masm代码的基本模板:
首先是指定使用的指令集,例如:
.586
这个就表示使用.586的指令集
然后指定内存模式和调用约定,例如:
.MODEL flat,stdcall
这里的flat是内存模式,stdcall是调用约定(stdcall就是32位下Windows API 的调用约定)
指定需要包含的静态链接库文件:
includelib user32.lib
includelib kernel32.lib
跟C++中的included差不多,包含我们后需要用到的静态库(调用系统的API),之后我们就可以使用库中所包含的API了:
ExitProcess PROTO, dwExitCode : DWORD
MessageBoxA PROTO hWnd : DWORD, lpText : BYTE, lpCaption : BYTE, uType : DWORD
这两个API很眼熟,在Windows编程中接触过,分别是退出进程和弹出提示框,这里提一下在汇编中调用这些API时要使用到一个伪指令:
PROTO
,这个伪指令是用来给API指定参数及其数据类型。比如在MessageBoxA中我们就要指定他的四个参数分别为:DWORD,BYTE,BYTE,DWORD。
在使用API时可以在最后加一行命令:
option casemap:none
这行命令是规定API调用时对大小写不敏感。
上面这部分就是开始编写正式程序之前的操作(API函数的调用位置可以任意,不一定在前面部分。)
之后就可以开始编写段了,根据以前学的知识大概知道有以下这些段:
- data普通数据段(也就是数据放在内存之中,可读可写)
- data?未初始化数据段(未被初始化的数据段一般作为缓冲区,并且在没有填入数据之前这个段是不占用内存空间的)
- code代码段
- stack栈段
- const常量数据段(只可读,因为是常量)
例如:
.data
Number DWORD 0
text db "shellcode",
.code
main proc
mov eax,5
mov ebx,5
add eax,ebx
add eax,Number
push 0
push offset text
push offset text
push 0
call MessageBoxA
add exp,16
call ExitProcess
main ENDP
END main
上面就是一个完整的数据段和代码段,首先在数据段那种声明了两个数据:Number和text,数据类型都是dword
之后就是代码段,代码段当中的:
main proc
.
.
.
main ENDP
END main
这个就相当于C++当中的:
int main()
{
}
数值的概念:
基本度量单位:
1 BYTE(字节)= 8BIT(比特)
WORD = 2 BYTE = 16 BIT
DWORD = 4 BYTE = 32BIT
QWORD = 8BYTE = 64BIT
数据存储度量单位:
1KB = 1024BYTE = 8192BIT
1MB = 1024KB
1GB = 1024MB
1TB = 1024GB
