目录
View 使用后端数据对前端页面进行渲染,获取渲染之后的html
Control 逻辑控制模块,oj_server.cc直接调用Control提供的方法
总览
简述
此项目,旨在设计出一款类似于leetcode的在线OJ平台,通过浏览器客户端获取服务端提供的http服务。主要提供的功能有两个: 1. 获取题目列表 2. 获取指定题目的详细信息,并获取一个在线编辑器,用于提交代码,提交后显示出此题的提交结果: 编译错误 / 运行时出错(程序崩溃) / 编译运行成功但没有通过测试用例 / 编译运行成功且通过测试用例
项目核心的三个模块
1. common 公共模块 : 用于提供一些第三方库文件,一些工具类,工具方法。
2. compile_server 编译与运行模块 : 通过提供网络服务的方式,获取通过网络请求发送来的源代码,仅提供编译运行功能,并将编译运行的结果通过网络返回回去。
3. oj_server 在线OJ模块 : 提供http服务,如获取题目列表,进入指定题目的OJ界面,负载均衡。
综上,common就是提供一些工具方法,用于另外两个模块使用。而oj_server相当于是一个在线oj平台的后端服务器,提供http服务,当用户获取列表,编写指定题目之后,将前端代码通过http请求发送给oj_server时,oj_server通过网络请求,负载均衡式地使用compile_server提供的编译运行服务,获取编译运行结果,再返回给用户的前端界面。
项目宏观结构

compile_server 编译与运行服务
总览分析
compile_server模块旨在实现出一个通过网络请求的方式,提供编译并运行服务的后端。在此项目中此功能用于服务oj_server编译并运行用户提交的oj代码。注意:此模块,仅提供编译运行功能,提交的代码是否通过测试用例,此模块不负责。
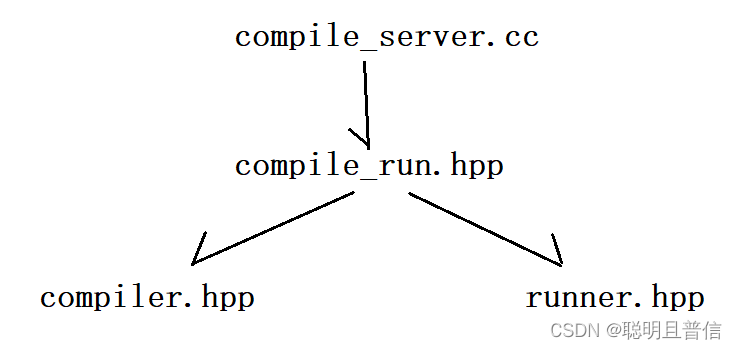
compiler.hpp提供编译服务,runner.hpp提供运行服务。compile_run.hpp整合下方两个功能,提供一个编译并运行功能的接口。而compile_server.cc通过网络请求,获取代码,调用compile_run.hpp提供的的接口。
这里有一个注意点:将来,oj_server模块,将用户提交的代码通过网络请求给compile_server,大体思路是:此模块创建临时文件,将代码写入文件中,也就成为了源文件。下方对源文件进行编译运行,此处文件名等并不重要,我们的目的是编译运行获取结果。那么,如何让compiler.hpp和runner.hpp对正确的源文件进行编译,和对正确的可执行程序进行运行呢?只要统一他们的文件名即可(不包含后缀)
compiler.hpp
#pragma once
#include <iostream>
#include <string>
#include <unistd.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include "./../common/util.hpp"
#include "../common/log.hpp"
// 只负责进行代码的编译
namespace ns_compiler
{
using namespace ns_util;
using namespace ns_log;
class Compiler
{
public:
// 返回值: 编译成功true,编译失败false
// 输入参数: 编译的文件名(不带路径,不带后缀)
static bool compile(const std::string &file_name)
{
// 程序替换为g++编译,成功则没有输出,可执行程序生成
// 失败则g++会向标准错误中输出错误信息,即编译失败的原因
pid_t pid = fork();
if (pid < 0)
{
LOG(ERROR) << "内部错误,编译时创建子进程失败" << std::endl;
return false;
}
else if (pid == 0)
{
// 子进程,进行程序替换g++,编译指定文件
umask(0);
int _compile_error_fd = open(PathUtil::CompileError(file_name).c_str(), O_CREAT | O_WRONLY, 0644);
if (_compile_error_fd < 0)
{
LOG(WARNING) << "内部错误, 编译时没有生成stderr文件" << std::endl;
exit(1); // 其实父进程不关心
}
// 程序替换,并不影响进程的文件描述符表
dup2(_compile_error_fd, 2);
execlp("g++", "g++", "-o", PathUtil::Exe(file_name).c_str(),
PathUtil::Src(file_name).c_str(), "-D", "COMPILE_ONLINE", "-std=c++11", nullptr);
exit(2); // 其实父进程不关心
}
else
{
// 父进程
waitpid(pid, nullptr, 0); // 不关心子进程的退出结果,只关心是否编译成功(exe是否生成)
// std::cout << "flag" << std::endl;
if (FileUtil::IsFileExists(PathUtil::Exe(file_name)) == true)
{
// 可执行程序已生成,编译成功
// std::cout << "flag 2" << std::endl;
LOG(INFO) << PathUtil::Src(file_name) << "编译成功!" << std::endl;
return true;
}
}
// 可执行程序没有生成,g++错误信息已打印到CompileError文件中。
return false;
}
};
}Compiler类提供编译功能接口,对参数传来的指定的文件(不包含后缀,路径),进行编译。编译成功返回true,对应的可执行生成。失败返回false,编译错误原因在对应的CompileError文件中。
思路:要编译,肯定要程序替换为g++,思路是让子进程进行程序替换,替换为g++,父进程通过对应的可执行是否生成来判断是否编译成功。编译失败时,g++会向标准错误中输出错误信息,标准错误原本为显示器,现通过dup2系统调用,将其重定向至CompileError文件中,则若编译失败,失败原因会在对应的CompileError文件中保存。
注意: 在编译运行模块中,会出现很多临时文件,也就是对应某一次编译运行请求所生成的源文件,编译错误文件,可执行等等。此处的策略为,在compile_server编译运行模块下下创建一个temp目录,用于存储临时文件。
runner.hpp
#pragma once
#include <string>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <sys/wait.h>
#include <sys/time.h>
#include <sys/resource.h>
#include <fcntl.h>
#include "../common/util.hpp"
#include "../common/log.hpp"
namespace ns_runner
{
using namespace ns_util;
using namespace ns_log;
// 只负责运行编译好的可执行
class Runner
{
public:
/* 返回值 > 0,oj程序运行异常,收到了信号,返回值为信号编号
* 返回值 = 0,oj程序运行成功,标准输出和标准错误信息在对应的文件中
* 返回值 < 0,内部错误。如打开文件失败,创建子进程执行oj程序时失败。
* cpu_limit: file_name程序运行时,可以使用的CPU资源上限(时间,秒)
* mem_limit: file_name程序运行时,可以使用的内存资源上限(KB)
*/
static int run(const std::string file_name, int cpu_limit, int mem_limit)
{
std::string _excute = PathUtil::Exe(file_name);
std::string _stdin = PathUtil::Stdin(file_name);
std::string _stdout = PathUtil::Stdout(file_name);
std::string _stderror = PathUtil::Stderror(file_name);
// 运行程序,程序的输入,输出,错误信息进行重定向的文件
umask(0);
int _stdin_fd = open(_stdin.c_str(), O_CREAT | O_RDONLY, 0644); // 不处理,便于扩展
