一个域名可以解析成多个ip地址,一般来说会轮询方式去解析成各个ip,但是如果其中一个服务器挂了,DNS不会立马将这个ip地址去掉,还是会解析成挂掉的ip,可能会造成访问失败。虽然客户端有重试,但还是会影响用户体验。
在应用web前加反向代理,安全性也会高一点。
正向代理:代理客户机
反向代理:代理服务器
反向代理机:使用keepalived双vip(虚拟ip)互为主备做高可用 www.xx.com 解析成两个虚拟ip
如何测试?
可以直接访问nginx web,也可以绑定域名访问
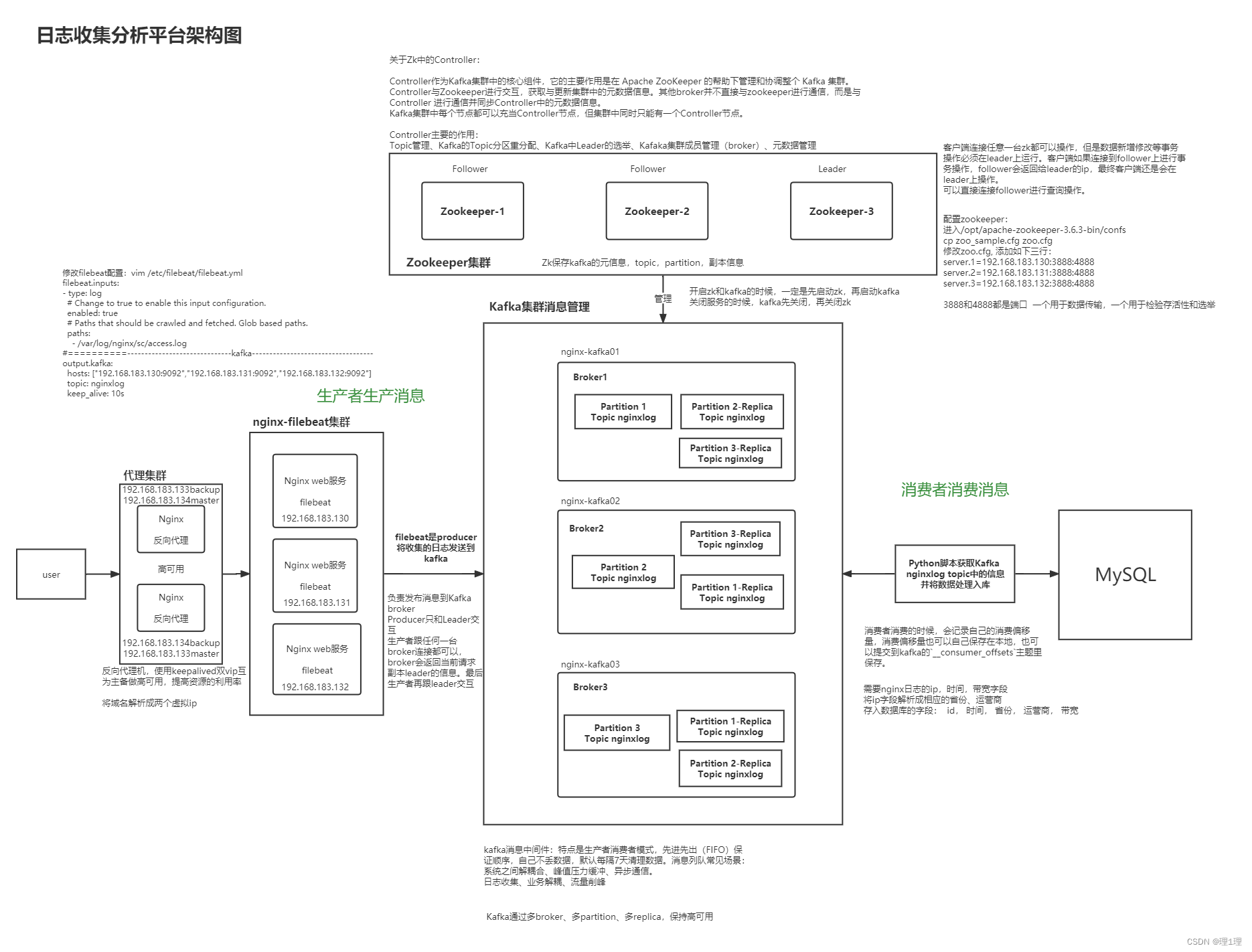
基于Kafka-Zookeeper-Nginx-FIlebeat-MySQL的日志清洗分析平台搭建
0. 分布式与集群的区别是什么?