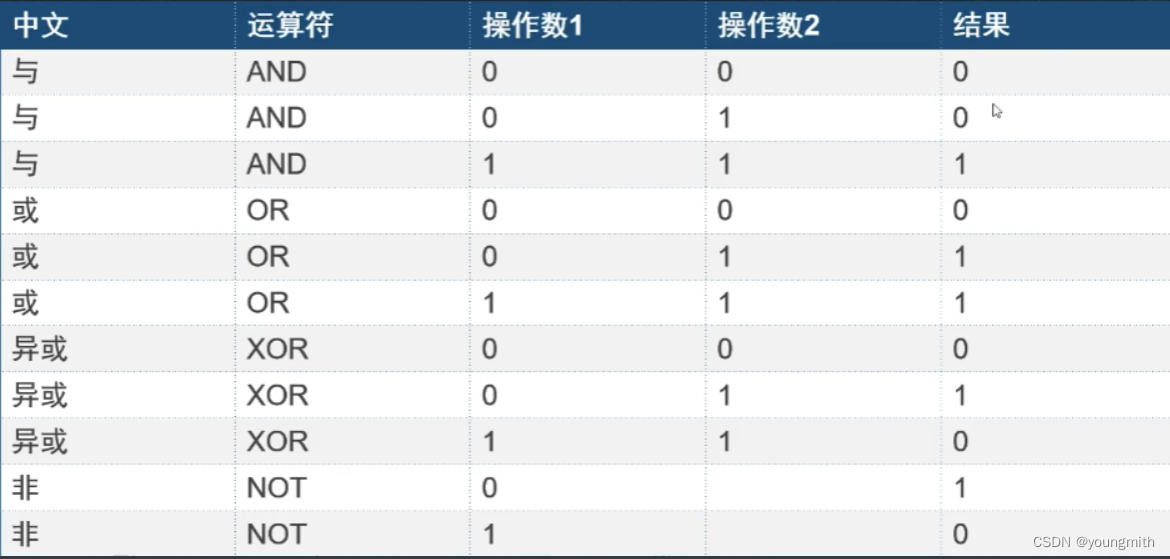
常用位运算
:
x86的基本构造:
这个都是老生常谈的问题了,首先是它的寄存器:

- EAX:加法运算后的结果存储
- ECX:loop循环指令的循环次数
- EBP,ESP:堆栈寄存器(栈底和栈顶)
- ESI.EDI:用于高速存储器的传输指令
CS,SS,DS等都是段寄存器(比如代码段和数据段)
EIP是指令寄存器,里面存放的是下一条指令的地址
EFLAGS就是指符号标志位:当CPU在运算中如果出现某些特定的运算结果(比如结果为0)就会将对应的符号标志位置为1
x86是一个32位的CPU,所以在后面扩展出来了x86-64的CPU,也就是64位的CPU。
64位的CPU原理上与32位相差不大,只是可以支持使用64位寄存器,地址长度变为了64位,且多出了8个通用寄存器,当然64位可以向后兼容32位程序
定义数据类型:
在前面的例子中使用到了db这种数据类型来储存字符串,但是还有关于其他数据的数据类型,下面来整理一下:
整数类型:
- BYTE 8位 无符号
- SBYTE 8位 有符号
- WORD 16位 无符号
- SWORD 16位 有符号
- DWORD 32位 无符号
- SDWORD 32位 有符号
- FWORD 48位 保护模式下的原始帧
- QWORD 64位 整数
- TBYTE 80位 整数
实数类型:
- REAL4 32位 短实数
- REAL8 64位 长实数
- REAL10 80位 扩展实数
伪指令:
- db 8位整数 (可以保存字符和字符串的原因是它是8位跟char是一个大小,可以保存ASCII码)
- dw 16位整数
- dd 32位整数或实数
- dq 64位整数或实数
- dt 80位整数或实数
数组:
使用dup指令直接创建多个同类型的数据,例如:
numarr dword 20 dup(0)
这样就创建了20个相同的numarr数据类型,并将他们全部初始化为0
而当我们需要对齐进行赋值时:
mov [numarr],1
mov [numarr + 4],2
mov [numarr + 8],3
其中的+4和+8就是根据数据长度(DWORD为4个字节)来位移的
数据传送指令:
操作数类型:
- 立即数:即普通数字(1,2,3等)
- 寄存器操作数 (eax,ebx等)
- 内存操作数(地址等)
各个操作数的对应符号:
- 立即数:imm
- 寄存器:reg
- 内存:mem
mov 目的操作数,源操作数
允许的操作类型:
- mov reg,reg
- mov mem,reg
- mov reg,mem
- mov mem,imm
- mov reg,imm
movzx :使用全0扩展并且完成数据传送(用来在不同位数的数据间传送,比如16位数据传送到32位寄存器中)
movsx:使用全1扩展并且完成数据传送
LAHF:加载状态标志为到AH里面(包括符号标志位,零标志位,奇偶标志位,进率标志位,借位标志位 )
SAHF:将AH里的值拷贝回标志位里
XCHG:交换两个操作数中的内容(操作数中不能包括立即数,且要保证位宽一致)
- xchg reg,reg
- xchg reg,mem
