使用CNN-LSTM搭建一个简单的回归预测模型,对油耗数据进行预测分析
首先导入必要的包,主要用到numpy,pandas,matplotlib和tensorflow下面的一些网络模型。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.utils import plot_model
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Dense, Dropout,Flatten,Activation,LSTM
from sklearn.preprocessing import MinMaxScaler
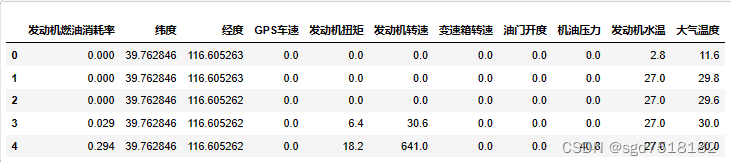
采用pandas读取数据,数据集部分展示如下,其中以发动机燃油消耗率为目标值,其余变量为特征值。
数据预处理,数据集进行归一化处理。
X = data.iloc[:,1:11]
Y = data.iloc[:,0:1]
X_transfer = MinMaxScaler()
X_transfer = MinMaxScaler()
x_MM = transfer.fit_transform(x)
Y_MM = transfer.fit_transform(Y)
归一化后数据由Datafram格式转换为ndarray格式,归一化后的数据展示如下

归一化完成后对数据集进行切分,采用SKlearn下面的train_test_splist方法对数据进行切分,按照3:1的比例划分训练集和测试集。
x_train, x_test, Y_train, Y_test = train_test_split(X_MM, Y_MM, test_size=0.25, random_state=10,shuffle=False)
数据集划分完毕后,对特征数据添加时间步长,由于本数据集采用单步预测,故不用特别定义时间步长函数来构造时间滑窗,直接使用numpy的reshape方法即可。
X_train = x_train.reshape(x_train.shape[0], 1, x_train.shape[1])
X_test= x_test.reshape(x_test.shape[0], 1, x_test.shape[1])添加时间步长之后的特征数据形状如下。
![]()
以上完成了对数据的基本处理,数据处理完毕之后,开始模型的搭建。构建一个由一维卷积层和LSTM组合而成的CNN-LSTM神经网络。网络代码如下。
#搭建CNN-LSTM融合神经网络
model = Sequential()
model.add(Conv1D(filters=32, kernel_size=3, padding='same', strides=1,
activation='relu', input_shape=(X_train.shape[1], X_train.shape[2]))) # input_shape=(X_train.shape[1], X_train.shape[2])
model.add(MaxPooling1D(pool_size=1))
model.add(LSTM(16, return_sequences=True))
model.add(LSTM(8, return_sequences=False))
model.add(Dense(1))
model.compile(loss='mse', optimizer='adam')
网络搭建完成之后,对网络进行拟合训练。
# 拟合网络
history = model.fit(X_train, Y_train, epochs=100, batch_size=256, shuffle=False,validation_data=(X_test,Y_test)可以看到训练过程,还是效果还是非常好的.

训练完整之后对模型进行测试集和验证集预测。
#在训练集和测试集上的拟合结果
Y_train_predict_CNN_LSTM= model.predict(X_train)
Y_test_predict_CNN_LSTM= model.predict(X_test)
#反归一化
Y_train_predict_CNN_LSTM_inver = X_transfer .inverse_transform(Y_train_predict_CNN_LSTM)
Y_test_predict_CNN_LSTM_inver = X_transfer .inverse_transform(Y_test_predict_CNN_LSTM)
Y_train_inver = transfer_y.inverse_transform(Y_train)
Y_test_inver = transfer_y.inverse_transform(Y_test)输出模型评价指标。
#输出结果
from sklearn.metrics import mean_absolute_error,mean_squared_error,r2_score
print('CNN-LSTM训练集上的MAE/MSE/r2')
print(mean_absolute_error(Y_train_predict_CNN_LSTM_inver,Y_train_inver))
print(mean_squared_error(Y_train_predict_CNN_LSTM_inver,Y_train_inver) )
print(r2_score(Y_train_predict_CNN_LSTM_inver,Y_train_inver) )
print('CNN-LTSM测试集上的MAE/MSE/r2')
print(mean_absolute_error(Y_test_predict_CNN_LSTM_inver, Y_test_inver))
print(mean_squared_error(Y_test_predict_CNN_LSTM_inver, Y_test_inver))
print(r2_score(Y_test_predict_CNN_LSTM_inver, Y_test_inver))

