HadoopIntellijPlugin 插件还没安装好的可以参考这篇文章,
IntelliJ IDEA搭建Hadoop开发环境(上)
,安装好插件后,下一步就是导入 hadoop 的依赖包,这些包可以在 hadoop 的 share/hadoop 目录下找到,这里以经典的 WordCount 程序来进行演示
1、新建 maven 项目
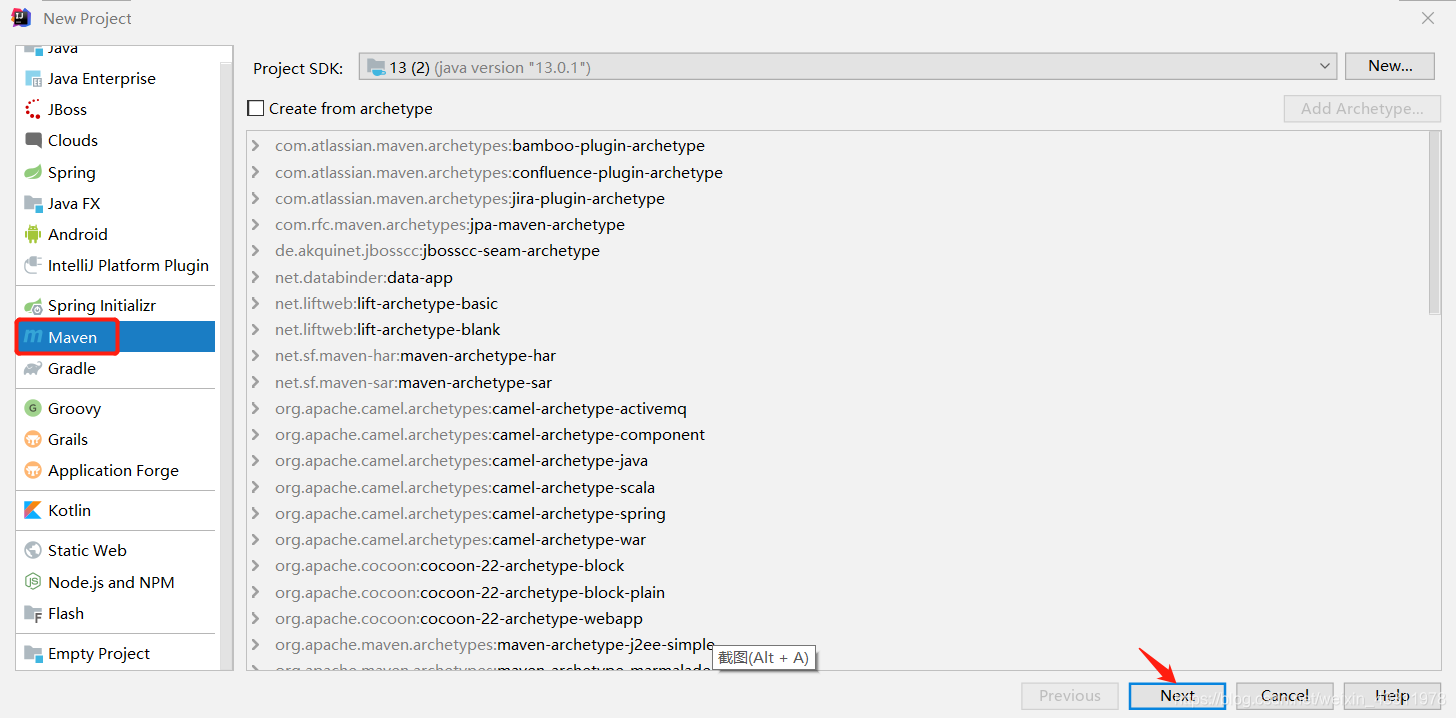
输入 GroupId 和 ArtifactId,然后 Next –> Finsh
2、新建class
名字输入 org.apache.hadoop.examples.WordCount
将下面代码复制过去
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public WordCount() {
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
