0413
第一、二、三、四、五章
六、事务(TRANSACTION)
28.事务ACID原则、脏读、不可重复读、幻读
1.什么是事务?
事务就是将
一组SQL语句放在同一批次内去执行
;
如果
一个SQL语句出错
,则该批次内的
所有SQL都将被取消执行
;(要么都成功,要么都失败)
MySQL事务处理只支持
InnoDB
和BDB数据表类型。
2.事务原则(巨重要)
ACID
原则:
原子性(Atomicity) 、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)
(脏读,幻读,不可重复读…)
参考博客链接:
事务ACID理解
原子性(Atomicity):
-
原子性是指事务是一个
不可分割的工作单位
,
事务中的操作要么都发生,要么都不发生
。或者说是两个操作要么一起成功,或者一起失败,不能只发生其中一个动作。
一致性(Consistency):
-
事务前后数据的完整性必须保持一致。针对一个事务
操作前与操作后
的状态一致。例如:两个人转账,两人一共1000块,操作前和操作后的总和都是1000。
隔离性(Isolation):
-
事务的隔离性是
多个用户并发访问数据库时
,数据库为每一个用户开启的事务,不
能被其他事务的操作数据所干扰
,多个并发事务之间要相互隔离。
持久性(Durability):
-
持久性是指
一个事务一旦被提交
,它对数据库中数据的
改变就是永久性的
,接下来
即使数据库发生故障也不应该对其有任何影响
,即
事务结束后
的数据不会因为外界原因导致数据丢失; -
举例:
操作前A:800,B:200
操作后A:600,B:400
如果在
操作前(事务还没有提交)服务器宕机或者断电
,那么重启数据库以后,数据状态应该为
A:800,B:200 – 相当于没发生,回滚到事务开始前的状态
如果在
操作后(事务已经提交)服务器宕机或者断电
,那么重启数据库以后,数据状态应该为
A:600,B:400 – 即实务操作成功后,带来的改变是不可逆的。
隔离所导致的一些问题:
①
脏读(Dirty Read)
:
-
指
一个事务读取了另外一个事务未提交的数据
的现象就是
脏读
。 -
例如:
在事务A执行过程中,事务A对数据资源进行了修改,事务B读取了事务A
修改后的数据
;
由于某些原因,事务A并没有完成提交,发生了
RollBack
操作,则事务B读取的数据就是
脏数据
。
②
不可重复读(Nonrepeatable Read)
:
-
在同一个事务中读取表中的某一行数据,
前后两次读取的数据不一致
的现象就是
不可重复读(Nonrepeatable Read)
。(这个不一定是错误,只是某些场合不对) -
例如:
事务B读取了两次数据资源,在这两次读取的过程中事务A修改了数据,导致事务B在这两次读取出来的数据不一致。 -
不可重复读强调的是
单条数据的更新
。

③虚读(幻读):
-
是指
在一个事务内读取到了别的事务插入的数据
,导致
前后读取数量总量不一致
。(一般是
行影响
,如下图所示:多了一行) -
例如:
事务B前后两次读取同一个范围的数据,在事务B两次读取的过程中事务A新增了数据,导致事务B后一次读取到前一次查询没有看到的行。 -
幻读强调的是
整个集合的增减
。

注意:
幻读和不可重复读有些类似,但是幻读强调的是
集合的增减
,而不可重复读强调的是
单条数据的更新
。
29. 测试事务实现转账
执行事务:(原理)
mysql 是默认
开启事务自动提交
,即
autocommit = 1
所以要手动处理事务,就要①先关闭(系统默认的)事务自动提交的设置:
-- 关闭
SET autocommit = 0;
②然后就可以手动处理事务了,先开启事务:
-- 事务开启
START TRANSACTION; -- 标记一个事务的开始,从这个之后的sql都在同一个事务内
③然后是一组sql:
INSERT XX
INSERT XX
④执行完这一组sql,可以有以下两种操作:
-- 回滚 : 只要没COMMIT,就还可以滚回到的原来的样子
ROLLBACK;
-- 提交 : 持久化(一旦提交,再回滚也滚不回去了)
COMMIT;
⑤最后结束手动处理事务,即恢复到系统默认设置
autocommit = 1
-- 事务结束
SET autocommit = 1; -- 开启自动提交(系统默认设置)
综上:
-- 手动处理事务
-- 1.
SET autocommit = 0; -- 关闭自动提交
-- 2.
-- 事务开启
START TRANSACTION; -- 标记一个事务的开始,从这个之后的sql都在同一个事务内
-- 3.
INSERT XX
INSERT XX
-- 4.
-- 回滚 : 只要没COMMIT,就还可以滚回到的原来的样子
ROLLBACK;
-- 提交 : 持久化(一旦提交,再回滚也滚不回去了)
COMMIT;
--5.
-- 事务结束
SET autocommit = 1; -- 开启自动提交
-- 补充:(了解)
SAVEPOINT 保存点名 -- 设置一个事务的保存点
ROLLBACK TO SAVEPOINT 保存点名 -- 回滚到保存点
RELEASE SAVEPOINT 保存点名 -- 撤销保存点

