|
|
|
|
|
|
是系统进行 |
一条线程指的是进程中一个
操作系统能够进行独立运行和调度的 |
线程类似于同时执行多个不同的程序,多线程运行有如下
优点
:
-
防止线程
堵塞
,使用线程可以把占据长时间的程序中的任务放到后台去处理。
-
程序的运行
速度
可能
加快
。
-
在一些等待的任务如:用户输入、文件读写和网络收发数据等, 可以释放一些珍贵的资源如内存占用等等,
提高资源利用率
。
-
增强用户体验
,用户不会看到进程卡死,用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
-
每个线程都有自己的一组 CPU 寄存器,称为
线程的上下文
,该上下文反应课线程上次运行该线程的CPU 寄存器的状态。
-
在其他线程正在运行时,线程可以
暂时搁置
(也称为
睡眠
),这就是
线程的退让
。
多线程的
缺点
:
-
如果有大量的线程,会影响性能,因为操作系统需要在它们之间
切换
。
-
更多的线程需要更多的
内存空间
。
-
线程可能会给程序带来更多“bug”,因此要小心使用 。
-
线程的
中止
需要考虑其对程序运行的
影响
。
-
通常块模型数据是在多个线程间共享的,需要防止线程
死锁
情况的发生 。
线程状态转换图

-
Python 的前后台线程
前台线程:应用程序必须运行完所有的前台线程才可以退出;
后台线程:应用程序则可以不考虑其是否已经运行完毕而直接退出,
所有的后台线程在应用程序退出时都会自动结束。
setDaemon(
True
): 设置
后台线程
、
守护线程
,也称为
服务线程
,是运行在后台的一种特殊线程(Daemon:守护线程、后台线程)。
当程序没有可服务的线程会自动离开
。即当主线程退出时,后台线程随即退出。因此,
守护线程的优先级比较低,用于为其他线程提供服务
。
setDaemon(
False
)(
默认情况
):
非守护线程
,也称为
前台线程
。
当主线程退出时,若前台线程还未结束,则等待所有前台线程结束,相当于在程序末尾加入join()
。
-
对
主进程
来说,运行完毕指的是主进程代码运行完毕。
-
对
主线程
来说,运行完毕指的是主线程所在的进程内所有非守护线程统统运行完毕,主线程才算运行完毕。
若在父线程中创建了子线程,当父线程结束时根据子线程daemon属性值的不同可能会发生下面的两种情况之一:
(1)如果某个子线程的daemon属性为False,父线程结束时会检测该子线程是否结束,如果该子线程还在运行,则主线程会等待它完成后再退出;
(2)如果某个子线程的daemon属性为True,主线程运行结束时不对这个子线程进行检查而直接退出,同时所有daemon值为True的子线程将随主线程一起结束,而不论是否运行完成。
属性daemon的值默认为False,如果需要修改,必须在调用start()方法启动线程之前进行设置。
在Python中要启动一个线程,可以使用
threading
包中的
Thread
建立一个对象,这个Thread类的基本原型是:
t=Thread(target,args=None)
-
其中target是要执行的线程函数,
-
args是一个元组或者列表,为target的函数提供参数,
-
然后调用t.start()就开始了线程。
在主线程中启动一个
前台
线程执行reading函数
import threading
import time
import random
def reading():
for i in range(5):
print("reading", i)
