目录
分类任务中的样本不均衡及hard negative mining的必要性
在训练一个分类器的时候,对数据的要求是class balance,即不同标签的样本量都要充足且相仿。然而,这个要求在现实应用中往往很难得到保证。
在目标检测算法中,对于输入的一张图像,可能会生成成千上万的预选框(region proposal),但是其中只有很少一部分是包含真实目标的,这就带来了类别不均衡问题。
类别不平衡时,无用的易分反例样本(easy negative sample)会使得模型的整体学习方向跑偏,导致无效学习,即只能分辨出没有物体的背景,而无法分辨具体的物体。(因为在使用cross-entropy loss做
mini-batch SGD时,是大量的样本产生的loss
average
之后计算gradient以及实施参数update
。
这个average的操作是有问题的,因为一个batch里面easy sample占绝大多数,hard sample只占很少部分,如果没有re-weighting或者importance balancing,那么在average之后,hard sample的contribution完全就被easy samples侵蚀平均抹掉了
。事实上,
往往这些hard samples,才是分类器性能进一步提升的bottleneck
(hard sample:很少出现但是现实存在的那些极端样本,比如车辆跟踪中出过事故的车辆。))
hard negative example
那么负样本中哪些是困难负样本(hard negative)呢?
困难负样本是指哪些容易被网络预测为正样本的proposal,即假阳性(false positive)
,
- 分类任务:虽然是负样本,但其预测为正的概率较高(如果p=0.5则判断为正样本,那么p=0.49就属于hard negative)
- 检测任务:如roi里有二分之一个目标时,虽然它仍是负样本,却容易被判断为正样本,这块roi即为hard negative;
- 度量学习:与anchor(正样本)距离较近的负样本就是hard negative
训练hard negative对提升网络的分类性能具有极大帮助,因为它相当于一个错题集。
如何判断它为困难负样本呢?也很简单,
我们先用初始样本集(即第一帧随机选择的正负样本)去训练网络,再用训练好的网络去预测负样本集中剩余的负样本,选择其中得分最高,即最容易被判断为正样本的负样本为困难样本
。
HEM(hard example/negative mining) 与 OHEM(online hard example mining)
HEM核心思想:
- 分类任务:用分类器对样本进行分类,把其中错误分类的样本(hard negative)放入负样本集合再继续训练分类器。
- 度量学习:度量学习中也有hard example/negative mining的概念。度量学习中的HEM是指找出与anchor(正样本)距离较近的负样本。
如何进行HEM? 重构训练数据集
以目标检测框算法为例:对于目标检测中我们会事先标记处ground truth,然后再算法中会生成一系列proposals,proposals与ground truth的IOU超过一定阈值(通常0.5)的则认定为是正样本,低于一定阈值的则是负样本。然后扔进网络中训练。However,这也许会出现一个问题那就是正样本的数量远远小于负样本,这样训练出来的分类器的效果总是有限的,会出现许多false positive。
把其中得分较高的这些false positive当做所谓的Hard negative,既然mining出了这些Hard negative,就把这些扔进网络再训练一次,从而加强分类器判别假阳性的能力
。
如何进行OHEM?在训练过程中通过loss(分类loss、roi loss等)进行选取
-
分类loss:
制定规则去选取hard negative: DenseBox
核心思想:选取与label差别大(分类loss)的作为hard negtive
根据制定的规则选取了hard negative ,在训练的时候加强对hard negative的训练。
In the forward propagation phase, we sort the loss of output pixels in decending order, and assign the top 1% to be hard-negative. In all experiments, we keep all positive labeled pixels(samples) and the ratio of positive and negative to be 1:1. Among all negative samples, half of them are sampled from hard-negative samples, and the remaining half are selected randomly from non-hard negative. -
ROI loss
一个只读的RoI网络对特征图和所有RoI进行前向传播,然后Hard RoI module利用这些RoI的loss选择B个样本。这些选择出的样本(hard examples)进入RoI网络,进一步进行前向和后向传播。
focal loss
二分类和多分类的focal loss的tensorflow 代码实现
多分类focalloss的pytorch实现
先前也有一些算法来处理类别不均衡的问题,比如OHEM(online hard example mining),OHEM的主要思想可以用原文的一句话概括:In OHEM each example is scored by its loss, non-maximum suppression (nms) is then applied, and
