一张表里的两个字段的数据
update your_table as a, your_table as b
set a.field1= b.field2, a.field2= b.field1
where a.actor_id = b.actor_id
需求:统计每隔10分钟的数据量
-- UNIX_TIMESTAMP 将时间转为时间戳,
-- 该时间戳对一个时间值(每10分钟就是 10*60,每5分钟就是 5*60)取模,得到的余数就是比最终要获得的时间值多的秒数,
-- 用时间戳减去时间值的余数就是每X分钟的时间值了,
-- 然后使用FROM_UNIXTIME 将时间戳转换为格式化字符串时间
select FROM_UNIXTIME(UNIX_TIMESTAMP(bind_phone_time) - UNIX_TIMESTAMP(bind_phone_time) % (10 * 60)) as aaa, count(1)
from share_activity_invitee
group by aaa
order by aaa desc
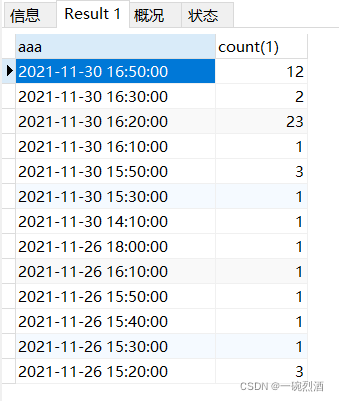
下面来看下区别
select
UNIX_TIMESTAMP(bind_phone_time) '时间戳',
UNIX_TIMESTAMP(bind_phone_time) % (10 * 60) '时间戳对一个时间段取模(取余数)',
UNIX_TIMESTAMP(bind_phone_time) - (UNIX_TIMESTAMP(bind_phone_time) % (10 * 60)) '最终要获得的每隔X分钟的时间',
FROM_UNIXTIME(UNIX_TIMESTAMP(bind_phone_time) - (UNIX_TIMESTAMP(bind_phone_time) % (10 * 60))) '格式化时间'
from
share_activity_invitee
部分数据来源:
MySQL 教程 | 菜鸟教程