1、值的规律:
多核比单核值大,整型比浮点值大。值越大越好,对Ratio的17个值进行几何平均值,内存数应该是CPU核数的2倍,8核CPU应该插总数为16G的内存,否则多核数缺失,计算出来低或者不出分。
|
SPEC cpu2006 (8GB*2) |
单核整型: |
15.38 |
|
|
单核浮点: |
14.73 |
||
|
多核整型: |
91.53 |
||
|
多核浮点: |
86.16 |
||
2、生成的结果文件: 分别对其进行几何平均数运算可以得出以上值
CFP2006.001
CFP2006.002
CINT2006.001
CINT2006.001
3、每个测试结果文件中的值基本如下
Estimated Estimated
Base Base Base Peak Peak Peak
Benchmarks Ref. Run Time Ratio Ref. Run Time Ratio
————– —— ——— ——— —— ——— ———
410.bwaves 13590 2280 5.95 *
416.gamess 19580 1090 18.0 *
433.milc 9180 754 12.2 *
434.zeusmp 9100 671 13.6 *
435.gromacs 7140 442 16.2 *
436.cactusADM 11950 862 13.9 *
437.leslie3d 9400 783 12.0 *
444.namd 8020 570 14.1 *
447.dealII 11440 430 26.6 *
450.soplex 8340 695 12.0 *
453.povray 5320 263 20.2 *
454.calculix 8250 632 13.0 *
459.GemsFDTD 10610 1080 9.83 *
465.tonto 9840 503 19.6 *
470.lbm 13740 1110 12.4 *
481.wrf 11170 537 20.8 *
482.sphinx3 19490 1030 19.0 *
==============================================================================
410.bwaves 13590 2280 5.95 *
416.gamess 19580 1090 18.0 *
433.milc 9180 754 12.2 *
434.zeusmp 9100 671 13.6 *
435.gromacs 7140 442 16.2 *
436.cactusADM 11950 862 13.9 *
437.leslie3d 9400 783 12.0 *
444.namd 8020 570 14.1 *
447.dealII 11440 430 26.6 *
450.soplex 8340 695 12.0 *
453.povray 5320 263 20.2 *
454.calculix 8250 632 13.0 *
459.GemsFDTD 10610 1080 9.83 *
465.tonto 9840 503 19.6 *
470.lbm 13740 1110 12.4 *
481.wrf 11170 537 20.8 *
482.sphinx3 19490 1030 19.0 *
Est. SPECfp(R)_base2006 —
Est. SPECfp2006 Not Run
4、对以上结果解释说明:
|
|
|||
|
子项目 |
|
|
|
|
整数测试 |
|||
|
400.perlbenchPERL编程语言 |
ANSI C |
Perl v5.8.7 SpamAssassin v2.61Digest-MD5 v2.33HTML-Parser v3.35MHonArc v2.6. 8IO-stringy v1.205MailTools v1.60TimeDate v1.16 |
