关于Oracle的rownum大家并不陌生,很多人说是一个
查询出结果后的伪列
,是从1开始的,使用rownum过滤时必须从1开始等。rownum是怎样一个伪列,我们一会讨论;rownum是从1开始的,但是既然是伪列,为什么必须从1开始,下面我们一点点剖析。
本此博客主要讨论以下几个问题
①,rownum是什么及简要算法;
②,因为rownum,执行计划中COUNT STOPKEY是怎么回事;
③,利用rownum的COUNT STOPKEY进行分页SQL优化。
0,数据准备
drop table test1 ;
create table test1 as select * from dba_objects;
alter table TEST1 add constraint PK_TEST1 primary key (OBJECT_ID);
drop table test2;
create table test2 as select * from test1 where rownum<100; –只插入99条数据
1,一位美女的问题引出rownum是什么
前几天,有位美女提出了类似这样一个问题:
select * from test2 t where rownum=trunc(dbms_random.value(0,100));
这个语句实际返回结果是0-n条不等,按照很多人的解释,rownum过滤时必须从1开始,用随机数做条件,返回结果只能时0条或者1条,大于1条是怎么回事?
当我们不知道原因时,首先看看执行计划,看看数据库是怎么执行这句SQL的。

看这个执行计划,挺正常,一打眼,也看不出眉目。这里有个不起眼但是很重要的信息,
TABLE ACCESS FULL
,
一会我们说完rownum算法时,再回头说。
那我们先讨论rownum是什么吧。首先,我给rownum下另一个定义,
计数器!!!
简要算法举例:
我们首先构造个学生表,
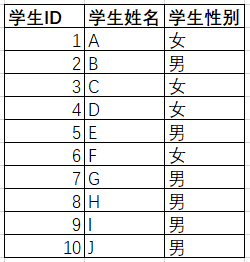
select * from 学生表 where 性别=男 and rownum<4;
运算过程如下,虽然枯燥,但是请逐行读完,这个地方对理解rownum很关键。
1,定义 rownum变量,初始值为1;
2,逐行扫描学生表:
2.1 学号为1的学生性别不满足,丢掉;
2.2找到2号学生时,性别满足,rownum的值为1,小于4,数据取出,并在这一列标
识上此时rownum的值,也就是1;
2.3 继续找下一行,性别不满足,丢掉;
2.4 找到学号为4的学生,性别满足,rownum值+1,此时rownum为2,小于4,数
据取出,并在数据上标识此时rownum的值2;
2.5 找到学号为5的学生,性别满足,rownum值+1,此时rownum为3,小于4,数
据取出,并在数据上标识此时rownum的值3;
2.6 找到6号学生,性别不满足,丢弃;
2.7找到7号学生,性别满足,rownum值+1,此时rownum值为4,不满足检索条件
rownum<4,截止目前,能够满足条件的数据已经全找出,结束查询。
通过这个运算过程,解释了rownum过滤为什么要从1开始,因为假设where rownum=2,
在上面2.2那个地方,就是取第一条结果是,就不满足rownum的条件了,查询就结束了;
通过上面的运算过程,也解释了大家为什么会称rownum为
查询出结果后的伪列
了,需要重点声明,这个所谓的查询出结果后,不是最后查询出结果后,而是逐行检索,取到满足条件(rownum条件和其他条件都满足)数据时加上的,即上面的
2.2
,2.4,2.5
那么,我们回到美女的问题,为什么用随机数做为rownum条件过滤时结果不固定呢?
此时该解释上面我们留下的问题,
TABLE ACCESS FULL
了。因为在查询过程时,
扫一行数据,产生一个随机数,随机数是1时,结果才保留下来
,当然,最后返回数据量不确定了。
当然,数据量最够大,但是随机数范围较小时,一般取到的行数=随机数最大值。例如用下面的test1(数据7万多条,随机数0-100),一般会返回99条;
select * from test1 t where rownum=trunc(dbms_random.value(0,100));
那么问题又来了,7万多次扫描,随机数产生1的机会应该不止99次吧,理论上700次左右吧,为什么几乎全是返回99条呢?
我个人猜想,Oracle内部做了优化处理,即使是满足条件的行数大于随机数的最大值,数据库也只返回随机数最大值以内的行数。至于猜想对不对,还请牛人指点。
2. 执行计划中COUNT STOPKEY
执行下面的SQL语句
select * from test1 t where rownum<10;
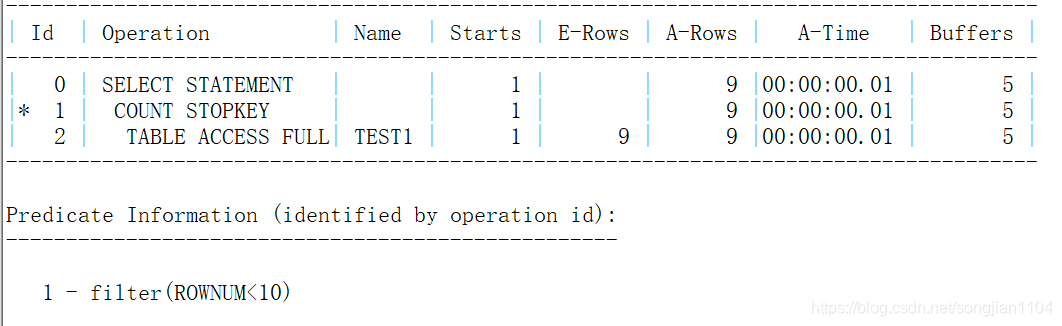
这里的COUNT STOPKEY就是【1,一位美女的问题引出rownum是什么】的【2.7找到7号学生,性别满足,rownum值+1,此时rownum值为4,不满足检索条件rownum<4,截止目前,能够满足条件的数据已经全找出,结束查询。】,也就是不满足rownum条件后,查询结束。
3. 利用rownum的COUNT STOPKEY进行分页SQL优化
其实,上面我们大篇幅说了rownum的原理,很多人该吐槽了,就是一程序员,又不是什么教授学究,搞这种算法有意义吗?