// System.out.println(this.word);
}
}
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for (Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable) i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.app-submission.cross-platform", "true");
// String[] otherArgs = (new GenericOptionsParser(conf,
// args)).getRemainingArgs();
String[] otherArgs = new String[] { "/user/hadoop/input", "/user/hadoop/output" };
if (otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
Path outputPath = new Path(otherArgs[1]);
outputPath.getFileSystem(conf).delete(outputPath, true);
for (int i = 0; i < otherArgs.length - 1; ++i) {
// System.out.println(otherArgs[i]);
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
// System.out.println(otherArgs[otherArgs.length - 1]);
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
注意 main 方法里的这段代码
String[] otherArgs = new String[] { "/user/hadoop/input/", "/user/hadoop/output" };
第一个是输入目录(里面放好要统计单词的文件,可以自己建个文件然后写上一些单词),第二个是输出目录(运行前要不存在),这两个目录改成你自己的,可以用绝对路径,因为在配置文件中有配置 fs.defaultFS ,因此也可以用相对路径
比如下面这个是我的文件结构,假如我的 ip 是192.168.xxx.123
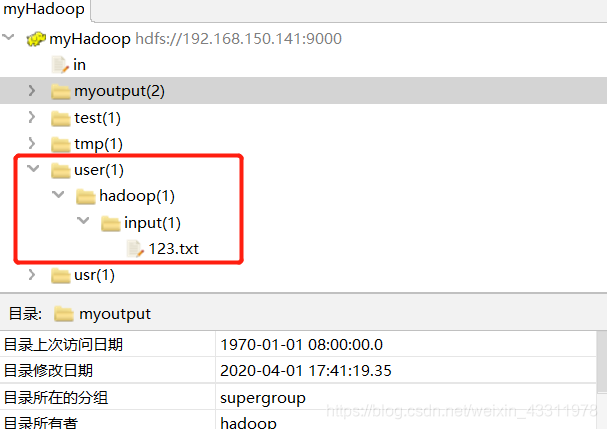
那么我的这两个参数可以是
String[] otherArgs = new String[] { "hdfs://192.168.xxx.123:9000/user/hadoop/input", "hdfs://192.168.xxx.123:9000/user/hadoop/output" };
也可以是用相对路径的