示例:(
转账实现
)
-- 创建数据库:
CREATE DATABASE `shop` CHARACTER SET utf8 COLLATE utf8_general_ci;
-- 创建数据表:
CREATE TABLE `account` (
`id` INT(4) NOT NULL AUTO_INCREMENT,
`name` VARCHAR(20) NOT NULL,
`money` DECIMAL(10,2) NOT NULL, -- VARCHAR(30)
PRIMARY KEY(`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
-- 插入数据
INSERT INTO `account`
VALUES(12,'小王',1000),(16,'小张',800)
-- 执行事务:
-- 1.关闭自动提交
SET autocommit = 0
-- 2.开启事务
START TRANSACTION
-- 3.一组sql(虽然是一组sql,但也要挨个单句执行,多句执行应该可以,但现在是初学阶段)
UPDATE `account` SET `money` = `money` - 20 WHERE `name`='小王'
UPDATE `account` SET `money` = `money` + 20 WHERE `name`='小张'
-- 4.只要没COMMIT,就可以回滚;一旦提交,再回滚也滚不回去了
ROLLBACK
COMMIT
-- 5.恢复系统的默认设置
SET autocommit = 1
结果:
执行事务之前:
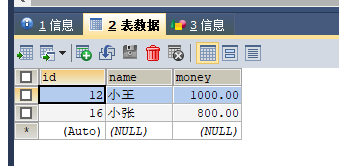
执行事务之后:
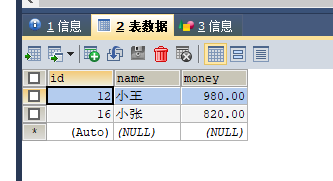
(只要没执行COMMIT,通过执行ROLLBACK是可以回到上上张图片的;一旦执行COMMIT,信息就永久更新,不可逆)
注意:(在实际应用中)
上面的示例只是
手动
去处理事务,在实际应用中,会把上面示例中的第3步和第4步放在一个
try...catch...
中,如果要执行的一组sql没有问题,能成功运行,就自动COMMIT,如果运行失败,相当于是异常情况,就跳到catch中自动回滚。

七、索引(index)
30,31小结
30主要讲了以下内容:
- 啥是索引:是一种数据结构,用它可以快速找到数据。
-
索引的
分类
:主键索引(只能有一个)、唯一索引、常规索引、全文索引。 -
添加索引
的三种方式:1.创建数据表的时候;2.用ALTER创建;3.用CREATE创建。 -
删除索引
:
DROP INDEX 索引名 ON 表名字;
-
查看所有索引
:
SHOW INDEX FROM 表名;
-
然后用
全文索引
写了个例子,来
说明有索引和没索引的区别
:没索引就是整个数据表去搜索,有索引就是直接一下子找到。
这里面用了关键字
EXPLAIN
来
查看sql执行的状况
,相当于是个工具,可以查看这次查询
一共用了多久的时间,查找了多少行数据
。
31中又写了一个例子,依然是
全文索引
:
-
把数据量增加到
100万条
; -
用了一个函数
mock_data()
,先把这个函数写好; -
然后执行这个函数
SELECT mock_data();
-
然后又借助关键字
EXPLAIN
来说明加索引和不加索引的区别:不加索引,查一条数据要用
1s
多,加上索引再查这条数据只用
0.01s
。
结论:
索引在小数据量的时候,用处不大,但是在大数据的时候,优势十分明显
。
30.索引的 介绍、分类、添加、示例
索引的定义:
-
索引(index)是帮助MySQL
高效获取数据
的
数据结构
。
索引的本质:
-
索引是数据结构
。
索引的作用:
-
提高查询速度
; - 确保数据的唯一性;
- 可以加速表和表之间的连接 , 实现表与表之间的参照完整性;
- 使用分组和排序子句进行数据检索时 , 可以显著减少分组和排序的时间;
- 全文检索字段进行搜索优化。
索引的分类:
-
主键索引(
primary key
):
唯一的标识,主键的内容不可重复,且只能有一个列(字段)作为主键。 -
唯一索引(
unique key
):
避免出现重复的列名(字段名)
,可以有多个唯一索引,即可以将
多个列
标识为唯一索引。 -
常规索引(
key / index
):
默认的index 或者 key 关键字 -
全文索引(
FullText index
):
在特定的数据库引擎下才有,如
MYISAM
;
可以快速定位数据。
注意:
主键索引只能有一个;唯一索引可以有多个。
添加所有的三种方式:
参考链接:
数据库创建索引和删除索引的方式总结
1.创建表时给字段增加索引
-- 格式:
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | PRIMARY] INDEX/KEY
[索引名] (字段名)
)ENGINE=INNODB DEFAULT CHARSET=utf8
-- 示例:
CREATE TABLE `result`(
-- 省略一些代码
PRIMARY KEY (`student_name`), -- 主键索引
INDEX/KEY `ind` (`studentNo`,`subjectNo`), -- 常规索引
UNIQUE KEY `UK_IDENTITY_CARD` (`identity_card`), -- 唯一索引
FULLTEXT INDEX `FI_PHONE` (`phone`) -- 全文索引
)ENGINE=INNODB DEFAULT CHARSET=utf8
注意:
因为主键索引是唯一的,所以不需要索引名,直接在括号里写字段名即可。