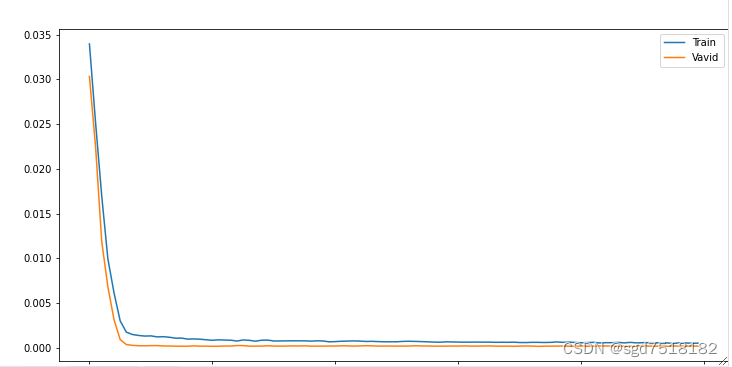
绘制训练Loss曲线。
# 绘制图像
plt.figure(1,figsize=(12,6),dpi=80)
plt.plot(history.history['loss'], label='Train')
plt.plot(history.history['val_loss'], label='Vavid')
plt.title('loss curve')
plt.legend()
plt.show()
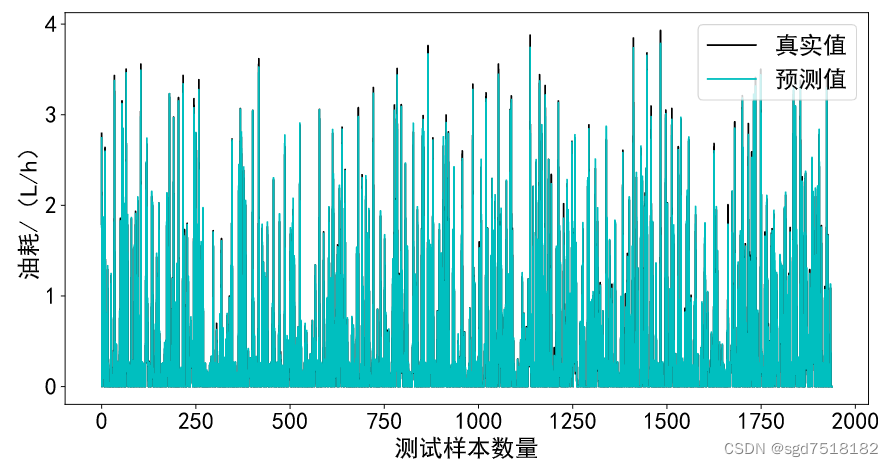
绘制真实值和预测值对比图。
plt.figure(2,figsize=(12,6),dpi=80)
plt.plot(range(len(Y_test_inver)),Y_test,color='k',label='真实值')
plt.plot(range(len(Y_test_CNN_LSTM_inver)),Y_test_predict_CNN_LSTM_inver,color='',label='预测值')
plt.xlabel('测试样本数量',fontsize=20)
plt.ylabel('油耗/(L/h)',fontsize=20)
plt.tick_params(labelsize=20)
plt.legend(fontsize=20)
plt.savefig("真实值和预测值对比.svg", dpi=80,format="svg")
plt.show()
需要完整代码以及咨询问题的加qq:1019312261,智能算法的改进,智能算法与神经网络结合等等。