int _stdout_fd = open(_stdout.c_str(), O_CREAT | O_WRONLY, 0644); // OJ程序的输出结果
int _stderror_fd = open(_stderror.c_str(), O_CREAT | O_WRONLY, 0644); // OJ程序的运行时错误信息
if (_stdin_fd < 0 || _stdout_fd < 0 || _stderror_fd < 0)
{
LOG(ERROR) << "内部错误,运行时打开文件失败" << std::endl;
return -1; // 代表打开文件失败
}
pid_t pid = fork();
if (pid < 0)
{
LOG(ERROR) << "运行时创建子进程失败" << std::endl;
close(_stdin_fd);
close(_stdout_fd);
close(_stderror_fd);
return -2; // 代表创建子进程失败
}
else if (pid == 0)
{
// 子进程进行程序替换,执行可执行程序
dup2(_stdin_fd, 0);
dup2(_stdout_fd, 1);
dup2(_stderror_fd, 2);
SetProcLimit(cpu_limit, mem_limit);
execl(_excute.c_str(), _excute.c_str(), nullptr);
exit(1);
}
else
{
close(_stdin_fd);
close(_stdout_fd);
close(_stderror_fd);
// 父进程获知程序的执行情况,仅关心成功执行or异常终止
// 对于成功执行之后的执行结果并不关心,是上层的任务,需要根据测试用例判断
int status = 0;
waitpid(pid, &status, 0);
LOG(INFO) << "OJ题运行完毕, 退出信号: " << (status & 0x7F) << std::endl;
return status & 0x7F; // 将子进程的退出信号返回(并非退出码)
}
}
// 设置进程占用资源大小的接口(CPU资源,内存资源)mem_limit的单位为KB
static void SetProcLimit(int _cpu_limit, int _mem_limit)
{
// 设置进程占用CPU时长限制
struct rlimit cpu_rlimit;
cpu_rlimit.rlim_max = RLIM_INFINITY;
cpu_rlimit.rlim_cur = _cpu_limit;
setrlimit(RLIMIT_CPU, &cpu_rlimit);
// 设置进程占用内存资源限制
struct rlimit mem_limit;
mem_limit.rlim_max = RLIM_INFINITY;
mem_limit.rlim_cur = _mem_limit * 1024; // 转化为KB
setrlimit(RLIMIT_AS, &mem_limit);
}
};
}参数:要执行的可执行程序的文件名(不包含路径,后缀),cpu限制,mem限制(OJ题一般会有时间空间限制)。程序执行结果,通过返回值进行判断,大于0,为程序异常终止(收到了信号),等于0,为程序运行成功,此时,标准输出和标准错误信息都在对应的文件中。小于0,为内部错误,如打开文件失败,创建子进程失败等等…
这里思路和compiler.hpp相似,让子进程进行程序替换,执行可执行(在temp目录下,也就是编译模块编译好的可执行),父进程通过waitpid,阻塞式等待子进程退出结果,通过信号判断其运行情况。若崩溃,则信号大于0,此时不考虑标准输出和标准错误。若等于0,则信号为0,表示程序运行成功,此时标准输出和标准错误在对应文件中。这里的关键其实还是,重定向,也就是子进程程序替换为可执行前要dup2,将标准输入输出错误进行重定向(此处不考虑输入),对应的临时文件在temp目录下。
compile_run.hpp
// 需定制通信协议
#pragma once
#include "../compile_server/compiler.hpp"
#include "../compile_server/runner.hpp"
#include "../common/log.hpp"
#include "../common/util.hpp"
#include "jsoncpp/json/json.h"
namespace ns_compile_run
{
using namespace ns_compiler;
using namespace ns_runner;
using namespace ns_log;
using namespace ns_util;
class CompileAndRun
{
public:
/***************************************
* 应用层协议定制:
* 输入json串:
* code: 用户提交的OJ代码
* input: 用户提交的代码对应的输入(不做处理)
* cpu_limit: OJ程序的时间要求
* mem_limit: OJ程序的空间要求
*
* 输出json串:
* 必填:
* status: 状态码
* reason: 请求结果(状态码描述)
* 选填:(当OJ程序编译且运行成功时)
* stdout: OJ程序运行完的标准输出结果
* stderr: OJ程序运行完的标准错误结果
* (若编译且运行成功out_json中才会有stdout和stderr字段)
* 参数:
* in_json: {"code": "#include...", "input": "","cpu_limit":1, "mem_limit":10240}
* out_json: {"status":"0", "reason":"","stdout":"","stderr":"",}
* ************************************/
static void execute(const std::string &in_json, std::string *out_json)
{
// 随便写写:输入的json串中有代码,输入,时间空间限制等等
// 提取出代码,写入到源文件中。
// 编译源文件,看编译结果
// 若编译成功,则运行可执行
// 若一切顺利则status状态码为0,对应的输出结果也写入
// 若某一步出现了错误,则status设置为对应的数字
// reason也写好
// 对json串进行反序列化
Json::Value in_value;
Json::Reader reader;
reader.parse(in_json, in_value);
// 提取出编译运行所需的数据
std::string code = in_value["code"].asString();
std::string input = in_value["input"].asString();
int cpu_limit = in_value["cpu_limit"].asInt();
int mem_limit = in_value["mem_limit"].asInt();
int status = 0; // 状态码,最终要写入到out_json中
std::string file_name;
int run_result = 0;
if (code.empty())
{
status = -1; // 用户输入的OJ代码为空(非服务端问题)
goto END;
}
file_name = FileUtil::UniqueFileName();
// 形成临时源文件,代码为传来的code,这个文件名不重要,唯一即可
// 我们的目的是编译并运行这份代码
if (FileUtil::WriteFile(PathUtil::Src(file_name), code) == false)
{
status = -2; // 未知错误
goto END;
}
if (Compiler::compile(file_name) == false)
{
status = -3; // 编译失败,跳过后面的运行
goto END;
}
run_result = Runner::run(file_name, cpu_limit, mem_limit);
if (run_result < 0)
{
status = -2; // 未知错误(不管run内部是打开文件失败还是创建子进程失败,统一称之为内部错误,即服务端错误)
}
else if (run_result > 0)
{
status = run_result; // 运行错误,程序崩溃,此时status为程序退出信号
}
else
{
status = 0; // 运行成功(且编译成功)
}
END:
Json::Value out_value;
out_value["status"] = status; // 状态码
