Scala总结终结篇
接Scala总结下篇
八、集合
8.13 自定义排序 SortWith
--自定义排序:
1.方法:sortWith(形参),返回值为经过自定义排序以后的集合;
2.形参:是一个函数,
函数形参为:集合中的两个元素,
参数1:第一个元素left;
参数2:第二个元素right;
函数返回值为:boolean类型,true和false
3.排序规则:
a、如果"left > right",则是左边的数据比右边的大,则是"降序"
b、如果"left < right",则是左边的数据比右边的小,则是"升序"
4.函数返回值:
a、当满足你的排序要求时,你就返回true
b、当不满足你的排序要求时,你就返回false
5.比较方式:在scala中,默认是指两两进行比较
6.默认排序规则:sortWith()默认是升序
val list = List(("a", 1), ("a", 5), ("c", 10))
//根据每个元组的第二个元素的值进行比较,此时为降序
val result: List[(String, Int)] = list.sortWith((left, right) => {
left._2 > right._2
})
println(result)//List((c,10), (a,5), (a,1))
/*
如下代码的逻辑为:
先比较元组中的第一个元素,按照字典的顺序进行降序排序;
如果第一个元素相等,则按照第二个元素的升序排序
*/
val result1 = list.sortWith((left, right) => {
if (left._1 > right._1) {
true
} else if (left._1 == right._1) {
left._2 < right._2
} else {
false
}
})
println(result1)//List((c,10), (a,1), (a,5))
8.14 集合的一些运算
8.14.1 并集 union
1. 并集,合集:求两个集合中所有的元素,可能会有重复的元素,不适用于Map和Set集合
2. 方法:union
val list1 = List(("a", 1), ("b", 2))
val list2 = List(("b", 2), ("c", 3))
println(list1.union(list2)) //List((a,1), (b,2), (b,2), (c,3))
8.14.2 交集 intersect
1. 交集:集合1和集合2的共同数据
2. 方法:intersect()
println(list1.intersect(list2)) //List((b,2))
8.14.3 差集 diff
1. 差集:集合1去除和集合2相同数据之后的数据集
2. 方法:diff()
println(list1.diff(list2)) //List((a,1))
println(list2.diff(list1)) //List((c,3))
8.14.4 拉链 zip
1. 关联,拉链:将集合1和集合2的数据按照索引相同的数据关联在一起
2. 方法:zip(),返回一个map集合
3. 注意:
a、返回值的集合的数据取决于个数少的集合
b、也可以自己关联自己