太多的说法是
分布式
是不同的人做不同的事,
集群
是多个人做同一件事的说法了。
这太误导人了。
比如
zookeeper
,3台机器的一个
集群
。
从
系统应用
来看
zookeeper
,他就是
集群
,因为他为我提供了一样的服务。
但是这个
集群内部
,主从之间又有不同的分工,
主负责写
,
从负责读
,主从之间又要通过长连接来同步数据副本,这样看,他又是个
分布式系统
了。
redis
也是,
kafka
也是…
其实分布式不一定就是不同的组件,同一个组件也可以,关键在于
是否通过交换信息的方式进行协作
。比如说
Zookeeper
的节点都是对等的,但它自己就构成一个
分布式系统
。
也就是说,
分布式
是指通过网络连接的
多个组件
,通过
交换信息协作
1. 环境准备:
-
准备好3台虚拟机搭建nginx和kafka集群
1C2G的配置即可
配置三台nginx服务器的原因:负载均衡
用户的流量过来了,按照调度的策略将他们调度分散到后端的web服务器上。
-
配置好静态ip地址、网关、dns
vim /etc/sysconfig/network-scripts/ifcfg-ens33
# 修改的几项配置 # 三台都需要修改 BOOTPROTO="static" IPADDR=192.168.183.130 GATEWAY=192.168.183.2 DNS1=114.114.114.114
[root@nginx-kafka03 ~]# cat /etc/resolv.conf
# Generated by NetworkManager
nameserver 114.114.114.114
dns解析:
1、浏览器的缓存
2、本地hosts文件 –linux(/etc/hosts)
3、找本地域名服务器 – linux(/etc/resolv.conf)
至此以上需要重启一下网络服务
服务:常驻系统内存中的进程且可以提供一些系统和网络功能
现在最新的Linux系统都统一使用systemctl进行服务的管理
服务:NetworkManager (推荐)或者 network 只运行一个
启动/停止/重启:
systemctl start/stop/restart NetworkManager
systemctl管理的服务,配置文件在
/usr/lib/systemd/system
下,以
.service
结尾的配置文件
-
修改主机名
目的:方便映射
vim /etc/hosthname
# nginx-kafka01/02/03
hostname -F /etc/hostname
-
每一台机器上都写好域名解析
这个文件的作用就是提供ip和主机名的对照作用,linux通过这个文件知道某个ip对应于某个主机名
vim /etc/hosts 192.168.0.94 nginx-kafka01 192.168.0.95 nginx-kafka02 192.168.0.96 nginx-kafka03 -
安装基本软件
yum install wget lsof vim -y
- 安装时间同步服务
yum -y install chrony
systemctl enable chronyd
systemctl start chronyd
设置时区:
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
- 关闭防火墙
[root@nginx-kafka01 ~]# systemctl stop firewalld
[root@nginx-kafka01 ~]# systemctl disable firewalld
-
关闭selinux:
vim /etc/selinux/config SELINUX=disabled
selinux关闭 需要重启机器
2. nginx配置文件
2.1 配置的含义
[root@nginx-kafka01 ~]# cd /etc/nginx/
[root@nginx-kafka01 nginx]# ls
conf.d fastcgi.conf.default koi-utf mime.types.default scgi_params uwsgi_params.default
default.d fastcgi_params koi-win nginx.conf scgi_params.default win-utf
fastcgi.conf fastcgi_params.default mime.types nginx.conf.default uwsgi_params
主配置文件: nginx.conf
... #全局块
events { #events块
...
}
http #http块
{
... #http全局块
server #server块,一个网站一个server,server块写在http块里面
{
... #server全局块
location [PATTERN] #location块
{
...
}
location [PATTERN]
{
...
}
}
server
{
...
}
... #http全局块
}
- 全局块:配置影响nginx全局的指令。一般有运行nginx服务器的用户组,nginx进程pid存放路径,日志存放路径,配置文件引入,允许生成worker process数等。
- events块:配置影响nginx服务器或与用户的网络连接。有每个进程的最大连接数,选取哪种事件驱动模型处理连接请求,是否允许同时接受多个网路连接,开启多个网络连接序列化等。
- http块:可以嵌套多个server,配置代理,缓存,日志定义等绝大多数功能和第三方模块的配置。如文件引入,mime-type定义,日志自定义,是否使用sendfile传输文件,连接超时时间,单连接请求数等。
- server块:配置虚拟主机的相关参数,一个http中可以有多个server。
- location块:配置请求的路由,以及各种页面的处理情况
2.2 配置文件修改
nginx 的 default_server 指令可以定义默认的 server 去处理一些没有匹配到 server_name 的请求,如果没有显式定义,则会选取第一个定义的 server 作为 default_server。
-
vim nginx.conf
将
listen 80 default_server;
修改成:
listen 80;
-
vim /etc/nginx/conf.d/sc.conf
server {
# 没有指定域名就交给默认的服务器去访问
listen 80 default_server;
# 配置访问域名
server_name www.sc.com;
root /usr/share/nginx/html;
access_log /var/log/nginx/sc/access.log main;
location / {
}
}
2.3 语法检测
[root@nginx-kafka01 html]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: [emerg] open() "/var/log/nginx/sc/access.log" failed (2: No such file or directory)