out_value["reason"] = StatusToDesc(status, file_name); // 状态码描述
if (status == 0)
{
// 只有当编译且运行成功时,才有stdout stderr字段
std::string _stdout;
FileUtil::ReadFile(PathUtil::Stdout(file_name), &_stdout, true); // 读取OJ程序的标准输出结果
out_value["stdout"] = _stdout;
std::string _stderr;
FileUtil::ReadFile(PathUtil::Stderror(file_name), &_stderr, true); // 读取OJ程序的标准错误结果
out_value["stderr"] = _stderr;
}
Json::StyledWriter writer;
*out_json = writer.write(out_value); // 将out_value进行序列化
// RemoveTempFile(file_name);
}
static std::string StatusToDesc(int status, const std::string &file_name)
{
// 将状态码转化为状态码描述
std::string desc;
switch (status)
{
case 0:
desc = "编译且运行成功";
break;
case -1:
desc = "用户输入的代码为空";
break;
case -2:
desc = "未知错误"; // 服务端错误,太羞耻了
break;
case -3:
// 代码编译时发生错误,返回编译错误原因
FileUtil::ReadFile(PathUtil::CompileError(file_name), &desc, true);
break;
case SIGABRT: // 6
desc = "程序占用内存资源超限";
break;
case SIGXCPU: // 24
desc = "程序占用CPU资源超限";
break;
case SIGFPE: // 8
desc = "浮点数溢出";
break;
default:
desc = "未知: " + std::to_string(status);
break;
}
return desc;
}
static void RemoveTempFile(const std::string &file_name)
{
// 有哪些文件生成不确定,但是文件名是有的,一共6个可能生成的临时文件,逐一检查。
if (FileUtil::IsFileExists(PathUtil::Src(file_name)) == true)
unlink(PathUtil::Src(file_name).c_str());
if (FileUtil::IsFileExists(PathUtil::CompileError(file_name)) == true)
unlink(PathUtil::CompileError(file_name).c_str());
if (FileUtil::IsFileExists(PathUtil::Exe(file_name)) == true)
unlink(PathUtil::Exe(file_name).c_str());
if (FileUtil::IsFileExists(PathUtil::Stdin(file_name)) == true)
unlink(PathUtil::Stdin(file_name).c_str());
if (FileUtil::IsFileExists(PathUtil::Stdout(file_name)) == true)
unlink(PathUtil::Stdout(file_name).c_str());
if (FileUtil::IsFileExists(PathUtil::Stderror(file_name)) == true)
unlink(PathUtil::Stderror(file_name).c_str());
}
};
}整合编译和运行功能,提供一个编译并运行的接口。注意,此接口直接被compile_server调用,compile_server提供网络服务,应用层协议为http协议。传来一个json串,返回一个json串。而json串的内容就属于这里需要定制的应用层协议的一部分。
传来的json中包含code(需要编译运行的源代码),input(仅象征性地设置一个这个字段,不考虑,也就是未来的OJ题没有输入),cpu_limit,mem_limit(回顾runner的接口参数)。注意,这里传来code,但是没有源文件,我们需要生成唯一的文件名,根据文件名生成源文件,将code写入。后面的编译错误,可执行,标准输出错误等文件的文件名都是这里设定的,文件名随意,唯一即可。
返回的json中包含状态码,状态码描述。可能包含标准输出和标准错误(当编译且运行成功时有这两个字段)
通过调用编译和运行模块的接口,最终,通过合理的设计,若状态码>0,则运行时错误,状态码为对应的信号。状态码=0,则编译且运行成功,此时需要读取标准输出和标准错误文件,添加到对应的out_json的字段中。状态码<0,对应各种情况,当=-3时,为编译失败,则编译错误原因在对应CompileError文件中,此时没有可执行生成,不会执行运行模块方法。添加了一个StatusToDesc方法,也就是状态码转状态码描述。若编译失败,状态码为-3,则状态码描述为编译失败的原因。
整体的设计非常巧妙,通过不同的返回值得到编译或者运行结果。而整体,编译运行服务只接收代码(当然还包含其他字段,如cpu_limit, mem_limit),一次编译运行的所有的临时文件的文件名是统一且唯一的。我们的目的是为了获取编译运行结果。通过json串返回回去。
compile_server.cc
#include "compile_run.hpp"
#include "../common/httplib.h"
using namespace ns_compile_run;
using namespace httplib;
static void Usage(const std::string &proc)
{
std::cout << "\nUsage: " << proc << " port\n" << std::endl;
}
// ./compile_server post
int main(int argc, char *argv[])
{
if(argc != 2)
{
Usage(argv[0]);
}
Server svr;
// 这里...接收一个req,返回一个resp?不太懂说实话,不过暂时来看不重要。
// 感觉...就是cpp-httplib的接口使用方法可能
// 网页,客户端访问/hello时就会有对应数据返回。
// svr.Get("/hello", [](const Request &req, Response &resp){
// // 设置响应正文?或许
// resp.set_content("hello httplib, 你好 httplib!", "text/plain;charset=utf-8");
// });
// 说实话,有关这里post,get的相关http内容,有印象,但是记不太清了,好像是请求和响应的方法?
// 我记得是,客户端也就是浏览器请求时可以是post/get方法,区别是账号密码的传输方式。一种是在正文中,一种是在url中。
// 而http服务端响应时,一般都是post方法?
// 那下面的req和resp这两个参数如何理解呢?
svr.Post("/compile_and_run", [](const Request &req, Response &resp)
{
// 用户请求的服务正文正是我们想要的json string
std::string in_json = req.body;
std::string out_json;
if(!in_json.empty())
{
CompileAndRun::execute(in_json, &out_json);
resp.set_content(out_json, "application/json;charset=utf-8");
}
});
// 不需要首页信息,不是一个对外网站。上面只是用来测试,介绍如何使用httplib库
// svr.set_base_dir("./wwwroot");
svr.listen("0.0.0.0", atoi(argv[1]));
return 0;
}
使用了第三方httplib库,方便生成一个http服务器。通过http请求获取json串,调用compile_run.hpp的编译运行接口,获取返回的json串。再通过http响应返回回去,也就是未来的oj_server端。(http的相关知识有点遗忘了….)

