前言
本文使用flink1.14.5版本,介绍standalone-HA模式的安装。
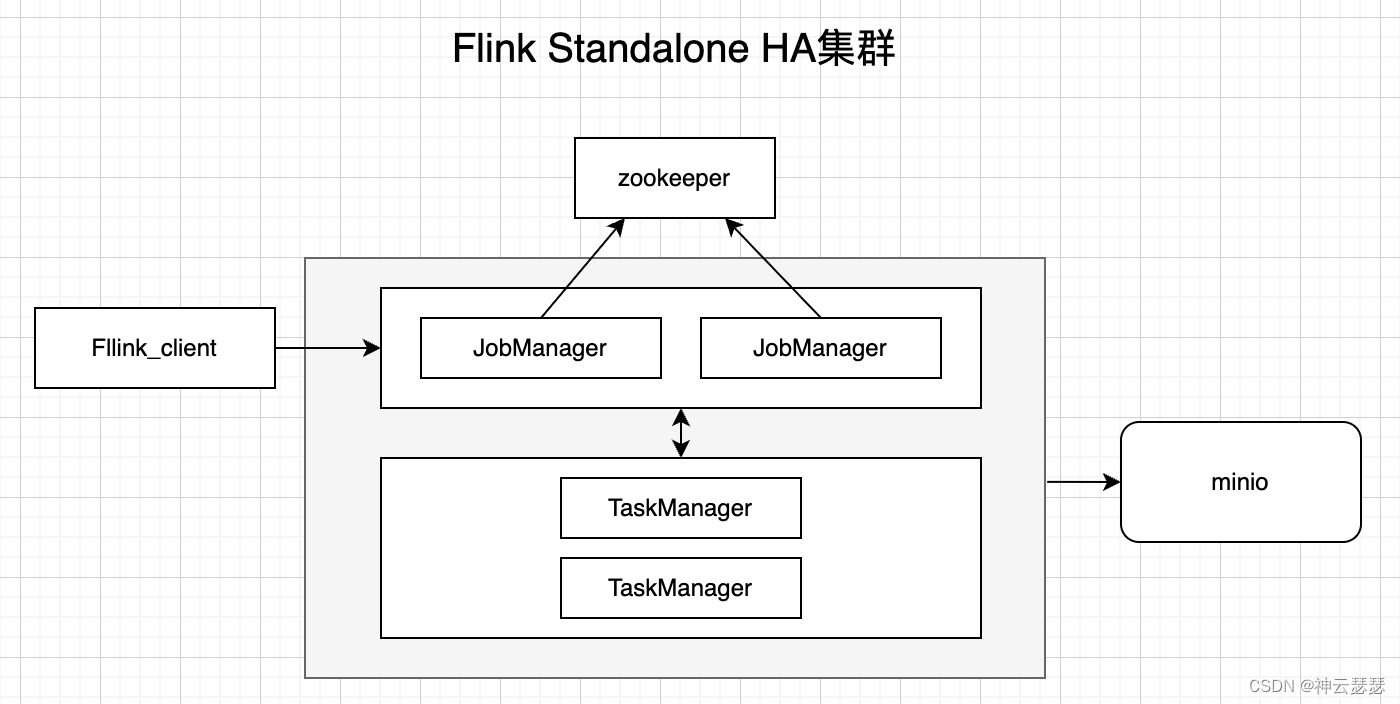
此模式时高可用架构,采用zookeeper协调多个JobManager,保持每时每刻有一个运行中的JobManager,其余JobManager处理stand by状态。
因为涉及到运行过程中的状态数据的存储,如savepoint,checkoutpoint等。采用minio替换掉hdfs来存储状态。
一、资源说明
1、flink集群机器
| 机器ip | hostname | JobManager运行节点 | TaskManager运行节点 | 备注 |
| 10.113.1.121 | flinknode1 | JobManager | ||
| 10.113.1.122 | flinknode2 | JobManager | ||
| 10.113.1.123 | flinknode3 | TaskManager | ||
| 10.113.1.124 | flinknode4 | TaskManager |
如果是standalone-ha模式最少使用两台机器,保证有两个JobManager。TaskManager可以与JobManager部署在一起,也可以单独部署
2、zookeeper集群(安装省略)
| hostname | 运行进程 |
| zknode1 | zookeeper |
| zknode2 | zookeeper |
| zknode3 | zookeeper |
3、minio(安装省略)
miniodocker单机版安装参看,
minio之docker的单机版安装_神云瑟瑟的博客-CSDN博客_docker minio
| hostname | 运行进程 |
| minionode | minio |
需要再minio中创建桶,本文用的桶名为“flink”
配置对该桶有读写权限的账户
4、各个组件架构图
二、机器的基础配置
1、对flinknode机器安装java环境
flink1.14版本可以使用jdk8,1.15后续的版本不能再使用jdk8了。
2、对flinknode1-4,4台机器配置hostname,并且在/etc/hosts文件中配置映射,(如果不配置hosts就使用ip访问)
实践生产中建议设置hosts
3、设置flinknode机器相互免密登录
本文配置的是相互都免密登录,
实际好像是保证JobManager可以免密登录TaskManager就可以了
4、创建存放软件的目录
/opt/soft
这个目录因人而异,本文是存放在以上目录的
三、下载安装
1、下载并且解压
下载预览界面:
https://flink.apache.org/zh/downloads.html
登录flinknode1
cd /opt/soft
wget https://www.apache.org/dyn/closer.lua/flink/flink-1.14.5/flink-1.14.5-bin-scala_2.12.tgz
tar zxvf flink-1.14.5-bin-scala_2.12.tgz2、修改配置
a、对${FLINK_HOME}/conf/flink-conf.yaml修改,在文件最后添加配置
fs.allowed-fallback-filesystems: s3
state.backend: filesystem
#checkout存储地址
state.checkpoints.dir: s3://flink/checkpoint
#savepoint存储地址
state.savepoints.dir: s3://flink/savepoint
#minio的地址
s3.endpoint: http://minionode:9000