- xchg mem,reg
加法与减法指令:
常规的两个加减指令:
- add
- sub
还有常见的自加和自减指令:
- inc
- dec
一个没怎么见到过的取非指令:neg
这个指令是将操作数中的数值以二进制取反的方式取它的补码,并将它的符号位也取反
数据相关的运算符与伪指令:
offset:返回后面操作数与段起始位置之间的偏移距离(就像是一个指针一样)
ptr:给已分配的存储地址赋予另一种属性,比如先在数据段中定义为DWORD的某个数据可以通过这个伪指令变成word型,但是数据只保留它的低十六位。(格式:type ptr xxx)
type:返回操作数的数据类型(比如byte是1个字节就返回1,word是两个字节就返回2)
lengthof:返回操作数中的单元数(比如数组中的元素个数)
sizeof:返回操作数所占用的字节数
间接寻址:
[ ]:一个间接寻址运算符,在作用上是取出符号中对应地址内的值,不好描述,直接放一个例子
xor eax,eax
xor ebx,ebx
mov eax,offset var1
mov al,[eax]
inc eax
mov al,[eax]
其中var1是一个数组,这样间接寻址就等于是在遍历这个数组
还有一种取地址中值的方式为:mov dl,byte ptr ds:[edi]
主要是这个关键词:byte ptr ds:[edi],将段中的某个地址中的值取出后还给他规定了数据类型
变址寻址:
一种最简单的变址寻址:[eax + 1],即直接在取值符号中的地址加上一个立即数
还有一种比较花哨的变址寻址,下面给一个例子:
mov esi,4
mov eax,var1[esi * 4]
push 0
call ExitProcess
add esp,4
其中esi中存储需要查找的数组下表,在后面将其传入eax中时在取值符号中将这个下标乘上数组的数据类型对应的地址位宽(比如word就*2 DWORD 就 *4)
还有一种在.586指令集下的重命名方式:
pbyte typedef ptr byte
也就是typedef这个伪指令与C中的typedef是一个套路,就是给某个数据类型取一个“别名”,注意这个指令要写在数据段之前
堆栈操作:
首先是最常见的pop和push
然后是pushfd 和 popfd,这一对指令是将标志寄存器的数值保存进栈里,然后是将它弹出来(可以用于保存调用函数前的程序运行情况)
pushad 和 popad =,这一对指令是用于将通用寄存器中的值保存进栈里,压栈时的顺序是:
eax,ecx,edx,ebx,esp,ebp,esi,edi
函数的定义:
在汇编中也可以定义函数,汇编里的函数是某个独立的进程(类似于程序中的main),这个进程将以ret或者retn结尾,下面是一个示例
function proc
mov eax,5
add eax,6
ret
function endp
与main进程相似,函数进程也是有一对:proc…endp,并且这一段代码要写在code段内。
在函数调用中最重要的就是这一对指令:call–ret。
首先是call指令,它做了这样一些事:
- 首先push eip(将现在的程序执行地址保存进栈里)