String[] otherArgs = new String[] { "/user/hadoop/input", "/user/hadoop/output" };
如果不想每次都手动删除 output 文件夹,可以加上这段代码(我上面给的代码已经加上了)
Path outputPath = new Path(otherArgs[1]);
outputPath.getFileSystem(conf).delete(outputPath, true);
3、导入依赖包
代码复制进去后,应该会看到有很多报错,因为还没有导入我们所需的依赖包
点击 File –> Project Structure
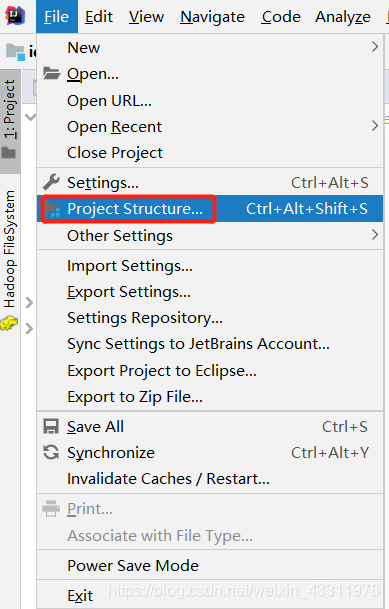
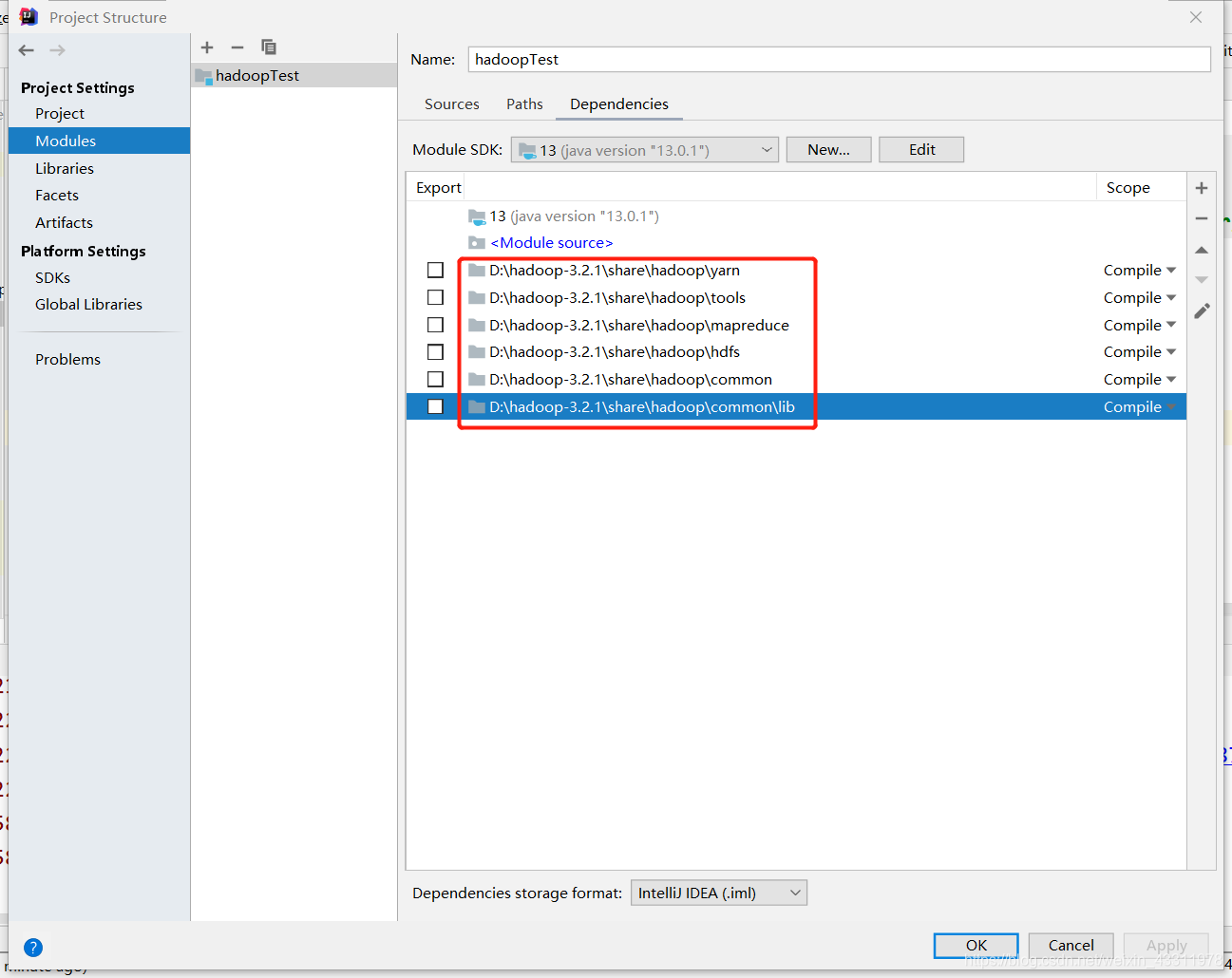
选择Modules,选中你的项目然后点击 Dependencies,右边的 + 号,JARs or directories