负载由三个script组成:主负载是垃圾邮件检测软件SpamAssassin,一个是email到HTML的 |
|
401.bzip2 压缩 |
ANSI C |
bzip2 v1.0.3 |
负载包括六个部分: 两个小的JPEG图片 一个程序 一个tar包起的几个源程序文件 一个HTML文件 混合文件,包括压缩起来的高可压缩文件及不怎么可压缩的文件 测试分别使用了三个不同的压缩等级进行压缩和解压缩 |
|
403.gcc C编译器 |
C |
gcc v3.2 |
对9组C代码进行了编译 |
|
429.mcf 组合优化 |
ANSI C w/libm |
MCF v1.2 |
MCF是一个用于大型公共交通中的单站车辆调度的程序 429.mcf运行于32/64位模型时分别需要约860/1700MB的内存 |
|
445.gobmk 人工智能:围棋 |
C |
围棋 |
|
|
456.hmmer 基因序列搜索 |
C |
使用HMMS(Hidden Markov Models,隐马尔科夫模型) 基因识别方法进行基因序列搜索 |
|
|
458.sjeng 人工智能:国际象棋 |
ANSI C |
Sjeng v11.2 |
国际象棋 |
|
462.libquantum 物理:量子计算 |
ISO/IEC 9899:1999(“C99”) |
libquantum是模拟量子计算机的库文件,用来进行量子计算机应用的研究 |
|
|
464.h264ref 视频压缩 |
C |
h264avc v9.3 |
使用两种配置对两个YUV格式源文件进行H.264编码 |
|
471.omnetpp 离散事件仿真 |
C++ |
OMNeT++ |
包括约8000台计算机和900个 |
|
473.astar 寻路算法 |
C++ |
实现了2D寻路算法A*的三种不同版本 |
|
|
483.xalancbmk
|
C++ |
Xalan-C++ v1.8 mod Xerces-C++ v2.5.0 |
XML文档/XSL表到HTML文档的转换 |
|
浮点测试 |
|||
|
410.bwaves 流体力学 |
Fortran 77 |
对三维瞬跨音速粘性流中冲击波的模拟计算 |
|
|
416.gamess 量子化学 |
Fortran |
GMAESS |
三种SCF自洽场计算: 胞嘧啶分子 水和Cu2+离子 三唑离子 |
|
433.milc 量子力学 |
C |
MILC |
四维SU(3)格点规范理论的模拟,用来研究QCD量子色动力学、夸克及胶子 |
|
434.zeusmp 物理:计算流体力学 |
Fortran 77/REAL*8 |
ZEUS-MP |
|
|
435.gromacs 生物化学/分子力学 |
C & Fortran |
GROMACS |
GROMACS是一个分子力学计算套件,然而也可以用于非生物系统,435.gromacs模拟了在一个水和离子溶液中的蛋白质溶菌酶结构在各种实验手段如核磁共振的X光照射下的变化 |
|
436.cactusADM 物理:广义相对论 |
Fortran 90, ANSI C |
Cactus BenchADM |
436.cactusADM对时空曲率由内部物质决定的爱因斯坦演化方程进行求解,爱因斯坦演化方程由10个标准ADM 3+1分解的二阶非线性偏微分方程组成。 |
|
437.leslie3d 流体力学 |
Fortran 90 |
LESlie3d |
LESlie3d是用来计算湍流的计算流体力学程序,437.leslie3d计算了一个如燃油注入燃烧室的时间分层混合流体。 |
|
444.namd 生物/分子 |
C++ |
N |
N |
|
447.dealII 有限元分析 |
C++ w/Boost lib |
deal.II lib |