- 然后jmp到指定地址
对应的ret指令就要完成这样一些事:
- 首先pop eip,将eip的执行地址复原
- 然后jmp eip,将程序的执行流放回去
那么像正常的函数一样,汇编的函数也可以通过寄存器等来传参,但是需要用到一个伪指令:uses,具体写法如下:
function proc uses eax ebx
add eax,ebx
ret
function endp
当时用到这个伪指令时,在调用函数前要注意先将参数传入栈中进行保存,例如:
mov eax,5
mov ebx,6
push eax
push ebx
call function
布尔指令和比较指令:
比较常见的布尔指令就是各种常见的逻辑操作:与(and)、或(or)、非(not)、异或(xor)。
这回多见到了一个伪指令test:这个指令完成的操作与and完成的操作使用一样的,不同的地方是,test在完成and操作后不会将结果保存在任何一个操作数中,而是将状态标志位设置为对应数值后将结果丢弃。
比较指令:
比较操作就是cmp指令:它完成的操作其实就是将两个操作数相减,得到的结果是不保存的,只是将对应的状态寄存器的各个位设置为相应数值
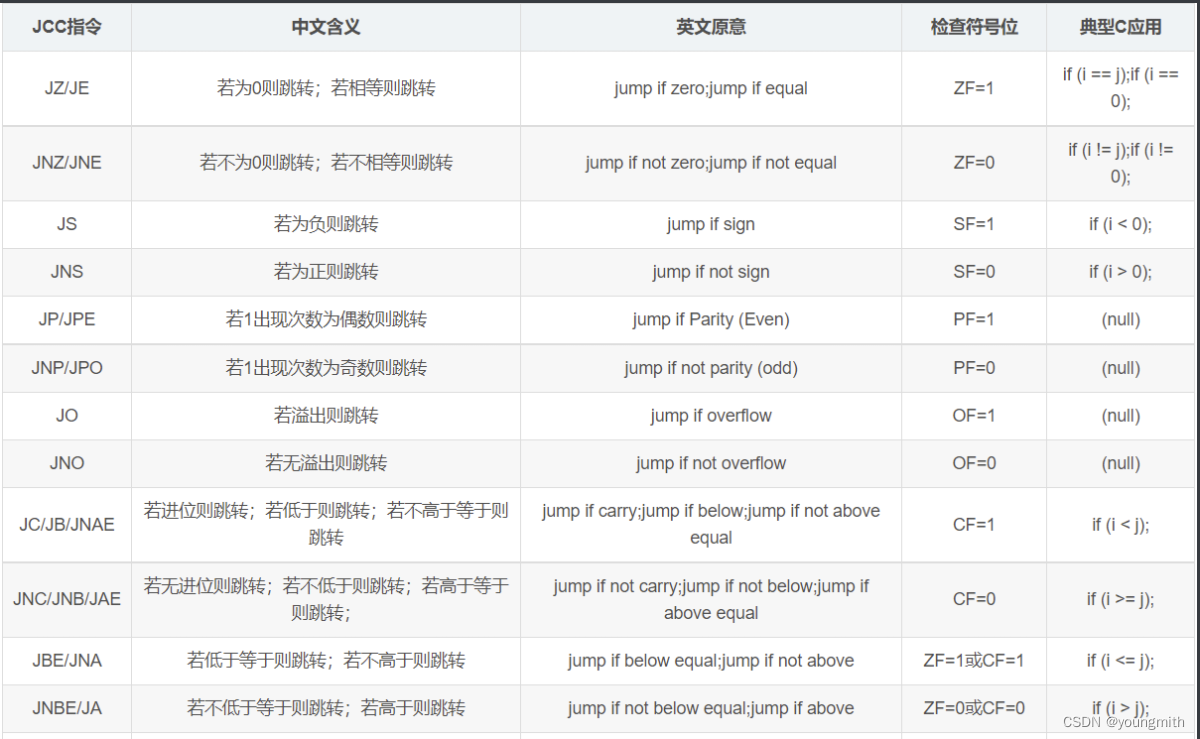
条件跳转指令:
也就是常说的jcc指令,在满足一定条件后进行跳转。
jcc指令关于是否跳转的判断一般是根据状态寄存器的值来判断的,现有的jcc指令大概有这些:

条件循环指令:
loopz:为0循环(ecx > 0 && zf = 1)
loope:相等循环,这个与前面的loopz跳转方式其实差不多,都是通过zf标志位来判断是否跳转,但是loopz是直接看zf位来跳转,但是loope是通过cmp指令比较之后再进行跳转
loopnz:不为0循环(ecx > 0 && zf = 0)
loopne:不相等循环
条件结构:
首先是
if else结构
:
在汇编中的形式稍微比较复杂一点,比如我们可以通过cmp和jcc指令来完成一次跳转:
mov eax,o1
cmp eax,o2
jne L1
mov o1,1
mov o2,1
L1:
push 0
call ExitProcess
add esp,4
注意这里选择结构是一个jne,如果是je直接跳转的话逻辑上会有问题,这个部分就是 if(…) {…}的操作了,之后完成else操作:
mov eax,o1
cmp eax,o2
jne L1
mov o1,1
mov o2,1
jmp L2
L1:
mov o1,2
mov o2,2
L2:
push 0
call ExitProcess
add esp,4
注意在执行完if后要跳过else的部分,不然逻辑上有问题
循环结构:
while循环
:
与if else相差不大,主要是程序逻辑上的问题,下面是一个实现例子:
mov eax,100
L2:
cmp eax,x
jna L1
inc x
jmp L2
L1:
push 0
call ExitProcess
add esp,4
条件控制伪指令:
.if .endif:
mov eax,100
.if eax > o1