println(list1.zip(list2)) //List(((a,1),(b,2)), ((b,2),(c,3)))
println(list1.zip(list1)) //List(((a,1),(a,1)), ((b,2),(b,2)))
8.14.5 数据关联索引
1. 数据和数据的索引进行关联,返回一个map集合
2. 方法:zipWithIndex
println(list1.zipWithIndex)//List(((a,1),0), ((b,2),1))
8.14.6 滑动 sliding
1. 滑动:将数据的一部分作为整体来使用。
数据指定的范围进行滑动,可以将这个范围理解为滑动的窗口
2. 方法:sliding(形参),返回一个迭代器,迭代器中的元素是一个一个的集合
3. 形参:有两个参数:
参数1:size:窗口数据的长度
参数2:step:窗口滑动的步长,幅度 ,可选参数,默认步长为1
val slidlist = List(1,2,3,5,6,4,1)
val iterator: Iterator[List[Int]] = slidlist.sliding(3)
iterator.foreach(println)
// List(1, 2, 3)
// List(2, 3, 5)
// List(3, 5, 6)
// List(5, 6, 4)
// List(6, 4, 1)
val iterator1: Iterator[List[Int]] = slidlist.sliding(3,3)
iterator1.foreach(println)
// List(1, 2, 3)
// List(5, 6, 4)
// List(1)
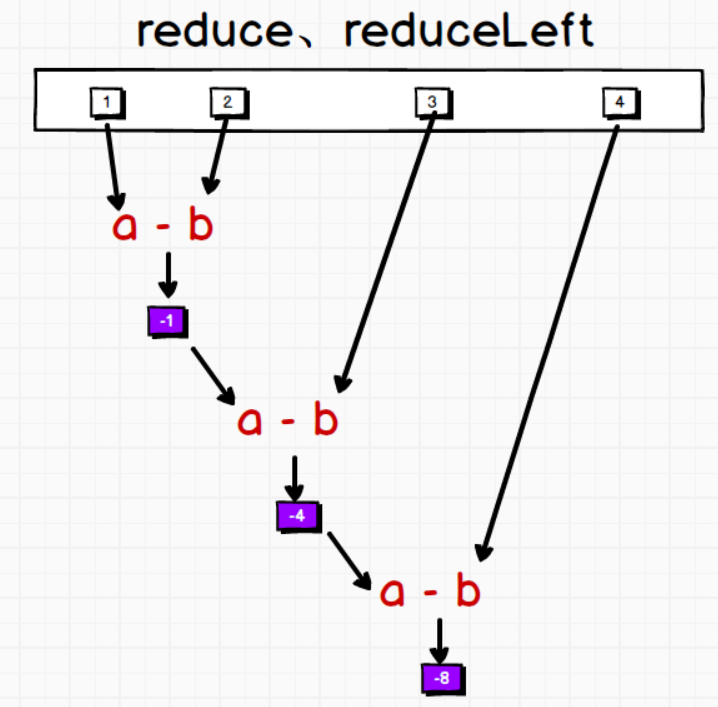
8.15 reduce
8.15.1 reduce
集合的自定义计算:简化,规约
1. 方法:reduce(op:(A1,A1)=>A1),递归形参中的函数,返回一个计算结果
2. 形参:是一个函数,函数的形参有两个参数,为集合中的两个元素,
要求这两个元素的数据类型一致,返回值和形参的数据类型保持一致.
3. 注意:当集合中的数据类型不一致,进行reduce计算时,会报类型匹配错误:type mismatch
val list = List(1,2,3,4)
val result: Int = list.reduce(_ + _)
println(result)// (((1 + 2) + 3) + 4) =10
val result1: Int = list.reduce(_ - _)
println(result1) // (((1 - 2) - 3) - 4) = -8
8.15.2 reduceLeft
1. 说明:reduce()方法的底层就是调用了reduceLeft()方法
2. 方法:reduceLeft(op:(B,Int)=>B),同样是通过递归调用参数的函数体进行计算,然后返回一个计算结果
3. 形参:是一个函数,函数有两个参数
参数1:B类型,集合中从左边开始的第一个元素的数据类型,与第二个参数类型是相关的,集合第一个元素
参数2:集合中数据类型,集合中的一个一个的元素
返回结果:函数的返回值类型与参数1的数据类型保持一致
4. 说明:何为参数1的数据类型与参数2的数据类型相关?
