上一节讲的cls的创建dataset还是使用的处理复制文件从而直接导入的傻瓜方法,该类方法在后期数据集特别大时会造成内存的重复读取耗时问题。且目标检测领域dataset类是避不开的,所以针对沐神的代码进行dataset从0开始搭建!
目录
1.目标检测数据集–banana
1.1描述
给的文件中,有train与val两个文件,这两个文件里面都是右边这张图所示:


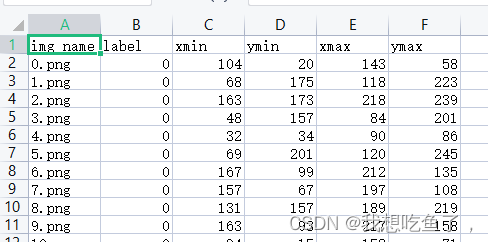
其中label里面如下图所示:第一列写着images里面的图片名称,后五列分别为图片包含目标的种类,该目标左上角x,y坐标与右下角xy坐标:
1.2读取文件:
代码如下图所示:
data_dir = '/CV/xhr/banana-detection'
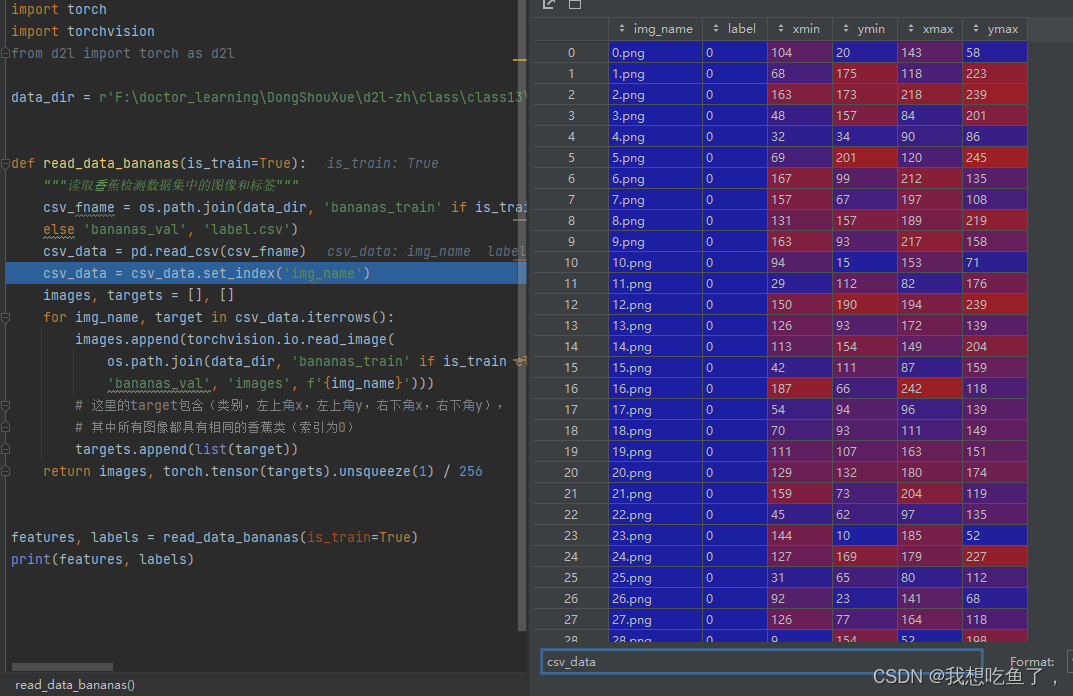
def read_data_bananas(is_train=True):
"""读取⾹蕉检测数据集中的图像和标签"""
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train
else 'bananas_val', 'label.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('img_name')
images, targets = [], []
for img_name, target in csv_data.iterrows():
images.append(torchvision.io.read_image(
os.path.join(data_dir, 'bananas_train' if is_train else
'bananas_val', 'images', f'{img_name}')))