inc eax
.elseif eax < o1
dec eax
.else
add eax,2
.endif
push 0
call ExitProcess
add esp,4
注意这个伪指令只有在VS下的masm中才有,正常的汇编中是没有这个伪指令的
.while .endw:
.while eax < 100
inc eax
.endw
push 0
call ExitProcess
add esp,4
还有一种while循环的写法,但是类似于do while循环:
mov eax,0
.repeat
inc eax
.until eax == 100
push 0
call ExitProcess
add esp,4
移位与循环移位指令:
逻辑移位:移出的一位放在CF中,原数据因移位而空缺的部分用0填充
算术移位:移出的一位放在CF中,原数据因移位而空缺的部分用标志位填充
SHL : 左移 SHR:右移 SAL:算术左移 SAR:算术右移 ROL:循环左移 ROR:循环右移
循环移位:将因移位丢弃的那一位补到相应的空缺上
带进位的循环移位:将因为移位丢弃的那一位填入CF中,在下一次循环移位时将CF中的这一位补进新数据的低位中,CF再接受新的移出的一位
双精度移位操作:拥有三个操作数o1(目的操作数),o2(源操作数),o3(位移位数):第一操作数向移动o3位,其“空出”的低位由第二操作数o2的高o3位来填补,但第二操作数自己不移动、不改变。
乘法与除法指令:
无符号: mul div
有符号:imul idiv
mul:只有一个操作数,这个操作数作为乘数,在x86中被乘数被统一设置为ax,这个操作的结果存放在ax中
imul:这个指令有三种模式:单操作数,双操作数,三操作数。
单操作数格式
(与mul相似)
单操作数格式将乘积存放在 AX、DX:AX 或 EDX:EAX 中
双操作数格式(32位模式)
32 位模式中的双操作数 IMUL 指令把乘积存放在第一个操作数中,
这个操作数必须是寄存器
。第二个操作数(乘数)可以是寄存器、内存操作数和立 即数。
三操作数格式
:
32 位模式下的三操作数格式将乘积保存在第一个操作数中。第二个操作数可以是 16 位寄存器或内存操作数,它与第三个操作数相乘,该操作数是一个8位或16 位立即数:
div:单操作数指令,后面跟的操作数作为除数,被除数是AX:DX中的值,运算结果的商放在ax中,余数放在dx中(在8位的情况下,余数放在AH中)
idiv:这个指令与div唯一的不同就是在使用前要先对被除数进行一次符号位扩展,比如al就用cbw(字节转字),ax就使用cwd(单字转双字),eax就使用cdq(双字转四字)
扩展加减法:
扩展加法:adc: 功能: OPRD1<–OPRD1 + OPRD2 + CF(带上了进位标志位一起运算)
扩展减法:sbb:是进行两个操作数的相减再减去CF进位标志位,即从OPRD1<–OPRD1-OPRD2-CF,其结 —- 果放在OPDR1中.指令的类型及对标志 位的影响与ADD指令相同,注意立即数不能用于目的操作数,
两个存储器操作数之间不能直接相减
.操作数可为8位或16位的无符号数或带符号数.