time.sleep(random.randint(1, 2))
r = threading.Thread(target=reading)
r.setDaemon(False) # 前台线程,非守护线程
# r.daemon = False # 另一种写法
r.start()
print("The End")程序结果如下:
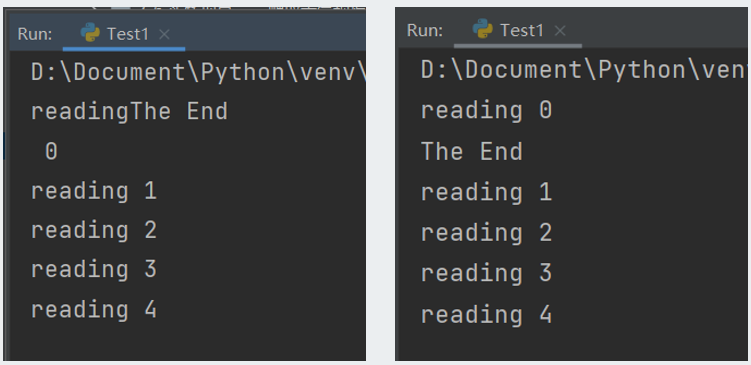
从结果看到,主线程启动子线程r后就结束了,输出“The End”,但是子线程还没有结束, 继续显示完reasing 4后才结束。其中的r.setDaemon(False)就是设置线程r为前台线程,主线程结束时会检测该子线程是否结束,如果该子线程还在运行,则主线程会等待它完成后再退出。(
注意
:没有设置线程的等待,结果可能不理想,因为根本不知道程序会先执行那行代码(主线程与子线程几乎同时运行))
启动一个后台线程
import threading
import time
import random
def reading():
for i in range(5):
print("reading", i)
time.sleep(random.randint(1, 2))
r = threading.Thread(target=reading)
r.setDaemon(True) # 后台线程,守护线程
r.start()
print("The End") # 后台线程因主线程的结束而结束
运行结果如下:
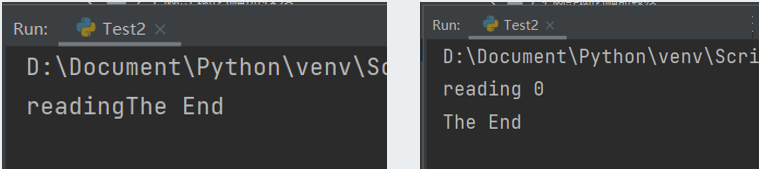
还有很多种结果,原因见前台线程里的
注意
由此可见在主线程结束后子线程也结束,这就是后台线程。
如果设置 r.setDaemon(True),那么r就是后台线程,主线程运行结束时不对这个子线程进行检查而直接退出,同时所有daemon值为True的子线程将随主线程一起结束,而不论是否运行完成。
前台与后台线程
# 前台与后台线程
import threading
import time
import random
def reading():
for i in range(5):
print("reading", i)
time.sleep(random.randint(1, 2))
def test():
r = threading.Thread(target=reading)
r.setDaemon(True) # 后台
r.start()
print("the end")
t = threading.Thread(target=test)
t.daemon = False # 另一种写法 前台
t.start()
print("The End")
运行结果如下:
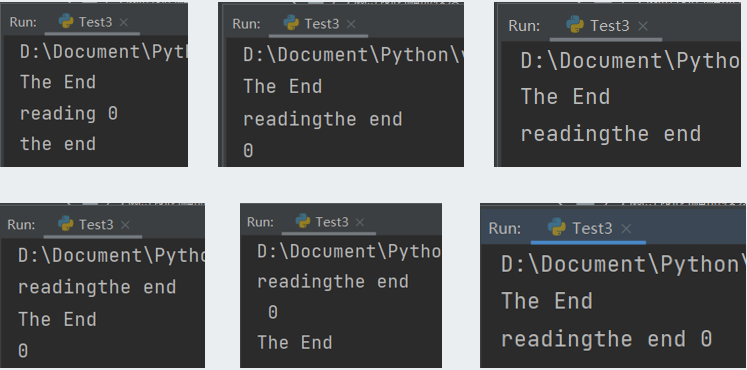
这就是没有线程等待的可怕之处,可能还有很多不同的结果
由此可见主线程启动前台子线程t后,主程序执行完毕输出“The End”,但是前台线程t还在执行,在t中启动后台r子线程,之后t程序结束,输出“test end” t线程结束,相应的r线程也结束,此时主线程才最终结束。(
按第一个结果(正常结果)来说明
),这里没必要深究,学完下面的 join()就不会出现这些问题了。
-
线程的等待
在多线程的程序中往往一个线程(例如主线程)要等待其它线程执 行完毕才继续执行,这可以用
join
函数,使用的方法是:
线程对象.join()
在一个(主)线程代码中执行这条语句,当前的(主)线程就会停止执行,一直等到指定的(子/被调用)线程对象的线程执行完毕后才继续执行,即这条语句启动(主线程)阻塞等待的作用。
