数据结构Hash算法
哈希表(Hash table,也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
优点:查找可以直接根据key访问
缺点: 不能进行范围查找
index=Hash(key)
数据结构平衡二叉树算法
平衡二叉查找树,又称 AVL树。 它除了具备二叉查找树的基本特征之外,还具有一个非常重要的特点:它 的左子树和右子树都是平衡二叉树,且左子树和右子树的深度之差的绝对值(平衡因子 ) 不超过1。 也就是说AVL树每个节点的平衡因子只可能是-1、0和1(左子树高度减去右子树高度)。
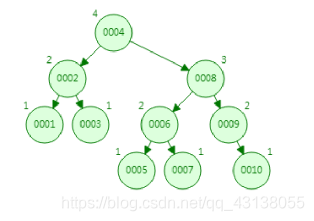
优点:平衡二叉树算法基本与二叉树查询相同,效率比较高
缺点:插入操作需要旋转,支持范围查询
数据结构B树
维基百科对B树的定义为“在计算机科学中,B树(B-tree)是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(log n)的时间复杂度运行进行查找、顺序读取、插入和删除的数据结构。B树,概括来说是一个节点可以拥有多于2个子节点的二叉查找树。与自平衡二叉查找树不同,B-树为系统最优化大块数据的读和写操作。B-tree算法减少定位记录时所经历的中间过程,从而加快存取速度。普遍运用在数据库和文件系统。”
因为B树节点元素比平衡二叉树要多,所以B树数据结构相比平衡二叉树数据结构实现减少磁盘IO的操作。

数据结构B+树
B+树相比B树,新增叶子节点与非叶子节点关系,叶子节点中包含了key和value,非叶子节点中只是包含了key,不包含value。叶子节点是通过飞叶子节点通过链表来链接的
所有相邻的叶子节点包含非叶子节点,使用链表进行结合,有一定顺序排序,从而范围查询效率非常高。
一个节点16MB ,假如索引为8b,指针也为8b,一共16b,也就是说一个节点可以 放1000个索引

MyISAM和InnoDB的区别
InnoDB 支持事务,MyISAM 不支持事务。
InnoDB 支持外键,而 MyISAM 不支持。
InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。
InnoDB 不保存表行数,count(
) 时需要全表扫描。而MyISAM 用一个变量保存了整个表的行数,执行count(
)时读取变量即可
MyISAM和InnoDB对B-Tree索引不同的实现方式
MyISAM
MyISAM 实现b+树,索引文件和数据文件是分开的,叶子节点的value值存的是数据文件中某一行对应的地址,在通过地址去查找哪一行数据
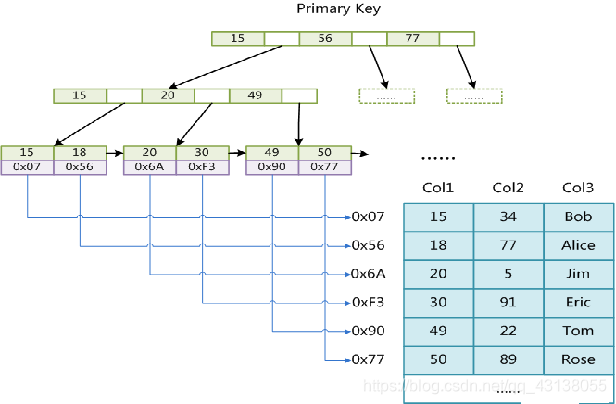
InnoDB
InnoDB实现b+树,索引文件和数据文件没有分开,叶子节点的value值存的是对应行的数据。(如果是非主键索引value存放的是主键ID,然后在通过id查询到整行数据,需要查询两次)
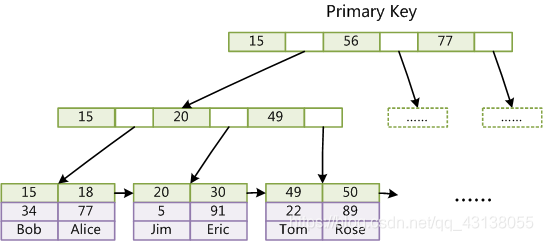
为什么MySQL底层使用b+树?