a、就是参数1和参数2在函数体中经过一系列计算以后,返回值的类型需要和参数1一致。
val list1 = List(5,10,0,2,3)
val l: Long = list1.reduceLeft(_ - _)
println(l) // ((((5 - 10) - 0) - 2) - 3) = -10
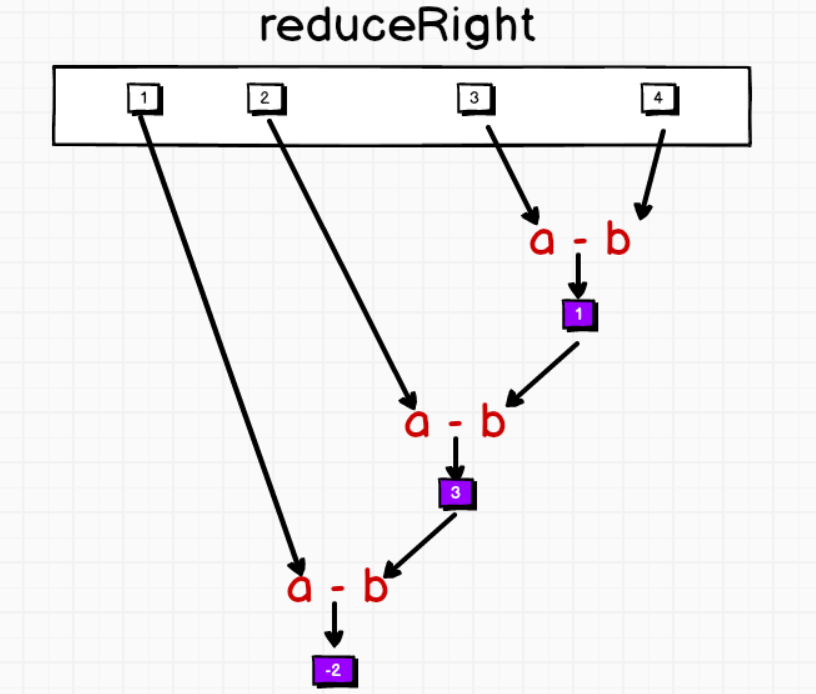
8.15.3 reduceRight
1. 方法:reduceRight(op:(B,Int)=>B):同样是通过递归调用参数的函数体进行计算,然后返回一个计算结果
2. 形参:是一个函数,
参数1:B类型,集合中从右边开始的第一个元素的数据类型,与第二个参数类型是相关的。
参数2:集合中数据类型,集合中的一个一个的元素
返回结果:函数的返回值类型与参数1的数据类型保持一致
3. 说明:底层转化为:reversed.reduceLeft[B]((x, y) => op(y, x))
转化过程:
假如:集合:(1,2,3,4,5),反转以后:
=> (5,4,3,2,1),反转参数1和参数2,本应该是5,4,反转以后,就变成4,5
第一轮:
=> 参数1: 4
参数2: 5
第二轮:
=> 参数1:3
参数2:第一轮计算结果
第三轮:
=> 参数1: 2
参数2:第二轮计算结果
val list1 = List(5,10,0,2,3)
val result3: Int = list1.reduceRight(_-_)
println(result3) // (5 - (10 - (0 - (2 - 3)))) = -4
8.15.4 总结reduce、reduceLeft、reduceRight
"总结":(reduce、reduceLeft),reduceRight计算方式: " 加括号"
a、left: 从左边加括号
b、right:从右边加括号
举例:
val list = List(1,5,4,3,4)
list.reduceLeft(_ - _ )
list.reduceRight(_ - _ )
计算过程:
left : ((((1 - 5 ) - 4 ) - 3 ) - 4 ) => -15
right: (1 - (5 - ( 4 - ( 3 - 4)))) => 1
| 方法 | 形参(均是一个函数,函数的形参如下) | 关系 |
|---|---|---|
| reduce (op:(A1,A1)=>A1 ) | 参数1、参数2、返回值类型三者保持一致,参数2为集合的数据类型 | 底层调用了reduceLeft() |
| reduceLeft (op:(B,Int)=>B) | 参数1与参数2的数据类型相关,返回值类型与参数1类型保持一致,参数2为集合的数据类型 | 与reduce()方唯一不同的函数形参的数据类型和返回值类型 |
| reduceRight(op:(B,Int)=>B) | 参数1与参数2的数据类型相关,返回值类型与参数1类型保持一致,参数2为集合的数据类型 | reversed.reduceLeft [B] ((x, y) => op(y, x)) ,在reduceLeft()的基础上,先将集合数据反转,然后将函数参数的顺序进行调换 |
关注方法的参数的数据类型。
8.16 折叠 fold
- fold
1. 折叠:将集合之外的数据和集合内部的数据进行聚合操作,聚合数据的方式是两两操作
2. 方法:fold(z:A1)(op:(A1:A1) =>A1),返回值类型与第一个参数列表的数据类型保持一致。
参数列表:两个参数列表,体现了函数的柯里化
参数列表1:z:A1 => zero:A1,表示数据处理的初始值
参数列表2:op:(A1:A1) =>A1,表示聚合函数的逻辑,与reduce()方法一样
参数列表中的三个参数类型需保持一致
3. 说明:
a、fold进行数据处理时,集合外的数据与集合内部的数据类型一般保持一致,也可以不一致。
b、在spark和scala源码中的z/zero均是表示初始值。
c、从源码的角度讲,fold方法的底层其实就是foldLeft
val list = List(1,2,3,4,5)
println(list.fold(2)(_ - _))//等价于(((((2 - 1) - 2) - 3) - 4) - 5) = -13
- foldLeft、foldRight
1. 折叠和reduce()方法一样,也是有foldLeft()和foldRight()方法,底层实现逻辑也是完全一样。
2. 注意:
a、第一个形参列表的数据作为第一个数据进行运算。
b、foldLeft((z:B)(op:(B,int)=>B)),形参列表1的数据类型需要和形参列表2中的函数第一个参数数据类型保持一致。
c、fold,foldLeft,foldRight方法的返回值类型为初始值的类型
println(list.foldRight(10)(_ - _))
// 计算过程:(1 - (2 - (3 - (4 - (5 - 10))))) = -7
println(list.foldLeft(10)(_ - _))