deal.II是定位于自适应有限元及误差估计的C++库,447.dealII对非常系数的亥姆霍兹方程进行求解,它使用了基于二元加权误差估计生成最佳网格的自适应方法,该方程在3维得解 |
|
450.soplex 线形编程、优化 |
ANSI C++ |
SoPlex v1.2.1 |
SoPlex使用单纯形算法解线性方程 |
|
453.povray 影像光线追踪 |
ISO C++ |
POV-Ray |
POV-Ray是一个光线追踪渲染软件,453.povray渲染一幅1280×1024的反锯齿国际象棋棋盘图像 |
|
454.calculix 结构力学 |
Fortran 90 & C w/SPOOLES code |
CalculiX |
CalculiX是一个用于线性及非线性三位结构力学的有限元分析软件,454.calculix计算了一个高速旋转的压缩 |
|
459.GemsFDTD 计算电磁学 |
Fortran 90 |
GmesTD from GEMS |
459.GemsFDTD使用FDTD(有限差分时域)方法求解三维时域中的麦克斯韦方程,计算了一个理想导体的雷达散射截面 |
|
465.tonto 量子化学 |
Fortran 95 |
Tonto |
Tonto是一个面向对象的量子化学程序包,465.tonto计算面向量子晶体学,它基于一个符合X光衍射实验数据的、约束的分子Hartree-Fock波函数 |
|
470.lbm 流体动力学 |
ANSI C |
470.lbm使用LBM(格子波尔兹曼方法)模拟非压缩流体,它模拟了两种情况:类似活塞推动的剪切 |
|
|
481.wrf 天气预报 |
Fortran 90 & C |
WRF v2.0.2 |
481.wrf基于WRF(Weather Research and Forecastin)模型,对NCAR的数据进行了计算,数据包括了UTC 2001.06.11到UTC 2001.06.12以三小时为间隔的数据 |
|
482.sphinx3 语音识别 |
C |
Sphinx-3 |
语音识别 |
5、背景说明:
CINT2006包括C编译程序、量子计算机仿真、下象棋程序等,CFP2006包括有限元模型结构化网格法、分子动力学质点法、流体动力学稀疏线性代数法等。为了简化测试结果,SPEC决定使用单一的数字来归纳所有12种整数基准程序。具体方法是将被测计算机的执行时间标准化,即将被测计算机的执行时间除一个参考处理器的执行时间
,结果称为SPECratio。SPECratio值越大,表示性能越快(因为SPECratio是执行时间的倒数)。CINT2006或CFP2006的综合测试结果是取SPECratio的几何平均值。
SPEC CPU 2006包括了CINT2006和C FP2006两个子项目,前者用于测量和对比整数性能,而后者则用于测量和对比浮点性能,SPEC CPU 2006中对SPEC CPU 2000中的一些测试进行了升级,并抛弃/加入了一些测试,因此两个版本测试得分并没有可比较性。
SPEC CPU测试中,测试系统的处理器、内存子系统和使用到的编译器(SPEC CPU提供的是源代码,并且允许测试用户进行一定的编译优化)都会影响最终的测试性能,而I/O(磁盘)、网络、操作系统和图形子系统对于SPEC CPU2006的影响非常的小。
An ounce of honest data is worth a pound of marketing hype(一盎司诚实的数据值得一磅的市场宣传)是SPEC组织成立的座右铭,为了保持数据的公平、可信度以及有效,SPEC CPU测试使用了现实世界的应用程序,而不是用循环的算术操作来进行基准测试。SPEC CPU 2006包括了12项整数运算和17项浮点运算,除此之外,还有两个随机数产生测试程序998.sperand(整数)和999.specrand(浮 点),它们虽然也包含在套件中并得到运行,但是它们并不进行计时以获得得分。这两个测试主要是用来验证一些其他组件中会用到的PRNG随机数生成功能的正确性。各个测试组件基本上由C和Fortran语言编写,有7个测试项目使用了C++语言,而Fortran语言均用来编写浮点部分。