nginx: configuration file /etc/nginx/nginx.conf test failed
# 日志文件地址中的文件夹不存在,新建一下即可
[root@nginx-kafka01 html]# mkdir /var/log/nginx/sc
[root@nginx-kafka01 html]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
2.4 重新加载nginx
nginx -s reload
3. kafka
3.0 简介
解释一下消息中间件:
消息队列是分布式系统中重要的
中间件
,在实现系统高性能,高可用,可伸缩性和最终一致性架构框架中扮演着重要角色。是大型分布式系统不可缺少的核心中间件之一。
kafka消息中间件:
kafka是一个高吞吐的
分布式
消息队列系统。特点是生产者消费者模式,先进先出(FIFO)保证顺序,自己不丢数据,默认每隔7天清理数据。消息列队常见场景:系统之间解耦合、峰值压力缓冲、异步通信。
日志收集、业务解耦、流量削峰
业务解耦:
允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
缓冲/削峰
:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
异步通信
:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
3.1 基础架构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-264HPhN0-1659510820076)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220715162535843.png)]
3.2 基本概念
-
Broker
: 和AMQP里协议的概念一样, 就是消息中间件所在的服务器 -
Topic
(主题) : 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处) -
Partition
(分区) : Partition是物理上的概念,体现在磁盘上面。分区,为了实现扩展性,一个非常大的Topic可以分布到多个Broker上,一个Topic可以分为多个Partition,每个Partition是一个有序的队列(分区有序,不能保证全局有序,即如果需要全局有序的话不建议建立多个partition)一般有几个broker就设置为几个partition
-
Producer
: 负责发布消息到Kafka broker -
Consumer
: 消息消费者,向Kafka broker读取消息的客户端。 -
Consumer Group
(消费者群组) : 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。 -
Replica
:副本Replication,为保证集群中某个节点发生故障,节点上的Partition数据不丢失,Kafka可以正常的工作,Kafka提供了副本机制,一个Topic的每个分区有若干个副本,一个Leader和多个Follower -
Leader
:每个Partition分区多个副本的主角色,生产者发送数据的对象,以及消费者消费数据的对象都是Leader。 -
Follower
:每个分区多个副本的从角色,实时的从Leader中同步数据,保持和Leader数据的同步,Leader发生故障的时候,某个Follower会成为新的Leader。 -
offset
偏移量: 是kafka用来确定消息是否被消费过的标识,在kafka内部体现就是一个递增的数字注意:从kafka-0.9版本及以后,kafka的消费者组和offset信息就不存zookeeper了,而是存到broker服务器上,所以,如果你为某个消费者指定了一个消费者组名称(group.id),那么,一旦这个消费者启动,这个消费者组名和它要消费的那个topic的offset信息就会被记录在broker服务器上 Kafka版本[0.10.1.1],已默认将消费的 offset 迁入到了 Kafka 一个名为 __consumer_offsets 的Topic中。其实,早在 0.8.2.2 版本,已支持存入消费的 offset 到Topic中,只是那时候默认是将消费的 offset 存放在 Zookeeper 集群中。那现在,官方默认将消费的offset存储在 Kafka 的Topic中,同时,也保留了存储在 Zookeeper 的接口,通过 offsets.storage 属性来进行设置。 在新版 Kafka 以及之后的版本,Kafka 消费的offset都会默认存放在 Kafka 集群中的一个叫 __consumer_offsets 的topic中。 可以运行zookeeper看到消费者消费的时候,会记录自己的消费偏移量,消费偏移量也可以自己保存在本地,也可以提交到kafka的
__consumer_offsets
主题里保存。[root@nginx-kafka03 config]# cd /data [root@nginx-kafka03 data]# ls cleaner-offset-checkpoint __consumer_offsets-43 __consumer_offsets-1 __consumer_offsets-46 __consumer_offsets-10 __consumer_offsets-49 __consumer_offsets-13 __consumer_offsets-7 __consumer_offsets-16 log-start-offset-checkpoint __consumer_offsets-19 meta.properties __consumer_offsets-22 nginxlog-0 __consumer_offsets-25 nginxlog-1 __consumer_offsets-28 nginxlog-2 __consumer_offsets-31 recovery-point-offset-checkpoint __consumer_offsets-34 replication-offset-checkpoint __consumer_offsets-37 sc-0 __consumer_offsets-4 sc-1 __consumer_offsets-40 sc-2 [root@nginx-kafka03 data]#关于offset的提交具体参考:https://blog.csdn.net/u011066470/article/details/124090576
多broker、多partition、多replica,保持高可用
3.3 kafka消费模式
Kafka的消费模式主要有两种:一种是一对一的消费,也即
点对点
的通信,即一个发送一个接收。第二种为一对多的消费,即一个消息发送到消息队列,消费者根据消息队列的
订阅
拉取消息消费。
-
一对一