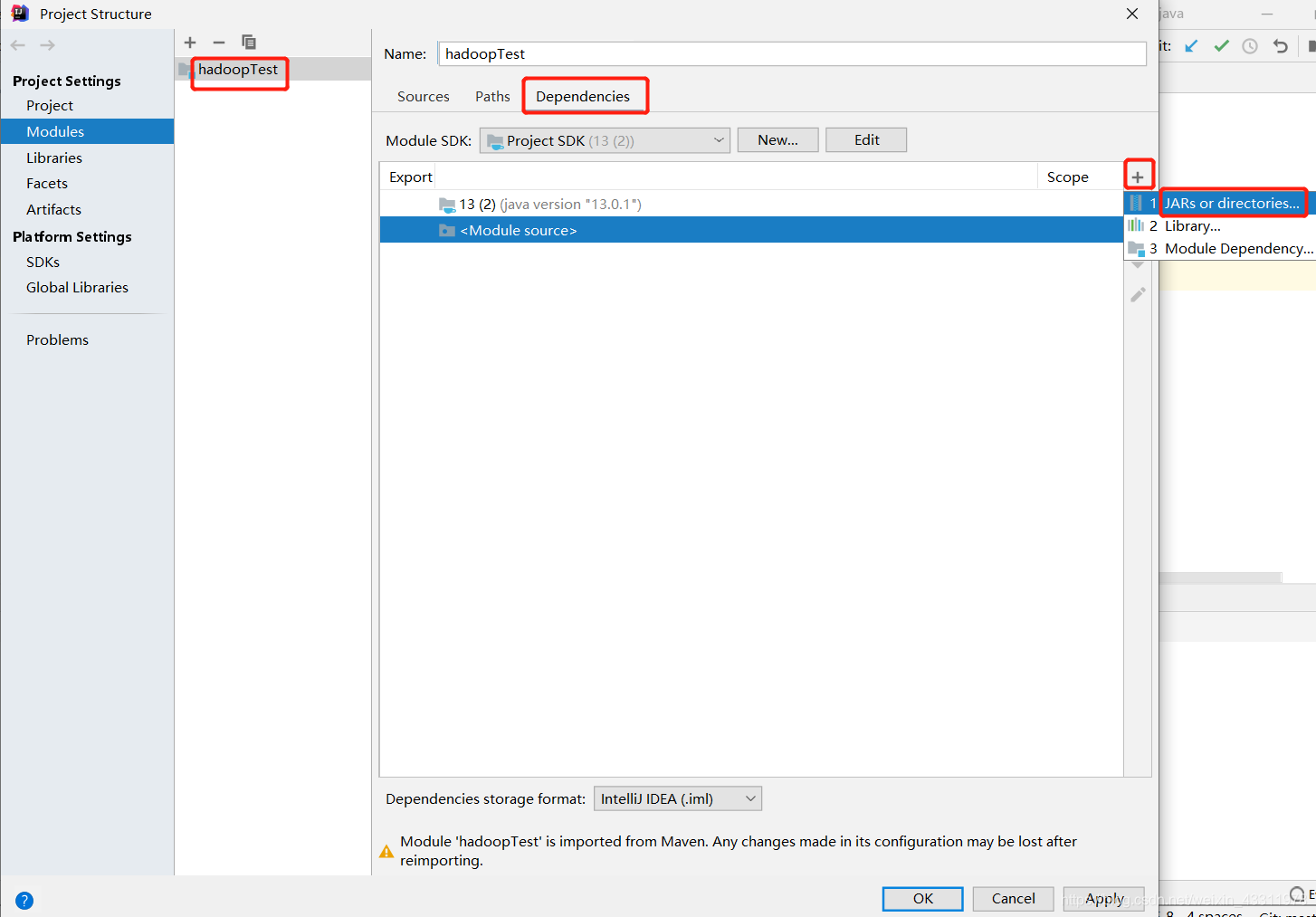
将下图几个文件夹添加进去,在你的 hadoop/share/hadoop 目录下
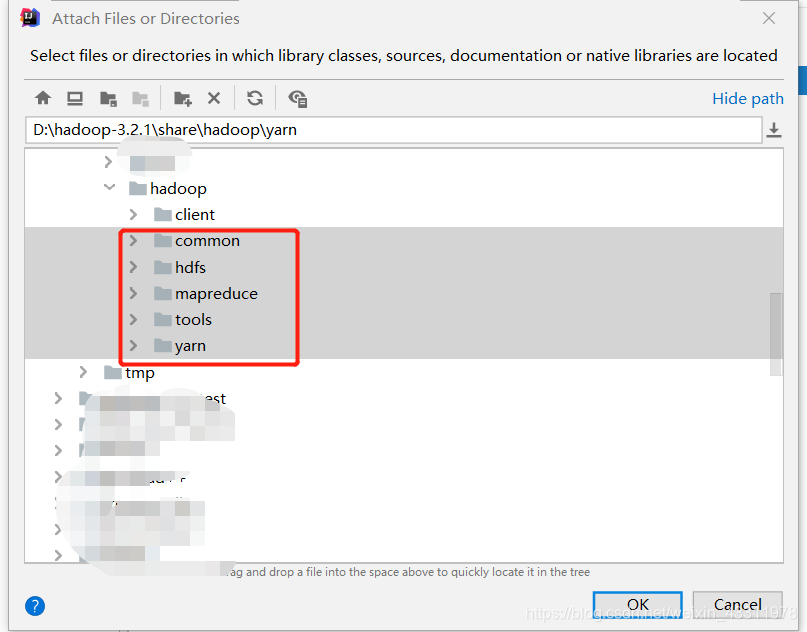
以及 common/lib 目录
添加完成后如下
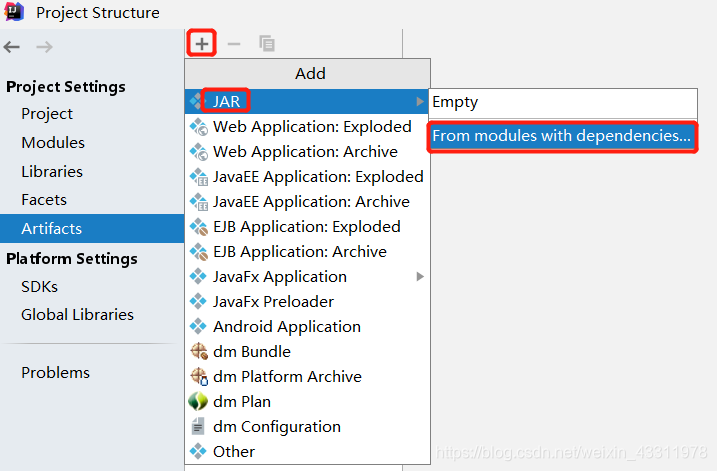
然后选择 Artifacts –> JAR –> From modules with dependencies
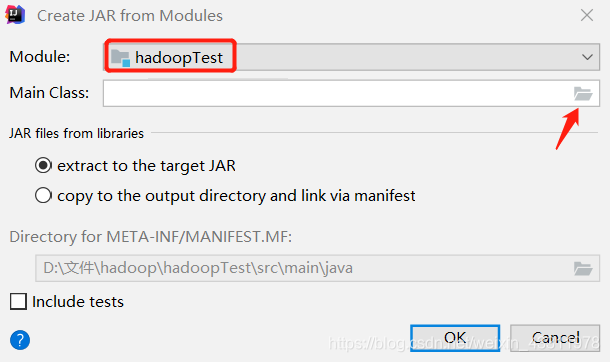
Module 选择刚刚这个, Main Class 选择 org.apache.hadoop.examples.WordCount
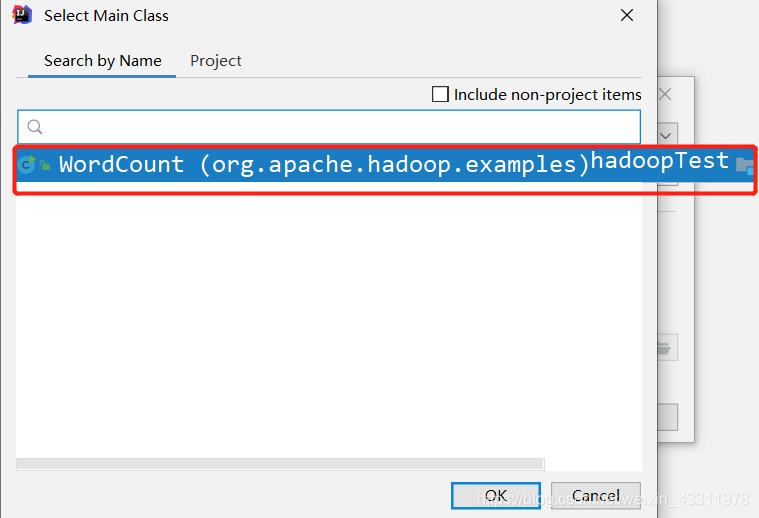
点击 OK