CINT2006包括C编译程序、量子计算机仿真、下象棋程序等,CFP2006包括有限元模型结构化网格法、分子动力学质点法、流体动力学稀疏线性代数法等。为了简化测试结果,SPEC决定使用单一的数字来归纳所有12种整数基准程序。具体方法是将被测计算机的执行时间标准化,即将被测计算机的执行时间除一个参考处理器的执行时间,结果称为SPECratio。SPECratio值越大,表示性能越快(因为SPECratio是执行时间的倒数)。CINT2006或CFP2006的综合测试结果是取SPECratio的几何平均
6、工具测试步骤和注意事项
speccpu使用说明
speccpu安装运行
tar -zxvf spec2006-v1.2-2.sw64built.tar.gz
cd spec2006-v1.2
source shrc
vim bin/runspec //在第一行和第二行,修改实际路径
vim bin/specdiff //在第一行和第二行,修改实际路径
单核
runspec -c swgcc710-base-O2 –tune=base -i ref -n 3 -r 1 –noreportable all
多核
runspec -c swgcc710-base-O2 –tune=base -i ref -n 3 -r 4 –noreportable all
speccpu测试参数
配置文件:XX.cfg,配置文件中可以包含上述命令的所有信息,但是runspec命令的优先级高。此文件在spec的解压目录下,由提供的cfg文件修改而来。
测试规模:ref(测试规模有test,ref,train其中test最小跑的时间最短,如果测试编译器正确性的时候可以用test规模,但是想测试性能时候用ref)
测试次数:iterations=3次(编译器性能稳定时候测一次就行),也可以写成-n 3; tips4:如果想得到加权统计的结果,也就是常说的cpu的spec分数,需要设置iterations大于等于3。
测试范围: all 表示进行fp和int测试(将all替换成int 或 fp 进行定点和浮点的测试;将all替换成456/444等文件编号,表示对某一测试项进行单独测试)。 对于CPU的SPEC测试,默认这一项是all,但是对于其中的某一项测试分数不满意,可通过指定此测试项的编号,进行单独测试。测试也会得到一个分数,做单项的性能调优时候,可以用得到。
输出格式:-o text,screen,pdf 表示测试完成,生成报告的格式,依次分别是txt,屏幕显示和pdf格式,保存目录在spec解压目录result中。
noreportable && reportable : 表示检测/不检测生成的二进制文件是否修改过。–reportable 如果原来生成的二进制文件被修改了,则运行时会自动重新编译生成二进制文件,确保运行的程序是原始的程序。
测试核数:-r 设置测试的CPU核心数目;
测试模式:-tune = base 基准测试;-tune = peak 峰值测试;-tune默认是base 可以选择base, peak, or all ,Report 首先是base,其次是peak.
-I : 表示测试中,如遇报错,略过错误继续测试;
常用测试参数说明
上面给出了例子,介绍了主要的测试参数配置。下面给出一组常用的测试命令及意义。
runspec -c test.cfg -i test -I all 基于最小测试数据集快速执行所有的测试,测试过程中如果某个用例发生错误,则跳过错误用例,继续执行其他用例。一般不用于不用于正式测试,验证环境是否有问题。