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XFQvxtBe-1659510820077)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220715162805118.png)]
消息生产者发布消息到Queue队列中,通知消费者从队列中拉取消息进行消费。消息被消费之后则删除,Queue支持多个消费者,但对于一条消息而言,只有一个消费者可以消费,即一条消息只能被一个消费者消费。
-
一对多
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u3h0KUF0-1659510820077)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220715162817154.png)]
这种模式也称为
发布/订阅
模式,即利用Topic存储消息,消息生产者将消息发布到Topic中,同时有多个消费者订阅此topic,消费者可以从中消费消息,注意发布到Topic中的消息会被多个消费者消费,消费者消费数据之后,数据不会被清除,Kafka会默认保留一段时间,然后再删除。
生产者跟任何一台broker连接都可以,broker会返回当前请求副本leader的信息。最后生产者再跟leader交互
3.4 kafka数据可靠性的实现
Producer 往 Broker 发送消息
如果我们要往 Kafka 对应的主题发送消息,我们需要通过 Producer 完成。前面我们讲过 Kafka 主题对应了多个分区,每个分区下面又对应了多个副本;为了让用户设置数据可靠性, Kafka 在 Producer 里面提供了消息确认机制。也就是说我们可以通过配置来决定有几个副本收到这条消息才算消息发送成功。可以在定义 Producer 时通过
acks
参数指定(在 0.8.2.X 版本之前是通过
request.required.acks
参数设置的,详见
KAFKA-3043
)。这个参数支持以下三种值:
-
acks=0:生产者不会等待任何来自服务器的响应。
如果当中出现问题,导致服务器没有收到消息,那么生产者无从得知,会造成消息丢失
由于生产者不需要等待服务器的响应所以可以以网络能够支持的最大速度发送消息,从而达到很高的吞吐量
-
acks=1(默认值):只要集群的Leader节点收到消息,生产者就会收到一个来自服务器的成功响应
如果消息无法到达Leader节点(例如Leader节点崩溃,新的Leader节点还没有被选举出来)生产者就会收到一个错误响应,为了避免数据丢失,生产者会重发消息
如果一个没有收到消息的节点成为新Leader,消息还是会丢失
此时的吞吐量主要取决于使用的是同步发送还是异步发送,吞吐量还受到发送中消息数量的限制,例如生产者在收到服务器响应之前可以发送多少个消息
-
acks=-1:只有当所有参与复制的节点全部都收到消息时,生产者才会收到一个来自服务器的成功响应
这种模式是最安全的,可以保证不止一个服务器收到消息,就算有服务器发生崩溃,整个集群依然可以运行
延时比acks=1更高,因为要等待不止一个服务器节点接收消息
根据实际的应用场景,我们设置不同的
acks
,以此保证数据的可靠性。
另外,Producer 发送消息还可以选择同步(默认,通过
producer.type=sync
配置) 或者异步(
producer.type=async
)模式。如果设置成异步,虽然会极大的提高消息发送的性能,但是这样会增加丢失数据的风险。如果需要确保消息的可靠性,必须将
producer.type
设置为 sync。
Topic 分区副本
在 Kafka 0.8.0 之前,Kafka 是没有副本的概念的,那时候人们只会用 Kafka 存储一些不重要的数据,因为没有副本,数据很可能会丢失。但是随着业务的发展,支持副本的功能越来越强烈,所以为了保证数据的可靠性,Kafka 从 0.8.0 版本开始引入了分区副本(详情请参见
KAFKA-50
)。也就是说每个分区可以人为的配置几个副本(比如创建主题的时候指定
replication-factor
,也可以在 Broker 级别进行配置
default.replication.factor
),一般会设置为3。
Kafka 可以保证单个分区里的事件是有序的,分区可以在线(可用),也可以离线(不可用)。在众多的分区副本里面有一个副本是 Leader,其余的副本是 follower,所有的读写操作都是经过 Leader 进行的,同时 follower 会定期地去 leader 上复制数据。当 Leader 挂掉之后,其中一个 follower 会重新成为新的 Leader。通过分区副本,引入了数据冗余,同时也提供了 Kafka 的数据可靠性。
Kafka 的分区多副本架构是 Kafka 可靠性保证的核心,把消息写入多个副本可以使 Kafka 在发生崩溃时仍能保证消息的持久性。
Leader 选举
在介绍 Leader 选举之前,让我们先来了解一下 ISR(in-sync replicas)列表。每个分区的 leader 会维护一个 ISR 列表,ISR 列表里面就是 follower 副本的 Borker 编号,只有“跟得上” Leader 的 follower 副本才能加入到 ISR 里面,这个是通过
replica.lag.time.max.ms
参数配置的。只有 ISR 里的成员才有被选为 leader 的可能。
1.什么是ISR?
分区中的所有副本统称为AR(Assigned Replicas)。所有与leader副本保持一定程度同步的副本(包括leader)组成ISR(in-sync replicas)。而与leader副本同步滞后过多的副本(不包括leader),组成OSR(out-sync replicas),所以,AR = ISR + OSR。在正常情况下,所有的follower副本都应该与leader副本保持一定程度的同步,即AR = ISR,OSR集合为空。
如果一个follower卡住或者同步过慢,也会从ISR中删除
如果一个机器宕机,后续启动之后想要重新加入ISR,必须同步到HW(最高水位线)值
所以当 Leader 挂掉了,而且
unclean.leader.election.enable=false
的情况下,Kafka 会从 ISR 列表中选择第一个 follower 作为新的 Leader,因为这个分区拥有最新的已经 committed 的消息。通过这个可以保证已经 committed 的消息的数据可靠性。
综上所述,为了保证数据的可靠性,我们最少需要配置一下几个参数:
- producer 级别:acks=all(或者 request.required.acks=-1),同时发生模式为同步 producer.type=sync
- topic 级别:设置 replication.factor>=3,并且 min.insync.replicas>=2;
- broker 级别:关闭不完全的 Leader 选举,即 unclean.leader.election.enable=false;
3.5 kafka如何保证数据一致性
这里介绍的数据一致性主要是说不论是老的 Leader 还是新选举的 Leader,Consumer 都能读到一样的数据。那么 Kafka 是如何实现的呢?