// 计算过程:(((((10 - 1) - 2) - 3) - 4) - 5) = -5
- 应用,合并集合
// TODO Scala - 集合 - 合并集合
// Map( a->1, b->2, c->3 )
// Map( a->4, d->5, c->6 )
// =>
// Map( a->5, b->2, d->5, c->9 )
val map1: Map[String, Int] = Map("a"->1,"b"->2,"c"->3)
val map2: mutable.Map[String, Int] = mutable.Map("a"->2,"d"->2,"c"->5)
//t 为集合map1中一个一个元素,map为每一次计算的结果,第一次递归时,是将map2集合赋值为map
val result: mutable.Map[String, Int] = map1.foldLeft(map2)((map, t) => {
val k: String = t._1
val v: Int = t._2
val num: Int = map.getOrElse(k, 0)
map.put(k, v + num)
map
})
println(result)
8.17 scan
scan和fold的方法逻辑是一样的,唯一区别就是fold返回最后的计算结果,scan会把每一次递归的计算结果都会保留下来
8.18 队列
1. Queue:普通队列
2. Dueue:双端队列,kafka就是双端队列,保证数据发送到kafka的topic中是有序的
3. BlockQueue:阻塞式队列
// 创建队列
val queue: mutable.Queue[String] = mutable.Queue[String]()
// 添加数据
queue.enqueue("scala", "java")
// 获取队列中的数据,按照队列中的数据顺序进行获取数据
val str1: String = queue.dequeue()
val str2: String = queue.dequeue()
println(str1)//scala
println(str2) //java
8.19 并行
val list = List(1,2,3,4,5)
list.par.foreach((i) =>{
println(Thread.currentThread().getName)
})
//scala-execution-context-global-14
//scala-execution-context-global-13
//scala-execution-context-global-12
//scala-execution-context-global-15
//scala-execution-context-global-16
list.foreach((i) =>{
println(Thread.currentThread().getName)
})
//main
//main
//main
//main
//main
8.20 集合练习
需求:
对每个省份里不同商品的点击率排行
val dataList = List(
("zhangsan", "河北", "鞋"),
("lisi", "河北", "衣服"),
("wangwu", "河北", "鞋"),
("zhangsan", "河南", "鞋"),
("lisi", "河南", "衣服"),
("wangwu", "河南", "鞋"),
("zhangsan", "河南", "鞋"),
("lisi", "河北", "衣服"),
("wangwu", "河北", "鞋"),
("zhangsan", "河北", "鞋"),
("lisi", "河北", "衣服"),
("wangwu", "河北", "帽子"),
("zhangsan", "河南", "鞋"),
("lisi", "河南", "衣服"),
("wangwu", "河南", "帽子"),
("zhangsan", "河南", "鞋"),
("lisi", "河北", "衣服"),
("wangwu", "河北", "帽子"),
("lisi", "河北", "衣服"),
("wangwu", "河北", "电脑"),
("zhangsan", "河南", "鞋"),
("lisi", "河南", "衣服"),
("wangwu", "河南", "电脑"),
("zhangsan", "河南", "电脑"),
("lisi", "河北", "衣服"),
("wangwu", "河北", "帽子")
)
- 代码
val result: Map[String, List[(String, Int)]] = dataList.map(t => {
(t._2, t._3)//去除用户名信息,结构转化,使用map,("河北,鞋子")
})
.groupBy(_._1)//按照省份进行分组,("河北",("河北,鞋子"))
.map(t => {
val list: List[(String, Int)] =