runspec -c test.cfg -i ref -n 3 -I all 基于最大测试数据集全面执行所有的测试,用于测试单核CPU,测试过程中如果某个用例发生错误,则跳过错误用例,继续执行其他用例。
runspec -c test.cfg –r ref –n 3 fp 基于最大测试数据集,只运行fp测试
runspec -c test.cfg –r ref –n 3 int 基于最大测试数据集,只运行int测试
runspec -c test.cfg -i ref 473.astar 基于最大测试数据集只执行473.astar单个测试。
runspec –c test.cfg –i ref –rate 4 int 基于最大数据测试集进行rate测试,运行4线程测试的分值
7.
性能优化
“跑分”这件事,相信各位读者对此并不陌生。“不服跑个分”已经成为了某些手机发布时的保留节目。对于普通用户来说,最常用的跑分程序大概就是鲁大师和安兔兔了。安装一个程序,然后再点几个按钮,几分钟以后跑分结果就出来了,整个过程简单轻松。如果要跑分的平台不是运行Windows系统的X86平台,也不是运行安卓系统的ARM平台,而是运行国产操作系统的国产处理器平台,用什么方法来衡量这些平台上的处理器性能呢?这时,我们可以使用一个重量级的跑分程序SPEC CPU 2006。
SPEC CPU 2006包含12项整数测试,17项浮点测试,共计29个测试项目。测试以后会分别根据每一项的测试成绩,用几何平均算出最终的整数测试成绩和浮点测试成绩。根据编译选项设置的不同,可以得到处理器的基础(base)性能和峰值(peak)性能。对于SPEC CPU 2006的具体内容,网上已经有很多材料了,在此我不做赘述。在这里,我着重介绍单核peak性能的测试。
1 三款国产处理器性能对比
使用SPEC CPU 2006,我们可以对各种国产处理器的性能做一个评价。这里,我们首先对比三款国产处理器的SPEC CPU 2006性能。
飞腾
FT2000-4处理器没有官方的SPEC CPU 2006性能。网友yygg100使用飞腾的内部测试配置文件,得到了FT2000-4处理器的整数峰值性能为23.2分;遗憾的是,在这个测试中并没有进行浮点性能的测试,该网友也没有提供配置文件的细节。这个成绩已经初步实现了飞腾在2016年的规划,即到2018年SPEC CPU 2006性能达到20~30分。
https://www.guancha.cn/zhangchengyi/2016_12_26_386083_s.shtml
兆芯
则直接在官网上公开了处理器的性能,目前KX-6000的性能为3GHz下单核整数性能29.2分,浮点性能则高达38分。由于兆芯处理器采用X86指令集,在进行性能测试的时候兆芯可以使用Intel编译器来获得最高性能,这也是兆芯的生态优势之一。
龙芯
3A4000,采用28nm工艺,主频2.0 GHz下,单核peak整数性能21.1分,浮点性能21.2分;单核base整数19.1分,浮点18.7分。我在去年试图复现这个成绩,没有成功,即使超频到2.15GHz的情况下,最终的成绩也没有超过20分,深感遗憾。现在我想再试一下,以正视听。

图1 三款国产处理器的单核性能对比
2 影响处理器性能的因素
在性能评测中,影响性能的因素有很多,简单的讲可以概括为以下几个个部分:
- 处理器核的设计水平。处理器核的性能是决定处理器性能的最关键因素。在相同的主频下,使用高效处理器核的处理器性能更好。
- 处理器主频。采用同样的处理器核,更高的处理器主频能够有更好的性能。优秀的制造工艺能够显著提高处理器的主频。比如,同样采用FT663内核,采用40nm工艺的飞腾FT2000-2处理器主频只有1.0 GHz,而采用16/14 nm工艺的FT2000-4处理器主频高达2.6 GHz。采用优秀的物理设计,也能够显著提高处理器的主频,比如龙芯3A3000处理器和龙芯3A4000处理器都采用28 nm工艺流片,前者主频只有1.5 GHz,而后者的主频提高到了2.0 GHz。
