最近研究python爬虫,按照网上资料实现了python爬虫爬取糗事百科,做个笔记。
分享几个学习python爬虫资料:
廖雪峰python教程
主要讲解python的基础编程知识
python开发简单爬虫
通过一个实例讲解python爬虫的整体结构
python正则表达式
讲解爬虫中匹配中所需要的正则表达式
python爬虫系列教程
几个训练的实例
简单爬虫的架构

爬虫的运行流程
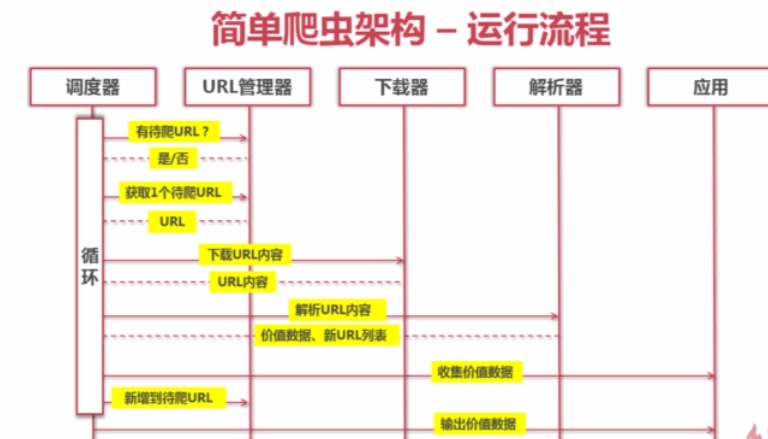
下面按照教程中的讲解实现python爬虫爬取糗事百科
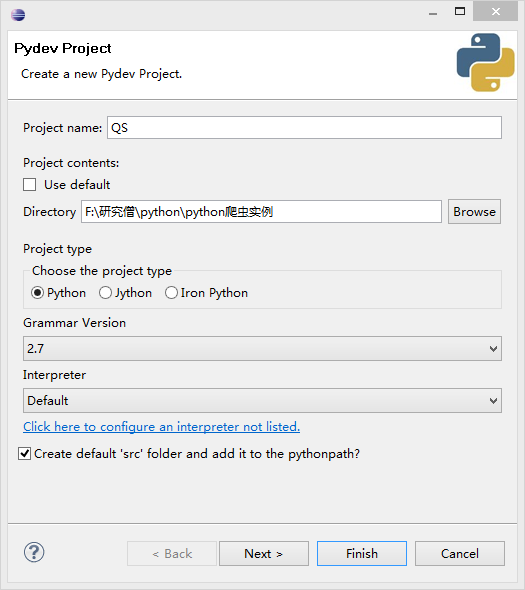
新建工程
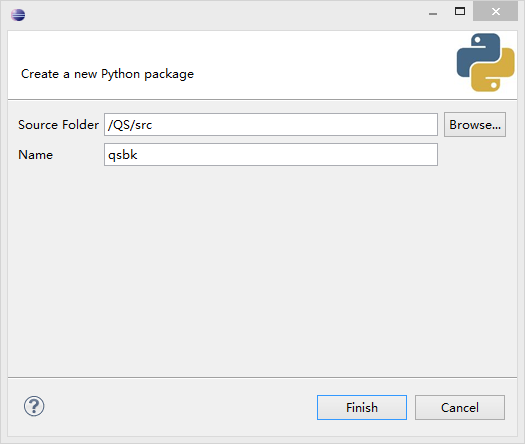
新建pydev package
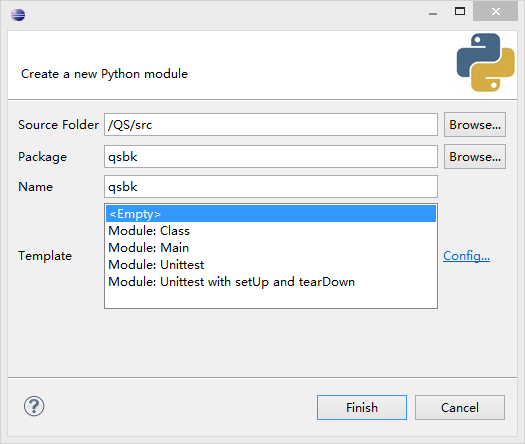
新建pydev module
编辑代码:
import urllib2
import re
class QSBK:
def __init__(self):
self.pageIndex =2
self.user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
self.headers = { 'User-Agent' : self.user_agent }
self.stories = []
self.enable = False
def getPage(self,pageIndex):
try:
url = ' http://www.qiushibaike.com/hot/page/' + str(pageIndex)
request = urllib2.Request(url,headers = self.headers)
response = urllib2.urlopen(request)
pageCode = response.read().decode('utf-8')
return pageCode
except urllib2.URLError, e:
if hasattr(e,"reason"):
print u"连接糗事百科失败,错误原因",e.reason
return None
def getPageItems(self,pageIndex):
pageCode = self.getPage(pageIndex)
if not pageCode:
print "页面加载失败...."
return None
pattern = re.compile(r'<div.*?class="author.*?>.*?<a.*?</a>.*?<a.*?>(.*?)</a>.*?<div.*?class'+
'="content".*?>(.*?)</div>(.*?)<div class="stats.*?class="number">(.*?)</i>',re.S)
items = re.findall(pattern,pageCode)
pageStories = []
for item in items:
replaceBR = re.compile('<br/>')
text = re.sub(replaceBR,"\n",item[1])
pageStories.append([item[0].strip(),text.strip(),item[2].strip(),item[3].strip()])
return pageStories
def loadPage(self):
if self.enable == True:
if len(self.stories) < 2:
pageStories = self.getPageItems(self.pageIndex)
if pageStories:
self.stories.append(pageStories)
self.pageIndex += 1
def getOneStory(self,pageStories,page):
for story in pageStories:
input = raw_input()
self.loadPage()
if input == "Q":
self.enable = False
return
print u"第%d页\t发布人:%s\t赞:%s\n%s" %(page,story[0],story[3],story[1])
def start(self):
print u"正在读取糗事百科,按回车查看新段子,Q退出"
self.enable = True
self.loadPage()
nowPage = 0
while self.enable:
if len(self.stories)>0:
pageStories = self.stories[0]
nowPage += 1
del self.stories[0]
self.getOneStory(pageStories,nowPage)
spider = QSBK()
spider.start()
运行结果:

对于不同的网页,请右键“审查元素”查看网页代码,修改一下正则表达式