t._2.map(_._2) //将("河北,鞋子") -> ("鞋子")
.groupBy(pro => pro)
.map(tuple => {
(tuple._1, tuple._2.length)
})
.toList
.sortBy(_._2)(Ordering.Int.reverse)
(t._1, list)
})
println(result)
九、模式匹配
9.1 模式匹配介绍
-- scala中模式匹配与java中switch的区别
1. 模式匹配和java中的switch..case .. default的格式很类似,但是也有很多是不一样的。
2. java:switch具有穿透现象,就是不加break语句,逻辑一旦满足条件,则下面的所有分支都会执行
3. scala:没有switch语法,采用了模式匹配的方式代替了switch方法,但是功能比switch更强大
因为可以按照规则对数据或对象进行匹配。
-- scala中的模式匹配用法说明:
1. 每个分支后面的代码逻辑不需要使用break
2. 使用下滑线表示任意值,类似java中switch的default分支
3. 模式匹配的顺序,自上而下的匹配顺序,一旦匹配成功,就会执行匹配成功后面的逻辑代码,执行完成以后,就会跳出match方法
4. 如果全部匹配完成以后,都没有匹配成功,则会报异常
5. 默认分支放在分支结构中的顺序不同,执行会有差异,放在默认分支后面的所有匹配都是无法被执行的,所以默认分支
(case _)一般是放在所有分支的后面,模仿switch中的default
val age = 10
age match {
case _ => println("4")
case 1 => println("1")
case 2 => println("2")
case 3 => println("3")
}
9.2 模式匹配的应用
9.2.1 匹配常量
val name = "scala"
name match {
case "java" => println("java")
case "hadoop" => println("hadoop")
case "scala" => println("scala")
case _ => println("other")
}
9.2.2 匹配类型
1. Array[数据类型],中括号中的数据类型不是泛型,而是数组的数据类型,编译器编译时:
val array = Array("a","2","2")
=> String[] array = new String[]("a","2","2")
2. 类型匹配:不匹配泛型,只要类型一致,则匹配成功
3. 关于默认分支:如果我们使用到默认分支的参数,那么可以使用一个变量,并在匹配逻辑代码中应用
如果我们不使用,那么我们就可以使用下划线进行代替
4. 下划线还可以表示泛型中的任意类型,如List[_]
//将传递的值赋值给了case后面的变量,如i,s,m,...
def describe(x: Any) = {
x match {
case i: Int => i
case s: String => "String hello"
case m: List[_] => "List"
case c: Array[Int] => "Array[Int]"
case scala => "something else " + scala
}
}
val b: Byte = 10
val array = Array("a", "2", "2")
val list = List("s", "c")
println(describe(b)) //"something else " + 10
println(describe(array)) //something else [Ljava.lang.String;@11531931
println(describe(list)) //"List"
9.2.3 匹配数组
val array1 = Array(2, 2)
val result = array1 match {
case Array(1, _) => println("1,_")
case Array(0, _) => println("0,_")
case Array(_, 0) => println("_,0")
case Array(_, 1) => println("_,1")
case Array(x, y) => println(x + y)
case Array(_*) => println("_*")
}
println(result) //4
9.2.4 匹配元组
val list8 = List((0, 1), (2, 2), (2, 3), (4, 1))
for (tuple <- list8) {
tuple match {
case (0, _) => println("0....")
case (1, _) => println("1....")
case (2, _) => println("2....")
case (x, y) => println(x + y)
}
}
/* 0....