- 处理器的缓存大小。众所周知,Intel的处理器阉割二级缓存以后就变成了奔腾。更大的处理器缓存,有助于提高处理器的性能。比如,龙芯3A2000处理器共享3级缓存为4M,龙芯3A3000处理器的共享三级缓存提高到了8M,使得3A3000处理器的性能有了更多提升。
- 内存的访存速度。有部分应用是访存密集型的,对这些应用来说,提高内存的访存性能能够有效提高处理器性能。影响内存性能的因素有内存的频率、内存通道的数目。如果主板上有多个处理器,还需要考虑每个处理器和内存的距离。
- 编译选项。优秀的编译器,加上与应用特征匹配的编译选项,能够显著提高计算的性能。在Intel平台上,要全面发挥处理器的性能,最佳选择是使用Intel 编译器;如果使用开源的GCC编译器,往往不能充分发挥处理器的能力。比如,兆芯KX6000处理器 SPEC CPU 2006 峰值性能整数29.2分,浮点38分,就是使用Intel 编译器测出来的。此外,还有大量的编译选项提高二进制文件性能,选择合适的编译选项是提高性能的重要手段。比如,对于支持avx指令的处理器,在使用GCC进行编译的时候开启-mavx选项,可能会显著提高程序的性能。
- 操作系统内核。过于古老的操作系统内核可能无法很好的支持新处理器的特性。如果操作系统内核编译的时候没有设定正确的选项,也可能无法支持新的处理器特性。以龙芯处理器为例,龙芯3A4000处理器增加了MSA指令,支持128位向量操作,如果操作系统内核不支持MSA,那么所有启用了MSA指令的二进制文件都无法正常运行,也就无法发挥处理器的性能。
- 程序运行依赖底层函数库。程序运行依赖的libc库和libm库,对处理器性能的发挥也有影响。高性能的数学库能够加快底层数学函数的计算,提高计算性能。如果是进行矩阵运算、信号处理,那么高性能的BLAS、LAPACK库、FFT库也能提高程序的运算速度。
3 龙芯3A4000处理器的SPEC CPU 2006性能调优
在对龙芯3A4000进行性能测试的时候,我测试了操作系统内核、内存性能、主频、编译选项等对操作系统性能的影响。
3.1 编译器优化选项
首先,我考察了编译器的各种优化选项对性能的影响。此时,我的测试环境是龙芯3A4000 处理器,主频1.8GHz,配单根8GB 2400MT/s内存条。操作系统为龙梦Fedora 28,内核版本为5.4.60,编译器版本为GCC 8.4。我简单尝试了O2、O3、Ofast三个优化选项,得到的SPEC CPU 2006性能如图2所示。
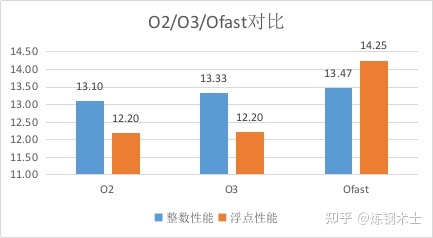
图2 采用O2,O3,Ofast选项时的处理器性能对比
这个性能看起来实在是不怎么样。从O2到O3再到Ofast,程序的性能有些许的提升,但距离龙芯官方生成的20分还差的很远。
接下来,我们可以通过进一步编译器参数来对处理器的性能进行优化。我采用的主要编译器参数和作用如下表所示。
| 编译器参数 | 作用 |
| -march=loongson3a | 开启针对龙芯3A处理器的优化 |
| -mabi=n32 | 使用N32的ABI |
| -funroll-all-loops | 循环展开 |
| -mmsa | 使用MIPS SIMD指令 |
| -flto | 开启链接时优化 |
| -ftree-parallelize-loops | 开启自动并行 |
| -fprofile-generate, -fprofile-use | 使用profile guided optimization |
对每个测试项目的编译参数,都进行了调整,最终得到的peak性能分数提高到了整数18.09分,浮点17.64分,相对于仅使用Ofast参数的性能分别提高了34%和24%。图4对比了只使用Ofast参数的性能和peak性能的对比。