主线程启动一个子线程并等待子线程结束后才继续执行。
# 主线程启动一个子线程并等待子线程结束后才继续执行
import threading
import time
import random
def reading():
for i in range(5):
print("reading", i)
time.sleep(random.randint(1, 2))
t = threading.Thread(target=reading)
t.setDaemon(False)
t.start()
t.join()
print("The End")运行结果如下:
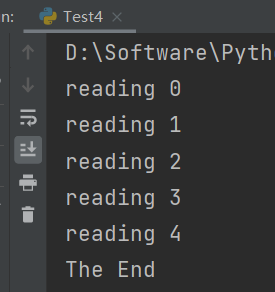
由此可见主线程启动子线程t执行reading函数,t.join()就阻塞主线程,一直等到t线程执行完毕后才结束t.join(),继续执行显示The End。
在一个子线程启动另外一个子线程,并等待子线程结束后才继续执行。
# 在一个子线程启动另外一个子线程,并等待子线程结束后才继续执行。
import threading
import time
import random
def reading():
for i in range(5):
print("reading", i)
time.sleep(random.randint(1, 2))
def test():
r = threading.Thread(target=reading)
r.setDaemon(True)
r.start()
r.join()
print("test end")
t = threading.Thread(target=test)
t.setDaemon(False)
t.start()
t.join()
print("The End")运行结果如下:
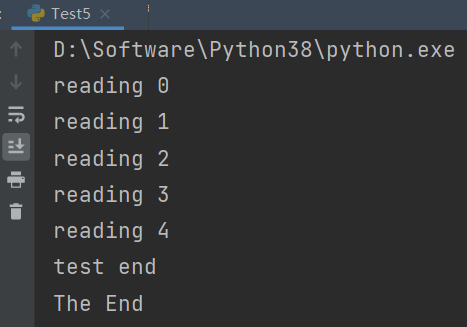
由此可见主线程启动t线程后t.join()会等待t线程结束,在test中再次 启动r子线程,而且r.join()而阻塞t线程,等待r线程执行完毕后才结束 r.join(),然后显示test end,之后t线程结束,再次结束t.join(),主线 程显示The End后结束。
-
多线程与资源
在多个线程的程序中一个普遍存在的问题是,如果多个线程要竞争同时 访问与改写公共资源,那么应该怎么样协调各个线程的关系。一个普遍 使用的方法是使用
线程锁
,Python使用
threading.RLock
类来创建一个线程 锁对象:
lock=threading.RLock()
这个对象lock有两个重要方法是获取
acquire()
与释放
release()
。
当执行:lock.acquire()语句时,强迫lock获取线程锁,如果已经有另外的线程先调用了acquire()方 法获取了线程锁而还没有调用release()释放锁,那么这个lock.acquire()就
阻塞当前的线程
,
一直等待锁的控制权
,直到别的线程释放锁后 lock.acquire()就
获取锁并解除阻塞
,线程继续执行,执行后线程要调用 lock.release()
释放锁
,不然别的线程会一直得不到锁的控制权。使用acquire /release的工作机制我们可以把
一段修改公共资源的代码用 acquire()与release()夹起来
,这样就保证一次最多只有一个线程在修改公共资源,别的线程如果也要修改就必须等待,直到本线程调用release() 释放锁后别的线程才能获取锁的控制权进行资源的修改。