2....
2....
5
9.2.5 匹配列表
val list4 = List(1, 2, 3, 4)
val list5 = List(1, 2, 3)
val list6 = List(1, 2)
val list7 = List(1)
def describeList(list: List[_]) = {
list match {
case first :: second :: rest => println(first + " - " + second + " - " + rest)
}
println(describeList(list4))// 1 - 2 - List(3,4)
println(describeList(list5))// 1 - 2 - List(3)
println(describeList(list6))// 1 - 2 - List()
println(describeList(list7))//不行,报错
9.2.6 匹配对象
1. 进行匹配对象时,会自动调用unapply()方法,这里的匹配对象,"是匹配对象的属性是否相等"
2. unapply()方法,使用对象自动获取属性值
object Scala2_MatchObject {
def main(args: Array[String]): Unit = {
val emp = Emp("scala", 20)
emp match {
case Emp("scala", 20) => println("yes")
case _ => println("no")
}
}
}
class Emp(val name: String, val age: Int) {
}
object Emp {
def apply(name: String, age: Int): Emp = new Emp(name, age)
def unapply(emp: Emp): Option[(String, Int)] = Option((emp.name, emp.age))
}
9.3 样例类(重要)
1. 概念:使用关键字"case声明的类",称为样例类
2. 作用:专门用于匹配对象
3. 说明:
a、样例类在编译时,会自动生成伴生对象以及apply方法
b、样例类中参数默认是使用val声明的,所以参数其实就是类的属性
c、如果想要是属性可以进行修改,那么需要显示的使用var修饰参数
d、样例类自动生成的方法有:toString()/equals()/hashcode()/copy()/apply()/unapply()
e、样例类还实现了serilizable接口
f、在实际开发中,一般使用样例类,便于开发
object Scala3_CaseObject {
def main(args: Array[String]): Unit = {
//创建样例类的对象
val emp = Emp1("scala",20)
//进行模式匹配
emp match {
case Emp1("scala",21) => println("yes")
case other => println( other) //Emp1(scala,20)
}
}
}
//声明样例类
case class Emp1(name :String,age :Int)
9.4 模式匹配的应用
9.4.1 应用1
//应用1:将如下集合元组的第二元素乘于3
val list = List(("a", 1), ("b", 2), ("c", 3))
//方法1:使用map()进行结构转化
val newList: List[(String, Int)] = list.map(tuple => {
(tuple._1, tuple._2 * 3)
})
println(newList)
/*
方法2:map + 模式匹配的方法,集合的元素进行case模式匹配,这里属于元组匹配
map方法的小括号变成{},case后面的(),不是形参,而是一个元组
*/
val newList1: List[(String, Int)] = list.map { case (word, count) => (word, count * 3) }
println(newList1)
9.4.2 应用2
//应用2:取map中v的第二个元素
val map: Map[String, (String, Int)] = Map("a" -> ("aa", 1), "b" -> ("bb", 2))
//方法1:
val newMap1: immutable.Iterable[Int] = map.map(t => {
t._2._2
})
println(newMap1)
//方法2:使用map + 模式匹配
val newMap2: immutable.Iterable[Int] = map.map {
case (k1, (k2, count)) => {
count
}
}
println(newMap2)
9.4.3 应用3
//应用3:变量声明,元组匹配,使用变量直接赋值的方式
val (id, name, age) = (1, "scala", 20)
println(name)//scala