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qLl5D3U7-1659510820078)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220715171540374.png)]
假设分区的副本为3,其中副本0是 Leader,副本1和副本2是 follower,并且在 ISR 列表里面。虽然副本0已经写入了 Message3,但是 Consumer 只能读取到 Message1。因为所有的 ISR 都同步了 Message1,只有 High Water Mark 以上的消息才支持 Consumer 读取,而 High Water Mark 取决于 ISR 列表里面偏移量最小的分区,对应于上图的副本2,这个很类似于木桶原理。
这样做的原因是还没有被足够多副本复制的消息被认为是“不安全”的,如果 Leader 发生崩溃,另一个副本成为新 Leader,那么这些消息很可能丢失了。如果我们允许消费者读取这些消息,可能就会破坏一致性。试想,一个消费者从当前 Leader(副本0) 读取并处理了 Message4,这个时候 Leader 挂掉了,选举了副本1为新的 Leader,这时候另一个消费者再去从新的 Leader 读取消息,发现这个消息其实并不存在,这就导致了数据不一致性问题。
当然,引入了 High Water Mark 机制,会导致 Broker 间的消息复制因为某些原因变慢,那么消息到达消费者的时间也会随之变长(因为我们会先等待消息复制完毕)。延迟时间可以通过参数
replica.lag.time.max.ms
参数配置,它指定了副本在复制消息时可被允许的最大延迟时间。
参考博客:https://www.cnblogs.com/yoke/p/11477167.html
使用kafka做日志统一收集:
- 故障发生时方便定位问题
- 日志集中管理,后续需要日志的程序直接从kafka获取日志即可。尽可能地减少日志处理对nginx的影响
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6ZxCJec8-1659510820078)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220715151143992.png)]
4. kafka配置
4.1 安装与配置
切换到/opt目录,将下载的包放置到该目录下
-
安装:
-
安装java:
yum install java wget -y
-
安装kafka:
wget https://mirrors.bfsu.edu.cn/apache/kafka/2.8.1/kafka_2.12-2.8.1.tgz
-
解包:
tar xf kafka_2.12-2.8.1.tgz
-
使用自带的zookeeper集群配置
安装zookeeper:
wget https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.6.3/apache-zookeeper-3.6.3-bin.tar.gz
-
安装java:
-
配置kafka
修改
opt/kafka_2.12-2.8.1/config/server.properties
broker.id=1
listeners=PLAINTEXT://nginx-kafka01:9092
zookeeper.connect=192.168.183.130:2181,192.168.183.131:2181,192.168.183.132:2181
三台机器每台的broker.id分别修改为1、2、3
listeners=PLAINTEXT://nginx-kafka01/02/03:9092(根据本机的主机名来)
zookeeper.connect=192.168.183.130:2181,192.168.183.131:2181,192.168.183.132:2181(每台机器都一样)
-
配置zk
进入
/opt/apache-zookeeper-3.6.3-bin/confs
cp zoo_sample.cfg zoo.cfg
修改
zoo.cfg
, 添加如下三行:server.1=192.168.183.130:3888:4888 server.2=192.168.183.131:3888:4888 server.3=192.168.183.132:3888:4888
3888和4888都是端口 一个用于数据传输,一个用于检验存活性和选举
创建/tmp/zookeeper目录 ,在目录中添加myid文件,文件内容就是本机指定的zookeeper id内容
如:在192.168.183.130机器上
echo 1 > /tmp/zookeeper/myid
启动zookeeper:
bin/zkServer.sh start
开启zk和kafka的时候,一定是先启动zk,再启动kafka
关闭服务的时候,kafka先关闭,再关闭zk
4.2 查看
[root@nginx-kafka03 apache-zookeeper-3.6.3-bin]# bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /opt/apache-zookeeper-3.6.3-bin/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
启动kafka:
bin/kafka-server-start.sh -daemon config/server.properties
zookeeper使用:
在zookeeper文件夹下运行
bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 1] ls /
[admin, brokers, cluster, config, consumers, controller, controller_epoch, feature, isr_change_notification, latest_producer_id_block, log_dir_event_notification, sc, zookeeper]
[zk: localhost:2181(CONNECTED) 2] ls /brokers/ids
[1, 2, 3]
[zk: localhost:2181(CONNECTED) 3] create /sc/yy
Created /sc/yy
[zk: localhost:2181(CONNECTED) 4] ls /sc
[page, xx, yy]
[zk: localhost:2181(CONNECTED) 5] set /sc/yy 90
[zk: localhost:2181(CONNECTED) 6] get /sc/yy
90
4.3 测试
-
进入kafka目录的bin目录下,创建topic
./kafka-topics.sh --create --zookeeper 192.168.183.130:2181 --replication-factor 3 --partitions 3 --topic sc
-
查看topic
bin/kafka-topics.sh --list --zookeeper 192.168.183.130:2181
- 创建生产者
[root@localhost kafka_2.12-2.8.0]# bin/kafka-console-producer.sh --broker-list 192.168.183.130:9092 --topic sc
>hello
>sanchuang tongle
>nihao
>world !!!!!!