扩展加减法等于是将一个比较长的数分割,edx中存入高位,eax中存入低位,这样就可以通过32位完成64位的操作
ASCII与非压缩十进制运算:
计算机中的十进制数分为两种运算方式:压缩方式和非压缩方式。
举个例子:一个ASCII字符串:3402
在压缩的情况下它可以写为:33 34 30 32(也就是ASCII格式,在ASCII码中0到9的字符对应的数值是:30到39)
非压缩模式下是:03 04 00 02
在进行ASCII码模式下的加减时要将结果用一组特殊的指令处理后才能正常输出:
AAA(加法) AAS(减法) AAM(乘法) AAD(除法)
这一组指令在本质上来说就是将一个相加后的结果拆成两个部分(拆成非压缩的BCD码模式)
AAA具体算法:
(1)如果al的低4位是在0到9之间,保留低4位,清除高4位,如果al的低4位在10到15之间,则通过加6,来使得低4位在0到9之间,然后再对高4位清零。
(2)如果al的低4位是在0到9之间,ah值不变,CF和AF标志清零,否则,ah=ah+1,并设置CF和AF标志。
AAS具体算法:
若AL寄存器的低4位>9或AF=1,则:
(1)AL=AL-6,AF置1;
(2)将AL寄存器高4位清零;
(3)AH=AH-1,CF置1。
否则,不需要调整。
在ASCII运算后要进行一个or 3030h的操作,这是为了将结果从数学上数字转化为ACII码中对应的数字
使用示例:
xor eax,eax
xor ebx,ebx
xor edx,edx
mov ah,0
mov al,8
add al,9
aaa
AF与CF的区别
共同点:AF跟CF一样是进位(借位)的标志寄存器
不同点:8位运算或16位运算时如果有进位或借位CF就等于1,而4位运算时如果有进位或借位AF就等于1。AF是为了在BCD码运算时,要用到的,因为BCD码是以4位表示的。
过程相关伪指令:
invoke指令:这是关于函数调用的一个伪指令,但是只能在32位的环境下使用,它可以代替call指令(需要包含windows.inc)
它比call方便在它可以直接在调用函数时传参,就不用再在栈中压入参数,例子如下:
invoke ExitProcess,0
ADDR指令:这个指令是与invoke指令配合使用,用于获取先前定义的某个变量的偏移地址。这个指令类似于offset指令,但是有两点不同:一是ADDR只能配合invoke使用,二是ADDR既可以用于获取全局变量的偏移地址也可以用于获取局部变量的偏移地址而offset只能用于获取全局变量的偏移地址
proc指令:关于进程开始的指令,前面也多次使用过。这个指令用于标志进程的开始,一般是与endp和end一起出现
proto指令:功能和高级语言中的函数声明一样,在代码最前面写函数声明,在后面写函数定义,例如:
ExitProcess PROTO o1 dword
在代码最前面加上这一句话,即使在头文件中没有调用Windows.inc这个头文件也可以使用ExitProcess这个API函数
字符串相关操作:
传送:
movsb movsw mosd(分别是byte word dword)
拥有两个操作数,通常与重复指令REP配合使用,REP指令的作用就是在ecx不为0时循环,类似于loop指令(但是rep指令只能用于一条字符串操作的指令,loop可以针对指令块)
在进行串操作时需要改变的标志寄存器和通用寄存器是DF(方向寄存器)和esi(源串) edi(目的串)
当DF为1时,每次操作后esi edi递减
为0时,每次操作后esi edi递增
传送的操作实例:
cld
mov esi,offset string1
mov edi,offset string2
mov ecx,9
rep movsb
mov eax,eax
比较:
cmpsb cmpsw cmpsd(与传送的操作差不多)
跟前面的cmp指令相差不多,完成后会设置标志位,一般配合jcc指令运用:
lp1:
cld
mov esi,offset string1
mov edi,offset string2
cmpsb
ja lp1
扫描
:
scasb scasw scasd(相同原理)
就是在一个字符串中找另一个字符串,需要寻找的字符串放在AX(AL,AX,EAX)中,示例:
lp1:
cld
mov edi,offset string1
;mov edi,offset string2
mov al,'d'
mov ecx,lengthof string1
repne scasb ;当搜寻结果不为0时重复(也就是没找到时)
jnz lp1
因为在比较成功后会把zf标志位置1,所以在比较成功后就不会跳转,注意目标字符串是指向edi的,需要搜索的字符串放在AX中。
当需要比较一个较长的字符串时,可以将需要比较的字符串分割为一个一个比较小的字符串再挨个比较
保存
:
stosb stosw stosd(相同原理)
将字符串存入edi中指向的偏移位置,示例:
mov al,0FFh
mov edi,offset string
mov ecx,100
cld
rep stosb
与扫描一样,需要保存的字符串放在AX中
加载
:
lodsb lodsw lodsd(相同原理)
可以理解为保存的镜像操作,将一个字节(或字或双字)保存进AX(AL,EAX)中
结构与宏:
在汇编中也可以像C语言中一样定义结构体,使用一个struct关键,具体用法如下:
mystruct struct
member1 dw ?
