目录
1 BIO同步阻塞IO

1.1 特性:同步阻塞IO
1.2 特点:一个请求对应一个线程,上下文切换占用的资源很重。
1.3 缺点:无用的请求也会占用一个线程,没有数据达到,也会阻塞。
1.4 改进:通过线程池机制。 但是还是未能解决一个请求一个线程的本质问题,只是稍加改善。
1.5 试用场景:链接数目较少,固定请求。程序比较清晰,一个请求一个线程,容易理解。要求机器配置较高。
2 NIO同步非阻塞IO

2.1 特性:同步非阻塞IO
2.2 特点:利用IO多路复用技术+NIO,多个socket通道对应一个线程
2.3 复用: 多路复用技术:select,poll和epoll ,linux系统下利用epoll多路复用技术性能更高。
2.4 虚拟内存映射文件操作,不需要read或write操作,虚拟内存相当于缓冲区,提升性能。
2.5 修改文件自动flush到文件
2.6 快速处理大文件
IO多路复用:I/O是指网络I/O,多路指多个TCP连接(即socket或者channel),复用指复用一个或几个线程。意思说一个或一组线程处理多个TCP连接。最大优势是减少系统开销小,不必创建过多的进程/线程,也不必维护这些进程/线程。
IO多路复用使用两个系统调用(select/poll/epoll和recvfrom),blocking IO只调用了recvfrom;select/poll/epoll 核心是可以同时处理多个connection,而不是更快,所以连接数不高的话,性能不一定比多线程+阻塞IO好,多路复用模型中,每一个socket,设置为non-blocking,阻塞是被select这个函数block,而不是被socket阻塞的。
3 select机制
客户端操作服务器时就会产生这三种文件描述符(简称fd):writefds(写)、readfds(读)、和exceptfds(异常)。select会阻塞住监视3类文件描述符,等有数据、可读、可写、出异常 或超时、就会返回;返回后通过遍历fdset整个数组来找到就绪的描述符fd,然后进行对应的IO操作。
优点:
几乎在所有的平台上支持,跨平台支持性好
缺点:
由于是采用轮询方式全盘扫描,会随着文件描述符FD数量增多而性能下降。 每次调用 select(),需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间) 默认单个进程打开的FD有限制是1024个,可修改宏定义,但是效率仍然慢。
3.1 poll机制
基本原理与select一致,也是轮询+遍历;唯一的区别就是poll没有最大文件描述符限制(使用链表的方式存储fd)。
3.2 epoll机制
没有fd个数限制,用户态拷贝到内核态只需要一次,使用时间通知机制来触发。通过epoll_ctl注册fd,一旦fd就绪就会通过callback回调机制来激活对应fd,进行相关的io操作。 epoll之所以高性能是得益于它的三个函数
1)epoll_create()系统启动时,在Linux内核里面申请一个B+树结构文件系统,返回epoll对象,也是一个fd
2)epoll_ctl() 每新建一个连接,都通过该函数操作epoll对象,在这个对象里面修改添加删除对应的链接fd, 绑定一个callback函数
3)epoll_wait() 轮训所有的callback集合,并完成对应的IO操作
优点:
没fd这个限制,所支持的FD上限是操作系统的最大文件句柄数,1G内存大概支持10万个句柄效率提高,使用回调通知而不是轮询的方式,不会随着FD数目的增加效率下降
内核和用户空间mmap同一块内存实现(mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间)
例子:
100万个连接,里面有1万个连接是活跃,我们可以对比 select、poll、epoll 的性能表现
select:不修改宏定义默认是1024,l则需要100w/1024=977个进程才可以支持 100万连接,会使得CPU性能特别的差。
poll: 没有最大文件描述符限制,100万个链接则需要100w个fd,遍历都响应不过来了,还有空间的拷贝消耗大量的资源。
epoll: 请求进来时就创建fd并绑定一个callback,主需要遍历1w个活跃连接的callback即可,即高效又不用内存拷贝。

简单来说:select和poll会一直循环遍历所有的连接事件,cpu会空转消耗资源。而epoll解决了这些问题,只有时间发送才会进行操作,select最多支持1024个连接而jdk1.4版本poll无上限,jdk1.5解决了所有问题。
4 Java中的IO模型
在JDK1.4之前,基于Java所有的socket通信都采⽤了同步阻塞模型(BIO),这种模型性能低下,当时⼤型的服务均采⽤C或C++开发,因为它们可以直接使⽤操作系统提供的异步IO或者AIO,使得性能得到⼤幅提升。
2002年,JDK1.4发布,新增了java.nio包,提供了许多异步IO开发的API和类库。新增的NIO,极⼤的促进了基于Java的异步⾮阻塞的发展和应⽤。
2011年,JDK7发布,将原有的NIO进⾏了升级,称为NIO2.0,其中也对AIO进⾏了⽀持
4.1 BIO模型
java中的BIO是blocking I/O的简称,它是同步阻塞型IO,其相关的类和接⼝在java.io下。
BIO模型简单来讲,就是服务端为每⼀个请求都分配⼀个线程进⾏处理,如下:

示例代码:
public class BIOServer {
public static void main(String[] args) throws Exception {
ServerSocket serverSocket = new ServerSocket(6666);
ExecutorService executorService = Executors.newCachedThreadPool();
while (true) {
System.out.println("等待客户端连接。。。。");
Socket socket = serverSocket.accept(); //阻塞
executorService.execute(() -> {
try {
InputStream inputStream = socket.getInputStream(); //阻塞
byte[] bytes = new byte[1024];
while (true){
int length = inputStream.read(bytes);
if(length == -1){
break;
}
System.out.println(new String(bytes, 0, length, "UTF-
8"));
}
} catch (Exception e) {
e.printStackTrace();
}
});
}
}
}
这种模式存在的问题:
客户端的并发数与后端的线程数成1:1的⽐例,线程的创建、销毁是⾮常消耗系统资源的,随着并
发量增⼤,服务端性能将显著下降,甚⾄会发⽣线程堆栈溢出等错误。
当连接创建后,如果该线程没有操作时,会进⾏阻塞操作,这样极⼤的浪费了服务器资源。
4.2 NIO模型
NIO,称之为New IO 或是 non-block IO (⾮阻塞IO),这两种说法都可以,其实称之为⾮阻塞IO更恰当⼀些。
NIO相关的代码都放在了java.nio包下,其三⼤核⼼组件:Buffer(缓冲区)、Channel(通道)、Selector(选择器/多路复⽤器)
Buffer
在NIO中,所有的读写操作都是基于缓冲区完成的,底层是通过数组实现的,常⽤的缓冲区是
ByteBuffer,每⼀种java基本类型都有对应的缓冲区对象(除了Boolean类型),如:
CharBuffer、IntBuffer、LongBuffer等。
Channel
在BIO中是基于Stream实现,⽽在NIO中是基于通道实现,与流不同的是,通道是双向的,
既可以读也可以写。
Selector

可以看出,NIO模型要优于BIO模型,主要是:
通过多路复⽤器就可以实现⼀个线程处理多个通道,避免了多线程之间的上下⽂切换导致系统开销
过⼤。
NIO⽆需为每⼀个连接开⼀个线程处理,并且只有通道真正有有事件时,才进⾏读写操作,这样⼤
⼤的减少了系统开销。
示例代码:
public class SelectorDemo {
/**
* 注册事件
*
* @return
*/
private Selector getSelector() throws Exception {
//获取selector对象
Selector selector = Selector.open();
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.configureBlocking(false); //⾮阻塞
//获取通道并且绑定端⼝
ServerSocket socket = serverSocketChannel.socket();
socket.bind(new InetSocketAddress(6677));
//注册感兴趣的事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
return selector;
}
public void listen() throws Exception {
Selector selector = this.getSelector();
while (true) {
selector.select(); //该⽅法会阻塞,直到⾄少有⼀个事件的发⽣
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey selectionKey = iterator.next();
process(selectionKey, selector);
iterator.remove();
}
}
}
private void process(SelectionKey key, Selector selector) throws Exception
{
if(key.isAcceptable()){ //新连接请求
ServerSocketChannel server = (ServerSocketChannel)key.channel();
SocketChannel channel = server.accept();
channel.configureBlocking(false); //⾮阻塞
channel.register(selector, SelectionKey.OP_READ);
}else if(key.isReadable()){ //读数据
SocketChannel channel = (SocketChannel)key.channel();
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
channel.read(byteBuffer);
System.out.println("form 客户端 " + new String(byteBuffer.array(),
0, byteBuffer.position()));
}
}
public static void main(String[] args) throws Exception {
new SelectorDemo().listen();
}
}
4.3 AIO模型
在NIO中,Selector多路复⽤器在做轮询时,如果没有事件发⽣,也会进⾏阻塞,如何能把这个阻塞也优化掉呢?那么AIO就在这样的背景下诞⽣了。
AIO是asynchronous I/O的简称,是异步IO,该异步IO是需要依赖于操作系统底层的异步IO实现。
AIO的基本流程是:⽤户线程通过系统调⽤,告知kernel内核启动某个IO操作,⽤户线程返回。kernel内核在整个IO操作(包括数据准备、数据复制)完成后,通知⽤户程序,⽤户执⾏后续的业务操作。
kernel的数据准备
将数据从⽹络物理设备(⽹卡)读取到内核缓冲区。
kernel的数据复制
将数据从内核缓冲区拷⻉到⽤户程序空间的缓冲区。
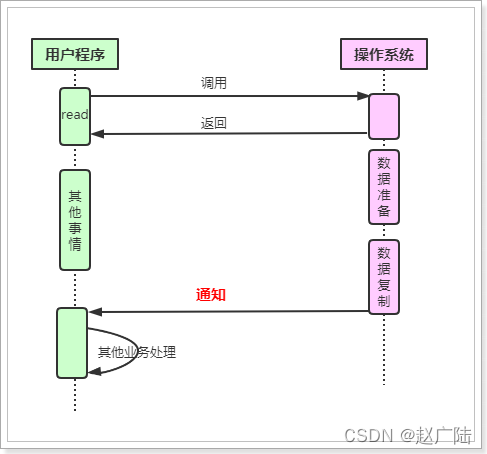
⽬前AIO模型存在的不⾜:
需要完成事件的注册与传递,这⾥边需要底层操作系统提供⼤量的⽀持,去做⼤量的⼯作。
Windows 系统下通过 IOCP 实现了真正的异步 I/O。但是,就⽬前的业界形式来说,Windows 系
统,很少作为百万级以上或者说⾼并发应⽤的服务器操作系统来使⽤。
⽽在 Linux 系统下,异步IO模型在2.6版本才引⼊,⽬前并不完善。所以,这也是在 Linux 下,实
现⾼并发⽹络编程时都是以 NIO 多路复⽤模型模式为主。