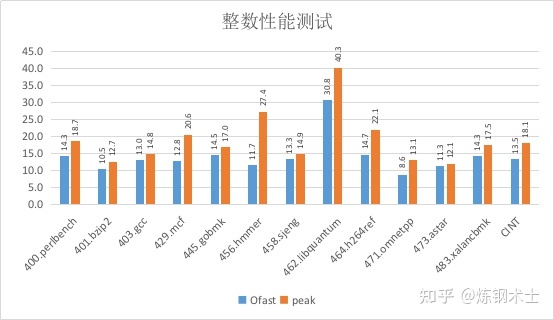

图3~4 peak性能和仅采用Ofast选项的性能对比
从测试的结果看,仅仅依靠编译选项的调整,就可以大幅提高应用程序运行的速度。对于部分测试的性能,甚至有数倍的性能提升。比如,456.hmmer测试项目的分数从11.7分提高到27.4分,性能是之前的2.3倍,这主要是因为启用了MIPS的SIMD指令;436.cactusADM测试项目的分数从2.5分提高到7.3分,性能是之前的2.9倍。
3.2
操作系统内核的选择
除了编译选项的调整,操作系统内核也对应用程序的性能有着非常大的影响。采用同样的编译选项,我分别使用Fedora 28的5.4.60内核以及龙芯提供的4.19.161内核进行了性能测试。使用4.19.161内核,进一步提升了程序的性能,整数/浮点性能分别从18.09分/17.64分,提高到了18.8分/19.92分,性能的提升分别为4%和13%。
如图5所示,429.mcf性能从20.56分提高到了24.9分,性能提高了21%。而性能提升最为明显的项目是436.cactusADM,分数从7.3分提高到了44.9分,性能暴涨到原来的6.15倍,简直像开挂了一样。这也表明龙芯公司在操作系统内核的优化上,也做了很多工作。
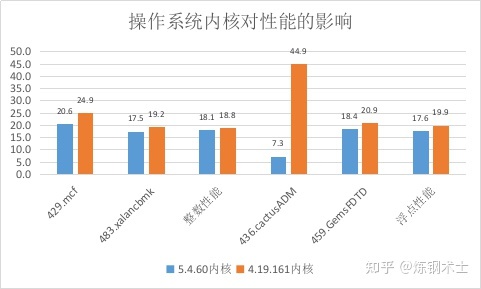
图 5 操作系统内核对性能的影响
3.3
内存性能
进一步,我对比了内存性能对系统性能的影响。当系统增加一根内存条,组成双通道以后,整体的性能再次提升,整数/浮点性能分别提升到了19.60分和20.99分,相比之前的测试分别又提高了4.3%和5.5%。其中,性能提升较大的项目如图6所示。很明显,这些项目也是访存密集型的。在对内存性能进行调优以后,1.8 GHz主频的龙芯3A4000处理器的浮点性能已经超过了20分。
从测试的结果也可以看出,462.libquantum测试对访存性能非常敏感,将内存从单通道升级到双通道,性能提升了66%。

图6 内存对性能的影响
3.4
处理器主频
以上的测试都是在1.8 GHz主频下完成的。实际上,龙芯3A4000处理器睿频频率可以到2.0 GHz。而使用龙芯内核开发者flygoat提供的龙梦A1901主板内核超频补丁,还可以进一步提升龙芯3A4000处理器的主频到2.2 GHz。
提高主频的话,龙芯3A4000处理器的性能究竟可以提升到什么程度?从下图7可以看出,在2.0GHz主频下,整数性能和浮点性能分别为21.3分和22.9分,这已经超过了龙芯官方提供的整数21.1分、浮点21.2分的peak性能。
我所测试的A1901主板,3A4000处理器可以稳定在2.1GHz主频下,在此主频下整数性能和浮点性能分别为22.2分和23.8分。
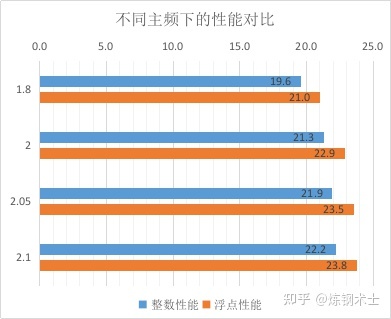
图7 不同主频下龙芯3A4000处理器的性能
然而,这并非是龙芯3A400处理器的性能极限。我在测试中使用的是GCC 8.4编译器,其中对龙芯3A4000中指令的支持并不完善。比如,龙芯3A4000中实现了256位向量操作指令LASX,但我在跑分的时候只用到了128位的向量操作指令MSA。如果编译器中的编译选项对龙芯处理器进行了深度的调优,整个系统的性能还有进一步提升的空间。
经过上述的测试,我对系统的硬件、软件等方面进行了多种调优,通过优化编译器选项、操作系统内核、内存性能,以及对处理器的超频,将SPEC CPU 2006的性能从最初的整数13.1分、浮点12.2分,提高到了最终的整数22.2分、浮点23.8分(2.1 GHz)。这些优化的经验,对于类似的系统同样适用。
4 针尖对麦芒:飞腾FT2000/4 vs 龙芯3A4000处理器
经过以上的测试,我们了解了龙芯3A4000处理器的性能,那么和友商的飞腾FT2000-4处理器相比,龙芯3A4000的差距有多大呢?