b+树分为叶子节点和非叶子节点,非叶子节点存放索引,叶子节点放索引和数据,这样的话每一页可以读取非常多的索引,从而减少了io操作。
优点
支持范围查询
树的高度低,减少io操作的次数
注意
:MyISAM和InnoDB对B-Tree索引不同的实现方式
MyISAM底层使用B+树 叶子节点的value对应存放行数的地址,在通过行数定位到数据。
InnoDB底层使用B+树,叶子节点的value对应存放是行的data数据,相比MyISAM效率要高一些,但是比较占硬盘内存大小。
环境linux索引文件如何查看
默认数据与索引文件位置: /var/lib/mysql
MyISAM引擎的文件:
.myd 即 my data,表数据文件
.myi 即my index,索引文件
.log 日志文件。
InnoDB引擎的文件:
采用表空间(tablespace)来管理数据,存储表数据和索引,
InnoDB数据库文件(即InnoDB文件集,ib-file set):
ibdata1、ibdata2等:系统表空间文件,存储InnoDB系统信息和用户数据库表数据和索引,所有表共用。
.ibd文件:单表表空间文件,每个表使用一个表空间文件(file per table),存放用户数据库表数据和索引。
MySQL数据库配置慢查询
参数说明:
slow_query_log 慢查询开启状态
slow_query_log_file 慢查询日志存放的位置(这个目录需要MySQL的运行帐号的可写权限,一般设置为MySQL的数据存放目录)
long_query_time 查询超过多少秒才记录
1.查询慢查询配置
show variables like ‘slow_query%’;
2.查询慢查询限制时间
show variables like ‘long_query_time’;
3.将 slow_query_log 全局变量设置为“ON”状态
set global slow_query_log=‘ON’;
4.查询超过1秒就记录
set global long_query_time=1;
5.查询cat /var/lib/mysql/localhost-slow.log
service mysqld restart
索引为什么会失效?注意那些事项?
where 条件中 存在 null,or,like开头,不等于符号
1.索引无法存储null值
2.如果条件中有,即使其中有条件带索引也不会使用(这也是为什么尽量少用or的原因)
要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
3.对于多列索引,不是使用的第一部分,则不会使用索引
4.like查询以%开头
5.如果列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
6.如果mysql估计使用全表扫描要比使用索引快,则不使用索引
非主键索引优化
7如果是非主键索引查询的说话,在不用写*号的情况下,就不要写
可以避免回表查询。
分页优化
8大数据量分页的情况下,可以先把需要数据的id查询出来,然后在通过id去查询这10行
EXPLAIN 工具分析sql语句
type最低 满足 range 范围查询级别
1 consts 单表中最多只有一个匹配行(主键或者唯一索引),在优化阶段即可读取到数据。
2 ref 指的是使用普通的索引(normal index)。
3 range 对索引进行范围检索。
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
SELECT * FROM item_type WHERE id>(SELECT id FROM item_type LIMIT 1500000,1) LIMIT 20
联合索引为什么需要遵循左前缀原则?
查询 和 排序的时候都可以遵循左前缀原则
什么是红黑树?
红黑树(Red Black Tree) 是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,典型的用途是实现关联数组。
基本特征:
1.每个节点不是红色就是黑色
2.不可能有连在一起的红色节点
3.根节点都是黑色
4.每个红色节点的两个子节点都是黑色
红黑树变换规则:
1.改变节点颜色
2.左旋转
3.右旋转
二叉搜索树存在的缺点?
不平衡 和时间插入的顺序有关系,使用插入的第一个节点作为平衡点,如果插入第一个是为0的情况下,最后成为了一条线。
所以:查找时间复杂度其实就是为树的深度,也就是变为O(n)
建议使用平衡二叉树,红黑树是平衡二叉树一种实现方案
mysql为什么要使用B+树?
平衡二叉树
树的高度越高,对磁盘的操作也越频繁
B树
继承了平衡二叉树的优点之外,一个节点可以最多可以有2个子节点 相对于二叉树来说降低了树了高低 也就减少了对io的操作次数、那么查询效率也提高了
B+树
继承了B树的优点之外 新增了叶子节点(包含key value)和非叶子节点包含key() 通过非叶子节点来定位到叶子节点,
如果是InnoDB引擎的情况下,通过叶子节点就可以直接拿到某一行数据了,如果是MyISAM引擎的情况下,通过叶子节点拿到一个地址,然后在通过地址找到某一行数据。
mysql 间隙锁
如果操作的是某个区间的数据,会锁住这个区间的所有数据
如何避免行锁升级为表锁
修改的时候where条件不是索引字段会全盘扫描,这个时候就成了表锁。