答案是有,我们这里就用rownum进行分页查询SQL优化,假设不懂rownum原理,我们只能生搬硬套高性能的分页写法。
先来两套分页写法,性能一好一坏。
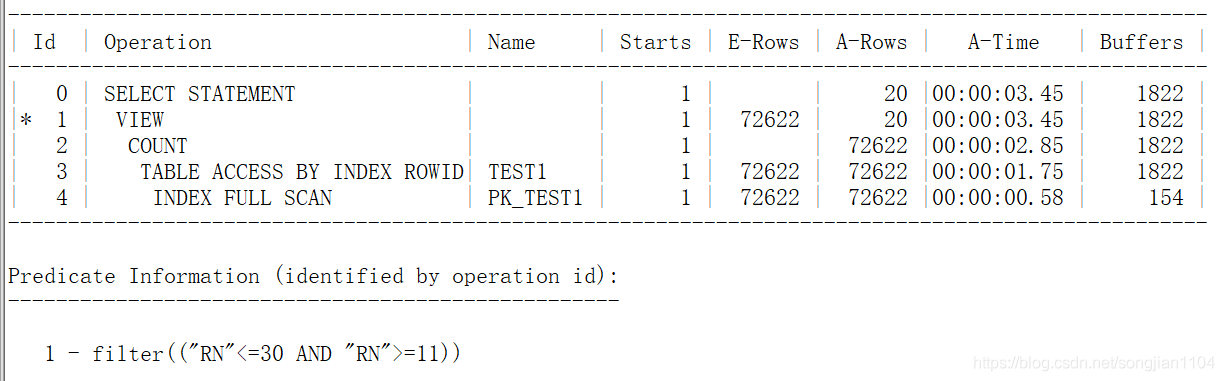
性能坏的写法:
select *
from (select rownum as rn , t1.*
from test1 t1
order by t1.object_id asc)
where rn between 11 and 30;
性能好的写法
select *
from (select rownum as rn, t.*
from(select t1.*
from test1 t1
order by t1.object_id asc) t
where rownum < 30) tt
where rn > 11;
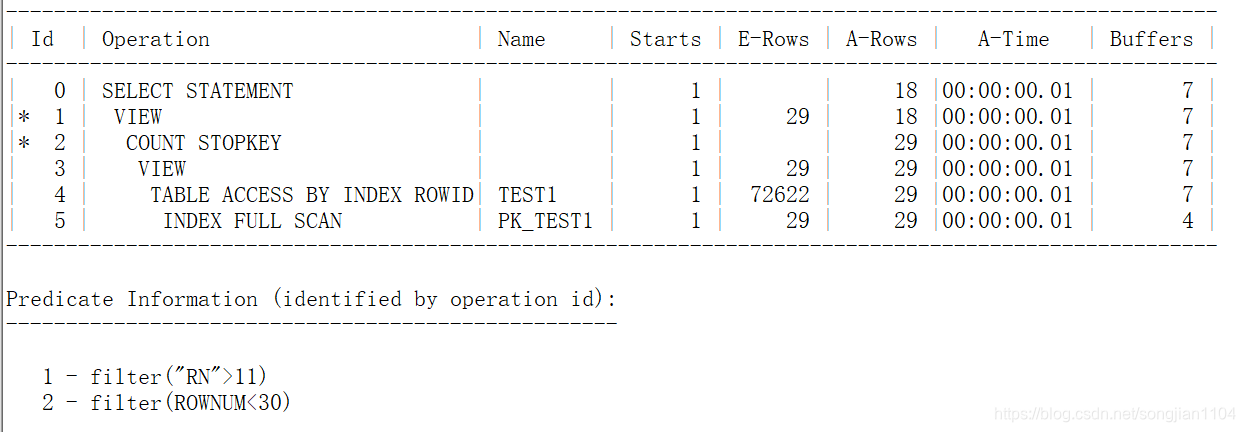
执行时间和逻辑读改善一目了然。
细心的朋友会发现,这里有个 INDEX FULL SCAN,其实之前,我也一直困惑INDEX FULL SCAN的使用场景,因为索引全扫描一般回表产生单块读(不回表就是INDEX FAST FULL SCAN了),全扫描就是全部回表;但是像ORACLE这种大厂,里面的研发人员都是技术相当牛的角色,他们肯定不会留着没有用的处理。看到这种高性能分页写法,还请教了SQL优化牛人落落(罗炳森)老师我才明白索引全扫描的好处,其实就是在分页查询时利用索引的有序配合rownum的COUNT STOPKEY来降低IO,至于索引全扫描还有没有其他的高性能使用场景,也请牛人指教。