目录
背景介绍
在DQN中,为了保证数据的有效性,采用了 Experience Replay Memory机制:
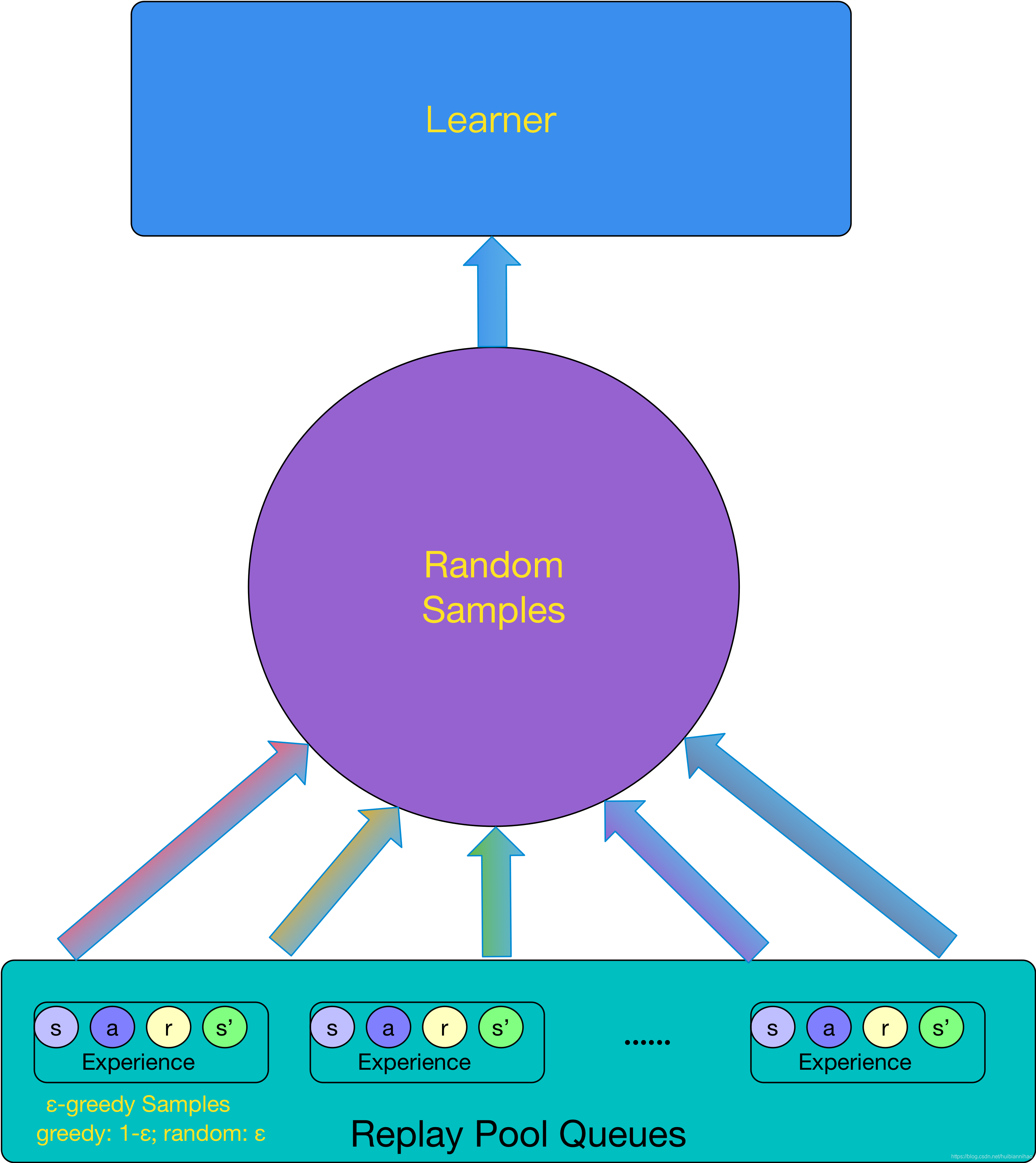
但是这种机制,存在几个问题:
1,
会占据
大块的内存
;
2,
学习是按mini-batch逐批
串行
学习的,数据吞吐量有限,学习
速度慢
;
3,
off-policy
,目标网络是旧的参数,生成sample data的网络参数也与当前不同。
探索既能提高数据吞吐量,又能保证数据有效性的并行算法,很有必要。
A3C模型
A
synchronous
A
dvantage
A
ctor-
C
ritic是一种
异步
的基于
优势函数
的
A
ctor-
C
ritic
并行
学习算法:
A
ctor指需要学习的policy π,
C
ritic指需要学习的Value Function。
模型的结构如下:
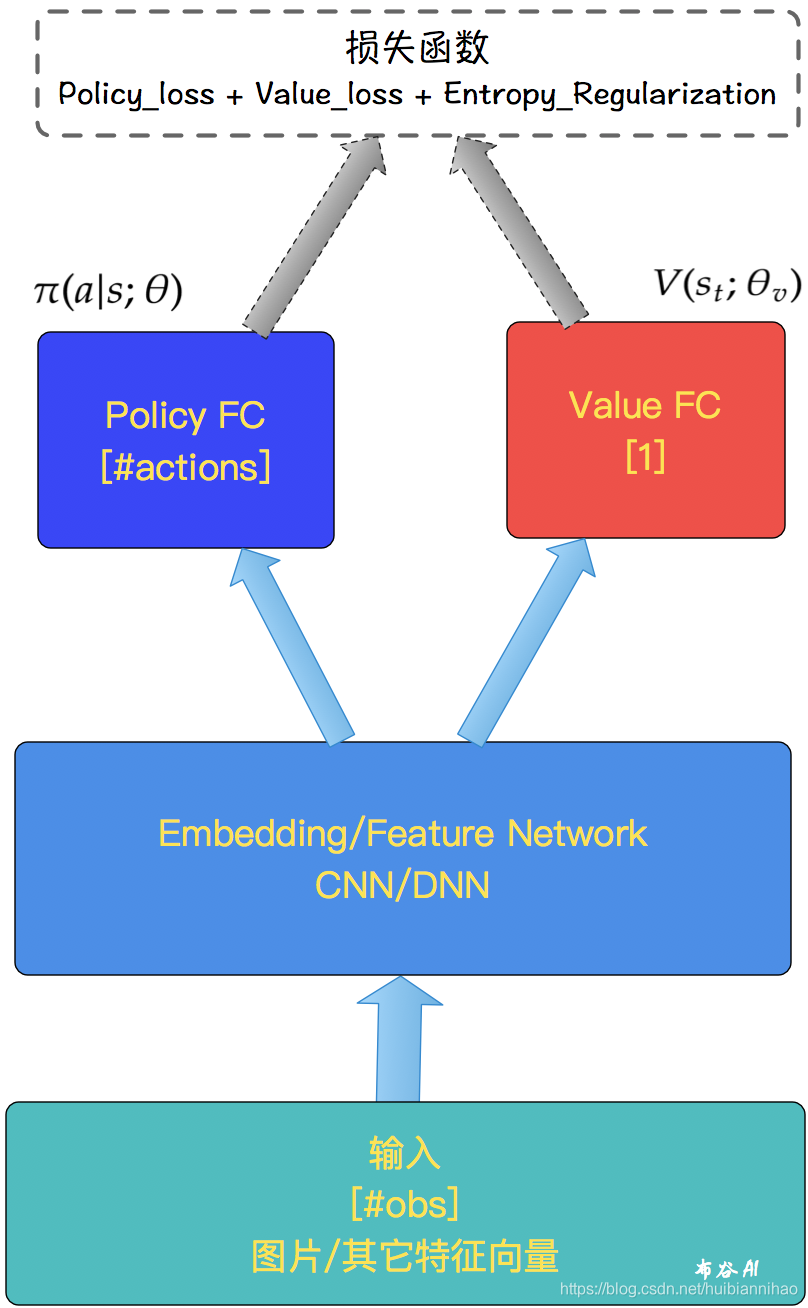