# 这⾥的target包含(类别,左上⻆x,左上⻆y,右下⻆x,右下⻆y),
# 其中所有图像都具有相同的⾹蕉类(索引为0)
targets.append(list(target))
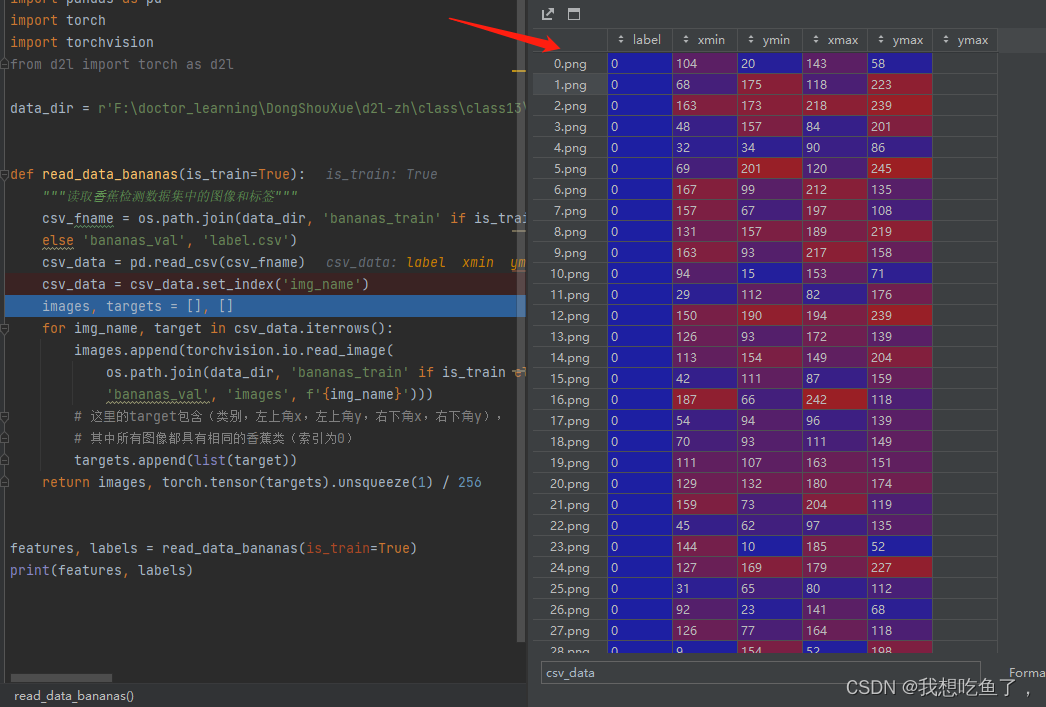
return images, torch.tensor(targets).unsqueeze(1) / 256关于里面的set_index(‘image_name’),其是配套后面的for loop里面的.iterrows使用的,set_index表示讲img_name这一列的元素替换掉原始的索引列,如下图所示:使用该命令前:
使用该命令后:可以看到原先索引标号0.1.2…替换成了img_name列中的各个元素。
为什么这么处理?
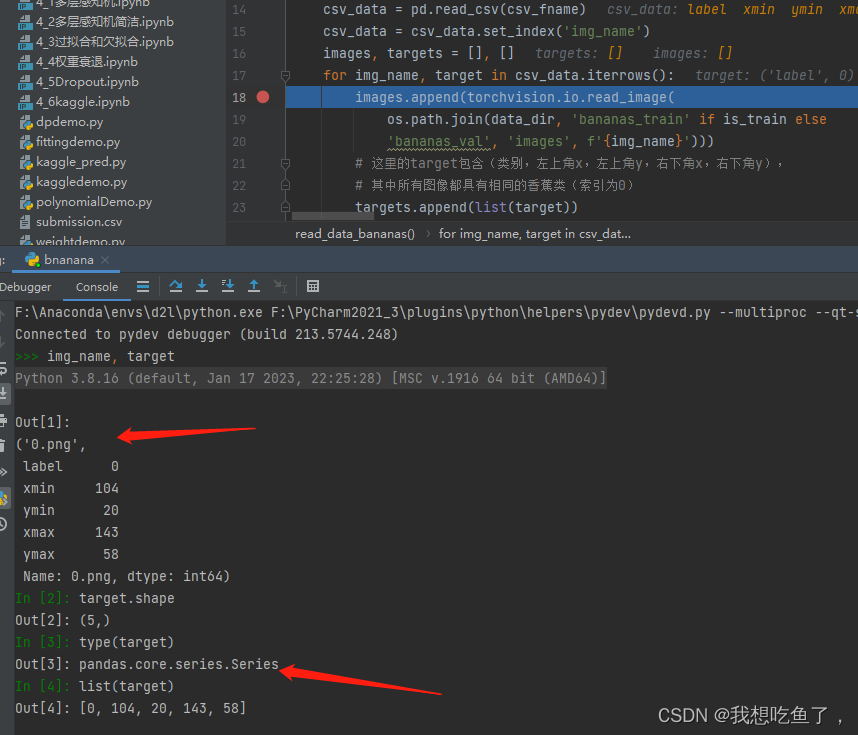
因为要有for loop里面的.iterrows()操作,该操作返回的两个值分别为每一行的索引与每一行剩下的元素:其中这个剩下的多个元素是pandas的Series数据结构,可以用list换成列表。
在注意里面这个torchvision.io.read_image(path)操作是将path中的图片(支持JPEG,PNG,BMP,GIF,TIFF等)从磁盘上读取并转换成tensor张量,输出为(C,H,W)
1.3 读取函数最终返回值
让我们看一下这个函数最终返回的是啥:
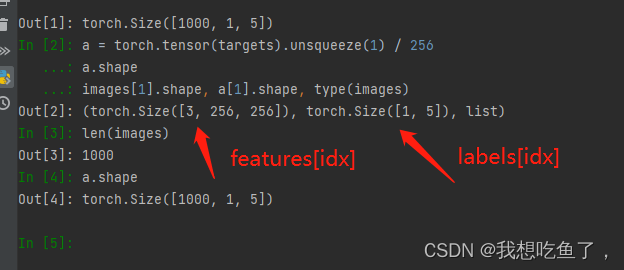
这里让a等于后面这一长串,返回的images是一个有1000个元素的list(一共有1000张图片),其中的每一个元素为一个tensor的图片(C,H,W),另一个值a是一个tensor(1000, m, 5),这里的m表示一张图设有几个目标物体,这里每张图都只有一个,所以m设为1.