上方为编译运行模块的文件组成。temp即存储临时文件的文件夹。
oj_server 基于MVC结构的oj服务设计
总览分析
这里的本质就是建立一个小型的网站,采用的结构是MVC结构。之前的compile_server其实只是提供一个基于网络的编译运行服务。而这里的oj_server才是oj平台的搭建。
这个oj平台,也就是oj_server这里主要提供两(三)个功能
1. 获取题目列表(可以通过点击,跳转至指定题目的在线oj界面)
2. 获取特定题目的在线OJ页面(包含这个题目的描述)此处包含在线编辑区域,提交判题功能(使用compile_server)
3. 一个非常简单的首页…没什么意思其实。可以跳转至题目列表界面
M: Model,通常是和数据交互的模块,比如,对题库进行增删改查(文件版,MySQL版)
V: view, 通常是拿到数据之后,要进行构建网页,渲染网页内容,展示给用户的(浏览器)(此处的数据其实就是Model模块提供的)
C: control, 控制器,就是我们的核心业务逻辑。其实就是提供一些接口,这些接口的实现需要综合Model和View模块。
(MVC结构,第一次听或许觉得有点难以理解,但其实学完之后发现,也就那样…)
Model 提供对数据的操作方法
在一个OJ平台中,数据当然就是一个题库了。由于我还没学MySQL,所以此处只能实现文件版的题库,也就是在oj_server模块下,创建一个questions文件夹,里面存储一些题目数据。
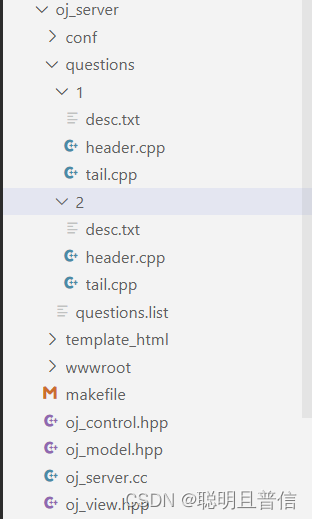
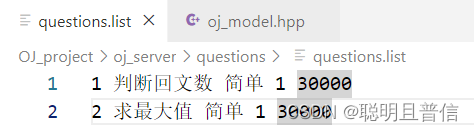
如上,questions文件夹为对应的题库,一个题目包含:题目编号,题目标题,题目难度,cpu_limit,mem_limit,题面描述,给用户设置的此题的预置代码,测试用例。
前面5个题目数据在questions/questions.list文件中,一行为一个题目。而后面三个较长,存储在同目录下的与题目编号同名的文件夹中。
oj_model.hpp
#pragma once
#include <iostream>
#include <string>
#include <unordered_map>
#include <fstream>
#include <vector>
#include <cassert>
#include "../common/log.hpp"
#include "../common/util.hpp"
// 根据题目list文件,加载所有的题目信息到内存中(unordered_map)
// model: 主要用来和数据进行交互,对外提供访问数据的接口
namespace ns_model
{
using namespace ns_log;
using namespace ns_util;
class Question
{
public:
std::string number; // 题目编号
std::string title; // 题目标题
std::string star; // 题目难度
int cpu_limit; // 题目的时间要求(s)
int mem_limit; // 题目的空间要求(KB)
std::string desc; // 题目描述
std::string header; // 内置代码
std::string tail; // 测试用例,和header拼接,形成完整可编译执行的代码
};
const std::string g_questions_list = "./questions/questions.list"; // questions_list文件的路径
const std::string g_questions_path = "./questions/";
class Model
{
private:
std::unordered_map<std::string, Question> questions;
public:
Model()
{
assert(LoadAllQuestions(g_questions_list));
}
~Model() {}
bool LoadAllQuestions(const std::string &questions_list)
{
// 加载所有的题目数据到内存中(unordered_map)
std::ifstream in(questions_list);
if(!in.is_open())
{
LOG(FATAL) << "加载题库失败,请检查是否存在题目列表文件" << "\n";
return false;
}
std::string line;
while(std::getline(in, line))
{
// 获取到了一行数据
// 1 两数之和 简单 1 30000
std::vector<std::string> tokens;
StringUtil::SplitString(line, &tokens, " ");
if(tokens.size() != 5)
{
// 这行数据无效
LOG(WARNING) << "加载部分题目失败,请检查文件格式" << "\n";
continue; // 继续加载下一个题目
}
Question q;
q.number = tokens[0];
q.title = tokens[1];
q.star = tokens[2];
q.cpu_limit = atoi(tokens[3].c_str());
q.mem_limit = atoi(tokens[4].c_str());
FileUtil::ReadFile(g_questions_path + tokens[0] + "/desc.txt", &q.desc, true);
FileUtil::ReadFile(g_questions_path + tokens[0] + "/header.cpp", &q.header, true);
FileUtil::ReadFile(g_questions_path + tokens[0] + "/tail.cpp", &q.tail, true);
questions.insert({q.number, q});
}
LOG(INFO) << "加载题库成功!" << "\n";
in.close();
return true;
}
// 提供获取所有题目数据和获取指定题目数据的接口
bool GetAllQuestions(std::vector<Question> *out)
{
if(questions.size() == 0)
{
LOG(ERROR) << "用户获取题库失败" << "\n";
return false;
}
for(const auto &iter : questions)
{
out->push_back(iter.second); // string : Question
}
return true;
}
bool GetOneQuestion(const std::string &number, Question *out)
{
if(questions.find(number) == questions.end())
{
LOG(ERROR) << "用户获取指定题目失败,题目编号: " << number << "\n";
return false;
}
*out = questions[number];
return true;
}
};
} // namespace ns_model对应文件版题库的结构,这个Model类,在构造时,先逐行读取questions.list文件。再对一行进行字符串切分,获取到5个元素,第一个元素为题号,再读取questions/目录下的对应题号文件夹,读取其中的题面描述,预置代码和测试用例。构造出一个Question对象。再按照 题目编号 : Question的key value映射结构,构造出一个unordered_map。
这个Model模块只提供两个对题库的读取方法,一个是获取全部题目数据,一个是根据题号,获取指定题目的数据。其实就是对应了这个oj平台的两个界面需求(题目列表界面和指定题目的oj界面)。 这里没有提供对题库的增删方法,对题目的增删都在questions目录下手动进行…
View 使用后端数据对前端页面进行渲染,获取渲染之后的html
这块使用了第三方开源的ctemplate渲染库,这个库…是前后端交互的一个库,第一次接触前端,也是第一次接触这个库…有点陌生(实际不是一点)。
其实吧,前端就是一个html网页,它里面用的是前端语法,我们不管。但是,前端显示的有些数据其实是在后端保存着的。我们如何把后端数据显示到前端html网页中呢?在这个项目中用的就是ctemplate渲染库..