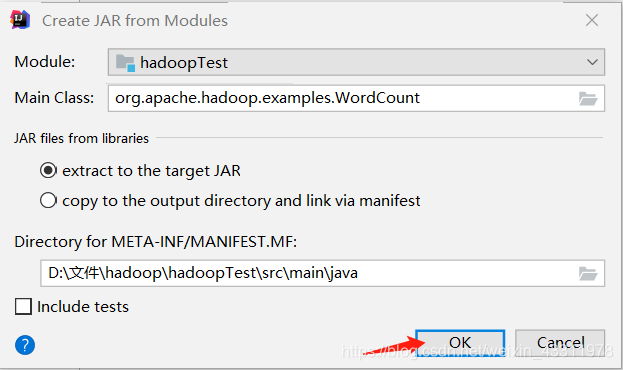
选中 Include in project build,点击 OK
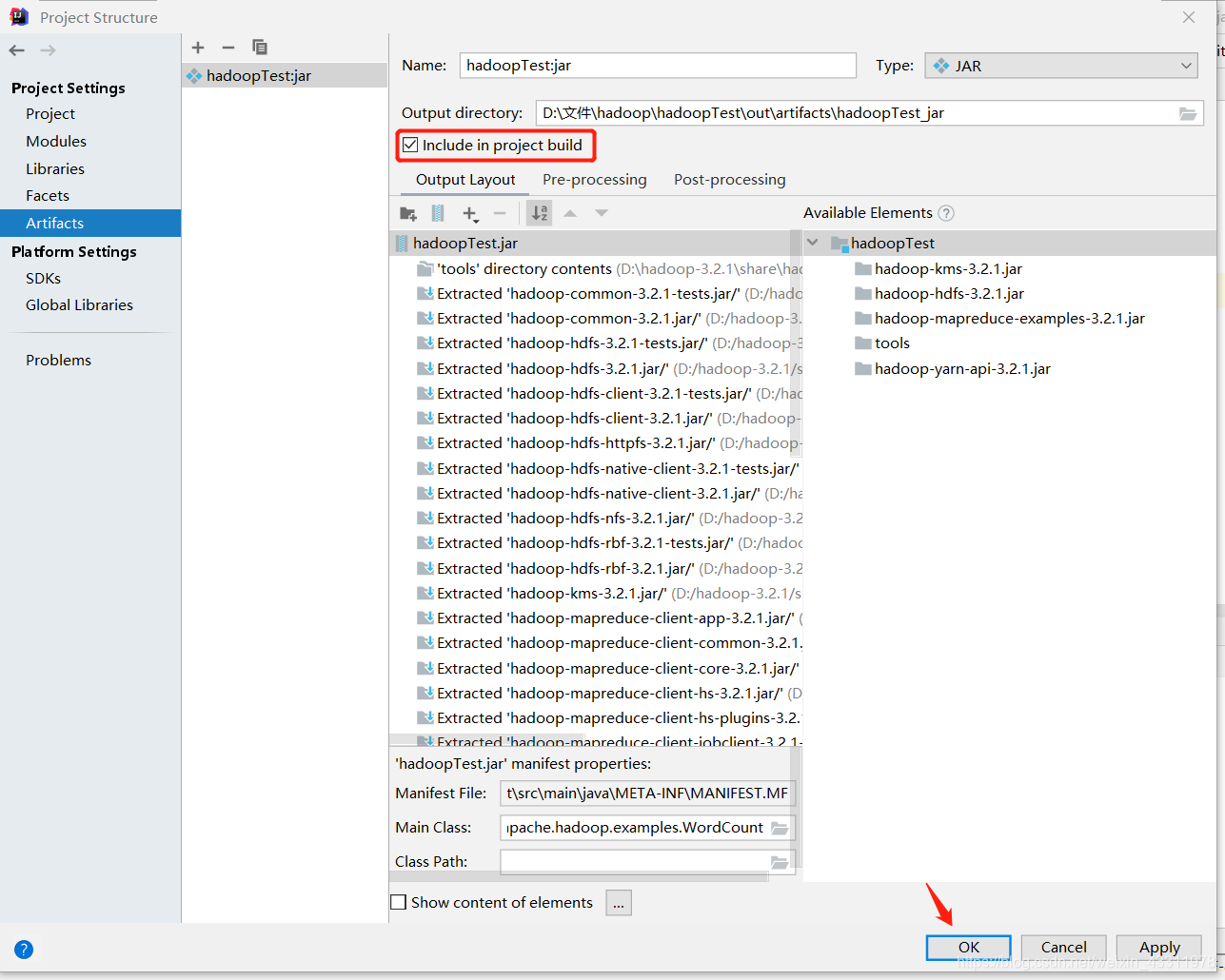
4、配置文件
我们将 core-site.xml ,hdfs-site.xml,mapred-site.xml,yarn-site.xml,log4j.properties 这五个文件复制到项目的 resources 目录下,前四个是你 hadoop 的配置文件,log4j.properties 用于记录程序的输出日志,没有的话就看不到报错信息
我的目录结构如下
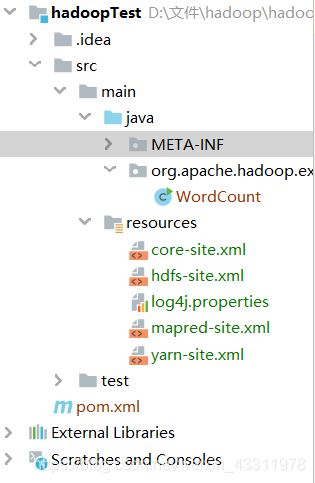
5、运行测试
下面我们开始运行 WordCount ,运行前记得先启动 hadoop 集群
右键 WordCount –> Run ‘WorldCount.main()’
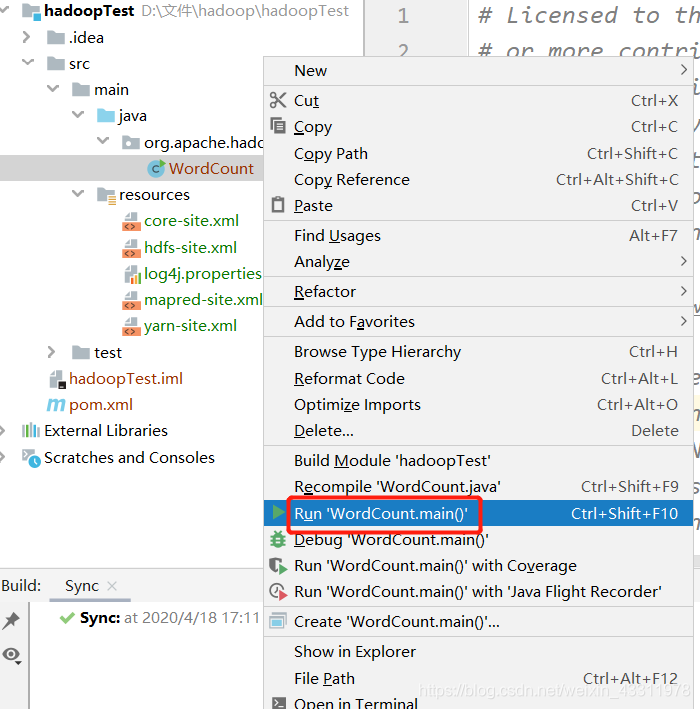