2.用ALTER在已建好的表上创建索引
-- 格式:
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | ] INDEX/KEY
索引名 (字段名)
-- 示例:
ALTER TABLE `student` ADD PRIMARY KEY (`student_name`); -- 主键索引
ALTER TABLE `result` ADD INDEX `ind`(`studentNo`,`subjectNo`); -- 常规索引
ALTER TABLE `student` ADD UNIQUE KEY `UK_IDENTITY_CARD` (`identity_card`); -- 唯一索引
ALTER TABLE `student` ADD FULLTEXT INDEX `FI_PHONE` (`phone`); -- 全文索引
3.用CREATE在已建好的表上创建索引
语法:
create index 索引名 on 表名(字段)
-- 格式:
CREATE [UNIQUE | FULLTEXT ] INDEX
索引名 ON 表名 (字段名)
-- 示例:
CREATE INDEX `name` ON `student` (`studentname`);
注意:
Create不能用于创建Primary key索引
其他操作:(
删除索引、显示索引信息
)
-- 删除索引:
DROP INDEX 索引名 ON 表名字;
DROP INDEX `name` ON `student` -- 示例
-- 删除主键索引:
ALTER TABLE 表名 DROP PRIMARY KEY;
ALTER TABLE 表名 DROP INDEX 索引名;
-- 显示索引信息:
SHOW INDEX FROM 表名;
一个完整的示例:
-- 显示所有的索引信息:
SHOW INDEX FROM `student`
-- 创建一个索引:
CREATE INDEX `name` ON `student` (`studentname`)
-- 删除索引:
DROP INDEX `name` ON `student`
-- 用explain来查看sql执行的状况,相当于是个工具,可以查看这次查询一共用了多久的时间,查找了多少行数据
-- 非全文索引:
SELECT * FROM `student` WHERE `studentname`='张伟强'
EXPLAIN SELECT * FROM `student` WHERE `studentname`='张伟强'
-- 增加全文索引:
ALTER TABLE `student` ADD FULLTEXT INDEX `name`(`studentname`);
-- 全文索引:
SELECT * FROM `student` WHERE `studentname`='张伟强'
EXPLAIN SELECT * FROM `student` WHERE MATCH(`studentname`) AGAINST('张伟强');
示例所用到的数据表:
结果:
查看所有索引:

非全文索引:


添加全文索引:

全文索引:


解释下上面的
全文索引
:
– 全文搜索通过
MATCH()
函数完成。
– 搜索字符串作为
against()
的参数被给定。搜索以忽略字母大小写的方式执行。对于表中的每个记录行,MATCH() 返回一个相关性值。即,在搜索字符串与记录行在 MATCH() 列表中指定的列的文本之间的相似性尺度。
-- 示例:
EXPLAIN SELECT *FROM student WHERE MATCH(studentname) AGAINST('love');
补充:
全文索引的版本、存储引擎、数据类型的支持情况:
-
MySQL 5.6 以前的版本,
只有 MyISAM 存储引擎支持全文索引
; -
MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎
均支持
全文索引; - 只有字段的数据类型为 char、varchar、text 及其系列才可以创建全文索引;
- 测试或使用全文索引时,要先看一下自己的 MySQL 版本、存储引擎和数据类型是否支持全文索引。
参考链接:
【MySQL优化】——
看懂explain_漫漫长途,终有回转;余味苦涩,终有回甘-CSDN博客_explain
31. SQL编程创建100万条数据测试索引
1.建表app_user:
CREATE TABLE app_user (
`id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'ID',
`name` VARCHAR(50) DEFAULT '' COMMENT '用户昵称',
`email` VARCHAR(50) NOT NULL COMMENT '用户邮箱',
`phone` VARCHAR(20) DEFAULT '' COMMENT '手机号',
`gender` TINYINT(4) UNSIGNED DEFAULT '0' COMMENT '性别(0:男 1:女)',
`password` VARCHAR(100) NOT NULL COMMENT '密码',
`age` TINYINT(4) DEFAULT '0' COMMENT '年龄',
`create_time` DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4 COMMENT='app用户表'
2.批量插入100w条数据:(
mock_data()
是个函数)
DELIMITER $$ -- 写函数之前必须要写,标志
CREATE FUNCTION mock_data()
RETURNS INT
BEGIN
DECLARE num INT DEFAULT 1000000;
DECLARE i INT DEFAULT 0;
WHILE i<num DO
INSERT INTO app_user(`name`,`email`,`phone`,`gender`,`password`,`age`)
VALUES(CONCAT('用户',i),'123345@qq.com',CONCAT('18',FLOOR(RAND()*((999999999-100000000)+100000000))),FLOOR(RAND()*2),UUID(),FLOOR(RAND()*100));
SET i = i+1;
END WHILE;
RETURN i;
END;
-- 执行函数
SELECT mock_data();
-- 查表
SELECT * FROM app_user;
3.测试:
-- 测试:
-- 查看索引信息:
SHOW INDEX FROM `app_user`
-- 删除索引:
DROP INDEX id_app_user_name ON `app_user`
SELECT * FROM app_user WHERE `name` = '用户9999'; -- 1.260 sec
EXPLAIN SELECT * FROM app_user WHERE `name` = '用户9999'; -- 0.002 sec
-- 创建索引:
-- id_表名_字段名 索引名
-- CREATE INDEX 索引名 ON 表名(`字段名`);
CREATE INDEX id_app_user_name ON app_user(`name`);
SELECT * FROM app_user WHERE `name` = '用户9999'; -- 0.001 sec
EXPLAIN SELECT * FROM app_user WHERE `name` = '用户9999'; -- 0.001 sec
结果:
不加索引:


加索引:


查看索引信息:


结论:
索引在小数据量的时候,用处不大,但是在大数据的时候,区分十分明显。
32. 索引的 原则、数据结构
索引的原则:
- 索引不是越多越好;
- 不要对经常变动的数据加索引;
- 小数据量的表建议不要加索引;
- 索引一般应加在查找条件的字段。
索引的数据结构:
1.Hash类型的索引;
2.BTree(B树):INNODB引擎默认的数据结构;
3.全文索引。
– 我们可以在创建上述索引的时候,为其指定索引类型,分两类
hash类型的索引:查询单条快,范围查询慢
btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它)
– 不同的存储引擎支持的索引类型也不一样
InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
NDB 支持事务,支持行级别锁定,支持 Hash 索引,不支持 B-tree、Full-text 等索引;
Archive 不支持事务,支持表级别锁定,不支持 B-tree、Hash、Full-text 等索引;
参考链接:
MySQL索引背后的数据结构及算法原理
32’ 补充1: BTree索引(32中参考链接的内容)
摘要:
MySQL数据库支持多种索引类型,如
BTree索引,哈希索引,全文索引
等等。
为了避免混乱,本文将只关注于BTree索引,因为这是平常
使用MySQL时主要打交道的索引
,至于哈希索引和全文索引本文暂不讨论。
第一部分:数据机构及算法基础
数据库查询
是数据库的最主要功能之一,我们都希望查询数据的速度能
尽可能的快
。
常见的查询算法有
-
顺序查找(linear search):这种复杂度为
O(n)
的算法在数据量很大时显然是糟糕的。 -
二分查找(binary search):二分查找
要求被检索数据有序
; -
二叉树查找(binary tree search):二叉树查找
只能应用于二叉查找树上
;
二叉查找树的改进:平衡二叉树(AVL树)+ 红黑树 –>见下面的
8.3 基于 树 的查找法 补充:红黑树和AVL树的详解和区别
在实际的数据库系统几乎没有使用二叉查找树或其进化品种红黑树(red-black tree)实现,因为数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织)。所以在数据之外,
数据库系统还维护着满足特定查找算法的数据结构
,这些数据结构
以某种方式引用(指向)数据
,这样就可以在这些数据结构上
实现高级查找算法
,这种数据结构就是
索引(index)
。
目前大部分数据库系统及文件系统都采用
B-Tree
或其变种
B+Tree
作为索引结构。
B树
:(1)–>(2)–>(3)
(1)二叉排序树,又叫二叉查找树:
-
若左子树为空,则
左子树
上所有结点的值均
小于
根结点的值;
若右子树为空,则
右子树上
所有结点的值均
大于等于
根结点的值;
左右子树也分别为二叉排序树。 -
中序遍历
一个二叉排序树可以得到一个
递增有序序列
。
(2)m叉排序树,又叫m路查找树:
-
一个结点最多有
m
棵子树,
m-1
个关键字; -
子树
Pi
中的所有关键字均大于
Ki
,小于
K(i+1)
; -
子树
P0
中的关键字均小于
K1
,子树
Pn
中的所有关键字均大于
Kn
; - 子树Pi也是m路查找树
-
书本P289的
例8.7
-