s3.path.style.access: true
#minio的访问key
s3.access-key: xxxx
s3.secret-key: xxxx
high-availability: zookeeper
#zookeeper地址
high-availability.zookeeper.quorum: zknode1:2181,zknode2:2181,zknode3:2181
#recovery存储地址
high-availability.storageDir: s3://flink/recovery
#zookeeper没有设置密码,就使用open就ok
high-availability.zookeeper.client.acl: openb、对${FLINK_HOME}/conf/masters修改,修改后的配置如
该配置中说明了运行JobManager的节点和IP
flinknode1:8081
flinknode2:8081c、对${FLINK_HOME}/conf/works修改,修改后的配置如
该配置中说明了运行TaskManager的节点和IP
flinknode3
flinknode4d、对${FLINK_HOME}/bin/config.sh修改
大概在107行的位置对变量`DEFAULT_ENV_PID_DIR`的值进行修改,修改后的内容如下
DEFAULT_ENV_PID_DIR="./.flinkpid" # Directory to store *.pid files to主要对master和work启动后的 StandaloneSessionClusterEntrypoint进程和TaskManagerRunner进程的pid存储位置修改,默认存储在“/tmp”目录,操作系统可能会清理该目录的资源,造成启动后的flink集群无法使用“${FLINK_HOME}/bin/stop-cluster.sh”命令停止集群。
本文使用相对目录,可以存储在用户目录下,如“/root/.flinkpid/”目录
保存进程的文件为:
/root/.flinkpid/flink-root-standalonesession.pid
/root/.flinkpid/flink-root-taskexecutor.pid
3、拷贝s3支持的包,flink-s3-fs-hadoop-1.14.5.jar
cd /opt/soft/flink-1.14.5
mkdir plugins/s3-fs-hadoop
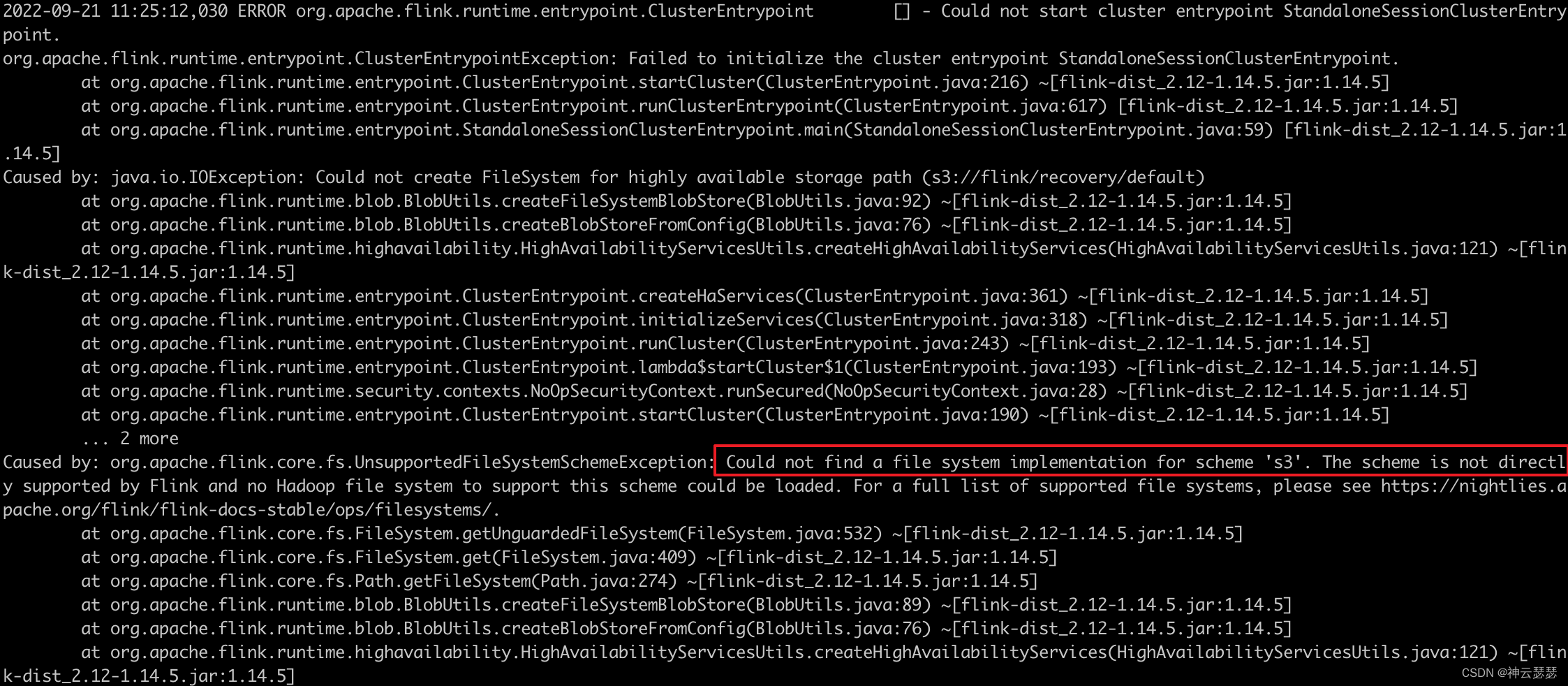
cp ./opt/flink-s3-fs-hadoop-1.14.5.jar ./plugins/s3-fs-hadoop/如果未执行上面的s3支持的包的拷贝,会报错
Could not find a file system implementation for scheme ‘s3’
Caused by: org.apache.flink.core.fs.UnsupportedFileSystemSchemeException: Could not find a file system implementation for scheme 's3'. The scheme is not directly supported by Flink and no Hadoop file system to support this scheme could be loaded. For a full list of supported file systems, please see https://nightlies.apache.org/flink/flink-docs-stable/ops/filesystems/.
4、分发修改后的flink文件夹
cd /opt/soft