a minibatch is constructed with the highest-loss examples
。
OHEM算法虽然增加了错分类(正、负)样本的权重,但是OHEM算法忽略了容易分类的(正)样本
。
因此针对类别不均衡问题,作者提出一种新的损失函数:focal loss。
这个损失函数是在标准交叉熵损失基础上修改得到的。这个函数可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。
我理解的focal loss 是,利用一个re-weighting factor来modulating(re-weighting)每一个样本的importance,得到一个cost sensitve的classifier。
二分类focal loss
local loss的具体实现在此以二分类cross entropy loss举例:
无focal
:
L
(
p
,
y
)
=
−
(
y
⋅
log
(
p
)
+
(
1
−
y
)
⋅
log
(
1
−
p
)
)
L(p, y)=-(y \cdot \log (p)+(1-y) \cdot \log (1-p))
L
(
p
,
y
)
=
−
(
y
⋅
lo
g
(
p
)
+
(
1
−
y
)
⋅
lo
g
(
1
−
p
))
有focal(hard negative mining,加大难的负样本权重
):
L
(
p
,
y
)
=
−
(
y
⋅
(
1
−
p
)
⋅
log
(
p
)
+
(
1
−
y
)
⋅
p
⋅
log
(
1
−
p
)
)
L(p, y)=-(y \cdot(1-p) \cdot \log (p)+(1-y) \cdot p \cdot \log (1-p))
L
(
p
,
y
)
=
−
(
y
⋅
(
1
−
p
)
⋅
lo
g
(
p
)
+
(
1
−
y
)
⋅
p
⋅
lo
g
(
1
−
p
))
上式中p是classifer输出的[0,1]之间实数值,为预测概率,y是非0即1的label。将一个一维实数p进行二分类化的操作是令p指示label = 1为正样本的概率,另1-p指示label = 0为负样本的概率。
focal loss的核心就是直接用p作为modulating(re-weighting factor)
,当一个负样本很难时,p略小于0.5;easy negative则是p远小于0.5。所以
hard negative mining就体现在给1-p越小的negative(hard negative)乘以一个越大的factor(p)
。
更一般化的表示:
二分类任务的交叉熵损失函数公式如下:
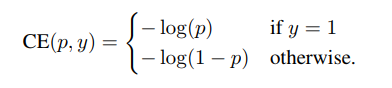
令pt代表如下意义
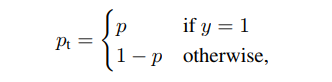
则二分类focal loss为
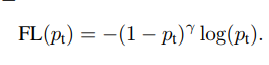
在此基础上可以进一步引进另一个调整权重的超参数a,
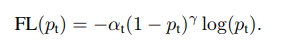
ps:在每一次预测时,真实标签的one-hot向量中,只有一项为1,其它项都为0,所以其focal loss只需计算为1的那一项。
def binary_focal_loss(y_true, y_pred,gamma=2.0, alpha=0.25):
# Define epsilon so that the backpropagation will not result in NaN
# for 0 divisor case
epsilon = K.epsilon()
# Add the epsilon to prediction value
#y_pred = y_pred + epsilon
# Clip the prediciton value
y_pred = K.clip(y_pred, epsilon, 1.0-epsilon)
# Calculate p_t
p_t = tf.where(K.equal(y_true, 1), y_pred, 1-y_pred)
# Calculate alpha_t
alpha_factor = K.ones_like(y_true)*alpha
alpha_t = tf.where(K.equal(y_true, 1), alpha_factor, 1-alpha_factor)
# Calculate cross entropy
cross_entropy = -K.log(p_t)
weight = alpha_t * K.pow((1-p_t), gamma)
# Calculate focal loss
loss = weight * cross_entropy
# Sum the losses in mini_batch
loss = K.sum(loss, axis=1)
return loss
多分类focal loss
对于多分类:
无focal:
H
(
p
,
q
)
=
−
∑
i
=
1
n
p
(
x
i
)
log
(
q
(
x
i
)
)
H(p, q)=-\sum_{i=1}^{n} p\left(x_{i}\right) \log \left(q\left(x_{i}\right)\right)
H
(
p
,
q
)
=
−
∑
i
=
1
n
p
(
x
i
)
lo
g
(