member2 dw ?
mystruct ends
.data
s1 mystruct <>
.code
entry proc
xor eax,eax
mov s1.member1,1
mov ax,s1.member1
mov eax,eax
entry endp
end entry
结构体的定义是在数据段之外,但是声明是在数据段之中声明
宏的定义是通过这一对指令:MACRO ENDM,具体写法如下:
h1 macro para
mov eax,para
endm
也是定义在数据段前,在进程中可以直接调用:
.code
entry proc
h1 9
entry endp
end entry
浮点数:
首先将数据转化为二进制模式,然后变成科学计数法的写法,然后:
1.看符号位,正数为0,负数为1
2.将数转化为相应的二进制数
3.用科学记数法转化为相应的形式 如:1.xxxxxx*2^n()
4.n为指数,加上127
5…转化后用二进制拼接写出
例如12.25这个数:
1.是正数,符号位为0
2.12.25的二进制数为1100.01
3.用科学记数法表示为 1.10001*2^3(整数部分为1100,小数部分为01,小数点向左移动,每移动一次加一,遇1停止 即为n的算法)
可得 指数n为3,尾数部分为10001
4.指数n加上127 3+127=130转化为二进制为10000010
5.尾数位为10001000000000000000000(当不足23位时,低位补0填充)
拼接后为0 10000010 10001000000000000000000
当数为负数也是同样的道理
注:为什么要加127呢,十进制127用二进制表示数01111111,IEEE码规定指数域小于01111111为负数,大于为正数,所以01111111为0
浮点数的操作指令一般加上一个F就可以了,例如FSUB
内联汇编:
这个操作也就是在C/C++里直接写汇编代码,gcc中的内联汇编与VC中不太一样,后面如果要学在介绍,下面是一个简单的例子:
#include<iostream>
using namespace std;
int main()
{
int val1 = 10;
_asm {
mov ebx, eax
mov ecx,val1
}
return 0;
}
数据转化为二进制模式,然后变成科学计数法的写法,然后:
1.看符号位,正数为0,负数为1
2.将数转化为相应的二进制数
3.用科学记数法转化为相应的形式 如:1.xxxxxx*2^n()
4.n为指数,加上127
5…转化后用二进制拼接写出
例如12.25这个数:
1.是正数,符号位为0
2.12.25的二进制数为1100.01
3.用科学记数法表示为 1.10001*2^3(整数部分为1100,小数部分为01,小数点向左移动,每移动一次加一,遇1停止 即为n的算法)
可得 指数n为3,尾数部分为10001
4.指数n加上127 3+127=130转化为二进制为10000010
5.尾数位为10001000000000000000000(当不足23位时,低位补0填充)
拼接后为0 10000010 10001000000000000000000
当数为负数也是同样的道理
注:为什么要加127呢,十进制127用二进制表示数01111111,IEEE码规定指数域小于01111111为负数,大于为正数,所以01111111为0
浮点数的操作指令一般加上一个F就可以了,例如FSUB