scp -r flink-1.14.5 root@flinknode2:/opt/soft
scp -r flink-1.14.5 root@flinknode3:/opt/soft
scp -r flink-1.14.5 root@flinknode4:/opt/soft5、在主节点上启动
cd /opt/soft/flink-1.14.5
./bin/start-cluster.sh在主节点上启动后,会自动将其他节点的任务也启动起来。
6、配置historyServer(非必须)
对${FLINK_HOME}/conf/flink-conf.yaml修改,在文件最后添加配置
#==============================================================================
# HistoryServer
#==============================================================================
# The HistoryServer is started and stopped via bin/historyserver.sh (start|stop)
# Directory to upload completed jobs to. Add this directory to the list of
# monitored directories of the HistoryServer as well (see below).
# jobmanager上传记录地址
jobmanager.archive.fs.dir: s3://flink/completed-jobs/
# The address under which the web-based HistoryServer listens.
#historyserver.web.address: 0.0.0.0
# The port under which the web-based HistoryServer listens.
#historyserver.web.port: 8082
# Comma separated list of directories to monitor for completed jobs.
## historyserver查看记录地址
historyserver.archive.fs.dir: s3://flink/completed-jobs/
# Interval in milliseconds for refreshing the monitored directories.
#historyserver.archive.fs.refresh-interval: 10000找一个节点,通过以下命令来启动停止history服务
./bin/historyserver.sh start
./bin/historyserver.sh stop
四、相关命令说明
| 命令 | 说明 | |
| ./bin/start-cluster.sh | 整体启动集群 | |
| ./bin/stop-cluster.sh | 整体停止机器 | |
| ./bin/jobmanager.sh | 对本节点jobManager的操作,start,stop | |
| ./bin/taskmanager.sh | 对本节点taskManager的操作,start,stop |
使用后面两条命令,可以定点维护某些需要维护的节点
五、相关进程说明
使用jps命令查看进程
| 进程名字 | |
| StandaloneSessionClusterEntrypoint | jobManager |
| TaskManagerRunner | taskmanager |