-
创建消费者
[root@localhost kafka_2.12-2.8.0]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.183.130:9092 --topic sc --from-beginning
Producer:
生产者负责获取数据并将数据上传到Kafka的,比如flume、logstash
生产者往往是监控一个或多个目录(文件)将数据对接到Kafka
生产者集群是由多个进程组成,一个生产者可以作为一个独立的进程,一个生产者就具有生产并发送的功能
多个生产者发送的数据可以发送到同一个topic中的
一个生产者可以将数据发送到多个topic中
Consumer Group:
消费者负责拉取数据,比如:Streaming、Storm、Flink
一个消费者组里可以有多个消费者
一个消费者对应的一个线程
新增或减少ConsumerGroup的Consumer数量是会触发Kafka集群的负载均衡,负载均衡的目的是尽量的将消费者均衡到每一个节点当中
Consumer可以消费多个分区的数据,一个分区的数据只能在同一时刻被一个Consumer来消费
在一个消费者组中,同一个分区的数据不可以重复消费,如果想
重复消费可以更改组名
或部署一个Kafka镜像集群
消费者组的优势
-
高性能
假设一个主题有10个分区,如果没有消费者组,只有一个消费者对这10个分区消费,他的压力肯定大。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dqxftNy5-1659510820079)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220725145756955.png)]
如果有了消费者组,组内的成员就可以分担这10个分区的压力,提高消费性能。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RUspZdPO-1659510820080)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220725145748692.png)]
-
消费模式灵活
假设有4个消费者订阅一个主题,不同的组合方式就可以形成不同的消费模式。
数据的存储目录:
文件夹:<topic_name>-<分区号>
每一个partition的数据都是由很多个segment存储,每一个segment都是由一个index和log文件组成。
kafka的日志可以按照两个维度来设置清除:
- 按时间 7天
- 按大小
分出多个segment是为了便于做数据清理。
任意一个按时间或者按大小的条件满足,都可以触发日志清理
可以在kafka的配置里查看/更改设置
kafka日志保存时按段保存的,segment
假设有如下segment
00.log 11.log 22.log00.log保存的是第一条到11条的日志
11.log保存的是第12条到第22条的日志
22.log保存的是第22条之后的日志
5. filebeat
关于ELK(Elastic Stack)
为什么需要?
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
- prospector: 负责找到所有需要进行读取的数据源
- harvesters:负责读取单个文件的内容,并将内容发送到output中,负责文件的打开和关闭。
在Filebaet运行过程中,每个Prospector的状态信息都会保存在内存里。如果Filebeat出行了重启,完成重启之后,会从注册表文件里恢复重启之前的状态信息,让FIlebeat继续从之前已知的位置开始进行数据读取。
filebeat是什么
Filebeat是用于转发和集中日志数据的轻量级传送工具。Filebeat监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或 Logstash进行索引。
Filebeat的工作方式如下:启动Filebeat时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于Filebeat所找到的每个日志,Filebeat都会启动收集器。每个收集器都读取单个日志以获取新内容,并将新日志数据发送到filebeat,filebeat将聚集事件,并将聚集的数据发送到为Filebeat配置的输出。
工作的流程图如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-59kgs6Jh-1659510820081)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220716161430268.png)]
详细信息:https://zhuanlan.zhihu.com/p/72912085?utm_medium=social&utm_oi=29440776077312
5.1 部署filebeat
-
rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
-
编辑
vim /etc/yum.repos.d/fb.repo
[elastic-7.x] name=Elastic repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md -
yum安装
yum install filebeat -y
rpm -qa |grep filebeat
可以查看filebeat有没有安装 rpm -qa 是查看机器上安装的所有软件包
rpm -ql filebeat 查看filebeat安装到哪里去了,牵扯的文件有哪些
-
设置开机自启
systemctl enable filebeat
#ymal格式
{
"filebeat.inputs": [
{ "type":"log",
"enabled":true,
"paths":["/var/log/nginx/sc_access"]
},
],
}
#配置
- 备份
cp /etc/filebeat/filebeat.yml /etc/filebeat/filebeat.yml.bak
-
清空filebeat.yml文件
-
修改配置文件
/etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/nginx/sc/access.log
#==========------------------------------kafka-----------------------------------
output.kafka:
hosts: ["192.168.183.130:9092","192.168.183.131:9092","192.168.183.132:9092"]