(3)B树,一颗
平衡
的m路查找树: -
每个结点做多有
m
棵子树; -
根结点至少有
2
棵子树; -
除根结点之外的所有非叶结点至少有
ceiling(m/2)
棵子树,
ceiling(m/2) - 1
个关键字; - 所有叶结点在同一层,也叫失败结点;
-
B树是“从叶向根”生长的,而根对每个分支是公用的,所以不论根长到多“深”,各分支的长度同步增长,
因而各分支是“平衡”的
; -
书中P289的
例8.8、8.9
,—B树的基本性质
P293的
例8.10,8.11
,—B树中插入一个关键字
P296的
例8.12,8.13
,—B树中删除一个关键字
**
B树
**有许多变种,其中最常见的是
B+Tree
,例如MySQL就普遍使用
B+Tree
实现其索引结构。那么B树和B+树区别在哪?
参考链接1:
简单剖析B树(B-Tree)与B+树
常说的B-树就是B树,没有所谓的B减树。
聚集索引(Clustered Index)、非聚集索引(NonClustered Index)、卫星数据?
B+树相比B树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少;
2.所有查询都要查找到叶子节点,查询性能稳定;
3.所有叶子节点形成有序链表,便于范围查询。
参考链接2:
B树和B+树
不同数据库引擎(MYISAM引擎和INNODB引擎)中B+树的差异:。
参考链接3:
B树与B+树简明扼要的区别
参考链接4:
面试总结:B树,B+树的原理及区别
参考链接5:
面试题:B(B-)树,B+树,B树和B+树的区别,B树和B+树的优点
参考链接6:
B树、B-树、B+树、B*树之间的关系
第二部分:MySQL索引实现:
- MyISAM索引实现
- InnoDB索引实现
第三部分:索引使用策略及优化
32’’ 补充2:数据结构教材的 第八章 查找算法
8.2 基于 线性表 的查找法
- 顺序查找法:
- 折半查找法:顺序存储、数据有序
-
分块查找法:创建一个索引表,每个索引项记录一个块的
起始位置
和块中的
最大关键字
,索引表按关键字有序排列(即块之间有序,块内无序)。先用顺序查找或折半查找
锁定块
,然后在块内用顺序查找法。