q
(
x
i
)
)
在机器学习中,将ground truth当作一个分布(P),将预测作为另一个分布(q),假设有cnum个类别(三分类问题cnum=3, 四分类问题cnum=4),那么就有:
H
(
p
,
q
)
=
−
∑
i
=
1
c
n
u
m
p
(
c
i
)
log
q
(
c
i
)
H(p, q)=-\sum_{i=1}^{c n u m} p\left(c_{i}\right) \log q\left(c_{i}\right)
H
(
p
,
q
)
=
−
∑
i
=
1
c
n
u
m
p
(
c
i
)
lo
g
q
(
c
i
)
假设有一个三分类问题,某个样例的正确答案是(1,0,0)。某模型经过Softmax回归之后的预测答案是(0.5,0,4,0.1),那么这个预测和正确答案直接的交叉熵是:
H(
(
1
,
0
,
0
)
,
(
0.5
,
0.4
,
0.1
)
)
=
−
(
1
×
log
0.5
+
0
×
log
0.4
+
0
×
log
0.1
)
≈
0.3
\mathrm{H}((1,0,0),(0.5,0.4,0.1))=-(1 \times \log 0.5+0 \times \log 0.4+0 \times \log 0.1) \approx 0.3
H
((
1
,
0
,
0
)
,
(
0.5
,
0.4
,
0.1
))
=
−
(
1
×
lo
g
0.5
+
0
×
lo
g
0.4
+
0
×
lo
g
0.1
)
≈
0.3
有focal(hard negative mining,加大难的负样本权重
):
在多分类任务中,
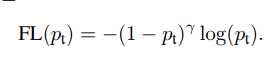
上述公式中的Pt用如下向量代替(其中乘法是向量内各元素的乘法,输出的pt是一个向量)
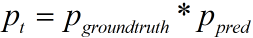
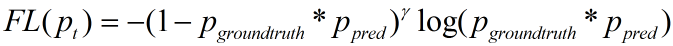
由于log函数中不能出现0,又因为Pgrountruth中只有一项不为0,所以将log函数中的Pgrountruth提到公式最前面:
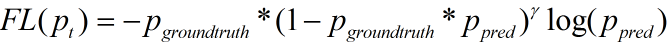
该表达式输出为一个向量(只有一项不为0),在此基础上用一个求和函数将各元素相加即为最终的loss值。在numpy中用reduce_sum或recuce_max函数实现.
https://blog.csdn.net/qq_39012149/article/details/96184383
在这篇文章中,描述了
多分类任务中,如何使用a参数(定义一个超参数数组,用于平衡各类别之间的权重)
*
从公式和代码看,
多分类并没有直接寻找到hard negative example,而是当正样本被预测道的概率较低时,将其对应的交叉熵的权重加大。(因为其公式中,groud_truth是one_hot表示,在计算交叉熵时,只有‘1’对应的正样本对应的预测概率被用上了,其它各个负样本由于对应的one_hot表示为’0’,所以没有真正计算进去)
# -*- coding: utf-8 -*-
import tensorflow as tf
"""
Tensorflow实现何凯明的Focal Loss, 该损失函数主要用于解决分类问题中的类别不平衡
focal_loss_sigmoid: 二分类loss
focal_loss_softmax: 多分类loss
Reference Paper : Focal Loss for Dense Object Detection
"""
def focal_loss_sigmoid(labels,logits,alpha=0.25,gamma=2):
"""
Computer focal loss for binary classification
Args:
labels: A int32 tensor of shape [batch_size].
logits: A float32 tensor of shape [batch_size].
alpha: A scalar for focal loss alpha hyper-parameter. If positive samples number
> negtive samples number, alpha < 0.5 and vice versa.
gamma: A scalar for focal loss gamma hyper-parameter.
Returns:
A tensor of the same shape as `lables`
"""
y_pred=tf.nn.sigmoid(logits)
labels=tf.to_float(labels)
L=-labels*(1-alpha)*((1-y_pred)*gamma)*tf.log(y_pred)-\
(1-labels)*alpha*(y_pred**gamma)*tf.log(1-y_pred)
return L
def focal_loss_softmax(labels,logits,gamma=2):
"""
Computer focal loss for multi classification
Args:
labels: A int32 tensor of shape [batch_size].
logits: A float32 tensor of shape [batch_size,num_classes].
gamma: A scalar for focal loss gamma hyper-parameter.