topic: nginxlog
keep_alive: 10s
- 创建主题nginxlog
bin/kafka-topics.sh --create --zookeeper 192.168.183.130:2181 --replication-factor 3 --partitions 3 --topic nginxlog
- 启动服务:
systemctl start filebeat
5.2 一点坑
配置filebeat.yml文件时,只能有一个输出
6. zookeeper
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
Zookeeper从
设计模式
的角度来理解:是一个基于
观察者模式
的
分布式
服务管理框架,它
负责存储和管理重要的数据
,然后接受观察者的注册,一旦这些
被观察的数据状态发生变化
,Zookeeper就负责
通知
已经在Zookeeper上注册的那些观察者让他们做出相应的反应。
为什么kafka依赖zookeeper:
需要要消费者知道现在哪些生产者(对于消费者而言,kafka就是生产者)是可用的。
如果没了zk消费者如何知道呢?如果每次消费者在消费之前都去尝试连接生产者测试下是否连接成功,效率就太低。
6.1 zk的角色(leader和follower)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VbYLsPy7-1659510820082)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220719101045603.png)]
对于zk,leader和follower的概念是针对于节点的,而kafka的leader和follower是针对partition的
【1】Zookeeper是存在一个领导者(Leader)和多个跟随者(Follower) 组成的集群。
【2】集群中若存在半数以上的(服务器存活数量必须大于一半,小于等于一半都不行)节点存活,就能正常工作。
【3】数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪一个Server获取的数据都是一样的。
【4】更新请求按发送的顺序依次执行。
【5】数据更新原子性原则,要么一次更新成功,要么失败。
【6】实时性,Client能够读取到最新的数据。
————————————————
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bze8liAy-1659510820083)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220719101315471.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ab2pa0TC-1659510820083)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220719101330470.png)]
6.2
Zookeeper的选举机制
-
半数机制:集群中半数以上的机器存活,集群就可以正常工作,所以Zookeeper适合安装
奇数台服务器
。数据的同步也是,只要过半节点同步完成,就表示数据已经commit
zookeeper不是强一致性
-
ZooKeeper虽然在配置中没有指定Master和Slave,但是Zookeeper在工作时会有一个节点成为Leader,其他的则为Follower,Leader是通过内部的选举机制临时产生的。
下面场景模拟内部的选举机制:假设有五台服务器,他们的ID分别是1-5。首先从ID为1开始,它进行投票,选择一台服务器为Leader,但是ID为1的服务器是会把这一票投给自己的,所以ID为1的票数为1,但是Leader只有票数超过总数的一半的时候才会产生(这里是总数是五台,其满足大于等于3就可以产生Leader)。所以轮到ID为2的服务器进行投票,当然ID为2的服务器是投自己的,所以ID为2的服务器票数为1,而这个时候ID为1的服务器就把自己的那一票投给ID为2的服务器(ID为1的服务器良心发现),所以这个时候ID为2的服务器票数为2,当然还没有满足票数大于总数的一半(这个场景票数为3才可以当Leader)。轮到ID为3的服务器开始投票,当然它也是自己投给自己,然后ID为1和ID为2的服务器也把自己的票投给ID为3的服务器,所以ID为3的服务器票数为3,满足票数大于总数的一半,ID为3的服务器变为Leader,而ID为4和ID为5没办法,只能乖乖被ID为3的服务器领导了。
图解如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5ZsZ4XOU-1659510820084)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220719101915039.png)]
客户端连接任意一台zk都可以操作,但是数据新增修改等事务操作必须在leader上运行。客户端如果连接到follower上进行事务操作,follower会返回给leader的ip,最终客户端还是会在leader上操作。
可以直接连接follower进行查询操作。
参考博客:https://blog.csdn.net/fenglongmiao/article/details/79305010
6.3 zk在kafka中作用
-
保存kafka的元信息,topic,partition,副本信息
元信息/元数据的内容
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Y07bt99B-1659510820084)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220719110749857.png)]
-
选举kafka controller,通过抢占的方式来选出controller,选举出来的kafka controller管理kafka中follower同步,选举
6.4 什么是Controller
Controller作为Kafka集群中的核心组件,它的主要作用是在 Apache ZooKeeper 的帮助下管理和协调整个 Kafka 集群。
Controller与Zookeeper进行交互,获取与更新集群中的元数据信息。其他broker并不直接与zookeeper进行通信,而是与 Controller 进行通信并同步Controller中的元数据信息。
Kafka集群中每个节点都可以充当Controller节点,但集群中同时只能有一个Controller节点。
每台 Broker 都有充当控制器的可能性。那么,控制器是如何被选出来的呢?当集群启动后,Kafka 怎么确认控制器位于哪台 Broker 呢?