8.3 基于 树 的查找法
-
二叉排序树:(二叉查找树)
若左子树为空,则
左子树
上所有结点的值均
小于
根结点的值;
若右子树为空,则
右子树上
所有结点的值均
大于等于
根结点的值;
左右子树也分别为二叉排序树。
中序遍历
一个二叉排序树可以得到一个
递增有序序列
。 -
平衡二叉排序树:(AVL树)
左右子树的
高度之差的绝对值小于等于1
;左右子树也是平衡二叉排序树。
结点的
平衡因子
(Balance Factor)是指结点的左右子树深度之差,AVL树中所有结点的平衡因子只能是-1、0、1。
给一个AVL树上插入一个结点,可能导致树失衡,失衡类型及相应的调整方法可归纳为四种:
LL型、LR型、RR型、RL型
。
红黑树和AVL树的区别:(见下面的详解) -
B树:
见
教材的P288 – P298
,或者直接看上面的
32’ 补充1:BTree索引
补充:红黑树和AVL树的详解和区别
(参考链接:
红黑树和AVL树(平衡二叉树)区别
、
链接2
)
AVL树是严格的平衡二叉树,一旦失衡就要通过
旋转
来保持平衡,而
旋转是非常耗时的
,因此AVL树适合用于
插入与删除次数比较少,但查找比较多
的情况。由于维护这种高度平衡所付出的代价比从中获得的效率收益还大,故而
实际的应用不多
,更多的地方是用
追求局部而不是非常严格整体平衡
的
红黑树
。当然,如果应用场景中对
插入、删除不频繁
,只是
对查找要求较高
,那么AVL还是较优于红黑树。
红黑树是一种
二叉查找树
,但在每个节点增加一个存储位表示节点的颜色,可以是红或黑(
非红即黑
)。通过对任何一条从根到叶子的路径上各个节点着色的方式的限制,
红黑树确保没有一条路径会比其它路径长出两倍
,因此,红黑树是一种
弱平衡二叉树
(由于是弱平衡,可以看到,在相同的节点情况下,AVL树的高度低于红黑树),相对于要求严格的AVL树来说,
红黑树的旋转次数少
,
插入,删除,查找的复杂度都是O(log N)
,所以
对于搜索,插入,删除操作较多的情况下,就用红黑树。
。
红黑树的规则:
-
规则1: 每个节点不是黑色就是红色(
非红即黑
); -
规则2:
根节点为黑色
; -
规则3
:红色节点的父节点和子节点不能为红色;
红色结点的两儿子都是黑的
-
规则4:所有的
叶子节点都是黑色
(空节点视为叶子节点NIL); -
规则5
:
任意一个节点
到叶子节点的
每条路径上
黑色节点的个数都相等; -
规则6(特点):
从根节点到叶子节点的最长的路径不多于最短的路径的长度的两倍
。
红黑树插入节点时的思路:(参考链接:
红黑树与平衡二叉树区别?
)
插入的节点总是设为红节点,当其复节点为红节点时,这就有破坏了规则3,就需要调整。将插入节点作为考察节点,考察其叔父,如果也是红节点,则将其父亲和叔父改为黑节点,而将其祖父改为红节点,然后以其祖父为考察节点。如果其叔父是黑节点则做一旋转变换可以搞定,没有图不太好说明,你可以自己考虑一下,总之它的思想是把“多出来”的红色往上一层推去,确保下面层红黑性质,最后推到根以后,如果依然违反性质1,则可以直接把根由红改黑即可,就相当于把这“多出来”的红色推到树以外的节点去了。
删除节点时先要找到顶替的节点,如果删去的节点是黑色则破坏了规则5,也需要调整。调整的思想也同前面类似,把这个黑色赋予顶替节点,则顶替节点相当于有两重黑色,然后将它的两重黑色向上推,一直推到根,再从根推到外面去了。
平衡二叉树和红黑树的区别:
| AVL树 | 红黑树 | |
|---|---|---|
| 概念 | 严格的平衡二叉树,左右子树高度差的绝对值≤1 |
弱平衡树,见上面的: 红黑树的规则 |
| 失衡类型及相应的调整方法 |
|
见上面的 红黑树插入节点时的思路 |
| 插入、删除 | 因为要通过旋转来恢复平衡,代价高 | O(log N) |
| 查找 | O(log N) | O(log N) |
| 应用 |
适合用于插入与删除次数比较少,但查找比较多的情况 如果应用场景中对 插入、删除不频繁 ,只是 对查找要求较高 ,那么AVL还是较优于红黑树。 |
对于查找,插入,删除操作较多的情况下,就用红黑树; 广泛用于C++的STL中,map和set都是用红黑树实现的 |
| 左右自述的高度差绝对值 | 小于等于1 |
某些时刻可能会超过1,但 红黑树确保没有一条路径会比其它路径长出两倍 ,只要符合红黑树的规则即可 |
| 失衡后的具体操作 | 只要不平衡就会进行旋转 | 改变颜色+旋转 |
| 是否是高度平衡 | 是,严格的平衡二叉树 | 否,弱平衡的二叉树,插入最多两次旋转,删除最多三次旋转 |
多余的内容:(不用看)
平衡二叉树和红黑树的区别:
+ 平衡二叉树的左右子树的高度差绝对值不超过1,
但是红黑树在某些时刻可能会超过1,**红黑树确保没有一条路径会比其它路径长出两倍**,只要符合红黑树的五个条件即可;
+ 二叉树**只要不平衡就会进行旋转**,
而红黑树不符合规则时,**有些情况只用改变颜色不用旋转,就能达到平衡**;
+ AVL树适合用于**插入与删除次数比较少,但查找比较多**的情况,
对于**搜索,插入,删除操作较多的情况**下,就用**红黑树**;
+ AVL 树是**高度平衡的**,频繁的插入和删除,会引起频繁的reblance,导致效率下降,
红黑树不是高度平衡的,算是一种折中,插入最多两次旋转,删除最多三次旋转。
8.4 计算式查找法(哈希表)
八、权限管理和备份
33. 数据库用户管理
方式一:用
SQLyog可视化
管理用户
- 添加用户;
- 删除用户;
- 管理用户权限(全局权限、对某个数据库的权限、对某个数据表的权限)

方式二:用
sql命令
管理用户
(首先找到用户表,在mysql数据库–>user数据表中)
用
sql命令
对用户进行管理,实质上就是
对用户表进行增删改查
。