9.4.4 应用4
//应用4 : 循环匹配
map.foreach {
case (k1, (k2, count)) => {
println(count)
}
}
println("================")
9.4.5 应用5
//应用5 : 过滤数据
val array = Array(1, 2, 3, 5, 9, 10)
//打印奇数的值
//方法1:
array.foreach(num => {
if (num % 2 != 0) {
print(num + " ")
}
})
//方式2见偏函数
9.5 偏函数
1. 偏函数:使用模式匹配进行数据的处理
以偏概全:
偏:部分
全:整体
2. 作用:对一部分满足条件的数据进行处理
map函数不支持偏函数,支持全函数
3. 自定义偏函数语法:
val pef : PartialFunction(数据类型1,数据类型2) ={
函数体,使用模式匹配,来处理满足条件的数据
}
形参:数据类型1:调用函数的对象的元素类型
数据类型2:经过函数体处理以后的结果类型
4. 调用支持偏函数的函数,collect:采集,支持偏函数
5. 偏函数在一般情况下可以使用模式匹配进行代替
val list = List(1,2,"3",6,"4",5,10)
//方式一:采用声明偏函数方式
val pef : PartialFunction[Any, Any]= {
case m: Int => m * 2
case s: String => s
}
val newList: List[Any] = list.collect(pef)
println(list)
println(newList) //List(2, 4, 3, 12, 4, 10, 20)
//方式二:使用模式匹配来代替偏函数
val newList2: List[Any] = list.collect {
//不是Int类型的数据则被过滤掉,此时有未匹配上的数据,也不会报错
case m: Int => m * 2
}
println(newList2) //List(2, 4, 12, 10, 20)
十 、异常
十 一、隐式转换
11.1 简介
1. 两个类型能转换需存在的关系:
a、父子类
b、接口或实现类
2. java中基本类型的数值之间存在精度的转换和截取,
scala中没有精度的概念,编译时会自动由编译器调用java的逻辑来进行数值操作
3. 假如不存在关系呢?
引出隐式转换的概念。
a、如果两个类型之间不存在关系,无法进行类型的转换,但是编译器在编译时,尝试找到对应的转换关系将类型进行转换,让程序 编译通过,这个自动转换的过程,称之为隐式转换。
b、这个过程由编译器完成,也称之为二次编译。
4. 拆解分析:
a、编译器可以按照指定的规则进行查找,让错误的逻辑通过转换后,编译运行通过,这个功能称之为隐式转换。
b、这里的隐式转换就是让编译器查找转换的规则,类型的转换 A => B
5. 如果想要编译器可以找到转换规则,那么需要使用特殊的关键词来实现:implicit
6. 隐式转换的作用:
a、程序因为意外的情况,导致正确的逻辑出现错误,如版本的升级
b、功能的拓展。
//声明隐式函数
implicit def func(i: Int): Byte = {
i.toByte
}
val b: Int = 10
//将Int类型的b赋值为Byte类型的C
val c: Byte = b
println(c)
11.2 应用
11.2.1 简单应用1
1. 如果在当前的范围内,有多个相同的转换规则怎么办?
转换无法成功,因为编译器无法识别用哪个转换规则
2. 什么时候会调用隐式转换的规则呢?
二次编译时,第一次编译出现出错时,会选择隐式转换
3. 转换的过程:
编译出错 -> 编译器查找转换规则 -> 二次编译
//需求:在原来的基础上,增加update()方法,如何实现呢?
- 方式1:使用混入特质的方式
object Scala2_implicit {
def main(args: Array[String]): Unit = {
//方式1:使用混入特质的方式
val emp = new emp2() with methodext
emp.insert
emp.update()
}
}
trait methodext {
def update() = {
println("update...")
}
}
class emp2 {
def insert() = {
println("insert....")
}
}
- 方式2:使用隐式转换
object Scala2_implicit {
def main(args: Array[String]): Unit = {
val emp = new emp2()
emp.insert
emp.update()
//方式2:使用隐式转换,只是一种转换规则,类型的转换
implicit def transform(emp: emp2): Partent = {
new Partent
}
}
}
class Partent {
def update() = {
println("update ...")