实际上,Broker 在启动时,会尝试去 ZooKeeper 中创建 /controller 节点。Kafka 当前选举控制器的规则是:第一个成功创建 /controller 节点的 Broker 会被指定为控制器。
进入zk查看controller
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FsuNpOZP-1659510820085)(C:\Users\15764\AppData\Roaming\Typora\typora-user-images\image-20220719110437368.png)]
6.5 Controller主要作用
-
主题管理:
创建、删除Topic,以及增加Topic分区等操作都是由控制器执行。 -
分区重分配:
执行Kafka的reassign脚本对Topic分区重分配的操作,也是由控制器实现。
如果集群中有一个Broker异常退出,控制器会检查这个broker是否有分区的副本leader,如果有那么这个分区就需要一个新的leader,此时控制器就会去遍历其他副本,决定哪一个成为新的leader,同时更新分区的ISR集合。
如果有一个Broker加入集群中,那么控制器就会通过Broker ID去判断新加入的Broker中是否含有现有分区的副本,如果有,就会从分区副本中去同步数据。 -
Preferred leader选举:
因为在Kafka集群长时间运行中,broker的宕机或崩溃是不可避免的,leader就会发生转移,即使broker重新回来,也不会是leader了。在众多leader的转移过程中,就会产生leader不均衡现象,可能一小部分broker上有大量的leader,影响了整个集群的性能,所以就需要把leader调整回最初的broker上,这就需要Preferred leader选举。 -
集群成员管理:
控制器能够监控新broker的增加,broker的主动关闭与被动宕机,进而做其他工作。这也是利用Zookeeper的ZNode模型和Watcher机制,控制器会监听Zookeeper中/brokers/ids下临时节点的变化。同时对broker中的leader节点进行调整。比如,控制器组件会利用 Watch 机制检查 ZooKeeper 的 /brokers/ids 节点下的子节点数量变更。目前,当有新 Broker 启动后,它会在 /brokers 下创建专属的 znode 节点。一旦创建完毕,ZooKeeper 会通过 Watch 机制将消息通知推送给控制器,这样,控制器就能自动地感知到这个变化,进而开启后续的新增 Broker 作业。
侦测 Broker 存活性则是依赖于刚刚提到的另一个机制:临时节点。每个 Broker 启动后,会在 /brokers/ids 下创建一个临时 znode。当 Broker 宕机或主动关闭后,该 Broker 与 ZooKeeper 的会话结束,这个 znode 会被自动删除。同理,ZooKeeper 的 Watch 机制将这一变更推送给控制器,这样控制器就能知道有 Broker 关闭或宕机了,从而进行“善后”。
-
元数据服务:
控制器上保存了最全的集群元数据信息,其他所有broker会定期接收控制器发来的元数据更新请求,从而更新其内存中的缓存数据。
7. 编写python脚本收集信息入库
import json
import requests
import time
taobao_url = "https://ip.taobao.com/outGetIpInfo?accessKey=alibaba-inc&ip="
#查询ip地址的信息(省份和运营商isp),通过taobao网的接口
def resolv_ip(ip):
response = requests.get(taobao_url+ip)
if response.status_code == 200:
tmp_dict = json.loads(response.text)
prov = tmp_dict["data"]["region"]
isp = tmp_dict["data"]["isp"]
return prov, isp
return None, None
#将日志里读取的格式转换为我们指定的格式
def trans_time(dt):
#把字符串转成时间格式
timeArray = time.strptime(dt, "%d/%b/%Y:%H:%M:%S")
#timeStamp = int(time.mktime(timeArray))
#把时间格式转成字符串
new_time = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return new_time
#从kafka里获取数据,清洗为我们需要的ip,时间,带宽
from pykafka import KafkaClient
client = KafkaClient(hosts="192.168.183.130:9092,192.168.183.131:9092,192.168.183.132:9092")
topic = client.topics['nginxlog']
balanced_consumer = topic.get_balanced_consumer(
consumer_group='testgroup',
auto_commit_enable=True,
zookeeper_connect='nginx-kafka01:2181,nginx-kafka02:2181,nginx-kafka03:2181'
)
import pymysql
# 打开数据库连接
db = pymysql.connect(host='192.168.183.128',
user='sanle',
password='123456',
database='project')
db.autocommit(True)
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
#consumer = topic.get_simple_consumer()
id = 1
for message in balanced_consumer:
if message is not None:
id += 1
line = json.loads(message.value.decode("utf-8"))
log = line["message"]
tmp_lst = log.split()
ip = tmp_lst[0]
dt = tmp_lst[3].replace("[", "")
bt = tmp_lst[9]
dt = trans_time(dt)
prov, isp = resolv_ip(ip)
sql = f"insert into nginxlog values('{id}','{dt}','{prov}','{isp}','{bt}')"
cursor.execute(sql)
if prov and isp:
print(prov, isp, dt)
7.1 遇到的问题
- 由于不是使用的本地数据库,使用root用户远程连接数据库时没注意授权问题,授权并且刷新权限后,问题解决。
- 配置Filebeat的yml文件时需要将原文件备份,重新编写一个输出只有一个yml文件。因为Filebeat的输出只有一个能生效。
为什么用kafka做日志收集而不用redis?
kafka适用于做日志收集平台
redis大多数使用在做kv数据存储上
redis也有一个queue的数据类型,用来做发布/订阅系统。
它里面的消息只能消费一次,kafka可以通过offset的设置来重复消费。
redis只有单一的消费者,不能分成多个消费组。
redis数据存储在内存的,kafka存储在磁盘的。