如果出现以下错误,说明项目编译配置使用的Java版本不对,需要检查一下项目及环境使用的Java编译版本配置

解决方法可以参考这篇文章:
https://blog.csdn.net/qq_22076345/article/details/82392236
在下方控制台可以看到输出的日志信息,等待运行完成
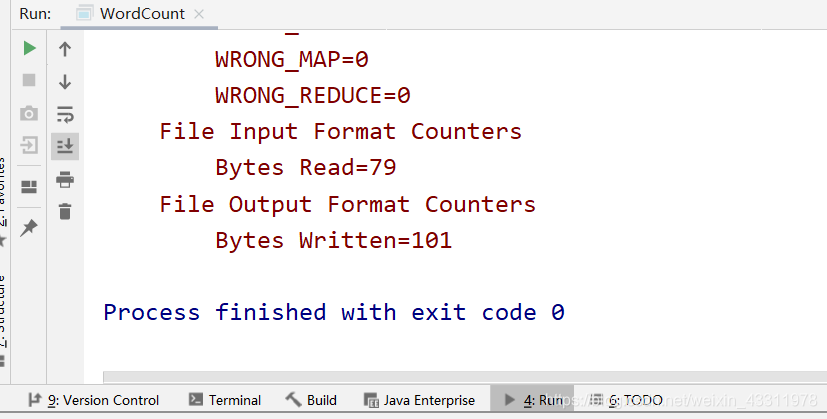
右键文件夹 Refresh,可以看见多了一个 output 文件夹,里面有两个文件,part-r-00000 这个文件就是统计结果了
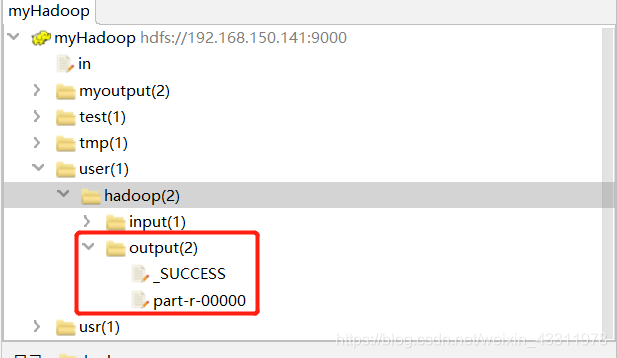
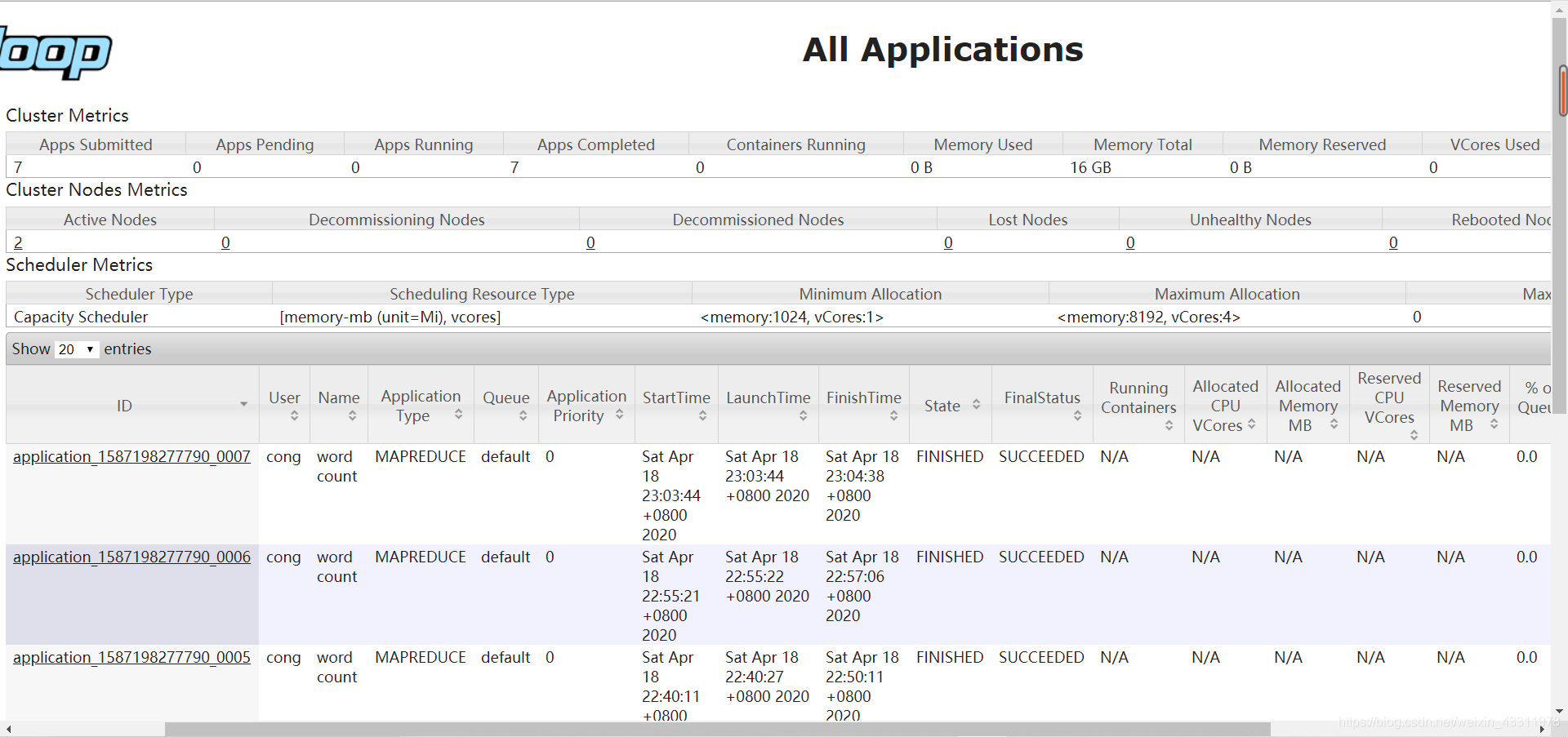
在8088页面也能看到刚刚提交到集群的 WorldCount 成功完成
这样就可以使用 idea 来开发 hadoop 程序并进行调试了!