1.4 构造dataset类
注意,这里面的__getitem__()最后索引的features[idx]与labels[idx]就是1.3那一张图里面对应的东西,即返回的是每一张idx对应的图片的
(c,h,w).float
与该图片对应的标注
(m, 5)
。
class BananasDataset(torch.utils.data.Dataset):
"""⼀个⽤于加载⾹蕉检测数据集的⾃定义数据集"""
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)dataset数据集,构造两个函数,一个是__len__,能够返回这个数据集有多长;另一个是__getitem__,给定第i个样本怎么读,features[idx].float将第idx个图片转成float,再将对应的labels[idx]返回回去.
dataloader与cls不太一样,因为一张图片可能会有多个检测物体,这也就解释了为什么在一开始的函数要unsqueeze增加第一位的维度,这样最终形成的标签小批量的形状为(bs,m,5),这个m是数据集的任何图像中边界框可能出现的最大数量。
1.5数据加载
常规操作啦:
def load_data_bananas(batch_size):
"""加载⾹蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter检查第一个batch:
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
batch[0].shape, batch[1].shape
'''
read 1000 training examples
read 100 validation examples
(torch.Size([32, 3, 256, 256]), torch.Size([32, 1, 5]))
'''
1.6显示方法与plt和opencv的补充:
imgs = (batch[0][0:10].permute(0, 2, 3, 1)) / 255
axes = d2l.show_images(imgs, 2, 5, scale=2)
for ax, label in zip(axes, batch[1][0:10]):
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])这会使用plt显示前十张图片。
permute这个操作的目的通常是将通道维(C)移到最后一维,在这里tensor对应的是(B,C,H,W),例如OpenCV与plt中读取的图片格式为(B, H, W, C)。这样,通过使用.permute(0, 2, 3, 1)可以将PyTorch中的张量格式转换为OpenCV中读取的图片格式,方便进行后续处理或展示。
因为应用到imshow命令,他需要的是RGB三通道上的数值均在[0,1]范围之间,所以要将imgs除255进行像素归一化
2.kaggle的树叶分类数据集制作
2.1文件概览
先看看要处理的数据集长什么样:其中,这个train文件夹长这样:
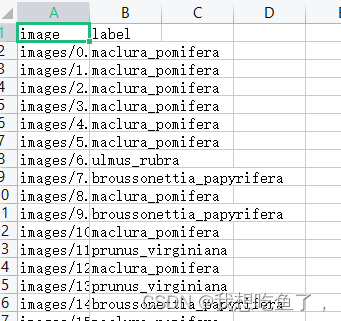
可见,它有两列,第一列为图片相对路径,第二列为图片对应的字符串类别。
2.1文件处理
直接上代码:
data_dir = '/CV/xhr/leaveskaggle'
def read_data_bananas(is_train=True):
"""读取⾹蕉检测数据集中的图像和标签"""
csv_fname = os.path.join(data_dir, 'train.csv')
csv_data = pd.read_csv(csv_fname)
csv_data = csv_data.set_index('image')
leaves_labels = sorted(list(set(csv_data['label'])))
n_classes = len(leaves_labels)
class_to_num = dict(zip(leaves_labels, range(n_classes)))
csv_data = csv_data.replace({'label': class_to_num})
images, targets = [], []
for img_name, target in csv_data.iterrows():
images.append(torchvision.io.read_image(
os.path.join(data_dir, f'{img_name}')))
# 这⾥的target包含(类别,左上⻆x,左上⻆y,右下⻆x,右下⻆y),
# 其中所有图像都具有相同的⾹蕉类(索引为0)
targets.append(list(target))
return images, torch.tensor(targets)相比前面的代码,可知我们最终要返回的labels类不再是(bs,n,5),而是(bs,1),首先我们要解决将字符串的类别名字转换为数字,通过以下的代码实现:
csv_fname = os.path.join(data_dir, 'train.csv')
csv_data = pd.read_csv(csv_fname)
leaves_labels = sorted(list(set(csv_data['label'])))
n_classes = len(leaves_labels)