同时学习policy π 和 state-value function,
这里设计的是两个网络公用特征层,只是在FC层参数不同,
这是一种常用做法,但共享特征层不是必须的。
A3C损失函数
损失函数一般包含三项:
策略
梯度损失、值
残差
和策略
熵
正则。
需要注意的是:
在进行策略梯度时,优势函数是通过采样数据计算好的,与当前value网络参数无关;
策略熵正则项能够为了保证Actions的多样性,增加环境
探索
能力;

A3C学习过程
如图:
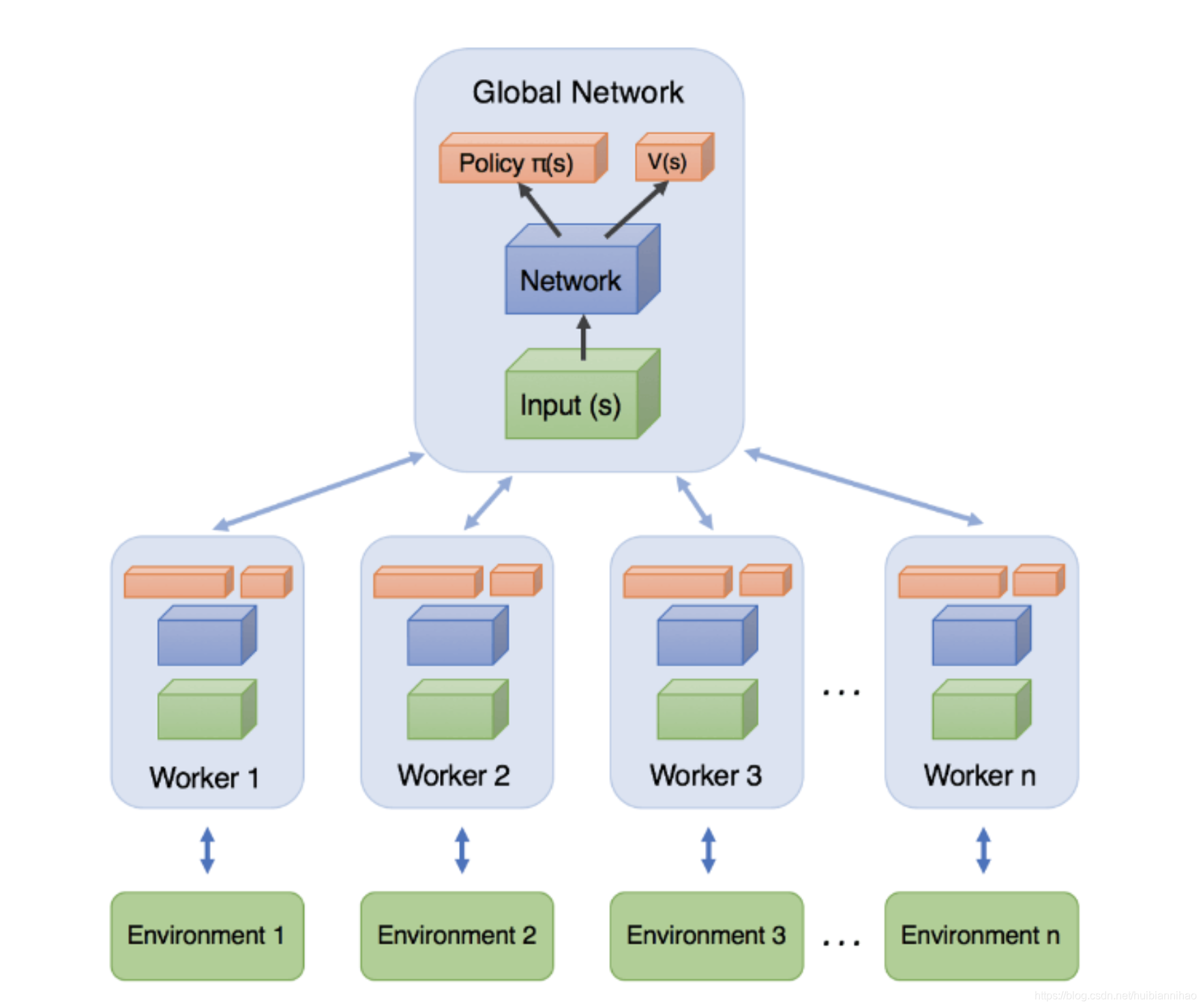
学习过程是这样的:
1,
开启多个线程(Worker),从Global Network同步最新的网络参数;
2,
每个Worker
独立
地进行采样、训练学习;
3,
每个Worker周期性地(Tmax)更新
独立
更新Global Network的参数,就是将自己累积的梯度更新到Global Network,然后更新最新的网络参数;
4,
重复2、3,直到收敛。
每个Worker学习更新的伪代码如下:

A2C
A
dvantage
A
ctor-
C
ritic是A3C的一种简化形式:
1,
开启多个线程(Worker),从Global Network同步最新的网络参数;
2,
每个Worker
独立
地进行采样;
3,
当数据总量达到mini-batch size时,
全部停止
采样;
4,
Global Network根据mini-batch的数据
统一
训练学习;
5,
每个Worker更新Global Network的参数
6,
重复2~5。
同时,可以看到,A2C的统一学习和A3C每个Worker的训练学习,采样数据的Policy与当前学习的Policy参数是一致的,即
on-policy
学习。
总结
A3C/A2C是通过利用多线程
并行独立
采样数据,
一方面保证数据的
多样性
,
另一方面提高学习效率,尤其是A3C通过异步学习,发挥多核同时学习的优势;
由于没有了DQN的Experience Replay Pool的设计,系统不必占用
大块内存
,更方便工业落地。