oj_view.hpp
#pragma once
#include <iostream>
#include <string>
#include "./oj_model.hpp"
#include <ctemplate/template.h>
namespace ns_view
{
using namespace ns_model;
const std::string template_path = "./template_html/";
class View
{
public:
void AllExpandHtml(const std::vector<Question> &questions, std::string *html)
{
// 利用题目列表数据questions,进行网页渲染形成html
// html模板为template_html目录下的all_questions.html
// 题目的编号 题目的标题 题目的难度
// 推荐使用表格显示
// 1. 形成路径,即将进行渲染的html路径
std::string src_html = template_path + "all_questions.html";
// 2. 形成数字典
ctemplate::TemplateDictionary root("all_questions");
for (const auto &q : questions)
{
// 对应html中的{{#question_list}}
ctemplate::TemplateDictionary *sub = root.AddSectionDictionary("question_list");
sub->SetValue("number", q.number);
sub->SetValue("title", q.title);
sub->SetValue("star", q.star);
}
// 3. 获取被渲染的html
ctemplate::Template *tpl = ctemplate::Template::GetTemplate(src_html, ctemplate::DO_NOT_STRIP);
// 4. 开始完成渲染功能
tpl->Expand(html, &root);
}
void OneExpandHtml(const Question &q, std::string *html)
{
// 利用指定题目的数据,进行网页渲染形成html
// 网页模板为template_html目录下的one_question.html
// 1. 形成路径
std::string src_html = template_path + "one_question.html";
// 2. 形成数字典
ctemplate::TemplateDictionary root("one_question");
root.SetValue("number", q.number);
root.SetValue("title", q.title);
root.SetValue("star", q.star);
root.SetValue("desc", q.desc);
root.SetValue("pre_code", q.header);
//3. 获取被渲染的html
ctemplate::Template *tpl = ctemplate::Template::GetTemplate(src_html, ctemplate::DO_NOT_STRIP);
//4. 开始完成渲染功能
tpl->Expand(html, &root);
}
};
}
// 我自己写的废话: View里面就是,获取数据然后主要任务是渲染前端界面。
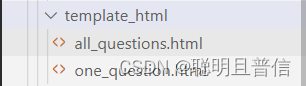
在template_html目录下,有两个html,其实就是题目列表页面和指定题目页面。我们View模块也提供两个方法,第一个:使用Model模块传来的全部题目数据,渲染一个显示题目列表的页面。第二个std::string *html参数是一个输出型参数,也就是对应的渲染之后的html。第二个:使用从Model模块获取的指定题目的数据,渲染一个显示指定题目的页面。第二个参数也是输出型参数,对应渲染之后的html网页。 那么,这两个方法的两个输出型参数,输出一个html,其实就是在control模块中需要获取的,根本上也是oj_server.cc需要获取并通过http响应返回给客户端的(浏览器,解析html,显示出来)
对于ctemplate库的使用方法,也就是渲染前端html网页的方法..我也不懂,看看代码浅了解一下吧
Control 逻辑控制模块,oj_server.cc直接调用Control提供的方法
#pragma once
#include <iostream>
#include <string>
#include <vector>
#include <mutex>
#include <fstream>
#include <cassert>
#include <jsoncpp/json/json.h>
#include "./oj_model.hpp"
#include "./oj_view.hpp"
#include "../common/httplib.h"
namespace ns_control
{
using namespace ns_model;
using namespace ns_view;
using namespace httplib;
// 为什么要加锁??????aaaa
class Machine
{
public:
std::string ip_;
int port_;
uint64_t load_; // 该机器的负载
std::mutex *mtx_; // std::mutex不可被拷贝,所以Machine将不能被拷贝,故存储指针,使Machine可以被拷贝(存入容器中)
public:
Machine()
: ip_(), port_(0), load_(0), mtx_(nullptr)
{}
~Machine()
{
// if(mtx_ != nullptr)
// delete mtx_;
}
void IncLoad()
{
mtx_->lock();
++load_;
mtx_->unlock();
}
void DecLoad()
{
mtx_->lock();
--load_;
mtx_->unlock();
}
void ResetLoad()
{
mtx_->lock();
load_ = 0;
mtx_->unlock();
}
uint64_t Load()
{
mtx_->lock();
uint64_t load = load_;
mtx_->unlock();
return load;
}
};
const std::string g_file_path = "./conf/service_machine.conf";
// 负载均衡模块
class LoadBalance
{
private:
std::vector<Machine> machines_; // 所有的机器
std::vector<int> online_; // 在线机器,存储所有在线机器的下标
std::vector<int> offline_; // 离线机器,存储所有离线机器的下标
std::mutex mtx_;
public:
LoadBalance()
{
assert(LoadAllMachines(g_file_path));
LOG(INFO) << " 加载所有编译运行服务器成功!" << "\n";
}
~LoadBalance() {}
bool LoadAllMachines(const std::string& file_path)
{
// 将配置文件中的所有后端机器加载到machines和online中
std::ifstream in(file_path);
if(!in.is_open())
{
LOG(FATAL) << "加载 " << file_path << " 失败" << "\n";
return false;
}
// std::cout << "debug 1" << std::endl;
std::string line;
while(std::getline(in, line))
{
// 127.0.0.1:8081
std::vector<std::string> tokens;
StringUtil::SplitString(line, &tokens, ":");
if(tokens.size() != 2)
{
LOG(WARNING) << "切分" << line << "失败" << "\n";
continue;
}
// for(auto &i:tokens)
// {
// std::cout << i << std::endl;
// }
Machine m;
m.ip_ = tokens[0];
m.port_ = atoi(tokens[1].c_str());
m.load_ = 0;
m.mtx_ = new std::mutex();
online_.push_back(machines_.size());
machines_.push_back(m);
}
in.close();
return true;
}
bool SmartChoice(int *id, Machine **m)
{
// 进行智能选择
mtx_.lock();
int online_num = online_.size();
if(0 == online_num)
{
mtx_.unlock();
LOG(FATAL) << "所有的后端编译服务器都已离线,请运维同事尽快处理" << "\n";
return false;
}
// 至少有一台可以提供编译服务的服务器
*id = online_[0];
for(int i = 1; i < online_num; ++i)
{
if(machines_[online_[i]].load_ < machines_[*id].load_)
{
*id = online_[i];
}
}
*m = &machines_[*id]; // 获取一个一级指针,传一个二级指针
mtx_.unlock();
return true;
}
void OfflineMachine(int id)
{
// 离线主机
mtx_.lock();
for(auto iter = online_.begin(); iter != online_.end(); ++iter)
{
if(*iter == id)
{
machines_[id].ResetLoad();
offline_.push_back(id);
online_.erase(iter);
break; // 因为break,所以此处不会出现vector的迭代器失效问题。
}
}
// offline_.push_back(id); // 有问题,不能在这里。
mtx_.unlock();
}
void OnlineMachine()
{
mtx_.lock();