# 生成 字符串:n 字典!
class_to_num = dict(zip(leaves_labels, range(n_classes)))
# 用上面生成的字典替换原字符串为对应数字
csv_data = csv_data.replace({'label': class_to_num})
csv_data.head()
len(class_to_num)
'''
176
'''可知,首先先生成一个针对label这一列,每一个字符串的种类对应一个编号的字典,具体要长这个样:

然后再根据这个replace命令,将label里面的每个字符串换成上面这个字典对应的标号,记住这个代码过程!!这样,我们就得到了每个label对应的是不同数字(从0-175以为一共有176个类)。然后剩下的操作与banana一样。
看看到这一步得到了啥:
images, labels = read_data_bananas(is_train=True)
images[1].shape, labels[1].shape
'''
(torch.Size([3, 224, 224]), torch.Size([1]))
'''
2.2加载数据集dataset与loader
直接上代码:
class BananasDataset(torch.utils.data.Dataset):
"""⼀个⽤于加载⾹蕉检测数据集的⾃定义数据集"""
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
# 注意这个reshape(-1)
self.labels = self.labels.reshape(-1)
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
def __getitem__(self, idx):
return (self.features[idx].float(), self.labels[idx])
def __len__(self):
return len(self.features)
def load_data_bananas(batch_size):
"""加载⾹蕉检测数据集"""
train_iter = torch.utils.data.DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = torch.utils.data.DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter看一下得到了啥:
batch_size = 32
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
batch[0].shape, batch[1], batch[1].shape
'''
read 18353 training examples
read 18353 validation examples
(torch.Size([32, 3, 224, 224]),
tensor([165, 56, 170, 64, 29, 24, 173, 77, 130, 67, 28, 77, 145, 62,
173, 10, 165, 51, 85, 101, 31, 78, 162, 120, 100, 145, 77, 162,
67, 40, 142, 160])),
torch.Size([32]))
这里要注意,对于图片分类,拿到的每个iter的第一个image,尺寸为(bs,c,h,w);但是拿到的label为
(bs),不能是(bs,1),所以要在dataset中事先将labels重新拉成一维的。
2.3网络
用了Densenet,直接套,注意更改输入的通道,输出的检测类别:
def conv_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1))
class DenseBlock(nn.Module):
def __init__(self, num_convs, input_channels, num_channels):
super(DenseBlock, self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block(
num_channels * i + input_channels, num_channels))
self.net = nn.Sequential(*layer)
def forward(self, X):
for blk in self.net:
Y = blk(X)
# 连接通道维度上每个块的输⼊和输出
X = torch.cat((X, Y), dim=1)
return X
def transition_block(input_channels, num_channels):
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2))
b1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# num_channels为当前的通道数
num_channels, growth_rate = 64, 32
num_convs_in_dense_blocks = [4, 4, 4, 4]
blks = []
for i, num_convs in enumerate(num_convs_in_dense_blocks):
blks.append(DenseBlock(num_convs, num_channels, growth_rate))
# 上⼀个稠密块的输出通道数
num_channels += num_convs * growth_rate
# 在稠密块之间添加⼀个转换层,使通道数量减半
if i != len(num_convs_in_dense_blocks) - 1:
blks.append(transition_block(num_channels, num_channels // 2))
num_channels = num_channels // 2
net = nn.Sequential(
b1, *blks,
nn.BatchNorm2d(num_channels), nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(num_channels, 176))检测一下:
devices = d2l.try_all_gpus()
net.to(devices[0]);
X = torch.rand(size=(32, 3, 224, 224)).to(devices[0])
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
2.4训练
套用之前的cls训练即可:
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,
lr_decay):
trainer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9,
weight_decay=wd)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)
num_batches, timer = len(train_iter), d2l.Timer()
legend = ['train loss', 'train acc']
if valid_iter is not None:
legend.append('valid acc')
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=legend)
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
net.train()
metric = d2l.Accumulator(3)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(net, features, labels,
loss, trainer, devices)
metric.add(l, acc, labels.shape[0])
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[2],
None))
if valid_iter is not None:
valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter)
animator.add(epoch + 1, (None, None, valid_acc))
scheduler.step()
measures = (f'train loss {metric[0] / metric[2]:.3f}, '
f'train acc {metric[1] / metric[2]:.3f}')
if valid_iter is not None:
measures += f', valid acc {valid_acc:.3f}'
print(measures + f'\n{metric[2] * num_epochs / timer.sum():.1f}'
f' examples/sec on {str(devices)}')命令行:
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 20, 2e-4, 5e-4
loss = nn.CrossEntropyLoss(reduction='none')
lr_period, lr_decay = 4, 0.9
train(net, train_iter, None, num_epochs, lr, wd, devices, lr_period,
lr_decay)