一个子线程A把一个全局的列表words进行升序的排列,另外一个D线程把这个列表进行降序的排列。
# 一个子线程A把一个全局的列表words进行升序的排列,另外一个D线程把这个列表进行降序的排列。
import threading
import time
lock = threading.RLock()
words = ["a", "b", "d", "b", "p", "m", "e", "f", "b"]
# 升序
def increase():
global words
for count in range(5):
lock.acquire() # ================公共资源使用线程锁——夹起来================
print("A acquire")
for i in range(len(words)):
for j in range(i + 1, len(words)):
if words[j] < words[i]:
t = words[i]
words[i] = words[j]
words[j] = t
print("A", words)
time.sleep(1)
lock.release() # ================公共资源使用线程锁——夹起来================
# 降序
def decrease():
global words
for count in range(5):
lock.acquire() # ================公共资源使用线程锁——夹起来================
print("D acquire")
for i in range(len(words)):
for j in range(i + 1, len(words)):
if words[j] > words[i]:
t = words[i]
words[i] = words[j]
words[j] = t
print("D", words)
time.sleep(1)
lock.release() # ================公共资源使用线程锁——夹起来================
A = threading.Thread(target=increase)
A.setDaemon(False)
A.start()
D = threading.Thread(target=decrease)
D.setDaemon(False)
D.start()
print("The End")运行结果如下:
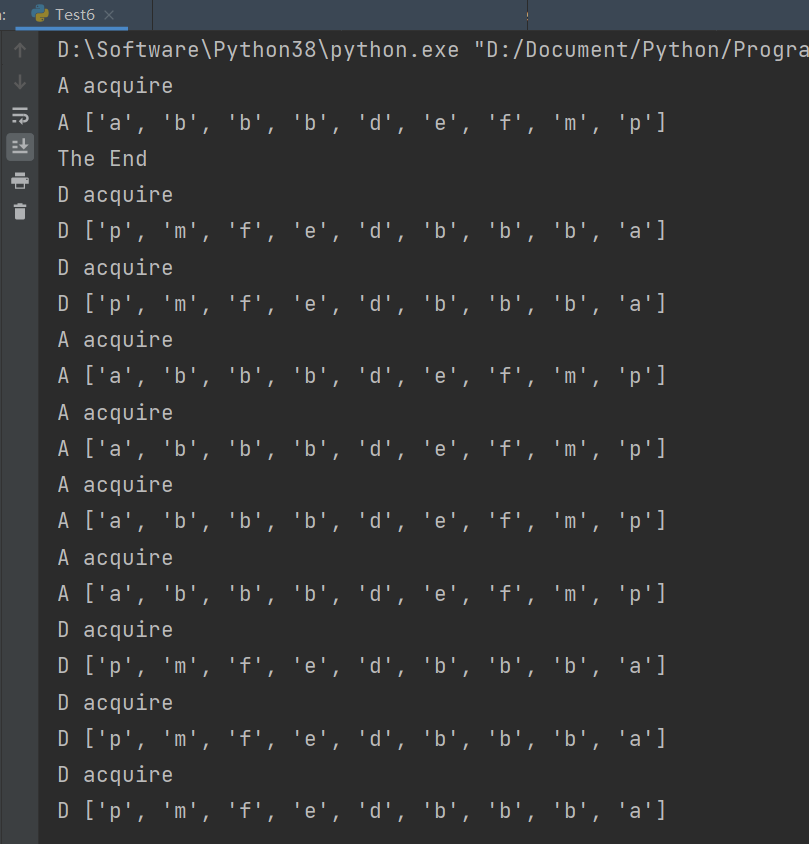
由此可见无论是
increase
还是
decrease
的排序过程,都是在获得锁的控制权下进行的,因此排序过程中另外一个线程必然处于等待状态,不会干扰本次的排序,因此每次显示的结构不是升序的就是降序的。
下面是去掉
线程锁
与
sleep(1)
的运行结果:
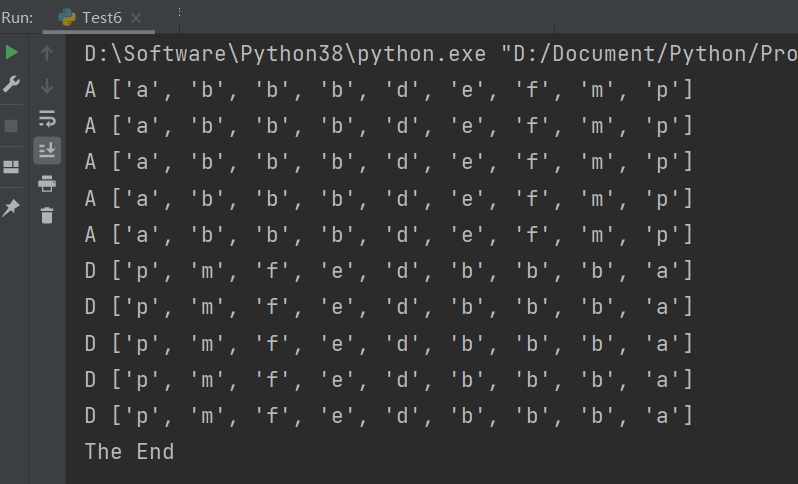
下面是只去掉
线程锁
的运行结果:
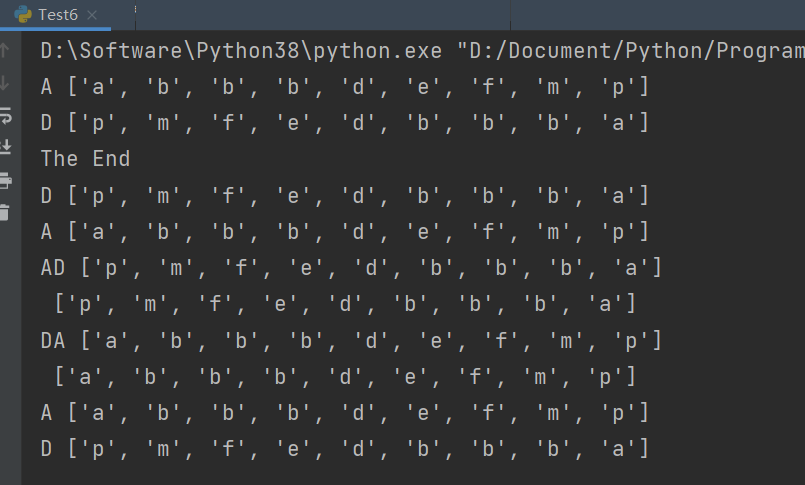
有书籍说,如果不适用锁,那么在升序排序时,降序排序也在工作,最后的结果既不是升序也不是降序。
但是上面这两种情况似乎也都是正常结果,这可能和python的版本和电脑的配置有关,这里用的时python3.8.9,这里即使没有使用线程锁也正常排序了,但还是不要卡这种bug了,毫无意义。