}
}
class emp2 {
def insert() = {
println("insert....")
}
}
11.2.2 隐式函数
1. 函数的参数预先知道可能会发生变化,为了遵循ocp的开发原则,可以给函数增加关键字implicit修饰一下
//声明隐式函数
implicit def func(i: Int): Byte = {
i.toByte
}
val b: Int = 10
//将Int类型的b赋值为Byte类型的C
val c: Byte = b
println(c)
11.2.3 隐式变量
1. 如果使用因素参数进行处理时,那么在调用函数时
2. implicit修饰函数的参数时,这个参数所在的参数列表只能有一个参数
3. 如果使用了()小括号,那么隐式变量无法使用
def info2(name:String)( implicit password:String="000000")={
println("name:" + name + ", password: " + password)
}
def info1(name:String)( password:String="000000")={
println("name:" + name + ", password: " + password)
}
implicit val password = "88888"
//即使我们给了默认值,但是形参的小括号()不能省
info1("lianzhipeng")() //name:lianzhipeng, password: 000000
//没有使用小括号,隐式变量有效
info2("lianzhipeng") //name:lianzhipeng, password: 88888
//加了小括号,隐式变量无效
info2("lianzhipeng")() //name:lianzhipeng, password: 000000
def func1(implicit d :Double) :Int ={
d.toInt
}
implicit val d :Double = 10.0
println(func1(3)) // 3
println(func1) //10
11.2.4 隐式类
-- 隐式类
a、scala 2.10 版本增加了此功能
b、构造参数必须存在且只有一个参数,用于类型转换
c、参数类型(User) => 当前类型(UserExt)
d、隐式类必须被定义在“类”或“伴生对象”或“包对象”里,即隐式类不能放置在顶级(top-level)对象中
object Scala_implicitClass {
def main(args: Array[String]): Unit = {
val user = new User4
user.update()
}
//隐式类,注意构造函数的参数
implicit class User4Ext(use :User4) {
def update()={
println("update ... ")
}
}
}
class User4 {
def insert() = {
println("insert ... ")
}
}
11.3 隐式机制
所谓的隐式机制,就是一旦出现编译错误时,编译器会从哪些地方查找对应的隐式转换规则
1. 当前代码的作用域中找到即可
2. 当前代码上级作用域
3. 当前类所在的包对象
4. 当前类的父类或特质
--总结: 如果想要隐式转换,那么直接导入
object Scala5_implicit {
def main(args: Array[String]): Unit = {
import com.atguigu.Scala_chapter01.scala_chapter10.Scala_implicitClass._
val user = new User4
user.update
}
}
class User4 {
def insert() = {
println("insert ... ")
}
}
十二、泛型
12.1
十三、正则表达式
存在且只有一个参数,用于类型转换
c、参数类型(User) => 当前类型(UserExt)
d、隐式类必须被定义在“类”或“伴生对象”或“包对象”里,即隐式类不能放置在顶级(top-level)对象中
```scala
object Scala_implicitClass {
def main(args: Array[String]): Unit = {
val user = new User4
user.update()
}
//隐式类,注意构造函数的参数
implicit class User4Ext(use :User4) {
def update()={
println("update ... ")
}
}
}
class User4 {
def insert() = {
println("insert ... ")
}
}
11.3 隐式机制
所谓的隐式机制,就是一旦出现编译错误时,编译器会从哪些地方查找对应的隐式转换规则
1. 当前代码的作用域中找到即可
2. 当前代码上级作用域
3. 当前类所在的包对象
4. 当前类的父类或特质
--总结: 如果想要隐式转换,那么直接导入
object Scala5_implicit {
def main(args: Array[String]): Unit = {
import com.atguigu.Scala_chapter01.scala_chapter10.Scala_implicitClass._
val user = new User4
user.update
}
}
class User4 {
def insert() = {
println("insert ... ")
}
}
十二、泛型
12.1
十三、正则表达式
版权声明:本文为qq_39437513原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。