Returns:
A tensor of the same shape as `lables`
"""
y_pred=tf.nn.softmax(logits,dim=-1) # [batch_size,num_classes]
# To avoid divided by zero
epsilon = 1.e-7
y_pred += tf.epsilon() #一个很小的数值
labels=tf.one_hot(labels,depth=y_pred.shape[1])
L=-labels*((1-y_pred)**gamma)*tf.log(y_pred) #输出一个向量,向量中只有一项不为0
#将向量变为标量,由于向量中只有一项不为0,所以也可用reduce_max()
L=tf.reduce_sum(L,axis=1) #将向量变为标量。
return L
if __name__ == '__main__':
logits=tf.random_uniform(shape=[5],minval=-1,maxval=1,dtype=tf.float32)
labels=tf.Variable([0,1,0,0,1])
loss1=focal_loss_sigmoid(labels=labels,logits=logits)
logits2=tf.random_uniform(shape=[5,4],minval=-1,maxval=1,dtype=tf.float32)
labels2=tf.Variable([1,0,2,3,1])
loss2=focal_loss_softmax(labels==labels2,logits=logits2)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print sess.run(loss1)
print sess.run(loss2)
keras版本实现:
https://github.com/maozezhong/focal_loss_multi_class/blob/master/focal_loss.py
reference : https://spaces.ac.cn/archives/4493(提到了加入另外的防过拟合的函数)
GHM
参数target, label_weight的关系
官方代码中用于分类问题的GHMC损失函数的部分代码如下:
def forward(self, pred, target, label_weight, *args, **kwargs):
"""Calculate the GHM-C loss.
Args:
pred (float tensor of size [batch_num, class_num]):
The direct prediction of classification fc layer.
target (float tensor of size [batch_num, class_num]):
Binary class target for each sample.
label_weight (float tensor of size [batch_num, class_num]):
the value is 1 if the sample is valid and 0 if ignored.
Returns:
The gradient harmonized loss.
"""
# the target should be binary class label
if pred.dim() != target.dim():
target, label_weight = _expand_binary_labels(
target, label_weight, pred.size(-1))
target, label_weight = target.float(), label_weight.float()
edges = self.edges
mmt = self.momentum
weights = torch.zeros_like(pred)
需要注意的是,参数target要求是one-hot编码形式,如果不是one-hot形式,则要通过_expand_binary_labels扩展成one-hot形式。
而参数label_weight则表示该标签是否要进行GHM操作,默认都是全1。而且,
label_weight的维度必须与target保持一致,即如果target采用one-hot(形如 [batch_num, class_num]),则label_weight的size也是 [batch_num, class_num],如果target的size是 [batch_num],那么label_weight的size也必须是[batch_num]。
非one-hot情况下,labels是从0还是从1开始编码
官方代码中,_expand_binary_labels定义如下
def _expand_binary_labels(labels, label_weights, label_channels):
bin_labels = labels.new_full((labels.size(0), label_channels), 0)
inds = torch.nonzero(labels >= 1).squeeze()
if inds.numel() > 0:
bin_labels[inds, labels[inds] - 1] = 1
bin_label_weights = label_weights.view(-1, 1).expand(
label_weights.size(0), label_channels)
return bin_labels, bin_label_weights
官方代码这种写法,认为labels(类别)的编码是从1开始的,不是从0开始的。
但很多情况下,
我们输入的labels(类别)编码是从0开始的。因此需要对代码进行修改,
如下所示:
def _expand_binary_labels(self, labels, label_weights, label_channels):
# expand labels
bin_labels = labels.new_full((labels.size(0), label_channels), 0)
# inds = torch.nonzero(labels >= 1).squeeze() #假设labels是从1开始编号
inds = torch.nonzero(labels >= 0).squeeze() #加谁labels是从0开始编号
if inds.numel() > 0:
# bin_labels[inds, labels[inds] - 1] = 1 #假设labels是从1开始编号
bin_labels[inds, labels[inds]] = 1 #假设labels是从0开始编号
# expand label_weights(label_weight should with size [batch_num], otherwise the function "expand" cannot work)
bin_label_weights = label_weights.view(-1, 1).expand(
label_weights.size(0), label_channels)
return bin_labels, bin_label_weights
难例挖掘的相关领域:长尾分布下的分类
-
Class-Balanced Loss Based on Effective Number of Samples
解读:
使用一个特别设计的损失来处理类别不均衡的数据集
-
Learning to Reweight Examples for Robust Deep Learning
源码
知乎解读:https://zhuanlan.zhihu.com/p/37477502
更简单的理解就是,以前我们算training loss的时候,选取一个mini batch。现在,为了给每个batch内的样本重新分配权重,使用一个valid set中的mini batch计算validation loss, 根据validation loss计算权重。training loss 更新的是模型参数,而validation loss更新的是权重,也就是超参数。这就是元学习。
如果训练样本分布和验证样本分布相似,它们的梯度方向也接近,那么这样的样本比较好,需要增加权重,反之则需要降低权重。这样的样本权重分配方式能够使得模型变得无偏
XMB—Cross-Batch Memory for Embedding Learning
跨越时空的难样本挖掘
代码:https://link.zhihu.com/?target=https%3A//github.com/msight-tech/research-xbm
由易到难 Curriculum Learning与Self-paced Learning