在日常工作的过程中,难免会遇到条件查询,接下来就来了解一下Specification条件查询。
要使用Specification条件查询,我们需要再继承JpaSpecificationExecutor接口。
public interface PetDao extends JpaRepository<Pet,Integer>,
JpaSpecificationExecutor<Pet>{}
首先我们来看一下这个接口里有哪些方法。
public interface JpaSpecificationExecutor<T> {
Optional<T> findOne(@Nullable Specification<T> spec);
List<T> findAll(@Nullable Specification<T> spec);
Page<T> findAll(@Nullable Specification<T> spec, Pageable pageable);
List<T> findAll(@Nullable Specification<T> spec, Sort sort);
long count(@Nullable Specification<T> spec);
}
可以看到每个方法都有一个允许为空的Specification对象。接下来我们对每个方法都进行测试。
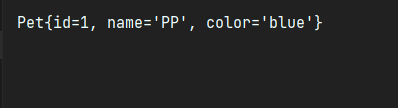
一、findOne()由方法名就可以看出是查询单条数据;我们查询一条id为1的数据且name为pp的数据。
Optional findOne(@Nullable Specification spec);
@Test
public void test09(){
Specification<Pet> specification = new Specification<Pet>() {
@Override
public Predicate toPredicate(Root<Pet> root, CriteriaQuery<?> query,
CriteriaBuilder builder) {
return query.where(
builder.equal(root.get("id"),1), //equal()相当于“=”
builder.equal(root.get("name"),"pp")
).getRestriction();
}
};
Optional<Pet> petOptional = petDao.findOne(specification);
if (petOptional.isPresent()) {
Pet pet = petOptional.get();
System.out.println(pet);
}
}
new 一个Specification会重写它的toPredicate方法,里面参数的含义分别是:
- root:得到查询的根,root.get(“变量名”),根据变量名查询。
- query:构建查询的顶层规则(where,from等)
- builder:构建查询的底层规则(equal,like,in等)
后面的getRestriction()方法的作用就是返回一个predicate对象。
结果:
二、findAll() 这个方法就是查询所有符合条件的列,返回的是一个List,或者分页查询的Page。
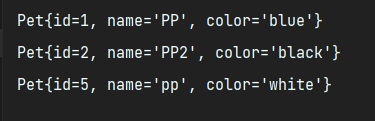
接下来用条件查询in,查询所有id为1,2,5的pet。这里我们直接使用lambda表达式,可以简化匿名内部类的写法。
List findAll(@Nullable Specification spec);
@Test
public void test11(){
Specification<Pet> specification = (root, query, builder) ->
query.where(
builder.in(root.get("id")).value(1).value(2).value(5)
).getRestriction();
List<Pet> all = petDao.findAll(specification);
all.forEach(System.out::println);
}
结果:
条件查询like,模糊查询,查询所有包含“p”的Pet。
@Test
public void test12(){
Specification<Pet> specification = (root, query, builder) ->
query.where(
builder.like(root.get("name"),'%'+"p"+"%")
).getRestriction();
List<Pet> all = petDao.findAll(specification);
all.forEach(System.out::println);
}
结果:

以上条件不变,分页展示查询出来的数据。
Page findAll(@Nullable Specification spec, Pageable pageable);
@Test
public void test13(){
Specification<Pet> specification = (root, query, builder) ->
query.where(
builder.like(root.get("name"),'%'+"p"+"%")
).getRestriction();
Pageable pageable = PageRequest.of(0,5);
Page<Pet> all = petDao.findAll(specification,pageable);
all.forEach(System.out::println);
System.out.println("总数量:"+all.getTotalElements());
System.out.println("总页码:"+all.getTotalPages());
System.out.println("当前页:"+(all.getNumber()));
System.out.println("页面记录数:"+(all.getSize()));
}
结果:由于页码是从0开始的,实际开发中,我们记得要把页码+1。

依旧使用上面的模糊查询,我们把查询结果按id排序(由大到小)。
List findAll(@Nullable Specification spec, Sort sort);
@Test
public void test14(){
Specification<Pet> specification = (root, query, builder) ->
query.where(
builder.like(root.get("name"),'%'+"p"+"%")
).getRestriction();
List<Pet> all = petDao.findAll(specification, Sort.by("id").descending());
all.forEach(System.out::println);
}
结果:

最后一个方法是
long count(@Nullable Specification spec);
它其实就是查询到的总记录数,返回的是一个long类型的数字。
@Test
public void test15(){
Specification<Pet> specification = (root, query, builder) ->
query.where(
builder.like(root.get("name"),'%'+"p"+"%")
).getRestriction();
long count = petDao.count(specification);
System.out.println(count);
}
结果:

以上都是使用query构建的顶层查询条件,其实我们也可以直接使用builder构建顶层查询条件。
使用builder构建单条件查询:
@Test
public void test16(){
Specification<Pet> specification = (root, query, builder) ->
builder.like(root.get("name"),'%'+"p"+"%");
List<Pet> all = petDao.findAll(specification);
all.forEach(System.out::println);
}
结果:

使用builder构建多条件查询:
@Test
public void test17(){
Specification<Pet> specification = (root, query, builder) ->
builder.and(
builder.equal(root.get("id"),2),
builder.like(root.get("name"),'%'+"p"+"%")
);
System.out.println(petDao.findOne(specification));
}
结果:

至于使用哪种就看实际场景和个人习惯了。