online_.insert(online_.begin(), offline_.begin(), offline_.end());
offline_.erase(offline_.begin(), offline_.end());
mtx_.unlock();
LOG(INFO) << "所有的主机已上线" << "\n";
}
// 用于调试
void ShowMachines()
{
mtx_.lock();
std::cout << "当前在线主机id列表 : ";
for(auto &i :online_)
std::cout << i << " ";
std::cout << std::endl;
std::cout << "当前离线主机id列表 : ";
for(auto &i : offline_)
std::cout << i << " ";
std::cout << std::endl;
mtx_.unlock();
}
};
class Control
{
private:
Model model_;
View view_;
LoadBalance loadbalance_;
public:
bool AllQuestions(std::string *html)
{
bool ret = true;
std::vector<Question> questions;
if(model_.GetAllQuestions(&questions))
{
// std::cout << "debug : " << questions[0].title << std::endl;
// 获取题目列表数据成功,将所有的题目数据渲染构建成网页
view_.AllExpandHtml(questions, html);
}
else
{
*html = "获取题目列表失败";
ret = false;
}
return ret;
}
bool OneQuestion(const std::string &number, std::string *html)
{
bool ret = true;
Question q;
if(model_.GetOneQuestion(number, &q))
{
// 获取指定题目信息成功, 将题目的所有数据渲染构建成网页
view_.OneExpandHtml(q, html);
}
else
{
*html = "获取指定题目失败,题目编号: " + number;
ret = false;
}
return ret;
}
void Judge(const std::string &number, const std::string in_json, std::string *out_json)
{
// 1. 获取题目信息
Question q;
model_.GetOneQuestion(number, &q);
// 2. 反序列化,从in_json中获取到code和input
Json::Value in_value;
Json::Reader reader;
reader.parse(in_json, in_value); // 反序列化
std::string code = in_value["code"].asString();
std::string input = in_value["input"].asString();
// 3. 构造给编译模块的json串
Json::Value compile_value;
compile_value["code"] = code + q.tail; // 用户提交的代码 + 测试用例 = 最终进行编译运行的代码
compile_value["input"] = input;
compile_value["cpu_limit"] = q.cpu_limit;
compile_value["mem_limit"] = q.mem_limit;
Json::FastWriter writer;
std::string compile_json = writer.write(compile_value);
// 4. 负载均衡地选择一个后端提供编译运行服务的服务器,获取编译服务,获取编译运行结果传给out_json
while(true)
{
int id = 0;
Machine *m = nullptr;
if(!loadbalance_.SmartChoice(&id, &m))
{
// 选取编译服务器失败,即所有的后端编译服务器都已离线
break;
}
// 选取到了一个编译服务器
Client cli(m->ip_, m->port_);
m->IncLoad(); // 增加对应编译服务器负载
LOG(ERROR) << " 选择编译主机成功,主机id : " << id << " 详情 : " << m->ip_ << ":" << m->port_ << " 当前主机负载为 : " << m->Load() << "\n";
if(auto res = cli.Post("/compile_and_run", compile_json, "application/json;charset=utf-8"))
{
if(res->status == 200)
{
// 请求成功,且状态码为200
m->DecLoad();
*out_json = res->body; // 编译运行的结果
LOG(INFO) << "请求编译和运行服务成功" << "\n";
break;
}
// 请求成功,但是退出码不为200,故需要再次选择编译服务器&&再次请求
m->DecLoad();
}
else
{
// 请求失败,直接把该主机挂掉即可
LOG(ERROR) << " 当前请求的主机 : " << id << " 详情 : " << m->ip_ << ":" << m->port_ << " 可能已离线" << "\n";
loadbalance_.OfflineMachine(id);
loadbalance_.ShowMachines(); // 仅仅为了调试
}
}
}
void RecoveryMachine()
{
loadbalance_.OnlineMachine();
}
};
} // namespace ns_control
// 我自己写的废话:这里是和server.cc直接交互的模块,提供一些方法。
综上,后端数据从Model中获取,渲染出的html从View中获取。也就是题目列表界面和指定题目界面我们都有了,对应的也就是Control类中的AllQuestions和OneQuestion方法。将来直接由主函数调用。
但是,用户需要提交代码,oj_server.cc获取到http请求之后需要判题(客户端浏览器点击提交按钮),也就是需要通过网络提交给compile_server进行编译运行。且这个OJ平台,是负载均衡式的,也就是可以在多台机器上部署compile_server服务,这样,当OJ平台有大量的判题请求时,oj_server可以选择当前负载最低的编译运行服务器。所以我们需要在Control中设计负载均衡式的Judge方法,用于判题。
如上,Machine表示每一台编译运行服务器,LoadBlance有加载后端服务器的方法(所有编译服务器的ip和port在配置文件中),智能选取负载最低服务器的方法,离线主机,上线主机方法。而Control的Judge方法中就是主函数直接调用的判题方法,传来题号,以及一个json(包含代码,input),而题目的cpu_limit mem_limit在题目数据中。Judge构造好给compile_server的json串,就通过LoadBlance获取负载最低的主机,发起请求,获取到返回的json串(回顾Compile_server模块,其实就是:状态码,状态码描述,若状态码为0即编译运行成功,则有stdout和stderr),通过输出型参数返回回去。
以上就是Control的全部功能,其实主要就是三个,AllQuestions OneQuestion Judge,对应这个OJ网站的三个需求。
这里有一个疑惑是:这里的Machine和LoadBalance都有加锁,但是我不太理解为什么要加锁,Machine的IncLoad和DecLoad在我看来好像不可能多线程执行吧… 还有LoadBalance的SmartChoice和OfflineMachine,这里的锁分别保护load_和online_ offline_。
解答:为什么要加锁,首先我们这里是通过第三方网络库,即httplib库获取的http请求,而这个网络库底层是采用的多线程策略,所以我们的judge其实是可能被多线程同时执行的,则就存在多线程并发访问问题,故需要加锁。第二点是:我们这里的LoadBalance和Machine是一个公共模块,他后面可能被多种场景调用,比如多线程场景,所以,虽然我们的judge这里没有设计多线程,但是为了提高代码的健壮性,多场景的适应能力,进行加锁保护。
oj_server.cc
#include <iostream>
#include <string>
#include <signal.h>
#include "../common/httplib.h"
#include "./oj_control.hpp"
using namespace httplib;
using namespace ns_control;
Control *ctrl_ptr = nullptr;
void Recovery(int signo)
{
ctrl_ptr->RecoveryMachine();
}
int main()
{
// 用户请求的服务路由功能
Server svr;
Control ctrl;
ctrl_ptr = &ctrl;
// std::cout << "hhhhh1" << std::endl;
signal(SIGQUIT, Recovery);
// 功能1: 获取所有的题目列表(严格来说,这里需要返回的是所有题目列表构成的一个html网页)
// 指的是访问这个all_questions资源时,会进行如下响应
svr.Get("/all_questions", [&ctrl](const Request &req, Response &resp){
// 返回一张包含所有题目的html网页
std::string html;
ctrl.AllQuestions(&html);
resp.set_content(html, "text/html; charset=utf-8");
});
// std::cout << "hhhhh2" << std::endl;
// 功能2: 用户根据题目编号,获取指定的题目内容(某指定题目的内容所组成的一个html网页)
// /question/100 -> 正则匹配(不懂) ?????????
// R"()", 原始字符串raw string, 保持字符串内容的原貌, 不用做相关的转义
svr.Get(R"(/question/(\d+))", [&ctrl](const Request &req, Response &resp){
std::string number = req.matches[1]; // ???????