创建用户、修改密码、重命名、用户授权、查看权限、撤销权限、删除用户
-- 创建用户:
-- 格式:CREATE USER 用户名 IDENTIFIED BY '密码'
CREATE USER lele IDENTIFIED BY '123456'
CREATE USER 'user_name'@'192.168.1.1' IDENTIFIED BY '123456'
-- 修改密码(修改当前用户密码):当前用户是root
SET PASSWORD = PASSWORD('654321'); -- 记得把密码改回来('123456')
-- 修改密码(修改指定用户密码):
SET PASSWORD FOR lele = PASSWORD('654321'); -- 记得把密码改回来('123456')
-- 修改密码:(数据库笔记1中的两条修改密码的命令行)
UPDATE mysql.user SET authentication_string=PASSWORD('123456') WHERE USER='root' AND HOST = 'localhost';
UPDATE USER SET PASSWORD=PASSWORD('123456')WHERE USER='root'; 修改密码
-- 重命名:
-- 格式:RENAME USER 原名字 TO 新名字;
RENAME USER lele TO lele2
-- 用户授权:
-- 格式:GRANT 权限列表 ON 数据库名.数据表名 TO 用户名
-- 给 用户lele2 授予 所有的库的所有的表 全部的权限ALL PRIVILEGES,
GRANT ALL PRIVILEGES ON *.* TO lele2
-- (解释:*.* 表示所有库的所有表; 库名.表名 表示某库下面的某表
-- 这里的 ALL PRIVILEGES 是除了给别人授权不行,其他都能干,
-- 即ALL PRIVILEGES指除了GRANT权限之外的所有权限)
-- 查看权限:
-- 查看当前用户的权限:
SHOW GRANTS; 或 SHOW GRANTS FOR CURRENT_USER; 或 SHOW GRANTS FOR CURRENT_USER();
-- 查看用户lele2的权限:(除GRANT权限之外的ALL PRIVILEGES)
SHOW GRANTS FOR lele2
-- 结果:GRANT ALL PRIVILEGES ON *.* TO 'lele2'@'%'
-- 查看root的权限:(有GRANT权限,和ALL PRIVILEGES)
SHOW GRANTS FOR root@localhost
-- 结果:GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' WITH GRANT OPTION
-- 撤销权限:(和授予权限正好相反)
-- 格式:REVOKE 权限列表 ON 数据库名.数据表名 FROM 用户名
REVOKE ALL PRIVILEGES ON *.* FROM lele2 --撤销用户lele2的所有权限
-- REVOKE ALL PRIVILEGES, GRANT OPTION FROM root -- 撤销root的所有权限
-- 不建议这么干!!!
-- 删除用户:
DROP USER lele2
授予权限的结果:
授予权限之前:

授予权限之后:(
GRANT ALL PRIVILEGES ON *.* TO lele2
)

权限解释:
-- 权限列表
ALL [PRIVILEGES] -- 设置除GRANT OPTION之外的所有简单权限
ALTER -- 允许使用ALTER TABLE
ALTER ROUTINE -- 更改或取消已存储的子程序
CREATE -- 允许使用CREATE TABLE
CREATE ROUTINE -- 创建已存储的子程序
CREATE TEMPORARY TABLES -- 允许使用CREATE TEMPORARY TABLE
CREATE USER -- 允许使用CREATE USER, DROP USER, RENAME USER和REVOKE ALL PRIVILEGES。
CREATE VIEW -- 允许使用CREATE VIEW
DELETE -- 允许使用DELETE
DROP -- 允许使用DROP TABLE
EXECUTE -- 允许用户运行已存储的子程序
FILE -- 允许使用SELECT...INTO OUTFILE和LOAD DATA INFILE
INDEX -- 允许使用CREATE INDEX和DROP INDEX
INSERT -- 允许使用INSERT
LOCK TABLES -- 允许对您拥有SELECT权限的表使用LOCK TABLES
PROCESS -- 允许使用SHOW FULL PROCESSLIST
REFERENCES -- 未被实施
RELOAD -- 允许使用FLUSH
REPLICATION CLIENT -- 允许用户询问从属服务器或主服务器的地址
REPLICATION SLAVE -- 用于复制型从属服务器(从主服务器中读取二进制日志事件)
SELECT -- 允许使用SELECT
SHOW DATABASES -- 显示所有数据库
SHOW VIEW -- 允许使用SHOW CREATE VIEW
SHUTDOWN -- 允许使用mysqladmin shutdown
SUPER -- 允许使用CHANGE MASTER, KILL, PURGE MASTER LOGS和SET GLOBAL语句,mysqladmin debug命令;允许您连接(一次),即使已达到max_connections。
UPDATE -- 允许使用UPDATE
USAGE -- “无权限”的同义词
GRANT OPTION -- 允许授予权限
/* 表维护 */
-- 分析和存储表的关键字分布
ANALYZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE 表名 ...
-- 检查一个或多个表是否有错误
CHECK TABLE tbl_name [, tbl_name] ... [option] ...
option = {QUICK | FAST | MEDIUM | EXTENDED | CHANGED}
-- 整理数据文件的碎片
OPTIMIZE [LOCAL | NO_WRITE_TO_BINLOG] TABLE tbl_name [, tbl_name] ...
34. MySQL备份
为什么要备份?
- 保证重要的数据不丢失;
- 数据转移。
MySQL数据库备份方法(三种方法)
-
1.直接拷贝数据库文件和相关配置文件; –
data
文件夹(数据库笔记1中有提及) -
2.在
sqlyog
这种可视化工具中手动导出;– 可视化操作 -
3.使用命令行
mysqldump
导出 。 – 命令行
在sqlyog这种可视化工具中手动导出
在想要导出的表或者库中,右键:

注意下图中三处框起来的地方即可:

使用命令行
mysqldump
导出
mysqldump
导出:
-- 导出一张表 :
-- 格式:mysqldump -h主机 -u用户名 -p密码 数据库 表名 >物理磁盘位置/文件名
mysqldump -hlocalhost -uroot -p123456 school student >D:/a.sql
-- 导出多张表 :
-- 格式:mysqldump -h主机 -u用户名 -p密码 数据库 表名1 表名2 >物理磁盘位置/文件名
mysqldump -hlocalhost -uroot -p123456 school student result >D:/b.sql
-- 导出整个数据库 :
-- 格式:mysqldump -h主机 -u用户名 -p密码 数据库 >物理磁盘位置/文件名
mysqldump -hlocalhost -uroot -p123456 school >D:/c.sql
导入:
方式一:(推荐)
-
先
登录
; -
切换到
指定的数据库
; -
然后
source 备份文件
。
(测试的时候可以先把school库中的student表备份下来a.sql,然后把student表删掉,然后按照上面的三个步骤导入)

方式二:(不推荐)
也可以这样:
mysql -u用户名 -p密码 库名 < 备份文件(要导入的文件)

九、规范数据库设计
35. 如何设计一个项目的数据库
为什么需要设计?
当数据库比较复杂的时候
,我们就需要设计了。
糟糕的数据库设计:
- 数据冗余,浪费空间;
- 数据库插入和删除都会麻烦、异常(屏蔽使用物理外键);
- 程序的性能差。
良好的数据库设计:
- 节省内存空间;
- 保证数据库的完整性;
- 方便我们开发系统。
软件项目开发周期中数据库设计:
- 需求分析阶段: 分析客户的业务和数据处理需求
- 概要设计阶段:设计数据库的E-R模型图 , 确认需求信息的正确和完整.
设计数据库步骤:(个人博客)
第1步:
收集信息
(与该系统有关人员进行交流 , 座谈 , 充分了解用户需求 , 理解数据库需要完成的任务)
- 用户表(用户登录注销,用户的个人信息,写博客,创建分类)
- 分类表(文章分类,谁创建的)
- 文章表(文章信息)
- 评论表
- 友链表(友情链接信息)
- 自定义表(系统信息,某个关键的字,或者一些主字段) key:value
- 关注表(粉丝数)
- 说说表(发表心情,字段: id…content…create_time)
第2步:
标识实体
[Entity]
(把需求落地到每个字段,数据库要管理的关键对象或实体,实体一般是名词,标识每个实体需要存储的详细信息[Attribute])
-
用户表:

-
分类表:

-
文章表:

-
评论表:

- 友链表:

-
关注表:

第3步:
标识实体之间的关系
[Relationship]
- 写博客:user –> blog
- 创建分类:user –> category
- 关注:user –> user
- 友链:links
- 评论:user –> user –> blog
博客,bbs,Ant Design
36.数据库的三大范式(了解)
问题 : 为什么需要数据规范化?
不合规范的表设计会导致的问题:
- 信息重复;
- 更新异常;
- 插入异常:无法正确表示信息;
- 删除异常:丢失有效信息。
三大范式:
第一范式 (1st NF):
-
原子性:保证
每一列不可再分
;
第二范式(2nd NF):
- 前提:满足第一范式
-
每张表只描述一件事情
;
第三范式(3rd NF):
- 前提:满足第一范式和第二范式
-
第三范式需要确保数据表中的每一列数据都
和主键直接相关,而不能间接相关
。
三大范式是用来规范数据库的设计,但存在规范性和性能的问题(不可兼得的关系):
(阿里有句话:
关联查询的表不得超过三张表
)
-
考虑
商业化的需求和目标
(成本,用户体验)时,数据库的
性能更加重要
; -
在规范性能的问题的时候,需要
综合考虑
一下规范性; -
有时会故意给某些表增加一些
冗余的字段
(从多表查询中变为单表查询),以大量减少需要从中搜索信息所需的时间; -
有时会故意增加一些
计算列
(从大数据库降低为小数据量的查询:索引)。
十、JDBC(重点)
37. 数据库驱动 和 JDBC
1.数据库驱动
驱动:声卡、显卡、数据库
应用程序
通过
数据库驱动
和
数据库
打交道。

2.JDBC
UN公司为了简化开发人员的(对数据库的统一)操作,提供了一个(java操作数据库的)规范,俗称
JDBC
。
这些规范的实现由具体的厂商去做~
对于开发人员来说,我们
只需要掌握JDBC接口的操作
即可!

38-44

45. 数据库连接池
数据库连接 – 执行完毕 – 释放
整个过程中
连接– 释放
是十分浪费系统资源的,所以就有了
池化技术
:准备一些预先的资源,过来就连接预先准备好的。
最小连接数
:10(常用连接数)
最大连接数
:100 (业务最高承载上线)
等待超时
:100ms(等待超过100ms就会告诉客户这里发生异常,让客户找别家)
编写连接池,实现一个接口DataSource。
总结:无论用什么数据源,本质还是一样的,DataSource接口不会变,方法就不会变。
(数据库的课先学到这,2022-04-15 21:44:26)