| 项目 | 龙芯3A4000 | 飞腾2000-4 |
| 处理器核 | GS464V | FTC663 |
| 指令集 | LoongISA(MIPS R5+MSA+龙芯扩展指令) | ARM V8 |
| 处理器核数 | 4 | 4 |
| 处理器主频 | 2.0 | 2.6 |
| 工艺 | 28nm | 14nm |
| 功耗 | 30~50W | 10~15W |
| 内存控制器 | DDR4 最高2400MT/s | DDR4 最高 3200MT/s |
表格可以看出,采用先进工艺的FT2000-4处理器在主频和功耗上大幅领先龙芯3A4000处理器。那么处理器的真实性能有多大的差距呢?最近,贴吧网友yygg100对FT2000处理器的SPEC CPU 2006的peak性能进行了测试,得到了在2.6GHz主频下单核peak整数性能23.2分的成绩。虽然他的测试并不完善,只有整数性能测试,没有浮点性能测试的数据,但这依旧是目前已知的FT2000处理器单核性能的最高值。
我们将这个数据与龙芯3A4000在2.0GHz下的性能进行了对比,龙芯3A4000性能为21.3分。由于龙芯处理器工艺落后,主频较低,主频只有飞腾处理器的77%,而整数性能达到了飞腾处理器的92%。

图8 龙芯3A4000和飞腾FT2000-4处理器整数性能对比。
从图中可以看出,在12项测试中,飞腾处理器在8个项目上性能强于龙芯3A4000,其中libquantum这一项的性能差距最大,龙芯处理器性能只有FT2000的58%,因为飞腾处理器不仅主频较高,而且内存频率为2666MT/s,相比龙芯3A4000的2400MT/s有明显的优势。
而在429.mcf,445.gobmk, 456.hmmer, 458.sjeng这4个项目上,2.6 GHz的飞腾2000处理器性能弱于2.0 GHz的3A4000处理器。随着龙芯3A5000处理器的上市,飞腾2000处理器的单核性能领先优势将会逐渐消失。
5 对龙芯3A5000的展望
龙芯3A5000处理器已经流片发布,很快就要发布了。龙芯3A5000处理器将采用台积电12nm工艺流片,处理器主频有望提高到2.5 GHz以上,和友商处理器的主频差距进一步缩小。据称,龙芯3A5000的SPEC CPU 2006 性能将达到25~30分。
根据我对龙芯3A4000处理器的性能测试,如果把龙芯3A5000处理器视为3A4000的简单升级版,仅仅提高主频,内存频率和缓存都不变,采用图7中的数据,进行一个简单的数据拟合,我预测龙芯3A4000处理器在2.5 GHz 主频时peak性能约为整数25.9分、浮点26.7分。龙芯3A5000的L3 缓存大小将从8MB提升到16MB,提高内存的频率(有望达到3200MT/s),还会进一步提升处理器的性能,我们可以假设有这些调整可以带来5%的性能提升;龙芯3A5000处理器采用了Loongarch指令集,摆脱了MIPS指令集的历史包袱,根据胡伟武研究员的报告,仅仅是指令集的更新,就可以让性能提升16.6%和9.4%,我们可以保守估计有9%的性能提升。
根据上面的计算,我认为龙芯3A5000处理器的SPEC CPU 2006单核peak性能达到整数30分、浮点30分是非常有可能的。届时,龙芯处理器将在单核性能上追平或赶超其他国产处理器。龙芯3C5000的出现,也将缩小龙芯处理器的多核性能与其他国产处理器的优势,有助于龙芯扩展服务器市场。
致谢
本次测试借用了网友gueenet的龙芯3A4000主机,对他的慷慨和信任我深表感谢!在对内核的性能测试中得到了陈华才、flygoat的指导。对SPEC CPU 2006性能的探索,受到了网友yygg100所发视频的启发,对他的视频分享一并表示感谢。
参考资料:
对SPEC CPU感兴趣的朋友,可以参考
https://github.com/zevanzhao/loongson-notes
中的文档,进行龙芯平台下SPEC CPU 2006的跑分。