std::string html;
ctrl.OneQuestion(number, &html);
resp.set_content(html, "text/html; charset=utf-8");
});
// std::cout << "hhhhh3" << std::endl;
// 用户提交代码,使用我们的判题功能
svr.Post(R"(/judge/(\d+))", [&ctrl](const Request &req, Response &resp){
std::string number = req.matches[1]; // ???????(题目编号)
std::string result_json; // 编译运行结果,也就是OJ程序的测试结果,非html
ctrl.Judge(number, req.body, &result_json);
resp.set_content(result_json, "application/json;charset=utf-8");
// std::cout << "out_json : " << result_json << std::endl;
// resp.set_content("指定题目的判题功能: " + number, "text/plain; charset=utf-8");
});
// std::cout << "hhhhh4" << std::endl;
svr.set_base_dir("./wwwroot"); // 首页设置,也就是访问127.0.0.1:8080时,要获取的资源
svr.listen("0.0.0.0", 8080); // 端口号直接固定,因为不像编译服务一样要部署到多台机器上
return 0;
}就是利用httplib构建一个http服务器,有首页,有题目列表网页,有特定题目oj网页,还有一个判题功能。就是基于http请求和http响应,构造一个网站。使用的方法也是Control提供的(C使用MV的接口,即MVC)
前端
index.html
<!-- OJ首页
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>OJ_无所畏惧</title>
</head>
<body>
<p5>yzl的OJ平台</p5>
<a href="/all_questions">点击获取OJ题目列表</a>
<table>
<tr>
<th>题目编号</th>
<th>题目标题</th>
<th>题目难度</th>
</tr>
<tr>
<td>111</td>
<td>222</td>
<td>333</td>
</tr>
<tr>
<td>444</td>
<td>555</td>
<td>666</td>
</tr>
<tr>
<td>hhh</td>
<td>hhh</td>
<td>hhh</td>
</tr>
</table>
</body>
</html> -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>这是我的个人OJ系统</title>
<style>
/* 起手式, 100%保证我们的样式设置可以不受默认影响 */
* {
/* 消除网页的默认外边距 */
margin: 0px;
/* 消除网页的默认内边距 */
padding: 0px;
}
html,
body {
width: 100%;
height: 100%;
}
.container .navbar {
width: 100%;
height: 50px;
background-color: black;
/* 给父级标签设置overflow,取消后续float带来的影响 */
overflow: hidden;
}
.container .navbar a {
/* 设置a标签是行内块元素,允许你设置宽度 */
display: inline-block;
/* 设置a标签的宽度,a标签默认行内元素,无法设置宽度 */
width: 80px;
/* 设置字体颜色 */
color: white;
/* 设置字体的大小 */
font-size: large;
/* 设置文字的高度和导航栏一样的高度 */
line-height: 50px;
/* 去掉a标签的下划线 */
text-decoration: none;
/* 设置a标签中的文字居中 */
text-align: center;
}
/* 设置鼠标事件 */
.container .navbar a:hover {
background-color: green;
}
.container .navbar .login {
float: right;
}
.container .content {
/* 设置标签的宽度 */
width: 800px;
/* 用来调试 */
/* background-color: #ccc; */
/* 整体居中 */
margin: 0px auto;
/* 设置文字居中 */
text-align: center;
/* 设置上外边距 */
margin-top: 200px;
}
.container .content .font_ {
/* 设置标签为块级元素,独占一行,可以设置高度宽度等属性 */
display: block;
/* 设置每个文字的上外边距 */
margin-top: 20px;
/* 去掉a标签的下划线 */
text-decoration: none;
/* 设置字体大小
font-size: larger; */
}
</style>
</head>
<body>
<div class="container">
<!-- 导航栏, 功能不实现-->
<div class="navbar">
<a href="/">首页</a>
<a href="/all_questions">题库</a>
<a href="#">竞赛</a>
<a href="#">讨论</a>
<a href="#">求职</a>
<a class="login" href="#">登录</a>
</div>
<!-- 网页的内容 -->
<div class="content">
<h1 class="font_">欢迎来到我的OnlineJudge平台</h1>
<p class="font_">这个我个人独立开发的一个在线OJ平台</p>
<a class="font_" href="/all_questions">点击我开始编程啦!</a>
</div>
</div>
</body>
</html>
all_question.html
<!-- <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>在线OJ-题目列表</title>
</head>
<body>
<table>
<tr>
<th>编号</th>
<th>标题</th>
<th>难度</th>
</tr>
{{#question_list}}
<tr>
<td>{{number}}</td>
<td><a href="/question/{{number}}">{{title}}</a></td>
<td>{{star}}</td>
</tr>
{{/question_list}}
</table>
</body>
</html> -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>在线OJ-题目列表</title>
<style>
/* 起手式, 100%保证我们的样式设置可以不受默认影响 */
* {
/* 消除网页的默认外边距 */
margin: 0px;
/* 消除网页的默认内边距 */
padding: 0px;
}
html,
body {
width: 100%;
height: 100%;
}
.container .navbar {
width: 100%;
height: 50px;
background-color: black;
/* 给父级标签设置overflow,取消后续float带来的影响 */
overflow: hidden;
}
.container .navbar a {
/* 设置a标签是行内块元素,允许你设置宽度 */
display: inline-block;
/* 设置a标签的宽度,a标签默认行内元素,无法设置宽度 */
width: 80px;
/* 设置字体颜色 */
color: white;
/* 设置字体的大小 */
font-size: large;
/* 设置文字的高度和导航栏一样的高度 */
line-height: 50px;
/* 去掉a标签的下划线 */
text-decoration: none;
/* 设置a标签中的文字居中 */
text-align: center;
}
/* 设置鼠标事件 */
.container .navbar a:hover {
background-color: green;
}
.container .navbar .login {
float: right;
}
.container .question_list {
padding-top: 50px;
width: 800px;
height: 100%;
margin: 0px auto;
/* background-color: #ccc; */
text-align: center;
}
.container .question_list table {
width: 100%;
font-size: large;
font-family: 'Lucida Sans', 'Lucida Sans Regular', 'Lucida Grande', 'Lucida Sans Unicode', Geneva, Verdana, sans-serif;
margin-top: 50px;
background-color: rgb(243, 248, 246);
}
.container .question_list h1 {
color: green;
}
.container .question_list table .item {
width: 100px;
height: 40px;
font-size: large;
font-family:'Times New Roman', Times, serif;
}
.container .question_list table .item a {
text-decoration: none;
color: black;
}
.container .question_list table .item a:hover {
color: blue;
text-decoration:underline;
}
.container .footer {
width: 100%;
height: 50px;
text-align: center;
line-height: 50px;
color: #ccc;
margin-top: 15px;
}
</style>
</head>
<body>
<div class="container">
<!-- 导航栏, 功能不实现-->
<div class="navbar">
<a href="/">首页</a>
<a href="/all_questions">题库</a>
<a href="#">竞赛</a>
<a href="#">讨论</a>
<a href="#">求职</a>
<a class="login" href="#">登录</a>
</div>
<div class="question_list">
<h1>OnlineJuge题目列表</h1>
<table>
<tr>
<th class="item">编号</th>
<th class="item">标题</th>
<th class="item">难度</th>
</tr>
{{#question_list}}
<tr>
<td class="item">{{number}}</td>
<td class="item"><a href="/question/{{number}}">{{title}}</a></td>
<td class="item">{{star}}</td>
</tr>
{{/question_list}}
</table>
</div>
<div class="footer">
<!-- <hr> -->
<h4>@聪明普信男</h4>
</div>
</div>
</body>
</html>
one_question.html
<!-- <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>{{number}}.{{title}}</title>
</head>
<body>
<h4>{{number}}.{{title}}.{{star}}</h4>
<p>{{desc}}</p>
<textarea name="code" id="" cols="30" rows="10">{{pre_code}}</textarea>
</body>
</html> -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>{{number}}.{{title}}</title>
<!-- 引入ACE插件 -->
<!-- 官网链接:https://ace.c9.io/ -->
<!-- CDN链接:https://cdnjs.com/libraries/ace -->
<!-- 使用介绍:https://www.iteye.com/blog/ybc77107-2296261 -->
<!-- https://justcode.ikeepstudying.com/2016/05/ace-editor-%E5%9C%A8%E7%BA%BF%E4%BB%A3%E7%A0%81%E7%BC%96%E8%BE%91%E6%9E%81%E5%85%B6%E9%AB%98%E4%BA%AE/ -->
<!-- 引入ACE CDN -->
<script src="https://cdnjs.cloudflare.com/ajax/libs/ace/1.2.6/ace.js" type="text/javascript"
charset="utf-8"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/ace/1.2.6/ext-language_tools.js" type="text/javascript"
charset="utf-8"></script>
<!-- 引入jquery CDN -->
<script src="http://code.jquery.com/jquery-2.1.1.min.js"></script>
<style>
* {
margin: 0;
padding: 0;
}
html,
body {
width: 100%;
height: 100%;
}
.container .navbar {
width: 100%;
height: 50px;
background-color: black;
/* 给父级标签设置overflow,取消后续float带来的影响 */
overflow: hidden;
}
.container .navbar a {
/* 设置a标签是行内块元素,允许你设置宽度 */
display: inline-block;
/* 设置a标签的宽度,a标签默认行内元素,无法设置宽度 */
width: 80px;
/* 设置字体颜色 */
color: white;
/* 设置字体的大小 */
font-size: large;
/* 设置文字的高度和导航栏一样的高度 */
line-height: 50px;
/* 去掉a标签的下划线 */
text-decoration: none;
/* 设置a标签中的文字居中 */
text-align: center;
}
/* 设置鼠标事件 */
.container .navbar a:hover {
background-color: green;
}
.container .navbar .login {
float: right;
}
.container .part1 {
width: 100%;
height: 600px;
overflow: hidden;
}
.container .part1 .left_desc {
width: 50%;
height: 600px;
float: left;
overflow: scroll;
}
.container .part1 .left_desc h3 {
padding-top: 10px;
padding-left: 10px;
}
.container .part1 .left_desc pre {
padding-top: 10px;
padding-left: 10px;
font-size: medium;
font-family: 'Gill Sans', 'Gill Sans MT', Calibri, 'Trebuchet MS', sans-serif;
}
.container .part1 .right_code {
width: 50%;
float: right;
}
.container .part1 .right_code .ace_editor {
height: 600px;
}
.container .part2 {
width: 100%;
overflow: hidden;
}
.container .part2 .result {
width: 300px;
float: left;
}
.container .part2 .btn-submit {
width: 120px;
height: 50px;
font-size: large;
float: right;
background-color: #26bb9c;
color: #FFF;
/* 给按钮带上圆角 */
/* border-radius: 1ch; */
border: 0px;
margin-top: 10px;
margin-right: 10px;
}
.container .part2 button:hover {
color: green;
}
.container .part2 .result {
margin-top: 15px;
margin-left: 15px;
}
.container .part2 .result pre {
font-size: large;
}
</style>
</head>
<body>
<div class="container">
<!-- 导航栏, 功能不实现-->
<div class="navbar">
<a href="/">首页</a>
<a href="/all_questions">题库</a>
<a href="#">竞赛</a>
<a href="#">讨论</a>
<a href="#">求职</a>
<a class="login" href="#">登录</a>
</div>
<!-- 左右呈现,题目描述和预设代码 -->
<div class="part1">
<div class="left_desc">
<h3><span id="number">{{number}}</span>.{{title}}_{{star}}</h3>
<pre>{{desc}}</pre>
</div>
<div class="right_code">
<pre id="code" class="ace_editor"><textarea class="ace_text-input">{{pre_code}}</textarea></pre>
</div>
</div>
<!-- 提交并且得到结果,并显示 -->
<div class="part2">
<div class="result"></div>
<button class="btn-submit" onclick="submit()">提交代码</button>
</div>
</div>
<script>
//初始化对象
editor = ace.edit("code");
//设置风格和语言(更多风格和语言,请到github上相应目录查看)
// 主题大全:http://www.manongjc.com/detail/25-cfpdrwkkivkikmk.html
editor.setTheme("ace/theme/monokai");
editor.session.setMode("ace/mode/c_cpp");
// 字体大小
editor.setFontSize(16);
// 设置默认制表符的大小:
editor.getSession().setTabSize(4);
// 设置只读(true时只读,用于展示代码)
editor.setReadOnly(false);
// 启用提示菜单
ace.require("ace/ext/language_tools");
editor.setOptions({
enableBasicAutocompletion: true,
enableSnippets: true,
enableLiveAutocompletion: true
});
function submit() {
// alert("嘿嘿!");
// 1. 收集当前页面的有关数据, 1. 题号 2.代码
var code = editor.getSession().getValue();
// console.log(code);
var number = $(".container .part1 .left_desc h3 #number").text(); // 获取题号是为了发起特定请求。
// console.log(number);
var judge_url = "/judge/" + number;
// console.log(judge_url);
// 2. 构建json,并通过ajax向后台发起基于http的json请求
$.ajax({
method: 'Post', // 向后端发起请求的方式
url: judge_url, // 向后端指定的url发起请求
dataType: 'json', // 告知server,我需要什么格式
contentType: 'application/json;charset=utf-8', // 告知server,我给你的是什么格式
data: JSON.stringify({
'code': code,
'input': ''
}),
success: function (data) {
//成功得到结果
// console.log(data);
show_result(data);
}
});
// 3. 得到结果,解析并显示到 result中
function show_result(data) {
// console.log(data.status);
// console.log(data.reason);
// 拿到result结果标签
var result_div = $(".container .part2 .result");
// 清空上一次的运行结果
result_div.empty();
// 首先拿到结果的状态码和原因结果
var _status = data.status;
var _reason = data.reason;
var reason_lable = $("<p>", {
text: _reason
});
reason_lable.appendTo(result_div);
if (status == 0) {
// 请求是成功的,编译运行过程没出问题,但是结果是否通过看测试用例的结果
var _stdout = data.stdout;
var _stderr = data.stderr;
var stdout_lable = $("<pre>", {
text: _stdout
});
var stderr_lable = $("<pre>", {
text: _stderr
})
stdout_lable.appendTo(result_div);
stderr_lable.appendTo(result_div);
}
else {
// 编译运行出错,do nothing
}
}
}
</script>
</body>
</html>这里的前端包含,首页的html编写,all_questions.html和one_question.html。也就是View需要渲染的两个网页。其实这三个(可以忽略首页)html的编写都是前端范畴,不需要学习。但是有一个需要学习和了解的是:前端如何将编辑器的代码获取到,然后构造出json(包含code和input字段),通过http请求访问oj_server的/Judge/x资源。又是如何获取到http响应,将其中的json解析出(包含status reason stdout stderr字段)(若status == 0,则有stdout stderr字段),然后打印到前端页面中的。
其实就是上方one_question.html的最后的两个function,也属于前端范畴,但是了解前后端是如何交互的还是有必要的。其实,就是通过前端的一些语法获取到一些数据,然后发起http请求和http响应。达到前后端互动。
结尾
这个项目中还有一个common模块,其实就是提供一些工具类,工具方法,例如在compile_server模块中经常用到的路径和后缀的拼接,还有字符串切割,还有形成唯一文件名,以及httplib.h,这块代码就不附上了,感觉意义不是太大。
补充一个点:我们为什么要把编译运行部分,单独设计为一个独立的模块呢?为什么设计为编译运行模块在多台机器执行,然后等待oj_server服务端的编译请求呢?
1. 因为编译运行模块,需要创建临时文件,读写文件,调用编译器编译源文件,执行可执行程序等。这部分是比较耗时的,因此,进行多台主机部署,这样利用多主机的性能,完成比较耗时的编译运行模块。
2. 编译运行模块需要执行用户提交的代码,这需要一定的安全保障。